【论文阅读】An empirical study on image bag generators for multi-instance learning
【论文阅读】An empirical study on image bag generators for multi-instance learning
用于多实例学习的图像包生成器的实证研究
时间:2022/10/31
文章目录
- 【论文阅读】An empirical study on image bag generators for multi-instance learning
-
- 1.基本信息
- 2. 主要贡献
- 3.主要内容
-
- 3.1.图像多示例包生成器
- 3.2.按是否分类语义分类
- 3.3.Row, SB and SBN
- 3.4.Blobworld
- 3.5.k-meansSeg
- 3.6.WavSeg
- 3.7.JSEG-bag
- 3.8.Local binary patterns(LBP)
- 3.9.Scale invariant feature transform (SIFT)
- 4.总结
1.基本信息
@article{wei2016empirical,
title={An empirical study on image bag generators for multi-instance learning},
author={Wei, Xiu-Shen and Zhou, Zhi-Hua},
journal={Machine learning},
volume={105},
number={2},
pages={155--198},
year={2016},
publisher={Springer}
}
2. 主要贡献
周老师在这篇文章中主要介绍了九种主流的图像多示例包的生成器,以及对这些包生成器的效用进行实证研究。通过6923个(9个袋发生器,7个学习算法,4个补丁大小和43个数据集)配置的实验中,他们得到了两个重要的新发现:(1)具有密集抽样策略的袋发生器的性能优于其他策略;(2)学习算法的标准MIL假设并不适用于图像分类任务。
3.主要内容
我读这篇文章主要了解当前主流的多示例包生成器的构成,而后面的实验部分却并不是我关注的,所以便没有去了解。
3.1.图像多示例包生成器
在多示例学习中,主要处理的数据对象是多示例包,一种由多个实例组成的集合数据。所以在实际的实践中,对于原始数据,我们需要使用包生成器来将图片或文本数据转化成多示例数据,用以后续的多示例算法。值得注意的是,包发生器不同于特征提取过程;也就是说,包生成器决定如何用一组补丁来表示图像,而特征提取过程决定如何用特征向量来描述每个补丁。由于将一个数据对象表示为多个实例有许多不同的方法,因此包生成器对MIL学习性能至关重要。周老师对此主要研究了不同的多示例包在那种算法上的应用效果是最好的。此外,周老师还提到,像miGraph、MIBoosting和miFV等算法强调MIL包中实例之间的关系,它们不采用标准的MIL假设(即,如果包中至少包含一个阳性实例,则标记为阳性,否则标记为阴性),而这些学习算法却获得更好的分类准确率,周老师说可能原因是这几个算法没有假设包中实例是独立同分布的,因为现实中的数据很少是符合独立同分布的。同时还分析了这些包发生器在不同类型的图像分类任务中的效用,即场景分类和目标分类。
3.2.按是否分类语义分类
根据包生成器能否区分图像的语义成分,图像包生成器可分为两类,即非分割包生成器和分割包生成器。非分割包生成器采用一种独立于图像结构的固定策略从图像中提取实例,如Row、SB和SBN。而分割包生成器试图将一幅图像分割成多个语义组件,并用一个实例表示一个对应的语义组件来构造MIL包,Blobworld、k-meansSeg、WavSeg和JSEG-bag。
3.3.Row, SB and SBN
这三个包生成器均是 由Maron and Ratan在2001年提出的。这三个包生成器均是借助RGB色彩空间来对图像进行处理。
Row
如图1(a),这个生成器对于8 × 8滤波后的图像,包的构造如下:对于每一行,用该行的平均颜色和其上下行的平均色差构造一个实例。
SB
SB是Single Blob with no neighbors(没有邻居的单个斑点)的缩写。如图1(b),该方法下每一个实例都是一个2*2大小的斑点,而且采用的是不重叠的覆盖方法,相邻的斑点没有重复区域。
SBN
SBN是SB的修改版,即Single Blob with Neighbors(有邻居的单个斑点)的缩写。它考虑了相邻的斑点之间的关系。如图1©,每一个实例构造为一个2*2大小的斑点,包含其颜色平均值以及其与周围相邻的四个斑点的颜色差值。除了考虑相邻斑点,其还采用了重叠滑动窗口采样的方式如图2所示。此外,还有一个值得注意的点是如图1©右上角,这个位置的图像SBN无法采集到,存在图像盲区,而SB便没有这个缺点。

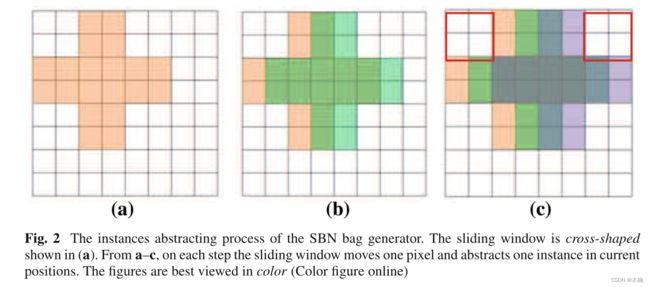
3.4.Blobworld
该算法是工作在L*a*b*的色彩空间中,它首先提取每个图像像素的颜色特征,采用色彩空间中的三维描述符进行描述。其次,从灰度图像中提取纹理特征,得到纹理的各向异性、对比度和极性。到目前为止,给定像素的颜色/纹理描述符由6个值组成:3个用于颜色,3个用于纹理。在第三步中,我们将像素的(x, y)位置附加到之前的特征向量上。Blobworld在获得8维像素特征后,通过混合高斯模型对像素特征分布进行建模,将像素分组。为了将这些像素分组,它使用期望-最大化(EM)算法估计K个高斯分量的混合物的极大似然参数。最后,Blobworld为MIL算法描述了每个区域的颜色分布和纹理,即图像中每个区域的表示是一个包中的一个实例。Blobworld处理的各个阶段如图所示。

3.5.k-meansSeg
在k-meansSeg中,图像在YCbCr颜色空间3中执行,而不进行任何预处理。该算法将一个4*4的图像块作为一个补丁,用一个六维向量表示,前三个维度是这16 (4 × 4)像素的三个颜色分量的平均值,后三个维度由HL、LH和HH三个子带组成,这些子带由亮度(Y)分量上的daubecies -4小波变换得到。则第i个原始图像斑点表示为:
| Y i Y_i Yi | C b i Cb_i Cbi | C r i Cr_i Cri | H L ( Y ) i HL(Y)_i HL(Y)i | L H ( Y ) i LH(Y)_i LH(Y)i | H H ( Y ) i HH(Y)_i HH(Y)i |
|---|
然后,利用K均值分割算法对这些六维向量进行分割,将图像分割为K个段,一个段对应一个实例。在该方法开始时,将未知参数K设为2,然后通过循环增加,直到其停止条件终止。最后,将表示第i段中所有斑点的所有六维向量的平均值计算为
b a g = { { m e a n ( Y i j ) , m e a n ( C b i j ) , m e a n ( C r i j ) , m e a n ( H L ( Y ) i j ) , m e a n ( L H ( Y ) i j ) , m e a n ( H H ( Y ) i j ) } ∣ i = 1 , 2 , … K } bag = \{\{mean(Y_{ij}), mean(Cb_{ij}), mean(Cr_{i j}), mean(HL(Y)_{i j}),\\ mean(L H(Y)_{i j}), mean(H H(Y)_{i j})\}| i = 1,2,…K \} bag={{mean(Yij),mean(Cbij),mean(Crij),mean(HL(Y)ij),mean(LH(Y)ij),mean(HH(Y)ij)}∣i=1,2,…K}
其中K是图像分割的段数,j是第i段的第j个斑点。
3.6.WavSeg
Zhang等人(2004)提出了WavSeg包生成器,可以在MIL包(图像)中自动构造多个实例(区域)。WavSeg主要涉及小波分析和并行分割和类参数估计(SPCPE)算法。
第一步,对图像进行daubecies -1小波变换预处理。
小波变换后,高频分量在更大的子带中消失,可能的区域清晰可见。然后对每个通道的显著点进行分组,得到一个初始粗分区,并将其作为SPCPE分割算法的输入。通过实验证明使用小波变化可以获得更好的分割结果,此外,它可以产生其他有用的特征,如纹理特征。
第二,WavSeg提取每个图像区域的局部颜色和局部纹理特征。
在提取颜色特征时,他们使用基于HSV颜色空间的HSV值范围(这些范围共有13种代表颜色)的颜色分类对颜色空间进行量化。
对于区域的纹理特征,daubecies -1变换可以在原始图像的HL、LH和HH三个频段生成三张对应的图像。对上述三个波段的小波系数分别采集均值和方差值。
最终,每个图像区域便形成6个纹理特征。
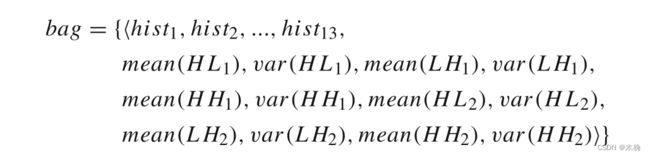
3.7.JSEG-bag
-
JSEG算法
Deng和Manjunath(2001)提出了JSEG图像分割算法,用于图像和视频中颜色纹理区域的无监督分割。该方法包括两个独立的步骤:颜色量化和空间分割。在第一步中,图像中的颜色被量化为几个有代表性的类,可以用来区分图像中的区域。这种量化只在颜色空间中执行,而不考虑空间分布。然后将图像像素颜色替换为对应的颜色类标签,从而形成图像的类图。第二步是在图像的类图上进行空间分割。
-
JSEG-bag
在JSEG-bag中,它首先用JSEG算法分割图像。然后按照区域面积递减的顺序从分割后的图像中选取最上面的k个区域。注意,在我们的实验中,我们将k的不同值设为2、6和10。JSEG-bag的第三步是计算每个区域的R、G、B颜色平均值。最后,将图像转换为对应的由k个三维特征向量(实例)组成的图像袋。其分割结果如图6(g)所示。
3.8.Local binary patterns(LBP)
局部二值模式(LBP) (Ojala et al, 2002)是一种局部描述符,它捕获像素周围小邻域内图像的外观。LBP是一串位,邻域中的每个像素对应一个位。每个位的开关取决于对应像素的强度是否大于中心像素的强度。通常,这些二进制字符串被合并到局部直方图中,而不是直接使用二进制字符串。周老师实验时用的LBP是来自开源库VLFeat。在VLFeat中,它只实现3x3像素的邻域的处理,其运行过程如图4所示,处理3*3像素的区域,以中心像素为对比对象,比较周围8个像素与中心的亮度,大于中心的编码为1,小于中心的像素编码为0。最终按逆时针方向从右上角开始组成一个8位的字符串。故一共便有256种编码。
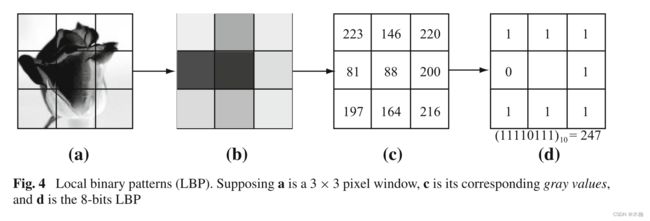
在实践中,根据统一模式(Heikkilä和Pietikäinen 2006)将256个模式进一步量化为58个量化模式。将量化后的LBP模式进一步分组为局部直方图。在我们的实验中,我们划分了一个40 × 40像素窗口的图像。然后,通过沿两个空间维度的双线性插值,将每个窗口的量化lbp聚合成一个直方图。故一个240 × 360图像的LBP共有54 ((240/40)× (360/40) = 6 × 9)个实例,58个维度。
3.9.Scale invariant feature transform (SIFT)
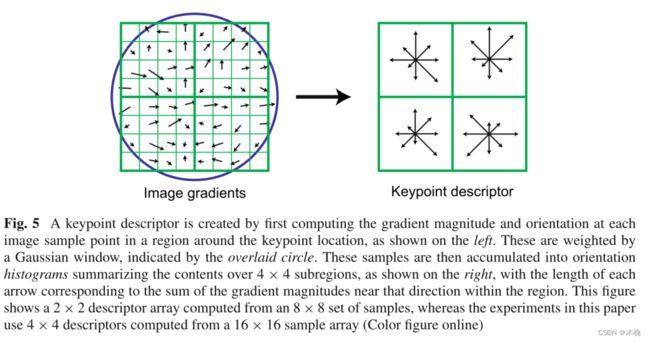
尺度不变特征变换(SIFT)特征(Lowe 2004)是描述图像关键点外观的图像梯度的三维空间直方图。计算SIFT描述符的第一件事是提取SIFT关键点。采集N个SIFT关键点,如图5所示,对于每个SIFT关键点,我们计算图像补丁中每个图像样本点的梯度幅值和方向。这些样本通过梯度范数进行加权,累积成三维直方图h,形成图像补丁的SIFT描述符。另外还应用了一个高斯加权函数,使远离关键点中心的梯度不那么重要。方位被量化为8个箱子,空间坐标分别为4个。因此,得到的SIFT描述符的维数为128 (8 bins×4×4 = 128个容器)。
注意,图5只是显示了一个从8 × 8的样本集计算出来的2 × 2描述符数组。
因此,由SIFT生成的包包含128维的N个实例。
4.总结
Row, SB和SBN是三种只提取颜色特征的非分割包生成器。他们使用固定的策略将原始图像分割成多个区域,这可能会将物体分成几个部分。对于SBN来说可能是不利的:它的重叠策略可能会使原始图像中的一个对象(bags)多次出现在多个区域(instance)中,根据实验的结果,这似乎是有问题的。
Blobworld, k-meansSeg, WavSeg和JSEG-bag是分割包生成器。它们的相似之处在于,它们首先将原始图像分割成多个区域(实例),然后提取特征来呈现每个局部区域。其中的不同之处在于它们不同的细分方法。Blobworld和k-meansSeg首先提取像素级或blob级特征。之后,他们将这些像素或blobs聚类到几个区域(实例),即Blobworld的高斯混合模型和k-meansSeg的k-means。
最后,对于每个区域,他们计算同一区域内像素或斑点特征的平均值作为该区域的特征。WavSeg和JSEG-bag分别采用SPCPE和JSEG分割算法对原始图像进行分割。这两种方法的最后一步是从多个区域提取特征。简而言之,k-meansSeg和WavSeg包含了每个区域的颜色和纹理信息,除此之外,Blobworld还包含了空间信息。然而,JSEG-bag只有颜色信息。图6便是各种算法运行结果。
而对于两个局部描述符算法LBP和SIFT,它们都计算图像(包)中本地区域(实例)的基于直方图的特征。重要的是它们都处理灰度图像,因此它们的局部特征(即LBP的比特串和SIFT的梯度分布)只包含纹理信息,不包含任何颜色信息。
此外,从采样策略来看,可以明显发现SB、SBN和LBP样本密集斑块/区域在袋中构造实例。然而,SIFT描述符(实例)只是基于SIFT检测器检测到的关键点,而不是从原始图像中采样密集的局部区域。此外,其他包生成器只将图像段作为实例处理。