MASK_RCNN解读3-原始训练模型加载和构建
MASK_RCNN解读3-原始训练FPN模型加载
现在开始进行网络的训练,脚本为:
python tools/train_net.py --config-file configs/my_e2e_mask_rcnn_R_50_FPN_1x.yaml MODEL.ROI_BOX_HEAD.NUM_CLASSES 6
SOLVER.IMS_PER_BATCH 4 SOLVER.BASE_LR 0.001 SOLVER.MAX_ITER 36000 SOLVER.STEPS " (24000, 32000)" TEST.IMS_PER_BATCH 1 MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN 2000
其中:
1:tools/train_net.py为用于训练的脚本;
2:–config-file指向训练用的配置文件;
3:MODEL.ROI_BOX_HEAD.NUM_CLASSES 6:指向我们finetuning的分类,注意,含这个数量背景。
4:SOLVER.IMS_PER_BATCH 4:一个batch,4张图片
5:SOLVER.BASE_LR:更新参数的权重detaT;
6:SOLVER.MAX_ITER 36000:做36000此训练eproch;
7:SOLVER.STEPS " (24000, 32000)" :到24000和32000次训练后,更新参数的权重detaT会变小
8:TEST.IMS_PER_BATCH 1:测试一个batch为张图;
9:MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN:对MASK-RCNN中的FPN网络,选取前2000个后续bbox
通过config.py文件下的merge_from_file(self, cfg_filename):函数,读取yml配置文件内容。
返回的配置类型为:
读取完配置文件进入def train(cfg, local_rank, distributed):函数
根据配置文件,构建模型:
model = build_detection_model(cfg)
根据配置,将模型放入显卡
device = torch.device(cfg.MODEL.DEVICE)
model.to(device)
根据配置,创建优化器和优化调度器
optimizer = make_optimizer(cfg, model)
scheduler = make_lr_scheduler(cfg, optimizer)
使能英伟达的Apex混合精度加速
Initialize mixed-precision training
use_mixed_precision = cfg.DTYPE == “float16”
amp_opt_level = ‘O1’ if use_mixed_precision else ‘O0’
model, optimizer = amp.initialize(model, optimizer, opt_level=amp_opt_level)
使能checkpointer功能
checkpointer = DetectronCheckpointer(
cfg, model, optimizer, scheduler, output_dir, save_to_disk )
extra_checkpoint_data = checkpointer.load(cfg.MODEL.WEIGHT)
arguments.update(extra_checkpoint_data)
开始读取用于训练的文件:
data_loader = make_data_loader(
cfg,
is_train=True,
is_distributed=distributed,
start_iter=arguments[“iteration”],
)
执行do_train函数,进行训练:

本文,先研究根据配置文件,构建模型的部分:
model = build_detection_model(cfg),创建后的结果为:
1)进入class GeneralizedRCNN(nn.Module)的初始化函数:def init(self, cfg);
2)执行self.backbone = build_backbone(cfg)函数,进入modeling/backbone下的backbone.py文件中的def build_resnet_fpn_backbone(cfg)函数,即基于resnet网络的图像金字塔(fpn)网络。
3)进入class ResNet(nn.Module)的def init(self, cfg)函数,初始化了2个类:
4)进入self.stem = stem_module(cfg)函数,生成stem,进入了class BaseStem(nn.Module):初始化stem。
5)这个函数body = resnet.ResNet(cfg),返回纯粹的resnet的网络结构。
6)通过fpn = fpn_module.FPN,返回fpn结构,特征图金字塔网络FPN网络;
7)行数self.rpn = build_rpn(cfg, self.backbone.out_channels)开始构建RPN网络(RegionProposalNetwork)。
通过正向传播研究网络结构,测试脚步如下所示:
python demo/jianghao_seg_image.py --config-file configs/jianghao_test_e2e_mask_rcnn_R_50_FPN_1x.yaml --input-file datasets/coco/val2017/20191225_091233_rsize1280x720.jpg --output-file demo/mypredictions.jpg
正向传播网络代码跟踪结果如下:
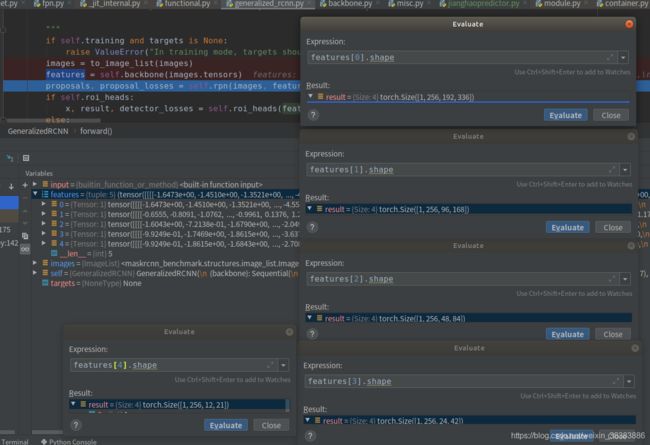
1)进入class GeneralizedRCNN(nn.Module)的def forward(self, images, targets=None):函数;
2)进入features = self.backbone(images.tensors)函数,进入主网络的正向传播;
3)主网络尾部结构为resnet101,所以进入该类的forward函数,标记为为return_features的layer1~layer4的输出features(抽取的特征)。

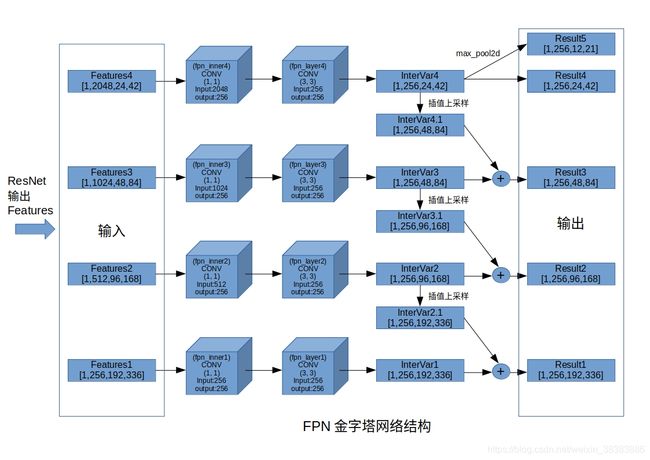
我们来看一下resnet101输出的features的内容:features1是尺寸最大、感受野最小的[1,256,192,336]四维度矩阵(tensor),忽略第一个1维度(代表就1张图片),即256(通道维度)x192(宽)x336(高),该尺寸和layer1使用的卷积核以及polling层相关。features2是[1,512,96,168]四维度矩阵(tensor),features3是[1,1024,48,84]四维度矩阵(tensor),features4是是尺寸最小、感受野大最的[1,2048,24,42]四维度矩阵(tensor).之所以抽取这四个features,就是为了实现图像金字塔(FPN)的功能,下一步将这四个四维矩阵传入FPN网络的forward函数。
4)FPN网络的forward函数的输入为:x (list[Tensor]): feature maps for each feature level.输出为,results (tuple[Tensor]): feature maps after FPN layers.They are ordered from highest resolution first.其中list 与 tuple 都是序列类型的容器对象,最根本的区别,list是可变数据类型,tuple是不可变数据类型,所以代码更安全。
5)FPN网络的forward函数里,第一步:last_inner = getattr(self, self.inner_blocks[-1])(x[-1]),其中,getattr(self, self.inner_blocks[-1])指向Conv2d(2048, 256, kernel_size=(1, 1), stride=(1, 1)),它是“

为什么要这么做,引用解释如下:
在这里作者实验表明使用1x1的Conv即可生成较好的输出特征,它可有效地降低中间层次的channels 数目。最终这些1x1的Convs使得我们输出不同维度的各个feature maps有着相同的channels数目(本文用到的Resnet-101主干网络中,各个层次特征的最终输出channels数目为256)。
作者:manofmountain
链接:https://www.jianshu.com/p/5a28ae9b365d
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
5)还是在FPN网络的forward函数里,第二步:results.append(getattr(self, self.layer_blocks[-1])(last_inner)),即将第四步的last_inner进行一个3x3的卷积层,输出结果torch.Size([1, 256, 24, 42])。
6)还是在FPN网络的forward函数里,第三步: for feature, inner_block, layer_block in zip(
x[:-1][::-1], self.inner_blocks[:-1][::-1], self.layer_blocks[:-1][::-1]
):从后往前取各层的feature(即输入的x),inner_block和layer_block。
7)第一轮循环取的feature为输入的features3,torch.Size([1, 1024, 48, 84]),inner_block为’fpn_inner3’,layer_block为’fpn_layer3’。
8) 对第5步计算的last_inner(torch.Size([1, 256, 24, 42]))进行插值上采样,inner_top_down = F.interpolate(last_inner, scale_factor=2, mode=“nearest”)得到的inner_top_down为torch.Size([1, 256, 48, 84]),放大了宽和高为原来的2倍。
9) inner_lateral = getattr(self, inner_block)(feature),将当前的feature3带入fpn_inner3进行计算,fpn_inner3为Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1)),计算结果inner_lateral为torch.Size([1, 256, 48, 84])。
10) 将9)和8)得到的结果相加,last_inner = inner_lateral + inner_top_down,得出结果last_inner。
11)将10中的last_inner进行fpn_layer3的卷积,并将结果归入result,该tensor的torch.Size([1, 256, 48, 84])。
12)重复7)到11)步骤将fpn_inner2~fpn_inner1以及fpn_layer2~fpn_layer1进行计算,至此,输出了result1~4,size为[1, 256, 24, 42]、[1, 256, 48, 84]、[1, 256, 96, 168]、[1, 256, 192, 336].
13)还是在FPN网络的forward函数里,执行last_results = self.top_blocks(results[-1]),通过max_pool2d操作,得到last_results为torch.Size([1, 256, 12, 21])。如下图所示:
Image(filename = 'MaskRcnn的FPN计算结构.jpg', width=1000, height=800)