基于keras的残差网络实现——以fashion mnist数据集分类为例
基于keras的残差网络实现——以fashion mnist数据集分类为例
- 前言
- 残差网络
-
- 残差块
- 残差网络
- fashion-mnist数据集
- 代码实现
- 结果展示
-
- 模型结构
- 预测结果
- 参考
前言
最近在学习残差网络的相关内容,并且尝试使用keras搭建自己的残差网络来完成一些深度学习任务,下面是这几天的学习成果。
残差网络
一般来说,越深的神经网络对于数据的特征抽取与识别会表现得更好,但同时,也会面临梯度消失或者梯度爆炸的现象。因此Kaiming He等人在论文《Deep residual Learning for Image Recognition》中提出了残差网络结构,有效的解决了网络加深后的梯度消失或者梯度爆炸现象,并且在残差网络中使用小卷积核使得模型训练的计算量大幅度减少。
残差块
残差网络的基本单元是残差块,如下图。

它由两部分组成:直连部分和捷径部分。数据在直连部分通过几个权重层,我用代码实现时使用的是卷积层(无偏置),因此直连部分的输出的形状与输入的形状是不同的无法直接相加。因此在捷径部分,还需要数据通过一个卷积核为11的卷积层。卷积核为11的卷积层可以可以改变数据的depth维度也即通道数。当然,我在直连部分也使用了两个卷积核为1*1的卷积层,用来控制数据的depth维度,使两个部分可以相加。
残差网络
上面简单讲述了一下残差块,其实残差块有相当多的变种,有时也需要根据不同的分类任务做不同的尝试。下图是我的代码里使用的残差块结构:

基于残差块的结构搭建残差网络,下图是论文原文中提供的34层结构的残差神经网络(右一)与其他神经网络的对比。

残差神经网络与其他结构有着很大的不同,并且在参数量上也有非常大的区别。例如左一的VGG16模型,就有着约169亿的参数需要训练,而右边两个模型需要训练的参数量只有约36亿。除此之外,就识别效果来看,残差神经网络也有着极大的优越性,单纯的卷积神经网络结构对fashion mnist数据集的识别准确率只有约91%,并且训练速度很慢。而残差神经网络则轻松超过了92%。我所搭建的只有四个简单残差块的残差神经网络在迭代十几轮后就轻松超过了92%。尽管之后训练很难再有所增加,但这无疑彰显了残差神经网络的优越性。
fashion-mnist数据集
FashionMNIST 是一个替代 MNIST 手写数字集的图像数据集。 它是由 Zalando(一家德国的时尚科技公司)旗下的研究部门提供。其涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。如下图:
FashionMNIST 的大小、格式和训练集/测试集划分与原始的 MNIST 完全一致。60000/10000 的训练测试数据划分,28x28 的灰度图片。相比较于手写数字训练集,该数据集具有更佳的测试性。手写数字在大部分的模型上上都能取得非常好的分类效果,很多甚至超过99%,包括一些常规的机器学习模型,因此难以区分他们的性能。
调用方式跟手写数字集一样,而且在keras中集成了该数据集。
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
代码实现
下面展示代码,我使用的是jupyter notebook写的代码所以有需要的话可以自己复制到一个文件中运行。
1、首先导入所需要的库:
import datetime
import tensorflow as tf
import numpy as np
import keras
from keras.layers import Input, Conv2D, AveragePooling2D, BatchNormalization, Activation, Add, Flatten, Dense, Dropout
from keras.models import Model
from keras.callbacks import ModelCheckpoint, TensorBoard
2、定义权重块方便调用,这里使用的是卷积:
def conv(channels, strides=1, kernel_size=(3, 3), padding='same'):
#定义卷积权重块
return Conv2D(filters=channels, kernel_size=kernel_size, strides=strides, padding=padding,
use_bias=False, kernel_initializer=tf.random_normal_initializer())
3、定义残差块,模型图示在前面有提及:
def res_block(inputs, base_channels):
'''定义残差块'''
#捷径部分
residual = inputs
residual = BatchNormalization()(residual)
residual = Activation('relu')(residual)
residual = conv(channels=base_channels, kernel_size=(1, 1))(residual)
#直连部分
x = conv(channels=base_channels, kernel_size=(1, 1))(inputs)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = conv(channels=base_channels*2, strides=1, kernel_size=(3, 3))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = conv(channels=base_channels, kernel_size=(1, 1))(x)
outputs = Add()([x, residual])
return Activation('relu')(outputs)
4、定义残差网络,有四个残差块,输出部分加入了平均池化层、平铺层和全连接层:
def ResNet(input_shape, base_channels, classes):
'''定义残差网络'''
inputs = Input(shape=input_shape)
x = conv(channels=base_channels, strides=2, kernel_size=(3, 3))(inputs)
x = res_block(x, base_channels=base_channels)
x = res_block(x, base_channels=base_channels*2)
x = res_block(x, base_channels=base_channels*2)
x = res_block(x, base_channels=base_channels*4)
x = AveragePooling2D()(x)
x = Flatten()(x)
x = Dense(512, activation='relu')(x)
outputs = Dense(classes,activation='softmax')(x)
model = Model(inputs=inputs, outputs=outputs)
return model
5、准备数据集,并进行预处理:
#准备数据集
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
#数据标准化
x_train, x_test = x_train.astype(np.float32)/255., x_test.astype(np.float32)/255.
#数据整形[None, 28, 28] => [None, 28, 28, 1]
x_train, x_test = np.expand_dims(x_train, axis=3), np.expand_dims(x_test, axis=3)
#标签改为独热编码
y_train_one = tf.one_hot(y_train,depth=10).numpy()
y_test_one = tf.one_hot(y_test,depth=10).numpy()
print(x_train.shape, y_train_one.shape)
print(x_test.shape, y_test_one.shape)
6、定义一些超参数:
#类别数
num_classes = 10
#批大小
batch_size = 32
#迭代次数
epochs = 30
#学习率
learning_rate = 0.001
#输入形状
input_shape = (28, 28, 1)
# 项目目录
project_path = "E:\\resnet\\"
# 定义日志目录,必须是启动web应用时指定目录的子目录,建议使用日期时间作为子目录名
log_dir = project_path + "logs\\" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
model_path = project_path + "model_best.h5"
7、载入模型,设置loss函数,打印模型:
model = ResNet(input_shape=input_shape, base_channels=16, classes=10)
model.compile(optimizer=keras.optimizers.adam_v2.Adam(learning_rate=learning_rate),
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
8、训练模型,保存日志,设置自动保存最佳模型:
#设置tensorboard
tensorboard_callback = TensorBoard(log_dir=log_dir, histogram_freq=1)
#设置检查点
checkpoint = ModelCheckpoint(filepath=model_path, monitor='val_accuracy', verbose=1, save_best_only=True, mode='max')
#训练
model.fit(x_train, y_train_one,
batch_size=batch_size,
epochs=epochs,
validation_data=(x_test, y_test_one),
callbacks=[tensorboard_callback, checkpoint],
verbose=1)
#评估
scores = model.evaluate(x_test, y_test_one,batch_size=batch_size,verbose=1)
print("最后损失值以及准确率:",scores)
9、画出一些图片进行展示:
import matplotlib.pyplot as plt
#标签对应字典
name_dict = {0: 't-shirt',1: 'trouser',2: 'pullover',3: 'dress',4: 'coat',
5: 'sandal',6: 'shirt',7: 'sneaker',8: 'bag',9: 'ankle boot'}
#绘制结果
model_best = keras.models.load_model('model_best.h5')
plot_image = x_test[10:20]
print(plot_image.shape)
predict_label = np.argmax(model_best.predict(plot_image), axis=1)
true_label = np.argmax(y_test_one[10:20], axis=1)
plot_image = np.reshape(plot_image, (10, 28, 28))
plt.figure(figsize=(25,10))
plt.suptitle('true/predict')
for i in range(1, 11):
plt.subplot(2, 5, i)
plt.imshow(plot_image[i-1])
plt.axis('off')
plt.title(name_dict[true_label[i-1]]+'/'+name_dict[predict_label[i-1]])
plt.show()
结果展示
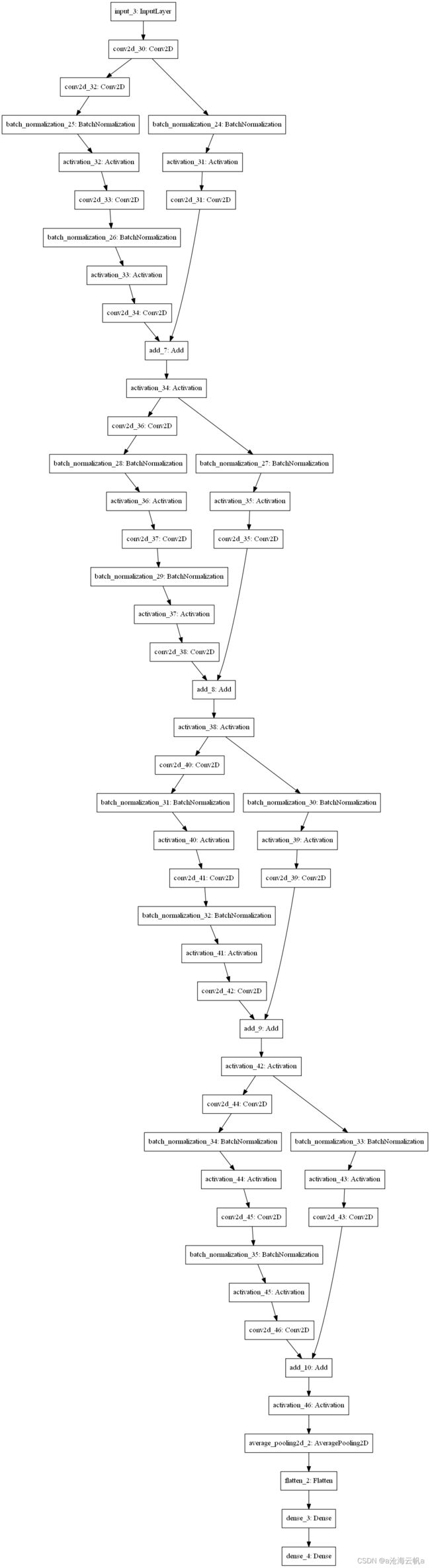
模型结构
使用model.summary()打印的模型结构如下:
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_3 (InputLayer) [(None, 28, 28, 1)] 0
__________________________________________________________________________________________________
conv2d_30 (Conv2D) (None, 14, 14, 16) 144 input_3[0][0]
__________________________________________________________________________________________________
conv2d_32 (Conv2D) (None, 14, 14, 16) 256 conv2d_30[0][0]
__________________________________________________________________________________________________
batch_normalization_25 (BatchNo (None, 14, 14, 16) 64 conv2d_32[0][0]
__________________________________________________________________________________________________
activation_32 (Activation) (None, 14, 14, 16) 0 batch_normalization_25[0][0]
__________________________________________________________________________________________________
conv2d_33 (Conv2D) (None, 14, 14, 32) 4608 activation_32[0][0]
__________________________________________________________________________________________________
batch_normalization_26 (BatchNo (None, 14, 14, 32) 128 conv2d_33[0][0]
__________________________________________________________________________________________________
batch_normalization_24 (BatchNo (None, 14, 14, 16) 64 conv2d_30[0][0]
__________________________________________________________________________________________________
activation_33 (Activation) (None, 14, 14, 32) 0 batch_normalization_26[0][0]
__________________________________________________________________________________________________
activation_31 (Activation) (None, 14, 14, 16) 0 batch_normalization_24[0][0]
__________________________________________________________________________________________________
conv2d_34 (Conv2D) (None, 14, 14, 16) 512 activation_33[0][0]
__________________________________________________________________________________________________
conv2d_31 (Conv2D) (None, 14, 14, 16) 256 activation_31[0][0]
__________________________________________________________________________________________________
add_7 (Add) (None, 14, 14, 16) 0 conv2d_34[0][0]
conv2d_31[0][0]
__________________________________________________________________________________________________
activation_34 (Activation) (None, 14, 14, 16) 0 add_7[0][0]
__________________________________________________________________________________________________
conv2d_36 (Conv2D) (None, 14, 14, 32) 512 activation_34[0][0]
__________________________________________________________________________________________________
batch_normalization_28 (BatchNo (None, 14, 14, 32) 128 conv2d_36[0][0]
__________________________________________________________________________________________________
activation_36 (Activation) (None, 14, 14, 32) 0 batch_normalization_28[0][0]
__________________________________________________________________________________________________
conv2d_37 (Conv2D) (None, 14, 14, 64) 18432 activation_36[0][0]
__________________________________________________________________________________________________
batch_normalization_29 (BatchNo (None, 14, 14, 64) 256 conv2d_37[0][0]
__________________________________________________________________________________________________
batch_normalization_27 (BatchNo (None, 14, 14, 16) 64 activation_34[0][0]
__________________________________________________________________________________________________
activation_37 (Activation) (None, 14, 14, 64) 0 batch_normalization_29[0][0]
__________________________________________________________________________________________________
activation_35 (Activation) (None, 14, 14, 16) 0 batch_normalization_27[0][0]
__________________________________________________________________________________________________
conv2d_38 (Conv2D) (None, 14, 14, 32) 2048 activation_37[0][0]
__________________________________________________________________________________________________
conv2d_35 (Conv2D) (None, 14, 14, 32) 512 activation_35[0][0]
__________________________________________________________________________________________________
add_8 (Add) (None, 14, 14, 32) 0 conv2d_38[0][0]
conv2d_35[0][0]
__________________________________________________________________________________________________
activation_38 (Activation) (None, 14, 14, 32) 0 add_8[0][0]
__________________________________________________________________________________________________
conv2d_40 (Conv2D) (None, 14, 14, 32) 1024 activation_38[0][0]
__________________________________________________________________________________________________
batch_normalization_31 (BatchNo (None, 14, 14, 32) 128 conv2d_40[0][0]
__________________________________________________________________________________________________
activation_40 (Activation) (None, 14, 14, 32) 0 batch_normalization_31[0][0]
__________________________________________________________________________________________________
conv2d_41 (Conv2D) (None, 14, 14, 64) 18432 activation_40[0][0]
__________________________________________________________________________________________________
batch_normalization_32 (BatchNo (None, 14, 14, 64) 256 conv2d_41[0][0]
__________________________________________________________________________________________________
batch_normalization_30 (BatchNo (None, 14, 14, 32) 128 activation_38[0][0]
__________________________________________________________________________________________________
activation_41 (Activation) (None, 14, 14, 64) 0 batch_normalization_32[0][0]
__________________________________________________________________________________________________
activation_39 (Activation) (None, 14, 14, 32) 0 batch_normalization_30[0][0]
__________________________________________________________________________________________________
conv2d_42 (Conv2D) (None, 14, 14, 32) 2048 activation_41[0][0]
__________________________________________________________________________________________________
conv2d_39 (Conv2D) (None, 14, 14, 32) 1024 activation_39[0][0]
__________________________________________________________________________________________________
add_9 (Add) (None, 14, 14, 32) 0 conv2d_42[0][0]
conv2d_39[0][0]
__________________________________________________________________________________________________
activation_42 (Activation) (None, 14, 14, 32) 0 add_9[0][0]
__________________________________________________________________________________________________
conv2d_44 (Conv2D) (None, 14, 14, 64) 2048 activation_42[0][0]
__________________________________________________________________________________________________
batch_normalization_34 (BatchNo (None, 14, 14, 64) 256 conv2d_44[0][0]
__________________________________________________________________________________________________
activation_44 (Activation) (None, 14, 14, 64) 0 batch_normalization_34[0][0]
__________________________________________________________________________________________________
conv2d_45 (Conv2D) (None, 14, 14, 128) 73728 activation_44[0][0]
__________________________________________________________________________________________________
batch_normalization_35 (BatchNo (None, 14, 14, 128) 512 conv2d_45[0][0]
__________________________________________________________________________________________________
batch_normalization_33 (BatchNo (None, 14, 14, 32) 128 activation_42[0][0]
__________________________________________________________________________________________________
activation_45 (Activation) (None, 14, 14, 128) 0 batch_normalization_35[0][0]
__________________________________________________________________________________________________
activation_43 (Activation) (None, 14, 14, 32) 0 batch_normalization_33[0][0]
__________________________________________________________________________________________________
conv2d_46 (Conv2D) (None, 14, 14, 64) 8192 activation_45[0][0]
__________________________________________________________________________________________________
conv2d_43 (Conv2D) (None, 14, 14, 64) 2048 activation_43[0][0]
__________________________________________________________________________________________________
add_10 (Add) (None, 14, 14, 64) 0 conv2d_46[0][0]
conv2d_43[0][0]
__________________________________________________________________________________________________
activation_46 (Activation) (None, 14, 14, 64) 0 add_10[0][0]
__________________________________________________________________________________________________
average_pooling2d_2 (AveragePoo (None, 7, 7, 64) 0 activation_46[0][0]
__________________________________________________________________________________________________
flatten_2 (Flatten) (None, 3136) 0 average_pooling2d_2[0][0]
__________________________________________________________________________________________________
dense_3 (Dense) (None, 512) 1606144 flatten_2[0][0]
__________________________________________________________________________________________________
dense_4 (Dense) (None, 10) 5130 dense_3[0][0]
==================================================================================================
Total params: 1,749,210
Trainable params: 1,748,154
Non-trainable params: 1,056
__________________________________________________________________________________________________
模型有约170万参数需要训练,删去模型中的后面的一个全连接层的参数量,整个模型只有十来万的参数需要训练,但准确率相比会有所降低。
模型图示如下:
预测结果
最终模型的准确率达到92.38%,并且仅迭代6次就达到了这样的效果。

但是后续在训练集的准确率还有提升。
下面是抽取测试集中的十张图片查看的预测类别,可以看到效果非常不错:

在之前测试的时候,第二行第三列的coat经常被识别为shirt,这个模型是唯一预测准确的。下面是一些预测错误的数据,可以看到很多图片肉眼都很难识别出来。
参考
详解残差网络
Fashion-MNIST:替代MNIST手写数字集的图像数据集
Keras入门与残差网络的搭建