deeplabv3+网络模型
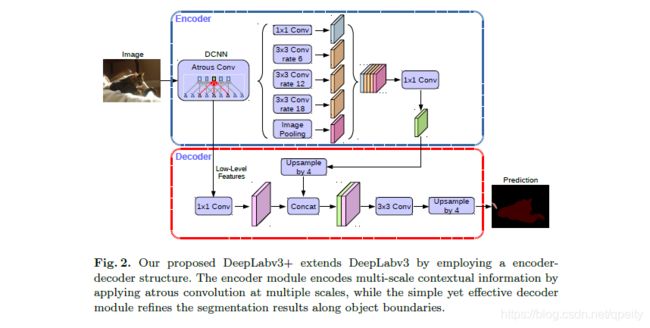
说一下个人理解:
本人选择的主干网络为Xception
1、先经过backbone提取特征,这时有两个输出:一个是向下的低级特征(low-level Features),是xception的entry flow的第一个残差块的输出,大小为输入的1/4,再经过一个1*1卷积;另一个为向右的高级特征,是xception网络的输出,大小由自己决定,本文采用的代码为输入的1/16,具体参数设置也可以见上篇博文。
2、高级特征经过一次ASPP模块,concat融合5个输出的通道,再通过1*1卷积调整通道,这时,因为输出为原始1/16,需要对进行上采样,上采样的结果尺寸,为低级特征的size()[-2:]
3、将处理好的低级特征与高级特征进行concat,再经过一次3*3的卷积(代码中用的是2次卷积,此时大小为输入的1/4),再经过一次上采样,最后按num_classes调整输出的通道即可。
aligned_xception.py 见(5条消息) Xception网络模型_qq_44785998的博客-CSDN博客
DeepLabV3P.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.tensorboard import SummaryWriter
from aligned_xception import xception_backbone
# from backbones.resnet_atrous import resnet50_atrous, resnet101_atrous
class ASPPConv1x1(nn.Sequential):
def __init__(self, in_channels, out_channels):
"""
ASPP用的5个处理之1,1个1x1卷积
:param in_channels: 输入channels,是backbone产生的主要特征的输出channels
:param out_channels: 输出channels,论文建议取值256
"""
modules = [nn.Conv2d(in_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True), ]
super(ASPPConv1x1, self).__init__(*modules)
pass
pass
class ASPPConv(nn.Sequential):
def __init__(self, in_channels, out_channels, dilation):
"""
ASPP用的5个处理之3,3个dilation conv,都是3x3的same卷积
:param in_channels: dilation conv的输入channels,是backbone产生的主要特征的输出channels
:param out_channels: dilation conv的输出channels,论文建议取值256
:param dilation: 膨胀率,论文建议取值6,12,18
"""
modules = [nn.Conv2d(in_channels, out_channels, kernel_size=3,
padding=dilation, dilation=dilation, bias=False), # same卷积padding=dilation*(k-1)/2
nn.BatchNorm2d(out_channels), # 有BN,卷积bias=False
nn.ReLU(inplace=True), ] # 激活函数
super(ASPPConv, self).__init__(*modules)
pass
pass
class ASPPPooling(nn.Sequential):
def __init__(self, in_channels, out_channels):
"""
ASPP用的5个处理之1,Image Pooling
:param in_channels: 输入channels,是backbone产生的主要特征的输出channels
:param out_channels: 输出channels,论文建议取值256
"""
modules = [
nn.AdaptiveAvgPool2d(1), # 全局平均池化,输出spatial大小1
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False), # 1x1卷积调整channels
nn.BatchNorm2d(out_channels), # 有BN,卷积bias=False
nn.ReLU(inplace=True), # 激活函数
]
super(ASPPPooling, self).__init__(*modules)
pass
def forward(self, x):
size = x.shape[-2:] # 记录下输入的大小
for mod in self:
x = mod(x)
return F.interpolate(x, size=size, mode='bilinear', align_corners=False) # 双线性差值上采样到原spatial大小
pass
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels):
"""
ASPP,对backbone产生的主干特征进行空间金字塔池化。
金字塔有5层:1个1x1卷积,3个3x3 dilation conv,1个全局平均池化
将5层cat后再调整channels输出。
这里不进行upsample,因为不知道low-level的spatial大小。
:param in_channels: 输入channels,是backbone产生的主要特征的输出channels
:param out_channels: 输出channels,论文建议取值256
"""
super(ASPP, self).__init__()
modules = [ASPPConv1x1(in_channels, out_channels), # 1个1x1卷积
ASPPConv(in_channels, out_channels, dilation=6), # 3x3 dilation conv,dilation=6
ASPPConv(in_channels, out_channels, dilation=12), # 3x3 dilation conv,dilation=12
ASPPConv(in_channels, out_channels, dilation=18), # 3x3 dilation conv,dilation=18
ASPPPooling(in_channels, out_channels), ] # 全局平均池化Image Pooling
self.convs = nn.ModuleList(modules)
self.project = nn.Sequential(nn.Conv2d(5 * out_channels, out_channels, 1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Dropout2d(0.5)) # 将5层cat后再调整channels输出,但不知道为什么Dropout
def forward(self, x):
output = []
for mod in self.convs:
output.append(mod(x))
pass
x = torch.cat(output, dim=1)
x = self.project(x)
return x
def get_backbone(in_channels, backbone_type='xception'):
"""
获取DeepLabV3+的Backbone
:param in_channels: 输出channels也就是图像的channels
:param backbone_type: 推荐使用ResNet101或Xception作为DeepLabV3+的Backbone
:return: 返回backbone,主干特征channels,low-level特征channels
"""
if backbone_type == 'resnet50':
pass
# atrous_channels = 2048
# low_level_channels = 256
elif backbone_type == 'resnet101':
# backbone = resnet101_atrous(in_channels=in_channels)
# atrous_channels = 2048
pass
# low_level_channels = 256
elif backbone_type == 'xception':
backbone = xception_backbone(in_channels=in_channels)
atrous_channels = 2048
low_level_channels = 128
else:
raise ValueError('backbone type error!')
return backbone, atrous_channels, low_level_channels
class DeepLabV3P(nn.Module):
aspp_out_channels = 256 # ASPP最终输出channels=256
reduce_to_channels = 48 # 论文中说low-level特征减少channels到48
def __init__(self, backbone_type, in_channels, n_class):
super(DeepLabV3P, self).__init__()
backbone, aspp_in_channels, low_level_in_channels = get_backbone(in_channels, backbone_type) # 取得backbone
self.backbone = backbone
self.aspp = ASPP(aspp_in_channels, self.aspp_out_channels) # 论文建议channels=256
# self.reduce_channels 对低特征图进行1*1卷积,改变通道数
reduce_modules = [nn.Conv2d(low_level_in_channels, self.reduce_to_channels, 1, bias=False),
nn.BatchNorm2d(self.reduce_to_channels),
nn.ReLU(inplace=True), ]
self.reduce_channels = nn.Sequential(*reduce_modules)
# self.decode 将ASPP模块输出和 低特征图1*1后结果进行concat
decode_modules = [nn.Conv2d(self.aspp_out_channels + self.reduce_to_channels,
self.aspp_out_channels,
3, padding=1, bias=False),
nn.BatchNorm2d(self.aspp_out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(self.aspp_out_channels,
self.aspp_out_channels,
3, padding=1, bias=False),
nn.BatchNorm2d(self.aspp_out_channels),
nn.ReLU(inplace=True), ]
self.decode = nn.Sequential(*decode_modules) # 两个3x3 conv decode
self.classifier = nn.Conv2d(self.aspp_out_channels, n_class, 1) # 最终分类
# 初始化参数
self._init_param()
pass
def _init_param(self):
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.ConvTranspose2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
pass
def forward(self, x):
size1 = x.shape[-2:] # 图像原始大小
# 提取特征,主干特征high-level和低级特征low-level
high_level, low_level = self.backbone(x) # high_level 是xception的输出 16x, low_level 是第一个残差块的输出4x
print("low_level.shape:",low_level.shape)
print("high_level.shape:",high_level.shape)
low_level = self.reduce_channels(low_level) # low-level feature的channels减少到 48
size2 = low_level.shape[-2:] # low-level feature大小,aspp上采样目标大小
high_level = self.aspp(high_level) # 空间金字塔池化
high_level = F.interpolate(high_level, size=size2, mode='bilinear',
align_corners=False) # 上采样和low-level的spatial大小一致
x = torch.cat([high_level, low_level], dim=1) # cat融合一下
x = self.decode(x) # 后面跟一系列3x3卷积,选择2个3x3卷积
x = self.classifier(x) # 最终分类
return F.interpolate(x, size=size1, mode='bilinear', align_corners=False) # 上采样和原图像大小一致
pass
if __name__ == '__main__':
device = torch.device('cuda')
# net = DeepLabV3P('resnet101', 3, n_class=8).to(device)
net = DeepLabV3P('xception', 3, n_class=21).to(device)
print(net)
in_data = torch.randint(0, 256, (4, 3, 299, 299), dtype=torch.float)
print('in data:', in_data.shape)
in_data = in_data.to(device)
out_data = net(in_data)
out_data = out_data.cuda()
print('out_data:', out_data.shape)
pass