Transformer-Attention Is All You Need阅读笔记
目录
- 前言
- 摘要
- 背景
- Transformer简介
- 结构
- encoder和decoder的工作方式
- 注意力
-
- Scaled Dot-Product Attention
- Multi-head attention
- 局限性
- 数据集及结果
- 总结
前言
之所以读这篇文章,是看到了公众号发的一篇文章,介绍了OpenAI最新发布的连接文本与图像的CLIP模型。该模型可以通过自然语言监督有效地学习视觉概念。只需提供要识别的视觉类别的名称,即可将CLIP应用于任何视觉分类基准,类似于GPT-2和GPT-3的“零镜头”功能。
CLIP使用了使用了Transformer、VirTex(探索自然回归语言建模)和 ConVIRT(研究掩蔽语言建模)的架构。因此,为了更好的学习CLIP,计划先从Transformer开始阅读学习。
论文链接: [Attention is all you need]
源码地址:Transformer
摘要
- Transformer是NLP中的模型,改变了处理文本数据的方式
- Transformer支持NLP的最新发展,包括Goole的BERT
- PyTorch-Transformers是一个最先进的自然语言处理预训练模型库,目前包含PyTorch实现、预训练的模型权重、使用脚本和用于BERT、GPT、GPT-2、Transformer-XL、XLNet、XLM 模型的转换工具
背景
序列到序列(通常简称为seq2seq)模型是一类特殊的递归神经网络体系结构,常用于将A类型序列转换为B类型序列。目前大多数数据都是序列形式,如数字序列、视频帧序或音频序列。这些序列到序列模型可以用于各种NLP任务,如机器翻译、文字摘要、语音识别和问题解答系统等。

图1
如图1 所示,这是一个德语转化为英语的seq2seq模型,两个两个编码器和解码器是RNNs。
这个体系结构存在与长度关的缺点:
- 这种架构内存有限,处理远程依赖关系能力还有待提高
- 对于递归神经网络,序列越长,随时间维度的神经网络越深,将导致梯度消失
- 模型的体系结构顺序性质阻碍了并行化
Transformer简介
Transformer是由谷歌提出的,一种解决序列到序列任务,同时能处理远程依赖性的新的体系结构。这个结构在论文“Attention is all you need"中进行了介绍。
该文章没有采取RNN/LSTM/GRU的结构,而是使用注意力层和全连接层,达到了较好的效果,也解决了seq2seq模型的远程依赖问题。同时也解决了训练并行度的问题,降低了计算复杂度。
结构
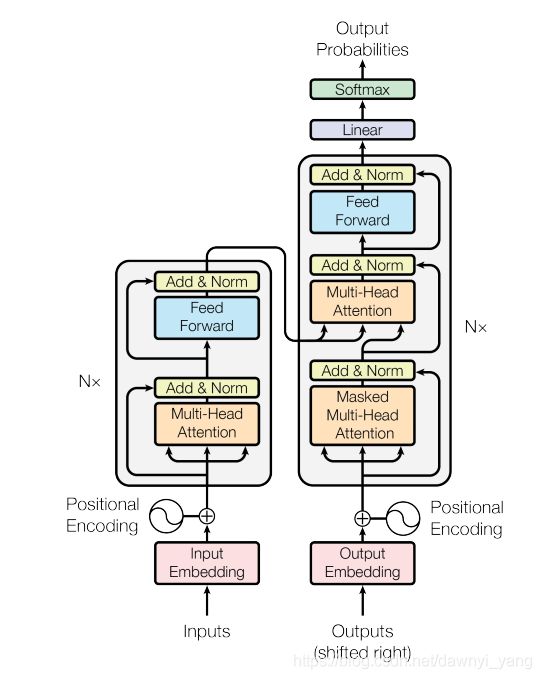
图2
图2是该篇论文提出的Transformer结构,主要由encoder编码器和decoder解码器组成。
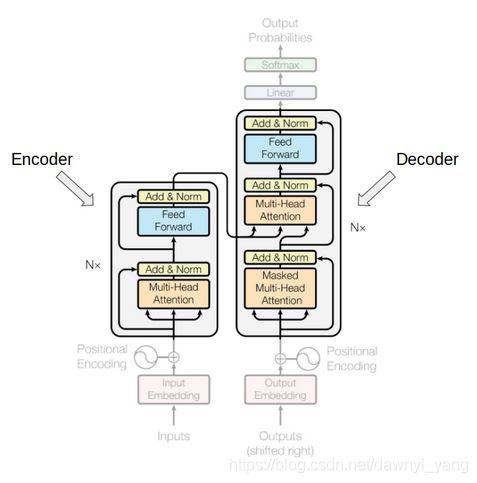
图3
如图3所示,右边是encoder编码器,左边是decoder解码器。
对于encoder解码器,有N(6)个一样的层,每一层包括一个多头注意力层和一个简单的全连接层,还包括一个残差链接。
对于decoder解码器,也有N(6)个一样的层,包括自注意力层,编码-解码注意力层和一个全连接层,前两个层是基于多头注意力层。
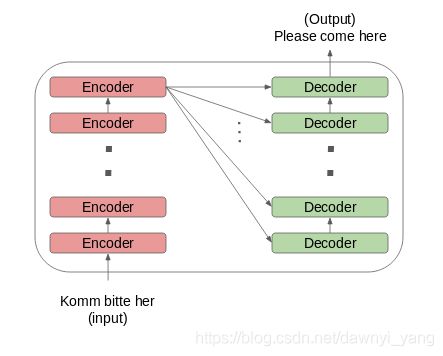
图4
encoder编码器和decoder解码器块实际上是彼此堆叠的多个相同的编码器和解码器。编码器堆栈和解码器堆栈都具有相同数量的单元,如图4。
编码器和解码器单元的数量是一个超参数。在论文中,使用了6种编码器和解码器。
encoder和decoder的工作方式
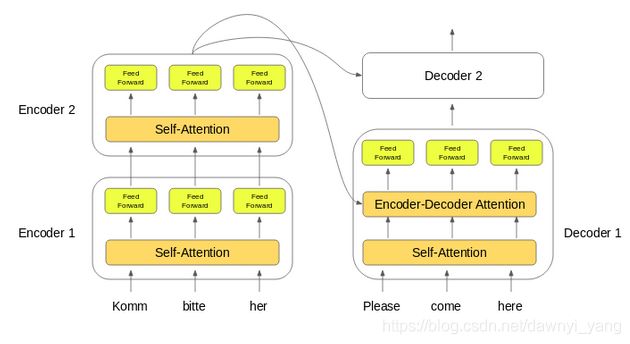
图5
如图5所示,首先输入序列的单词嵌入传递给第一个编码器,然后将它们转换并传播到下一个编码器。最后一个编码器的输出则传入所有的解码器。
解码器中的编码器-解码器注意力层有助于专注输入序列合适的部分。
注意力
“注意力函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出作为值的加权和进行计算,其中分配给每个值的权重由查询与相应键的兼容函数计算。”
文章中介绍了Scaled Dot-Product Attention和Multi-Head Attention。
Scaled Dot-Product Attention

图6
输入包括:维度为 d k d_k dk的quary vector和key vecotrs,以及维度为 d v d_v dv的Value Vector。通过数学表达式: A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V)=softmax(\frac{QK^T}{\sqrt{ d_k})V} Attention(Q,K,V)=softmax(dk)VQKT来计算。
Multi-head attention
因为scaled dot-product attention看起来还有点简单, 网络的表达能力较简单,所以提出了multi-head attention多头注意力机制。
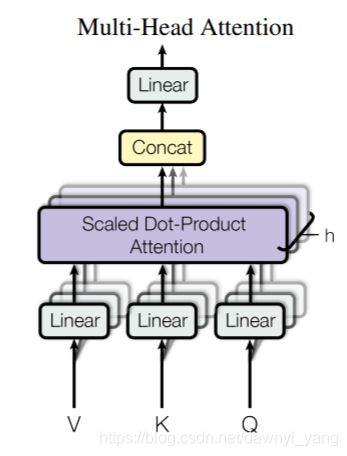
图7
在执行自注意力计算之前通过一个linear project的矩阵,投影到维度num_head ∗ ( d q , d k , d c ) *(d_q,d_k,d_c) ∗(dq,dk,dc)上,多次并行、独立的计算自注意力,输出被串联并进行线性转换,如图7。计算公式如下:
M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . h e a d h ) W O w h e r e h e a d i = A t t e n t i o n ( Q W i Q , K W i K , V W i v ) MultiHead(Q,K,V)=Concat(head_1,...head_h)W^O where head_i=Attention(QW^Q_i,KW^K_i,VW^v_i) MultiHead(Q,K,V)=Concat(head1,...headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiv)
这里的计算复杂度为: n 2 ∗ d + n ∗ d 2 n^2*d+n*d^2 n2∗d+n∗d2,n为序列长度,d为word representation dimension。
局限性
相较于基于RNN的seq2seq模型相比,Transformer是一个巨大的改进。但是也有一定的局限性:
- 只能处理固定长度的文本字符串,在将文本作为输入输入系统之前,必须将其分成一定数量的段或块
- 文本的这种分块会导致上下文碎片。例如,如果将句子从中间分开,则将丢失大量上下文。换句话说,在不考虑句子或任何其他语义边界的情况下拆分文本
Transformer-XL克服了这些缺点,这里暂不展开。
数据集及结果
文章使用了标准 WMT 2014 English-German 数据集,在有8 NVIDIA P100 GPUs的机器上训练,得到了较好的结果,如图8.
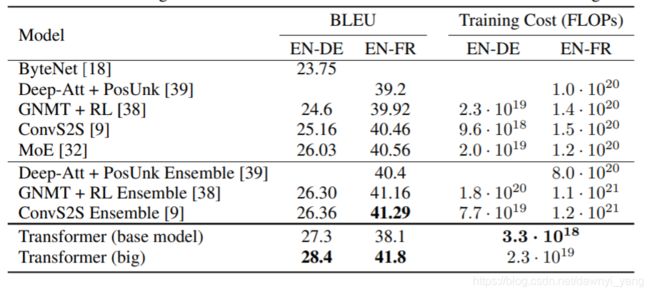
图8
在标准 WMT 2014 English-German 数据集上,Transformer(big)获得了41.0的BLEU分数,优于以前发布的模型, 训练成本不超过之前的 1 4 \frac{1}{4} 41。且模型损失率为0.1.
总结
该模型提出了完全基于注意的序列转换模型Transformer,用多头自注意力取代了编码-解码结构中最常用的递归层。且Transformer的训练速度比基于循环层和卷积层的结果要快的多。