Tensorflow神经网络模型训练之Fashion Mnist
1.最简单的单神经元网络
实例:
x = − 1 , 0 , 1 , 2 , 3 , 4 ; y = − 3 , − 1 , 1 , 3 , 5 , 7 x= -1,0,1,2,3,4;y= -3,-1,1,3,5,7 x=−1,0,1,2,3,4;y=−3,−1,1,3,5,7
通过简单观察我们可以知道x与y满足的表达式:
y = 2 x − 1 y=2x-1 y=2x−1
那么如何让机器自己学习x与y之间的关系呢?
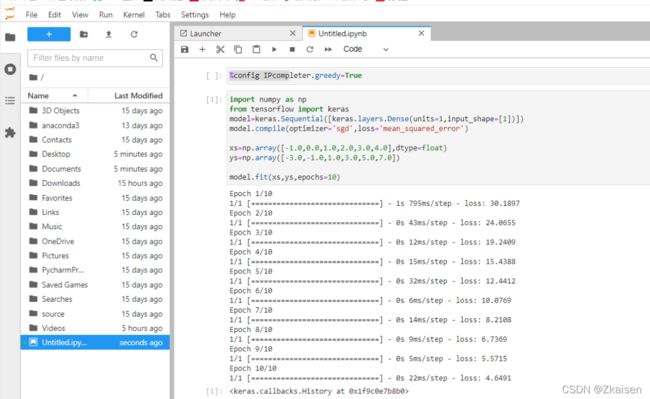
1)构建模型
model=keras.Sequential([keras.layers.Dense(units=1,input_shape=[1])])
model.compile(optimizer='sgd',loss='mean_squared_error')
代码解释:
- keras是tensorflow的一个高级的API;units=1代表一层神经元;input_shape=[1]表示只有一个输入值。
- 指定模型的lossfunction,根据什么检测损失
指定optimizer,根据什么来优化;'sgd’表示一种优化器;mean_squared_error均方误差损失函数。
2)准备训练数据
xs=np.array([-1.0,0.0,1.0,2.0,3.0,4.0],dtype=float)
ys=np.array([-3.0,-1.0,1.0,3.0,5.0,7.0])
代码解释:使用numpy将x与y的取值转成array,可以指定数据类型。
3)训练模型
使用fit方法训练模型epochs指训练的次数,所有的数据训练一次为有一个epochs,epochs=500,就是指这些数据要跑500次,这个模型学习500次。
model.fit(xs,ys,epochs=500)
4)使用模型
最后使用模型预测x=10.0时y的值是多少
我们代入y=2x-1,应该是19,但是输出未必正好是19,他可能是一个很接近19的一个值,神经网络会把y的取值当做一个概率的问题来做,结果就是概率最大情况的取值。
print(model.prediict([10.0]))
5)运行结果
- 先训练10个epoch,我们可以看到loss在逐渐减小
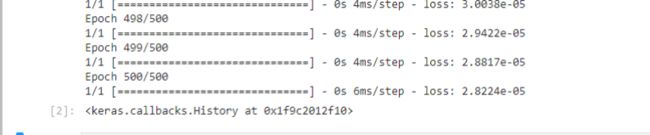
-训练500次后损失较少为2.8224×10(-5)
 - 根据模型预测x=10.0时,y的值为18.9845,与19非常接近说明预测结果很好。
- 根据模型预测x=10.0时,y的值为18.9845,与19非常接近说明预测结果很好。

2.BP神经网络的实例
1)Fashion MNIST数据集
- 70000张图片
- 10个类别
- 图像像素为28×28
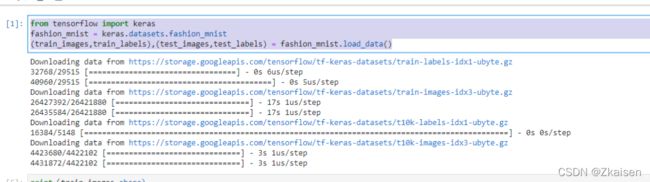
2)加载Fashion MNIST数据集
from tensorflow import keras
fashion_mnist = keras.datasets.fashion_mnist
(train_images,train_labels),(test_images,test_labels) = fashion_mnist.load_data()
运行结果:
第一次加载数据集时可以看到下载的进度条。
- 看看训练集图像和测试集图像的大小
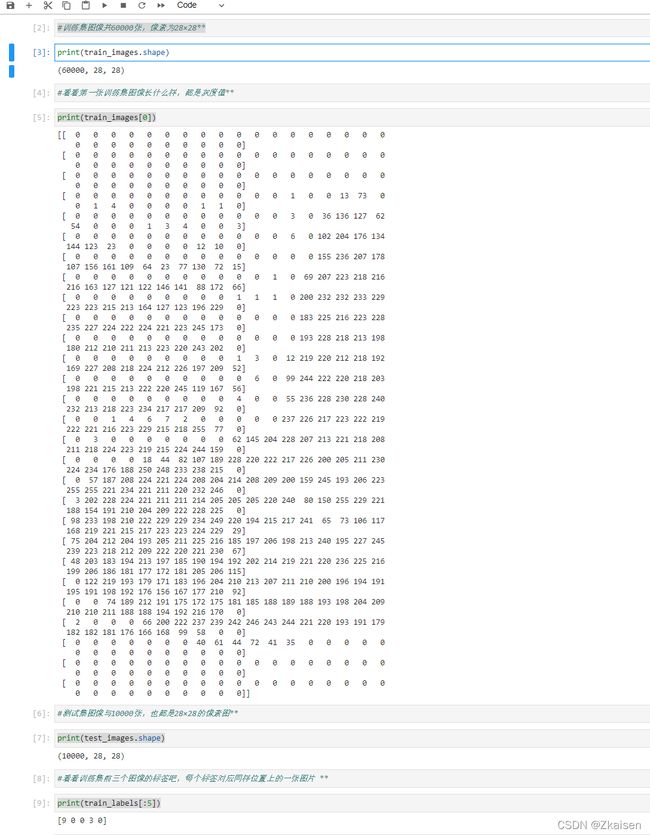
print(train_images.shape)
print(train_images[0])
print(test_images.shape)
print(train_labels[:5])
- 看看具体图片长啥样
使用matplot.pyplot中的imshow方法将图片展示出来,第0张图片是一只靴子,第1张图片是一件T恤。
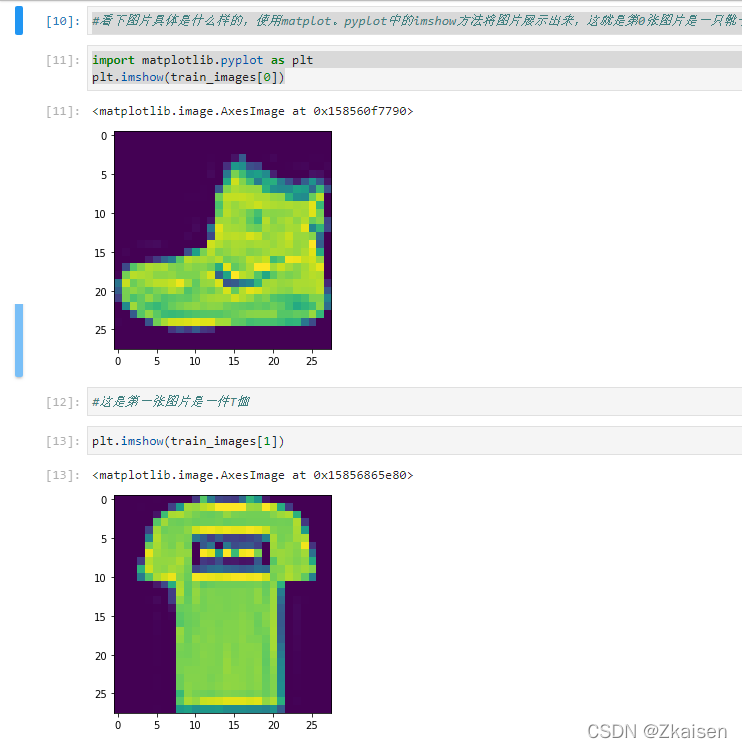
import matplotlib.pyplot as plt
plt.imshow(train_images[0])
3)构建神经元网络模型
一个三层的神经元网络结构:
- 输入层接受输入,因为训练数据是28×28的,所以输入这个shape也是28×28的,它是把28×28的像素展开共784个像素;
- 中间层有128个神经元,是可以自己任意修改中间层的神经元个数的;
- 最后一层是输出层,因为我们是10分类问题,所以有10个输出,即10个神经元。
model=keras.Sequential()
model.add(keras.layers.Flatten(input_shape=(28,28)))
model.add(keras.layers.Dense(128,activation=tf.nn.relu))
model.add(keras.layers.Dense(10,activation=tf.nn.softmax))
-使用model.summary()看看网络结构
model.summary()
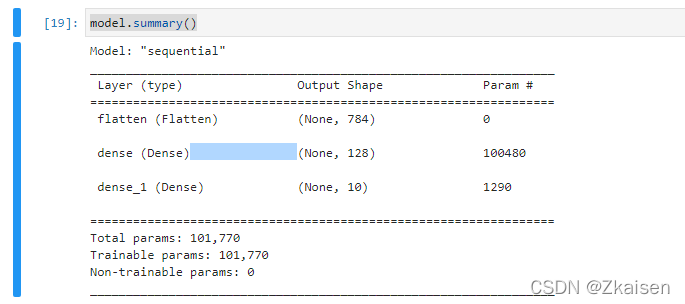
网络参数解读:
第二层:10480=784×128+128=100352+128
第三层:1290=10×(128+1)
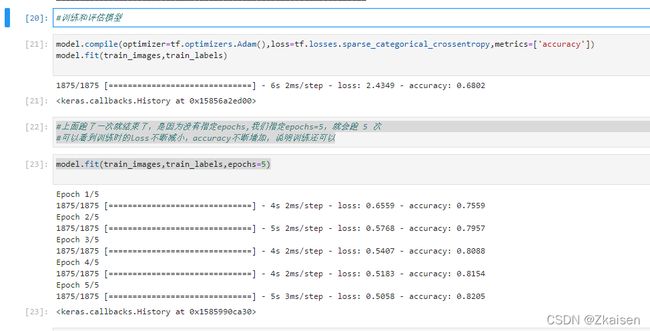
4)训练
model.compile(optimizer=tf.optimizers.Adam(),loss=tf.losses.sparse_categorical_crossentropy,metrics=['accuracy'])
model.fit(train_images,train_labels)//未指定epochs,默认训练一次
model.fit(train_images,train_labels,epochs=5)
- 归一化
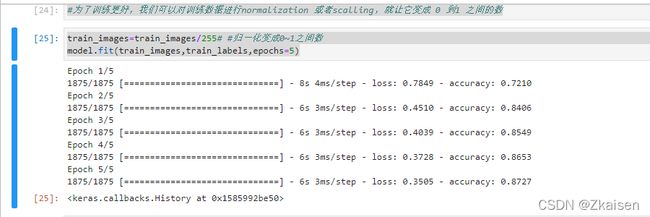
为了训练更好,我们可以对训练数据进行normalization 或者scalling,就让它变成 0 到1 之间的数。
train_images=train_images/255# #归一化变成0~1之间数
model.fit(train_images,train_labels,epochs=5)
运行结果:与未归一化相比,通过normalization训练中loss更小,准确度accuracy更高了,训练效果更好了。
5)评估模型
- test数据集测试
模型训练完成后,我们可用test数据集评估模型的准确度
test_images_scaled=test_images/255
model.evaluate(test_images_scaled,test_labels)
我们看到loss比训练时有点增加,accuracy比训练是有点低,不过查德努什很多,说明模型训练的还是可以的!

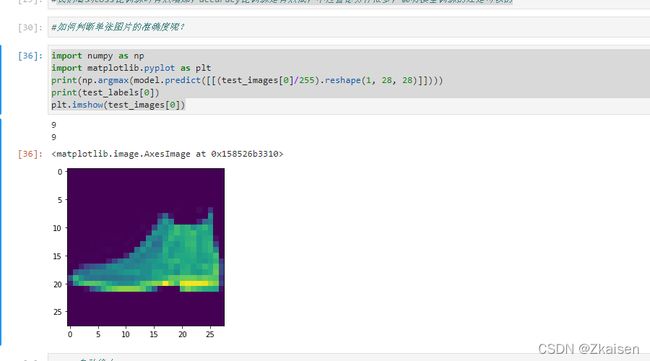
- 预测单张图像的类别
import numpy as np
import matplotlib.pyplot as plt
print(np.argmax(model.predict([[(test_images[0]/255).reshape(1, 28, 28)]])))
print(test_labels[0])
plt.imshow(test_images[0])
我们看到loss比训练时有点增加,accuracy比训练是有点低,不过查德努什很多,说明模型训练的还是可以的
- 可视化loss与accuracy
history = model.fit(train_images,train_labels,epochs=50,validation_split=0.3,shuffle=True)
epochs = len(history.history['loss']) #获取X轴长度
fig, axes = plt.subplots(2, sharex=True, figsize=(12, 8))
fig.suptitle('Training Metrics')
axes[0].set_ylabel("Loss", fontsize=14)
axes[0].set_xlabel("Epoch", fontsize=14)
axes[0].plot(range(epochs),history.history['loss'], label='Loss')
axes[0].plot(range(epochs),history.history['val_loss'], label='Loss')
plt.legend()
axes[1].set_ylabel("Accuracy(%)", fontsize=14)
axes[1].set_xlabel("Epoch", fontsize=14)
axes[1].plot(range(epochs),history.history['accuracy'], label='Accuracy')
axes[1].plot(range(epochs),history.history['val_accuracy'], label='Val_accuracy')
# plt.savefig('./epoch.jpg')
# plt.suptitle('自定义图表', fontsize=400, ha='center') # 即标题在x轴和y轴形成的方框内部,如下图(详细用法见下注释)。如果需要标题在这上方,使用 plt.title(blabla)
plt.legend()
plt.show()
运行结果:
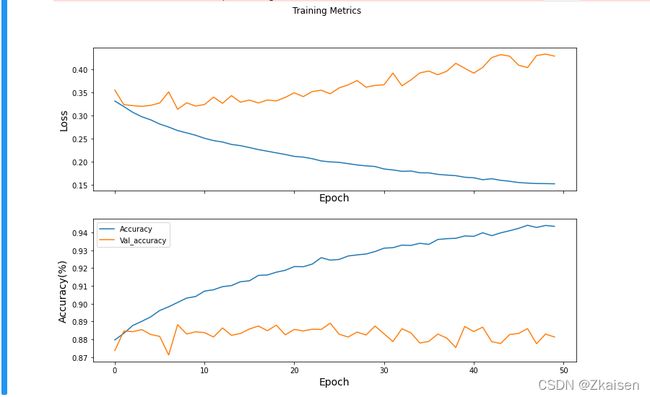
从上图可以看出:loss与准确率曲线可以看出训练过拟合了,训练集的loss下降多,但是测试集的训练loss增加了,训练参数不匹配,我们可以通过调节训练次数对模型进行优化。
6)自动终止
为了避免出现过拟合现象,我们可以设定一个条件,当满足该条件时,及时终止训练。
定义一个Callbacks的类传递给参数,每次训练都会调用这个类,当满足这个类的条件时,训练就会自动终止。
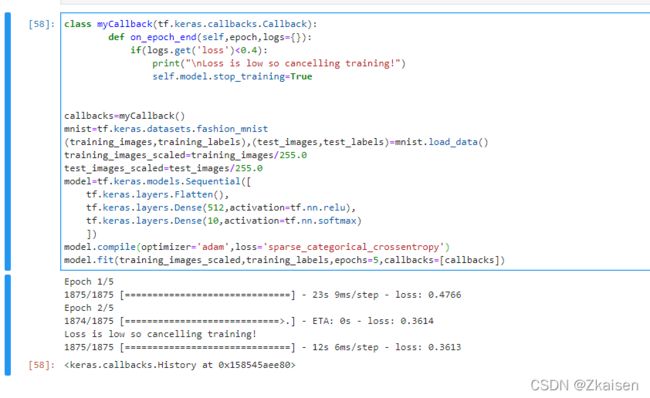
class myCallback(tf.keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs={}):
if(logs.get('loss')<0.4):
print("\nLoss is low so cancelling training!")
self.model.stop_training=True
callbacks=myCallback()
mnist=tf.keras.datasets.fashion_mnist
(training_images,training_labels),(test_images,test_labels)=mnist.load_data()
training_images_scaled=training_images/255.0
test_images_scaled=test_images/255.0
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512,activation=tf.nn.relu),
tf.keras.layers.Dense(10,activation=tf.nn.softmax)
])
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy')
model.fit(training_images_scaled,training_labels,epochs=5,callbacks=[callbacks])
如运行结果显示:当loss<0.4时,训练自动终止。