NLP学习笔记-Seq2Seq实现聊天机器人(六)
Seq2Seq实现闲聊机器人
1. 准备训练数据
单轮次的聊天数据非常不好获取,所以这里我们从github上使用一些开放的数据集来训练我们的闲聊模型
数据地址:https://github.com/codemayq/chaotbot_corpus_Chinese
主要的数据有两个:
-
小黄鸡的聊天语料:噪声很大

-
微博的标题和评论:质量相对较高


2. 数据的处理和保存
由于数据中存到大量的噪声,可以对其进行基础的处理,然后分别把input和target使用两个文件保存,即input中的第N行尾问,target的第N行为答
后续可能我们可能会把单个字作为特征(存放在input_word.txt),也可能会把词语作为特征(input.txt)
2.1 小黄鸡的语料的处理
def format_xiaohuangji_corpus(word=False):
"""处理小黄鸡的语料"""
if word:
corpus_path = "./chatbot/corpus/xiaohuangji50w_nofenci.conv"
input_path = "./chatbot/corpus/input_word.txt"
output_path = "./chatbot/corpus/output_word.txt"
else:
corpus_path = "./chatbot/corpus/xiaohuangji50w_nofenci.conv"
input_path = "./chatbot/corpus/input.txt"
output_path = "./chatbot/corpus/output.txt"
f_input = open(input_path,"a")
f_output = open(output_path,"a")
pair = []
for line in tqdm(open(corpus_path),ascii=True):
if line.strip() == "E":
if not pair:
continue
else:
assert len(pair) == 2,"长度必须是2"
if len(pair[0].strip())>=1 and len(pair[1].strip())>=1:
f_input.write(pair[0]+"\n")
f_output.write(pair[1]+"\n")
pair = []
elif line.startswith("M"):
line = line[1:]
if word:
pair.append(" ".join(list(line.strip())))
else:
pair.append(" ".join(jieba_cut(line.strip())))
"""
准备闲聊语料
"""
import string
from lib import cut
from tqdm import tqdm
import config
def filter(pair):
"""
:param pair: pair[q, a] pari[0] = q, pair[1] = a
:return:
"""
if pair[0].lower() in list(string.ascii_lowercase):
return True
# 判断是否为=.=类型的表情, str/list.count(b),统计b的出现次数
elif pair[1].count('=')>2:
return True
def prepar_xiaohuangji(by_word = False):
path = r'E:\chatservice\corpus\classify\小黄鸡未分词.conv'
input_path = config.chatbot_input_path
target_path = config.chatbot_target_path
one_qa_pair = [] # 保存一个问答对,用于过滤答案为表情的问答对
num = 0 # 统计保存的问答对
f_input = open(input_path, 'a', encoding='UTF-8')
f_target = open(target_path, 'a', encoding='UTF-8')
"""
E
M 呵呵 # 问
M 是王若猫的。 # 答
"""
for line in tqdm(open(path, encoding='UTF-8').readlines(), desc = 'chatbot 小黄鸡语料'):
if line.startswith('E'):
continue
else:
# 取M 后面的内容
line = line[1:].strip().lower()
# 进行分词
line = cut(line, by_word = by_word)
if by_word:
line = ' '.join(line) + '\n'
else:
line = ''.join(line) + '\n'
if len(one_qa_pair) < 2:
one_qa_pair.append(line)
if len(one_qa_pair) == 2:
# 写入
# 判断是否是需要的句子
if filter(one_qa_pair):
continue
f_input.write(one_qa_pair[0])
f_target.write(one_qa_pair[1])
num += 1
one_qa_pair = []
f_input.close()
f_target.close()
return num
2.2 微博语料的处理
def format_weibo(word=False):
"""
微博数据存在一些噪声,未处理
:return:
"""
if word:
origin_input = "./chatbot/corpus/stc_weibo_train_post"
input_path = "./chatbot/corpus/input_word.txt"
origin_output = "./chatbot/corpus/stc_weibo_train_response"
output_path = "./chatbot/corpus/output_word.txt"
else:
origin_input = "./chatbot/corpus/stc_weibo_train_post"
input_path = "./chatbot/corpus/input.txt"
origin_output = "./chatbot/corpus/stc_weibo_train_response"
output_path = "./chatbot/corpus/output.txt"
f_input = open(input_path,"a")
f_output = open(output_path, "a")
with open(origin_input) as in_o,open(origin_output) as out_o:
for _in,_out in tqdm(zip(in_o,out_o),ascii=True):
_in = _in.strip()
_out = _out.strip()
if _in.endswith(")") or _in.endswith("」") or _in.endswith(")"):
_in = re.sub("(.*)|「.*?」|\(.*?\)"," ",_in)
_in = re.sub("我在.*?alink|alink|(.*?\d+x\d+.*?)|#|】|【|-+|_+|via.*?:*.*"," ",_in)
_in = re.sub("\s+"," ",_in)
if len(_in)<1 or len(_out)<1:
continue
if word:
_in = re.sub("\s+","",_in) #转化为一整行,不含空格
_out = re.sub("\s+","",_out)
if len(_in)>=1 and len(_out)>=1:
f_input.write(" ".join(list(_in)) + "\n")
f_output.write(" ".join(list(_out)) + "\n")
else:
if len(_in) >= 1 and len(_out) >= 1:
f_input.write(_in.strip()+"\n")
f_output.write(_out.strip()+"\n")
f_input.close()
f_output.close()
2.3 处理后的结果

3. 构造文本序列化和反序列化方法
和之前的操作相同,需要把文本能转化为数字,同时还需实现方法把数字转化为文本
# word_sequence.py
import config
import pickle
class Word2Sequence():
UNK_TAG = "UNK"
PAD_TAG = "PAD"
SOS_TAG = "SOS"
EOS_TAG = "EOS"
UNK = 0
PAD = 1
SOS = 2
EOS = 3
def __init__(self):
self.dict = {
self.UNK_TAG :self.UNK,
self.PAD_TAG :self.PAD,
self.SOS_TAG :self.SOS,
self.EOS_TAG :self.EOS
}
self.count = {}
self.fited = False
def to_index(self,word):
"""word -> index"""
assert self.fited == True,"必须先进行fit操作"
return self.dict.get(word,self.UNK)
def to_word(self,index):
"""index -> word"""
assert self.fited , "必须先进行fit操作"
if index in self.inversed_dict:
return self.inversed_dict[index]
return self.UNK_TAG
def __len__(self):
return len(self.dict)
def fit(self, sentence):
"""
:param sentence:[word1,word2,word3]
:param min_count: 最小出现的次数
:param max_count: 最大出现的次数
:param max_feature: 总词语的最大数量
:return:
"""
for a in sentence:
if a not in self.count:
self.count[a] = 0
self.count[a] += 1
self.fited = True
def build_vocab(self, min_count=1, max_count=None, max_feature=None):
# 比最小的数量大和比最大的数量小的需要
if min_count is not None:
self.count = {k: v for k, v in self.count.items() if v >= min_count}
if max_count is not None:
self.count = {k: v for k, v in self.count.items() if v <= max_count}
# 限制最大的数量
if isinstance(max_feature, int):
count = sorted(list(self.count.items()), key=lambda x: x[1])
if max_feature is not None and len(count) > max_feature:
count = count[-int(max_feature):]
for w, _ in count:
self.dict[w] = len(self.dict)
else:
for w in sorted(self.count.keys()):
self.dict[w] = len(self.dict)
# 准备一个index->word的字典
self.inversed_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transform(self, sentence,max_len=None,add_eos=False):
"""
实现吧句子转化为数组(向量)
:param sentence:
:param max_len:
:return:
"""
assert self.fited, "必须先进行fit操作"
r = [self.to_index(i) for i in sentence]
if max_len is not None:
if max_len>len(sentence):
if add_eos:
r+=[self.EOS]+[self.PAD for _ in range(max_len-len(sentence)-1)]
else:
r += [self.PAD for _ in range(max_len - len(sentence))]
else:
if add_eos:
r = r[:max_len-1]
r += [self.EOS]
else:
r = r[:max_len]
else:
if add_eos:
r += [self.EOS]
# print(len(r),r)
return r
def inverse_transform(self,indices):
"""
实现从数组 转化为 向量
:param indices: [1,2,3....]
:return:[word1,word2.....]
"""
sentence = []
for i in indices:
word = self.to_word(i)
sentence.append(word)
return sentence
#之后导入该word_sequence使用
word_sequence = pickle.load(open("./pkl/ws.pkl","rb")) if not config.use_word else pickle.load(open("./pkl/ws_word.pkl","rb"))
if __name__ == '__main__':
from word_sequence import Word2Sequence
from tqdm import tqdm
import pickle
word_sequence = Word2Sequence()
#词语级别
input_path = "../corpus/input.txt"
target_path = "../corpus/output.txt"
for line in tqdm(open(input_path).readlines()):
word_sequence.fit(line.strip().split())
for line in tqdm(open(target_path).readlines()):
word_sequence.fit(line.strip().split())
#使用max_feature=5000个数据
word_sequence.build_vocab(min_count=5,max_count=None,max_feature=5000)
print(len(word_sequence))
pickle.dump(word_sequence,open("./pkl/ws.pkl","wb"))
word_sequence.py
class Word_Sequence(object):
PAD_TAG = 'PAD' # 填充标记
UNK_TAG = 'UNK' # 未知词标记
SOS_TAG = 'SOS' # strat of sequence
EOS_TAG = 'EOS' # end of sequence
PAD = 0
UNK = 1
SOS = 2
EOS = 3
def __init__(self):
self.dict = {
self.PAD_TAG : self.PAD,
self.UNK_TAG : self.UNK,
self.SOS_TAG : self.SOS,
self.EOS_TAG : self.EOS
}
self.count = {} # 保存词频词典
def fit(self, sentence):
"""
传入句子,统计词频
:param sentence:
:return:
"""
for word in sentence:
# # 对word出现的频率进行统计,当word不在sentence时,返回值是0,当word在sentence中时,返回+1,以此进行累计计数
self.count[word] = self.count.get(word, 0) +1
def build_vocab(self, min_count = 2, max_count = None, max_features = None):
"""
构造词典典
:param min_count 最小词频
:param max_count 最大词频
:param max_features 词典中词的数量
:return:
"""
# self.count.pop(key),和del self.count[key] 无法在遍历self.count的同时进行删除key.因此浅拷贝temp后对temp遍历并删除self.count
temp = self.count.copy()
for key in temp:
cur_count = self.count.get(key, 0) # 当前词频
if min_count is not None:
if cur_count < min_count:
del self.count[key]
if max_count is not None:
if cur_count > max_count:
del self.count[key]
if max_features is not None:
self.count = dict(sorted(self.count.items(), key = lambda x : x[1], reverse = True)[:max_features])
for key in self.count:
self.dict[key] = len(self.dict)
self.inverse_dict = dict(zip(self.dict.values(), self.dict.keys()))
def transforms(self, sentence, max_len, add_eos = False):
"""
把sentence 转化为 序列
:param max_len 句子最大长度
:param add_eos 是否添加结束符
add_eos : True时,输出句子长度为max_len + 1
add_eos : False时,输出句子长度为max_len
:return:
"""
if len(sentence) > max_len:
sentence = sentence[:max_len]
sentence_len = len(sentence) # 提前计算句子长度,实现add_eos后,句子长度统一
# sentence[1,3,4,5,UNK,EOS,PAD,PAD....]
if add_eos:
sentence += [self.EOS_TAG]
if sentence_len < max_len:
# 句子长度不够,用PAD填充
sentence += (max_len - sentence_len) * [self.PAD_TAG]
# 对于新出现的词采用特殊标记
result = [self.dict.get(i, self.UNK) for i in sentence]
return result
def invert_transform(self, indices):
"""
序列转化为sentence
:param indices:
:return:
"""
# return [self.inverse_dict.get(i, self.UNK_TAG) for i in indices]
result = []
for i in indices:
if self.inverse_dict[i] == self.EOS_TAG:
break
result.append(self.inverse_dict.get(i, self.UNK_TAG))
return result
def __len__(self):
return len(self.dict)
# if __name__ == '__main__':
# num_sequence = Word_sequence()
# print(num_sequence.dict)
# print(num_sequence.inverse_dict)
cut.py
"""
分词
"""
import jieba
import config
import string
import jieba.posseg as psg # 返回词性
from lib.stopwords import stopwords
# 加载词典
jieba.load_userdict(config.user_dict_path)
# 准备英文字符
letters = string.ascii_lowercase+'+'
def cut_sentence_by_word(sentence):
"""实现中英文分词"""
temp = ''
result = []
for word in sentence:
if word.lower() in letters:
# 如果是英文字符,则进行拼接空字符串
temp += word
else:
# 遇到汉字后,把英文先添加到结果中
if temp != '':
result.append(temp.lower())
temp = ''
result.append(word.strip())
if temp !='':
# 若英文出现在最后
result.append(temp.lower())
return result
def cut(sentence, by_word = False, use_stopwords = True, with_sg = False):
"""
:param sentence: 句子
:param by_word: T根据单个字分词或者F句子
:param use_stopwords: 是否使用停用词,默认False
:param with_sg: 是否返回词性
:return:
"""
if by_word:
result = cut_sentence_by_word(sentence)
else:
result = psg.lcut(sentence)
# psg 源码返回i.word,i.flag 即词,定义的词性
result = [(i.word, i.flag) for i in result]
# 是否返回词性
if not with_sg:
result = [i[0] for i in result]
# 是否使用停用词
if use_stopwords:
result = [i for i in result if i not in stopwords]
return result
4. 构建Dataset和DataLoader
创建dataset.py 文件,准备数据集
import torch
import config
from torch.utils.data import Dataset,DataLoader
from word_sequence import word_sequence
class ChatDataset(Dataset):
def __init__(self):
super(ChatDataset,self).__init__()
input_path = "../corpus/input.txt"
target_path = "../corpus/output.txt"
if config.use_word:
input_path = "../corpus/input_word.txt"
target_path = "../corpus/output_word.txt"
self.input_lines = open(input_path).readlines()
self.target_lines = open(target_path).readlines()
assert len(self.input_lines) == len(self.target_lines) ,"input和target文本的数量必须相同"
def __getitem__(self, index):
input = self.input_lines[index].strip().split()
target = self.target_lines[index].strip().split()
if len(input) == 0 or len(target)==0:
input = self.input_lines[index+1].strip().split()
target = self.target_lines[index+1].strip().split()
#此处句子的长度如果大于max_len,那么应该返回max_len
return input,target,min(len(input),config.max_len),min(len(target),config.max_len)
def __len__(self):
return len(self.input_lines)
def collate_fn(batch):
#1.排序
batch = sorted(batch,key=lambda x:x[2],reverse=True)
input, target, input_length, target_length = zip(*batch)
# 2.进行padding的操作
input = torch.LongTensor([word_sequence.transform(i, max_len=config.max_len) for i in input])
target = torch.LongTensor([word_sequence.transform(i, max_len=config.max_len, add_eos=True) for i in target])
input_length = torch.LongTensor(input_length)
target_length = torch.LongTensor(target_length)
return input, target, input_length, target_length
data_loader = DataLoader(dataset=ChatDataset(),batch_size=config.batch_size,shuffle=True,collate_fn=collate_fn,drop_last=True)
if __name__ == '__main__':
for idx, (input, target, input_lenght, target_length) in enumerate(data_loader):
print(idx)
print(input)
print(target)
print(input_lenght)
print(target_length)
Dataset.py
"""
完成数据集的准备
"""
from torch.utils.data import Dataset, DataLoader
import config
import torch
class ChatBotDataset(Dataset):
def __init__(self):
self.input_path = config.chatbot_input_path
self.target_path = config.chatbot_target_path
self.input_lines = open(self.input_path, encoding = 'utf-8').readlines()
self.target_lines = open(self.target_path, encoding = 'utf-8').readlines()
assert len(self.input_lines) == len(self.target_lines), 'input和target长度不一致'
def __getitem__(self, index):
input = self.input_lines[index].strip().split()
target = self.target_lines[index].strip().split()
input_length = len(input)
target_length = len(target)
return input, target, input_length, target_length
def __len__(self):
return len(self.input_lines)
def collate_fn(batch):
"""
:param batch: [(input, target, input_length, target_length),....]
:return:
"""
# 根据长度进行排序
batch = sorted(batch, key = lambda x : x[2], reverse = True)
input, target, input_length, target_length = zip(*batch)
input = [config.chatbot_ws_input.transforms(i, max_len = config.chatbot_input_max_len) for i in input]
input = torch.LongTensor(input)
target = [config.chatbot_ws_target.transforms(i, max_len = config.chatbot_target_max_len, add_eos = True) for i in target]
target = torch.LongTensor(target)
input_length = torch.LongTensor(input_length)
target_length = torch.LongTensor(target_length)
return input, target, input_length, target_length
train_data_loader = DataLoader(ChatBotDataset(), batch_size = config.chatbot_batch_size, shuffle = True, collate_fn = collate_fn)
5. 完成encoder编码器逻辑
import torch.nn as nn
from word_sequence import word_sequence
import config
class Encoder(nn.Module):
def __init__(self):
super(Encoder,self).__init__()
self.vocab_size = len(word_sequence)
self.dropout = config.dropout
self.embedding_dim = config.embedding_dim
self.embedding = nn.Embedding(num_embeddings=self.vocab_size,embedding_dim=self.embedding_dim,padding_idx=word_sequence.PAD)
self.gru = nn.GRU(input_size=self.embedding_dim,
hidden_size=config.hidden_size,
num_layers=1,
batch_first=True,
dropout=config.dropout)
def forward(self, input,input_length):
embeded = self.embedding(input)
embeded = nn.utils.rnn.pack_padded_sequence(embeded,lengths=input_length,batch_first=True)
#hidden:[1,batch_size,hidden_size]
out,hidden = self.gru(embeded)
out,outputs_length = nn.utils.rnn.pad_packed_sequence(out,batch_first=True,padding_value=word_sequence.PAD)
#hidden [1,batch_size,hidden_size]
return out,hidden
6. 完成decoder解码器的逻辑
import torch
import torch.nn as nn
import config
import random
import torch.nn.functional as F
from word_sequence import word_sequence
class Decoder(nn.Module):
def __init__(self):
super(Decoder,self).__init__()
self.max_seq_len = config.max_len
self.vocab_size = len(word_sequence)
self.embedding_dim = config.embedding_dim
self.dropout = config.dropout
self.embedding = nn.Embedding(num_embeddings=self.vocab_size,embedding_dim=self.embedding_dim,padding_idx=word_sequence.PAD)
self.gru = nn.GRU(input_size=self.embedding_dim,
hidden_size=config.hidden_size,
num_layers=1,
batch_first=True,
dropout=self.dropout)
self.log_softmax = nn.LogSoftmax()
self.fc = nn.Linear(config.hidden_size,self.vocab_size)
def forward(self, encoder_hidden,target,target_length):
# encoder_hidden [1,batch_size,hidden_size]
# target [batch_size,seq-len]
decoder_input = torch.LongTensor([[word_sequence.SOS]]*config.batch_size).to(config.device)
decoder_outputs = torch.zeros(config.batch_size,config.max_len,self.vocab_size).to(config.device) #[batch_size,seq_len,vocab_size]
decoder_hidden = encoder_hidden #[1, batch_size,hidden_size]
for t in range(config.max_len):
decoder_output_t , decoder_hidden = self.forward_step(decoder_input,decoder_hidden)
decoder_outputs[:,t,:] = decoder_output_t
value, index = torch.topk(decoder_output_t, 1) # index [batch_size,1]
decoder_input = index
return decoder_outputs,decoder_hidden
def forward_step(self,decoder_input,decoder_hidden):
"""
:param decoder_input:[batch_size,1]
:param decoder_hidden: [1,batch_size,hidden_size]
:return: out:[batch_size,vocab_size],decoder_hidden:[1,batch_size,didden_size]
"""
embeded = self.embedding(decoder_input) #embeded: [batch_size,1, embedding_dim]
out,decoder_hidden = self.gru(embeded,decoder_hidden) #out [batch_size, 1,hidden_size]
out = out.squeeze(1)
out = F.log_softmax(self.fc(out),dim=-1)#[batch_Size, vocab_size]
# print("out size:",out.size(),decoder_hidden.size())
return out,decoder_hidden
关于 decoder_outputs[:,t,:] = decoder_output_t的演示
decoder_outputs 形状 [batch_size, seq_len, vocab_size]
decoder_output_t 形状[batch_size, vocab_size]
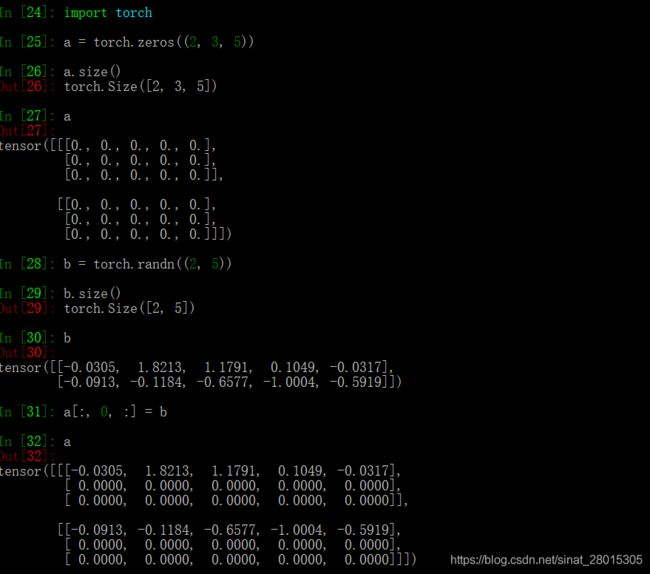
关于torch.topk, torch.max(),torch.argmax()
value, index = torch.topk(decoder_output_t , k = 1)
decoder_output_t [batch_size, vocab_size]
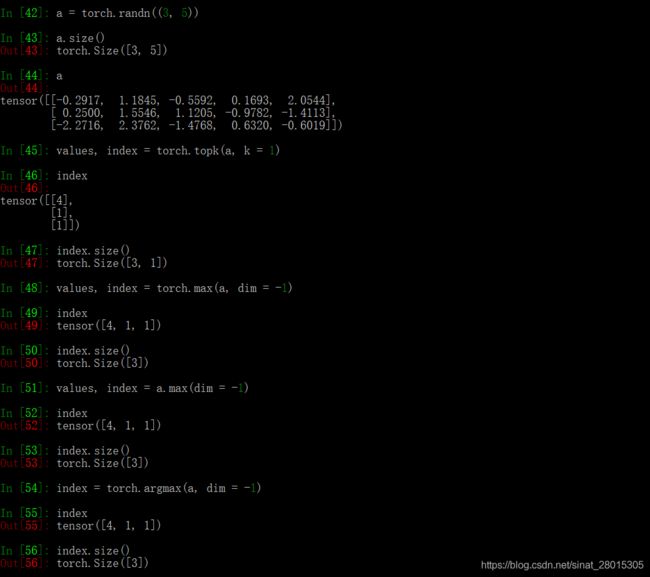
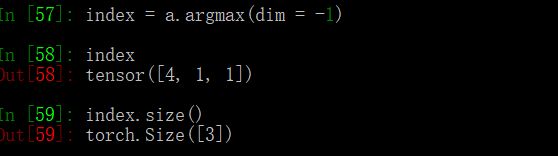
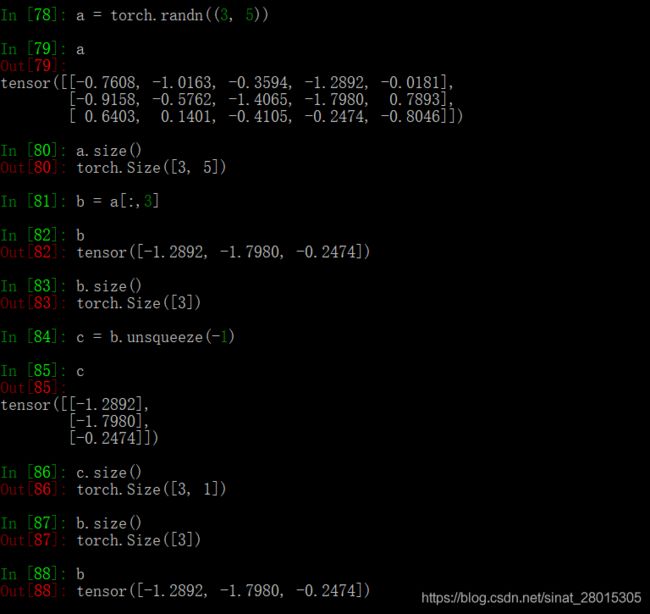
若使用teacher forcing ,将采用下次真实值作为下个time step的输入
# 注意unsqueeze 相当于浅拷贝,不会对原张量进行修改
decoder_input = target[:,t].unsqueeze(-1)
target 形状 [batch_size, seq_len]
decoder_input 要求形状[batch_size, 1]
7.完成seq2seq的模型
import torch
import torch.nn as nn
class Seq2Seq(nn.Module):
def __init__(self,encoder,decoder):
super(Seq2Seq,self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, input,target,input_length,target_length):
encoder_outputs,encoder_hidden = self.encoder(input,input_length)
decoder_outputs,decoder_hidden = self.decoder(encoder_hidden,target,target_length)
return decoder_outputs,decoder_hidden
def evaluation(self,inputs,input_length):
encoder_outputs,encoder_hidden = self.encoder(inputs,input_length)
decoded_sentence = self.decoder.evaluation(encoder_hidden)
return decoded_sentence
8. 完成训练逻辑
为了加速训练,可以考虑在gpu上运行,那么在我们自顶一个所以的tensor和model都需要转化为CUDA支持的类型。
当前的数据量为500多万条,在GTX1070(8G显存)上训练,大概需要90分一个epoch,耐心的等待吧
注意:CUDA训练时
RuntimeError: CUDA out of memory.
解决办法:改小batch_size
import torch
import config
from torch import optim
import torch.nn as nn
from encoder import Encoder
from decoder import Decoder
from seq2seq import Seq2Seq
from dataset import data_loader as train_dataloader
from word_sequence import word_sequence
encoder = Encoder()
decoder = Decoder()
model = Seq2Seq(encoder,decoder)
#device在config文件中实现
model.to(config.device)
print(model)
model.load_state_dict(torch.load("model/seq2seq_model.pkl"))
optimizer = optim.Adam(model.parameters())
optimizer.load_state_dict(torch.load("model/seq2seq_optimizer.pkl"))
criterion= nn.NLLLoss(ignore_index=word_sequence.PAD,reduction="mean")
def get_loss(decoder_outputs,target):
target = target.view(-1) #[batch_size*max_len]
decoder_outputs = decoder_outputs.view(config.batch_size*config.max_len,-1)
return criterion(decoder_outputs,target)
def train(epoch):
for idx,(input,target,input_length,target_len) in enumerate(train_dataloader):
input = input.to(config.device)
target = target.to(config.device)
input_length = input_length.to(config.device)
target_len = target_len.to(config.device)
optimizer.zero_grad()
##[seq_len,batch_size,vocab_size] [batch_size,seq_len]
decoder_outputs,decoder_hidden = model(input,target,input_length,target_len)
loss = get_loss(decoder_outputs,target)
loss.backward()
optimizer.step()
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, idx * len(input), len(train_dataloader.dataset),
100. * idx / len(train_dataloader), loss.item()))
torch.save(model.state_dict(), "model/seq2seq_model.pkl")
torch.save(optimizer.state_dict(), 'model/seq2seq_optimizer.pkl')
if __name__ == '__main__':
for i in range(10):
train(i)
训练10个epoch之后的效果如下,可以看出损失依然很高:
Train Epoch: 9 [2444544/4889919 (50%)] Loss: 4.923604
Train Epoch: 9 [2444800/4889919 (50%)] Loss: 4.364594
Train Epoch: 9 [2445056/4889919 (50%)] Loss: 4.613254
Train Epoch: 9 [2445312/4889919 (50%)] Loss: 4.143538
Train Epoch: 9 [2445568/4889919 (50%)] Loss: 4.412729
Train Epoch: 9 [2445824/4889919 (50%)] Loss: 4.516526
Train Epoch: 9 [2446080/4889919 (50%)] Loss: 4.124945
Train Epoch: 9 [2446336/4889919 (50%)] Loss: 4.777015
Train Epoch: 9 [2446592/4889919 (50%)] Loss: 4.358538
Train Epoch: 9 [2446848/4889919 (50%)] Loss: 4.513412
Train Epoch: 9 [2447104/4889919 (50%)] Loss: 4.202757
Train Epoch: 9 [2447360/4889919 (50%)] Loss: 4.589584
9.评估逻辑
decoder 中添加评估方法
def evaluate(self, encoder_hidden):
"""
评估, 和fowward逻辑类似
:param encoder_hidden: encoder最后time step的隐藏状态 [1, batch_size, hidden_size]
:return:
"""
batch_size = encoder_hidden.size(1)
# 初始化一个[batch_size, 1]的SOS张量,作为第一个time step的输出
decoder_input = torch.LongTensor([[config.target_ws.SOS]] * batch_size).to(config.device)
# encoder_hidden 作为decoder第一个时间步的hidden [1, batch_size, hidden_size]
decoder_hidden = encoder_hidden
# 初始化[batch_size, seq_len, vocab_size]的outputs 拼接每个time step结果
decoder_outputs = torch.zeros((batch_size, config.chatbot_target_max_len, self.vocab_size)).to(config.device)
# 初始化一个空列表,存储每次的预测序列
predict_result = []
# 对每个时间步进行更新
for t in range(config.chatbot_target_max_len):
decoder_output_t, decoder_hidden = self.forward_step(decoder_input, decoder_hidden)
# 拼接每个time step,decoder_output_t [batch_size, vocab_size]
decoder_outputs[:, t, :] = decoder_output_t
# 由于是评估,需要每次都获取预测值
index = torch.argmax(decoder_output_t, dim = -1)
# 更新下一时间步的输入
decoder_input = index.unsqueeze(1)
# 存储每个时间步的预测序列
predict_result.append(index.cpu().detach().numpy()) # [[batch], [batch]...] ->[seq_len, vocab_size]
# 结果转换为ndarry,每行是一个预测结果即单个字对应的索引, 所有行为seq_len长度
predict_result = np.array(predict_result).transpose() # (batch_size, seq_len)的array
return decoder_outputs, predict_result
eval.py
import torch
import torch.nn as nn
import torch.nn.functional as F
from dataset import get_dataloader
import config
import numpy as np
from Seq2Seq import Seq2SeqModel
import os
from tqdm import tqdm
model = Seq2SeqModel().to(config.device)
if os.path.exists('./model/chatbot_model.pkl'):
model.load_state_dict(torch.load('./model/chatbot_model.pkl'))
def eval():
model.eval()
loss_list = []
test_data_loader = get_dataloader(train = False)
with torch.no_grad():
bar = tqdm(test_data_loader, desc = 'testing', total = len(test_data_loader))
for idx, (input, target, input_length, target_length) in enumerate(bar):
input = input.to(config.device)
target = target.to(config.device)
input_length = input_length.to(config.device)
target_length = target_length.to(config.device)
# 获取模型的预测结果
decoder_outputs, predict_result = model.evaluation(input, input_length)
# 计算损失
loss = F.nll_loss(decoder_outputs.view(-1, len(config.target_ws)), target.view(-1), ignore_index = config.target_ws.PAD)
loss_list.append(loss.item())
bar.set_description('idx{}:/{}, loss:{}'.format(idx, len(test_data_loader), np.mean(loss_list)))
if __name__ == '__main__':
eval()
interface.py
from cut_sentence import cut
import torch
import config
from Seq2Seq import Seq2SeqModel
import os
# 模拟聊天场景,对用户输入进来的话进行回答
def interface():
# 加载训练集好的模型
model = Seq2SeqModel().to(config.device)
assert os.path.exists('./model/chatbot_model.pkl') , '请先对模型进行训练!'
model.load_state_dict(torch.load('./model/chatbot_model.pkl'))
model.eval()
while True:
# 输入进来的原始字符串,进行分词处理
input_string = input('me>>:')
if input_string == 'q':
print('下次再聊')
break
input_cuted = cut(input_string, by_word = True)
# 进行序列转换和tensor封装
input_tensor = torch.LongTensor([config.input_ws.transfrom(input_cuted, max_len = config.chatbot_input_max_len)]).to(config.device)
input_length_tensor = torch.LongTensor([len(input_cuted)]).to(config.device)
# 获取预测结果
outputs, predict = model.evaluation(input_tensor, input_length_tensor)
# 进行序列转换文本
result = config.target_ws.inverse_transform(predict[0])
print('chatbot>>:', result)
if __name__ == '__main__':
interface()

Attention的原理和实现
1. Attention的介绍
在普通的RNN结构中,Encoder需要把一个句子转化为一个向量,然后在Decoder中使用,这就要求Encoder把源句子中所有的信息都包含进去,但是当句子长度过长的时候,这个要求就很难达到,或者说会产生瓶颈(比如,输入一篇文章等场长内容),当然我们可以使用更深的RNN和大多的单元来解决这个问题,但是这样的代价也很大。那么有没有什么方法能够优化现有的RNN结构呢?
为此,Bahdanau等人在2015年提出了Attenion机制,Attention翻译成为中文叫做注意力,把这种模型称为Attention based model。就像我们自己看到一副画,我们能够很快的说出画的主要内容,而忽略画中的背景,因为我们注意的,更关注的往往是其中的主要内容。
通过这种方式,在我们的RNN中,我们有通过LSTM或者是GRU得到的所有信息,那么这些信息中只去关注重点,而不需要在Decoder的每个time step使用全部的encoder的信息,这样就可以解决第一段所说的问题了
那么现在要讲的Attention机制就能够帮助我们解决这个问题
Attention机制,让模型更加关注句子中的重点内容
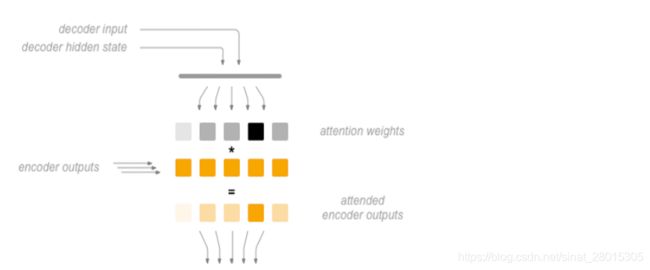
2. Attenion的实现机制
假设我们现在有一个文本翻译的需求,即机器学习翻译为machine learning。那么这个过程通过前面所学习的Seq2Seq就可以实现

上图的左边是Encoder,能够得到hidden_state在右边使用
Deocder中蓝色方框中的内容,是为了提高模型的训练速度而使用teacher forcing手段,否则的话会把前一次的输出作为下一次的输入(但是在Attention模型中不再是这样了)
那么整个过程中如果使用Attention应该怎么做呢?
在之前我们把encoder的最后一个输出,作为decoder的初始的隐藏状态,现在我们不再这样做
2.1 Attention的实现过程
-
初始化一个Decoder的隐藏状态 z 0 z_0 z0
-
这个 z o z_o zo会和encoder第一个time step的output进行match操作(或者是socre操作),得到 α 0 1 \alpha_0^1 α01 ,这里的match可以使很多中操作,比如:
- z和h的余弦值
- 是一个神经网络,输入为z和h
- 或者 α = h T W z \alpha = h^T W z α=hTWz等
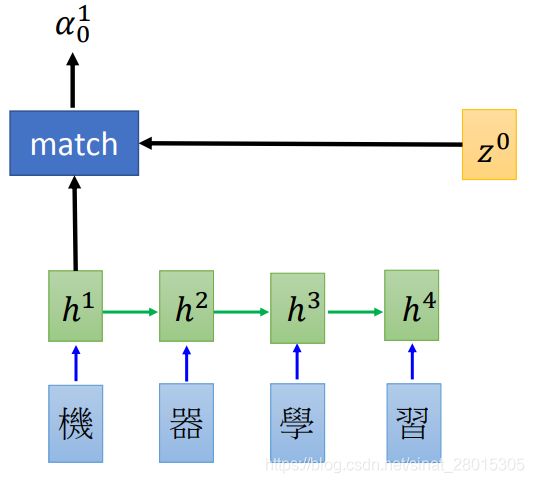
-
encoder中的每个output都和 z 0 z_0 z0进行计算之后,得到的结果进行softmax,让他们的和为1(可以理解为权重)
-
之后把所有的softmax之后的结果和原来encoder的输出 h i h_i hi进行相加求和得到 c 0 c^0 c0
即 : c 0 = ∑ α ^ 0 i h i 即: c^0 = \sum\hat{\alpha}_0^ih^i 即:c0=∑α^0ihi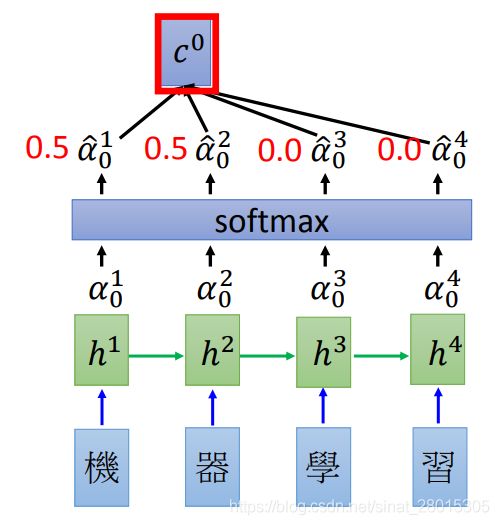
-
得到 c 0 c^0 c0之后,把它作为decoder的input,同和传入初始化的 z 0 z^0 z0,得到第一个time step的输出和hidden_state( Z 1 Z^1 Z1)
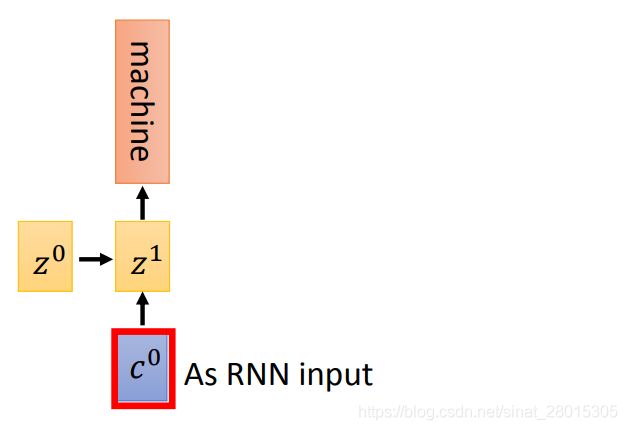
-
把 Z 1 Z_1 Z1再和所有的encoder的output进行match操作,得到的结果进行softmax之后作为权重和encoder的每个timestep的结果相乘求和得到 c 1 c^1 c1
-
再把 c 1 c^1 c1作为decoder的input,和 Z 1 Z^1 Z1作为输入得到下一个输出,如此循环,只到最终decoder的output为终止符
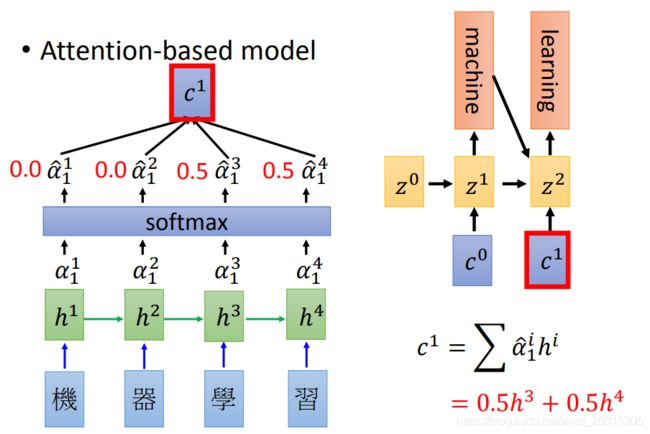
-
上述参考:
http://speech.ee.ntu.edu.tw/~tlkagk/courses_MLSD15_2.html -
整个过程写成数学公式如下:

- 先计算attention权重
- 在计算上下文向量,图中的 c i c^i ci
- 最后计算结果,往往会把当前的output([batch_size,1,hidden_size])和上下文向量(context vector)进行拼接然后使用
attention 原理实现过程
a. 初始化decoder的隐藏状态 z0
b. 计算attention权重:隐藏状态和和encoder的outputs计算(余弦,DNN,矩阵)出的结果进行sofamax之后得到attention weight
c. 得到context vector:attention weight 和 encoder outputs 计算得到
d. attention的最终结果:前一次的输出和context vector 进行concat,经过形状变换和tanh的处理后作为当前时间步的输入
e. decoder当前时间步会把attention的最终结果作为输入,还会把前一次的输出zi作为隐藏状态输入
2.2 不同Attention的介绍
在上述过程中,使用decoder的状态和encoder的状态的计算后的结果作为权重,乘上encoder每个时间步的输出,这需要我们去训练一个合适的match函数,得到的结果就能够在不同的时间步上使用不同的encoder的相关信息,从而达到只关注某一个局部的效果,也就是注意力的效果
2.2.1 Soft-Attention 和 Hard-Attention
最开始Bahdanau等人提出的Attention机制通常被称为soft-attention,所谓的soft-attention指的是encoder中输入的每个词语都会计算得到一个注意力的概率。
在进行图像捕捉的时候,提出了一种hard-attenion的方法,希望直接从input中找到一个和输出的某个词对应的那一个词。但是由于NLP中词语和词语之间往往存在联系,不会只关注某一个词语,所以都会使用soft-attention,所以这里的就不多介绍hard-attention
soft attention: encoder中每一个输出都会计算一个概率
hard attention: encoder中只寻找某一个计算概率

2.2.3 Global-Attention 和Local Attention
Bahdanau等人提出的Bahdanau Attention 被称为local attention,后来Luong等人提出的Luong Attention是一种全局的attenion。
所谓全局的attenion指的是:使用的全部的encoder端的输入的attenion的权重
local-attenion就是使用了部分的encoder端的输入的权重(当前时间步上的encoder的hidden state),这样可以减少计算量,特别是当句子的长度比较长的时候。
golbal attention:使用全部的encoder 的输出来计算attention权重
local attention:使用部分的encoder的输出来计算attention权重
2.2.4 Bahdanau Attention和 Luong Attenion的区别
Bahdanau Attention计算过程
1. 前一次的隐藏状态和encoder的output match计算得到attention weight
2. attention weight 和 encoder output计算得到context vector
3. context vector作为当前时间步的输入,同时当前时间步的输入还有前一次的隐藏状态
4. 得到当前时间步的输出和隐藏状态
Luong Attenion计算过程
1. GRU计算得到的decoder的hidden_state(若没有则可以初始化一个)
2. hidden state 和encoder的hidden计算得到a_t(attention weight)
3. attention weight 和 encoder 的output计算得到context vector
4. context vector 和 GRU的当前时间步的output合并计算得到最终的输出
区别在于两个地方:
-
attention的计算数据和位置
-
Bahdanau Attention会使用前一次的隐藏状态来计算attention weight,所以我们会在代码中的GRU之前使用attention的操作,同时会把attention的结果和word embedding的结果进行concat,作为GRU的输出(参考的是pytorch Toritul)。Bahdanau使用的是双向的GRU,会使用正反的encoder的output的concat的结果作为encoder output,如下图所示
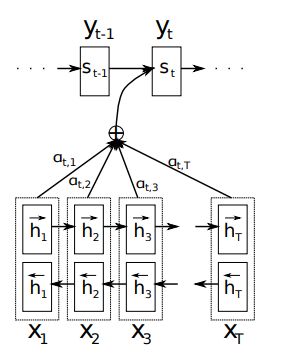
-
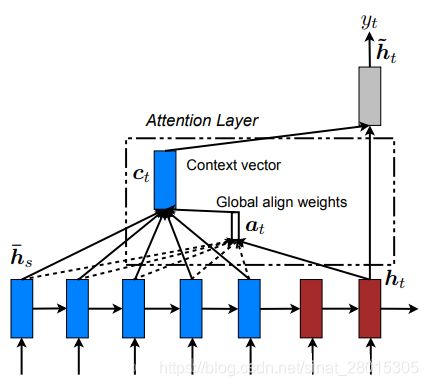
Luong Attenion使用的是当前一次的decoder的output来计算得到attention weight,所以在代码中会在GRU的后面进行attention的操作,同时会把context vector和gru的结果进行concat的操作,最终的output。Luong使用的是多层GRU,只会使用最后一层的输出(encoder output)
-
-
计算attention weights的方法不同
-
Bahdanau Attention的match函数, a i j = v a T t a n h ( W a Z i − 1 , + U a h j ) a_i^j = v^T_a tanh (W_aZ_{i-1},+U_ah_j) aij=vaTtanh(WaZi−1,+Uahj),计算出所有的 a i j a_i^j aij之后,在计算softmax,得到 a ^ i j \hat{a}_i^j a^ij,即 a ^ i j = e x p ( a i j ) ∑ e x p ( a i j ) \hat{a}_i^j = \frac{exp(a_i^j)}{\sum exp(a_i^j)} a^ij=∑exp(aij)exp(aij)其中
- v a T 是 一 个 参 数 矩 阵 , 需 要 被 训 练 , W a 是 实 现 对 Z i − 1 的 形 状 变 化 v_a^T是一个参数矩阵,需要被训练,W_a是实现对Z_{i-1}的形状变化 vaT是一个参数矩阵,需要被训练,Wa是实现对Zi−1的形状变化,
- U a 实 现 对 h j 的 形 状 变 化 ( 矩 阵 乘 法 , 理 解 为 线 性 回 归 , 实 现 数 据 形 状 的 对 齐 ) U_a实现对h_j的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐) Ua实现对hj的形状变化(矩阵乘法,理解为线性回归,实现数据形状的对齐),
- Z i − 1 是 d e c o d e r 端 前 一 次 的 隐 藏 状 态 , h j 是 e n c o d e r 的 o u t p u t Z_{i-1}是decoder端前一次的隐藏状态,h_j是encoder的output Zi−1是decoder端前一次的隐藏状态,hj是encoder的output
-
Luong Attenion整体比Bahdanau Attention更加简单,他使用了三种方法来计算得到权重- 矩阵乘法:general
- 直接对decoder的隐藏状态进行一个矩阵变换(线性回归),然后和encoder outputs进行矩阵乘法
- dot
- 直接对decoder的隐藏状态和encoder outputs进行矩阵乘法
- concat
-
把decoder的隐藏状态和encoder的output进行concat,把这个结果使用tanh进行处理后的结果进行
对齐(进行矩阵乘法,变换为需要的形状)计算之后,和encoder outputs进行矩阵乘法
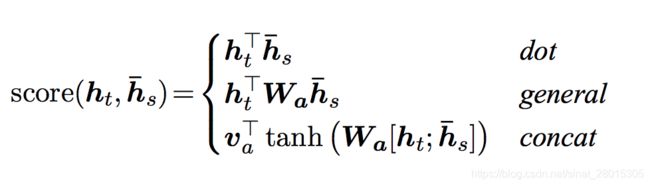
-
h t 是当前的decoder hidden state, h s 是所有的encoder 的hidden state(encoder outputs) h_t\text{是当前的decoder hidden state,}h_s\text{是所有的encoder 的hidden state(encoder outputs)} ht是当前的decoder hidden state,hs是所有的encoder 的hidden state(encoder outputs)
-
- 矩阵乘法:general
-
最终两个attention的结果区别并不太大,所以以后我们可以考虑使用Luong attention完成代码
Bahdanau Attention和 Luong Attenion 的区别
encoder:
1. Bahdanau Attention采用双向GRU进行解码,正向和反向的output进行concat之后的结果作为encoder的结果
2. Luong attention采用单向多层GRU,把最后一层的输出作为encoder的输出
decoder:
1. Bahdanau Attention使用之前的hidden_state 和encoder的output计算,得到attention weight和context vector,作为gru输入
2. Luong attention使用当前时间步的输出和encoder的output计算得到attention weight,在和encoder out 计算得到context vector ,和decoder的output进行concat,作为输出

3. Attention的代码实现
完成代码之前,我们需要确定我们的思路,通过attention的代码,需要实现计算的是attention weight
通过前面的学习,我们知道attention_weight = f(hidden,encoder_outputs),主要就是实现Luong attention中的三种操作
import torch
import torch.nn as nn
import torch.nn.functional as F
import config
class Attention(nn.Module):
def __init__(self, method):
"""
attention 机制
:param method:三种attention_weights 计算方法general, dot, concat
"""
super(Attention, self).__init__()
self.method = method
self.hidden_size = config.chatbot_encoder_hidden_size
assert self.method in ['dot', 'general', 'concat'], 'attention method error'
if self.method == 'dot':
# dot 为decoder_hidden 和encoder_outputs 直接进行矩阵乘法
pass
elif self.method == 'general':
# general为对decoder_hidden 进行矩阵变换后,与encoder_outputs相乘
self.Wa = nn.Linear(config.chatbot_encoder_hidden_size * 2, config.chatbot_encoder_hidden_size * 2,
bias=False)
elif self.method == 'concat':
self.Wa = nn.Linear(config.chatbot_encoder_hidden_size * 4, config.chatbot_encoder_hidden_size * 2,
bias=False)
self.Va = nn.Linear(config.chatbot_encoder_hidden_size * 2, 1, bias = False)
def forward(self, decoder_hidden, encoder_outputs):
"""
进行三种运算得到attn_weights
:param decoder_hidden: decoder每个时间步的隐藏状态[1, batch_size, en_hidden_size * 2]
由于encoder中使用Bi-GRU,最后对双向hidden进行了拼接,因此de_hidden_size = en_hidden_size * 2
未拼接前 encoder_hidden [1, batch_size, en_hidden_size]
:param encoder_outputs:encoder最后的输出[batch_size, en_seq_len, en_hidden_size * 2]
:return:
"""
if self.method == 'dot':
return self.dot_score(decoder_hidden, encoder_outputs)
elif self.method == 'general':
return self.general_score(decoder_hidden, encoder_outputs)
elif self.method == 'concat':
return self.concat_score(decoder_hidden, encoder_outputs)
def dot_score(self, decoder_hidden, encoder_outputs):
"""
dot 方法:直接对decoder_hidden 和 encoder_outputs进行矩阵乘法
:param decoder_hidden: [1, batch_size, en_hidden_size * 2]
:param encoder_outputs:[batch_size, en_seq_len, en_hidden_size * 2]
:return:
"""
# 要进行矩阵乘法,需要改变decoder_hidden的形状为[batch_size, en_hidde_size * 2 , 1]
# 乘法后形状为[batch_size, en_seq_len, 1]
# squeeze去掉1的维度 为[batch_size, en_seq_len]
# 最终对结果在en_seq_len维度上进行log_softmax
return F.log_softmax(torch.bmm(decoder_hidden.permute(1, 2, 0), encoder_outputs).squeeze(-1), dim = -1)
def general_score(self, decoder_hidden, encoder_outputs):
"""
general 方法:对decoder_hidden进行线性变换后与encoder_outputs进行矩阵乘法
:param decoder_hidden: [1, batch_size, en_hidden_size * 2]
:param encoder_outputs: [batch_size, en_seq_len, en_hidden_size * 2]
:return:
"""
# 由于要进行线性变换, decoder_hidden首先变成二维张量,因此线性变换的输入维度为en_hidden_size * 2
# [1, batch_size, en_hidden_size * 2]->[batch_size, en_hidden_size * 2]
decoder_hidden = decoder_hidden.squeeze(0)
# 由于要与encoder_outputs进行矩阵计算,需要将decoder_hidden的形状改变为dot中的形状
# 即[batch_size, en_hidden_size * 2, 1],因此线性变换的输出维度为en_hidden_size * 2
decoder_hidden = self.Wa(decoder_hidden).unsqueeze(-1)
# 进行矩阵乘法[batch_size, en_seq_len, 1] ->squeeze [batch_size, en_seq_len]
return F.log_softmax(torch.bmm(decoder_hidden, encoder_outputs).squeeze(-1), dim = -1)
def concat_score(self, decoder_hidden, encoder_outputs):
"""
concat方法:decoder_hidden和encoder_outputs拼接,
把这个结果使用tanh进行处理后的结果进行对齐(进行矩阵乘法,变换为需要的形状)计算之后,
和encoder outputs进行矩阵乘法
:param decoder_hidden: [1, batch_size, en_hidden_size * 2]
:param encoder_outputs: [batch_size, en_seq_len, en_hidden_size * 2]
:return:
"""
encoder_seq_len = encoder_outputs.size(1)
batch_size = encoder_outputs.size(0)
# repeat 沿着该维度重复指定次数
# repeat(3,1,1)指在0维度重复3次,其他2个维度各一次
# decoder_hidden [1, batch_size, en_hidden_size *2]->squeeze(0):[batch_size, en_hidden_size * 2]
# ->repeat:[encoder_seq_len, batch_size, en_hidden_size * 2] ->transpose:[batch_size, encoder_seq_len, en_hidden_size * 2]
decoder_hidden_repeated = decoder_hidden.squeeze(0).repeat(encoder_seq_len, 1, 1).transpose(1,0)
# 对decoder_hidden_repeated和encoder_outputs进行拼接
# cat:[batch_size, en_seq_len, en_hidden_size * 2 *2]
# view[batch_size * en_seq_len, en_hidden_size * 4]
# 因此第一个线性层输入维度为en_hidden_size * 4
h_cated = torch.cat((decoder_hidden_repeated, encoder_outputs), dim = -1).view(batch_size * encoder_seq_len, -1)
# 拼接后,需要进行线性变换及tanh和第二次线性变换最终将结果变为[batch_size, en_seq_len]
# h_cated->Wa:[batch_size * en_seq_len, en_hidden_size *4] ->[batch_size * en_seq_len, en_hidden_size *2]
# ->Va:[batch_size * en_seq_len, en_hidden_size *2] ->[batch_size * en_seq_len, 1]
# ->view:[batch_size * en_seq_len, 1] ->[batch_size ,en_seq_len]
attn_weight = self.Va(F.tanh(self.Wa(h_cated))).view([batch_size, encoder_seq_len])
return F.log_softmax(attn_weight, dim = -1)
完成了attention weight的计算之后,需要再对代码中forward_step的内容进行修改
def forward_step(self,decoder_input,decoder_hidden,encoder_outputs):
"""
:param decoder_input:[batch_size,1]
:param decoder_hidden: [1,batch_size,hidden_size]
:param encoder_outputs: encoder中所有的输出,[batch_size,seq_len,hidden_size]
:return: out:[batch_size,vocab_size],decoder_hidden:[1,batch_size,didden_size]
"""
embeded = self.embedding(decoder_input) #embeded: [batch_size,1 , embedding_dim]
#TODO 可以把embeded的结果和前一次的context(初始值为全0tensor) concate之后作为结果
#rnn_input = torch.cat((embeded, last_context.unsqueeze(0)), 2)
# gru_out:[256,1, 128] decoder_hidden: [1, batch_size, hidden_size]
gru_out,decoder_hidden = self.gru(embeded,decoder_hidden)
gru_out = gru_out.squeeze(1)
#TODO 注意:如果是单层,这里使用decoder_hidden没问题(output和hidden相同)
# 如果是多层,可以使用GRU的output作为attention的输入
#开始使用attention
attn_weights = self.attn(decoder_hidden,encoder_outputs)
# attn_weights [batch_size,1,seq_len] * [batch_size,seq_len,hidden_size]
context = attn_weights.bmm(encoder_outputs) #[batch_size,1,hidden_size]
gru_out = gru_out.squeeze(0) # [batch_size,hidden_size]
context = context.squeeze(1) # [batch_size,hidden_size]
#把output和attention的结果合并到一起
concat_input = torch.cat((gru_out, context), 1) #[batch_size,hidden_size*2]
concat_output = torch.tanh(self.concat(concat_input)) #[batch_size,hidden_size]
output = F.log_softmax(self.fc(concat_output),dim=-1) #[batch_Size, vocab_size]
# out = out.squeeze(1)
return output,decoder_hidden,attn_weights
attetnion的Bahdanau实现可以参考:https://github.com/spro/practical-pytorch/blob/master/seq2seq-translation/seq2seq-translation.ipynb
Beam Search
1. Beam Search的介绍
Beam Search 是介于贪心算法和计算全部概率之间的一种束集搜索的方法,假设Beam width= 2,表示每次保存的最大概率的个数为2个,在下一个时间步步骤一样。这样就可以达到约束搜索空间大小的目的,提高算法效率。当Beam width = 1时, 就是贪心算法;Beam width = 候选词数目时候,就是计算全部概率。
堆:优先级队列,优先级越低越先出队列。
堆实现Beam Search流程:
1. 构造<SOS>开始符号等第一次输入的信息,保存在堆中
2. 取出堆中的数据,进行forward_step 操作,获得当前时间步的output, hidden
3. 从output 中选择topk(k = beam width)个输出,作为下一次的input
4. 把下一个时间步需要的输入等数据保存在一个新的堆中
5. 获取新的堆中优先级最高(概率最大)的数据,判断数据是否是EOS结尾或者达到最大长度,如果是,停止迭代;如果不是,则重新遍历新堆中的数据。
在进行模型评估的过程中,每次我们选择概率最大的token id作为输出,那么整个输出的句子的概率就是最大的么?
Beam search的又被称作束集搜索,是一种seq2seq中用来优化输出结果的算法(不在训练过程中使用)。
例如:传统的获取解码器输出的过程中,每次只选择概率最大的那个结果,作为当前时间步的输出,等到输出结束,我们会发现,整个句子可能并不通顺。虽然在每一个时间步上的输出确实是概率最大的,但是整体的概率确不一定最大的,我们经常把它叫做greedy search[贪心算法]
为了解决上述的问题,可以考虑计算全部的输出的概率乘积,选择最大的哪一个,但是这样的话,意味着如果句子很长,候选词很多,那么需要保存的数据就会非常大,需要计算的数据量就很大
那么Beam Search 就是介于上述两种方法的一个这种的方法,假设Beam width=2,表示每次保存的最大的概率的个数,这里每次保存两个,在下一个时间步骤一样,也是保留两个,这样就可以达到约束搜索空间大小的目的,从而提高算法的效率。
beam width =1 时,就是贪心算法,beam width=候选词的时候,就是计算全部的概率。beam width 是一个超参数。
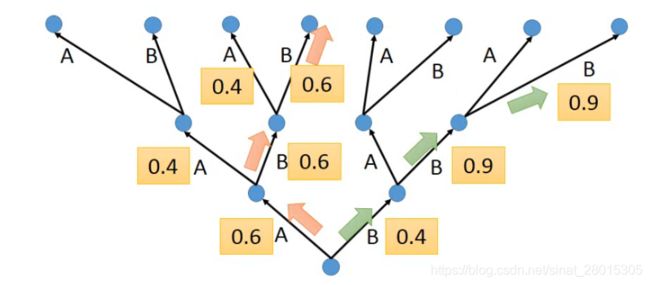
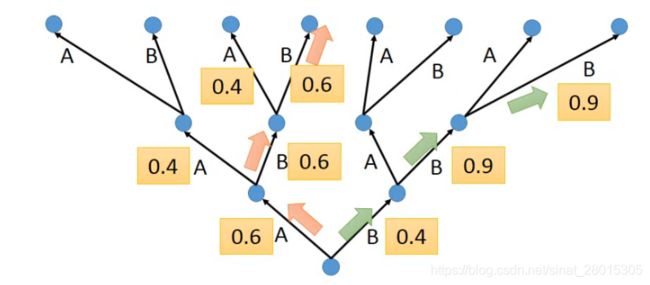
比如在下图中:
使用一个树状图来表示每个time step的可能输出,其中的数字表示是条件概率
黄色的箭头表示的是一种greedy search,概率并不是最大的
如果把beam width设置为2,那么后续可以找到绿色路径的结果,这个结果是最大的
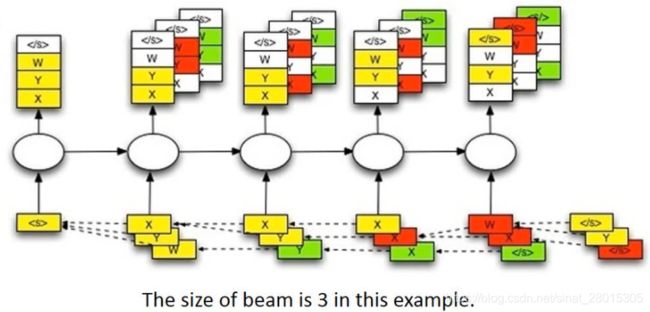
下图是要给beam width=3的例子
- 首先输入
start token,然后得到四个输出(这里假设一个就四个输出:x,y,z,),选择概率最大三个,x,y,w - 然后分别把x,y,z放到下一个time step中作为输入,分别得到三个不同的输出,找到三个输出中概率最大的三个,x,y,y
- 继续重复上述步骤,直到获得结束符(概率最大)或者是达到句子的最大长度,那么此时选择概率乘积最大的一个。
- 拼接整个路径上概率最大的所有结果,比如这里可能是
,y,y,x,w,
2. Beam serach的实现
在上述描述的思路中,我们需要注意以下几个内容:
- 数据该如何保存,每一次的输出的最大的beam width个结果,和之后之前的结果该如何保存
- 保存了之后的概率应该如何比较大小,保留下概率最大的三个
- 不能够仅仅只保存当前概率最大的信息,还需要有当前概率最大的三个中,前面的路径的输出结果
2.1 数据结构-堆-的认识
对于上面所说的,保留有限个数据,同时需要根据大小来保留,可以使用一种带有优先级的数据结构来实现,这里我们可以使用堆这种数据结构
堆是一种优先级的队列,但是他其实并不是队列,我们常说的队列都是先进先出或者是先进后出,但是堆只根据优先级的高低来取出数据。
和堆在一起的另外一种数据结构叫做栈,有入栈和出栈的操作,可以理解为是一种先进后出的数据结构,关于栈,大家可以下来在了解。
在python自带的模块中,有一个叫做heapq的模块,提供了堆所有的方法。通过下面的代码我们来了解下heapq的使用方法
my_heap = [] #使用列表保存数据
#往列表中插入数据,优先级使用插入的内容来表示,就是一个比较大小的操作,越大优先级越高
heapq.heappush(my_heap,[29,True,"xiaohong"])
heapq.heappush(my_heap,[28,False,"xiaowang"])
heapq.heappush(my_heap,[29,False,"xiaogang"])
for i in range(3):
ret= heapq.heappop(my_heap) #pop操作,优先级最小的数据
print(ret)
#输出如下:
[28, False, 'xiaowang']
[29, False, 'xiaogang']
[29, True, 'xiaohong']
可以发现,输出的顺序并不是数据插入的顺序,而是根据其优先级,从小往大pop(False 为了实现数据的的保存,我们可以把beam search中的数据保存在堆中,同时在往这个堆中添加数据的同时,判断数据的个数,仅仅保存beam width个数据 实现方法,完成模型eval过程中的beam search搜索 思路: 代码如下 在seq2seq中使用evaluatoin_beamsearch_heapq查看效果,会发现使用beam search的效果比单独使用attention的效果更好 使用小黄鸡语料(50万个问答),单个字作为token,5个epoch之后的训练结果,左边为问,右边是回答 在前面的seq2seq的案例中,我们介绍了 我们可以在每个batch遍历time step的外层使用 代码如下: 前面,我们给大家介绍了 在常见的深度神经网络中,特别是RNN中,我们经常会使用 梯度裁剪的实现非常简单,仅仅只需要设置一个阈值,把梯度大于该阈值时设置为该阈值。 实现代码:2.2 使用堆来实现beam search
class Beam:
def __init__(self):
self.heap = list() #保存数据的位置
self.beam_width = config.beam_width #保存数据的总数
def add(self,probility,complete,seq,decoder_input,decoder_hidden):
"""
添加数据,同时判断总的数据个数,多则删除
:param probility: 概率乘积
:param complete: 最后一个是否为EOS
:param seq: list,所有token的列表
:param decoder_input: 下一次进行解码的输入,通过前一次获得
:param decoder_hidden: 下一次进行解码的hidden,通过前一次获得
:return:
"""
heapq.heappush(self.heap,[probility,complete,seq,decoder_input,decoder_hidden])
#判断数据的个数,如果大,则弹出。保证数据总个数小于等于3
if len(self.heap)>self.beam_width:
heapq.heappop(self.heap)
def __iter__(self):#让该beam能够被迭代
return iter(self.heap)
# decoder中的新方法
def evaluatoin_beamsearch_heapq(self,encoder_outputs,encoder_hidden):
"""使用 堆 来完成beam search,对是一种优先级的队列,按照优先级顺序存取数据"""
batch_size = encoder_hidden.size(1)
#1. 构造第一次需要的输入数据,保存在堆中
decoder_input = torch.LongTensor([[word_sequence.SOS] * batch_size]).to(config.device)
decoder_hidden = encoder_hidden #需要输入的hidden
prev_beam = Beam()
prev_beam.add(1,False,[decoder_input],decoder_input,decoder_hidden)
while True:
cur_beam = Beam()
#2. 取出堆中的数据,进行forward_step的操作,获得当前时间步的output,hidden
#这里使用下划线进行区分
for _probility,_complete,_seq,_decoder_input,_decoder_hidden in prev_beam:
#判断前一次的_complete是否为True,如果是,则不需要forward
#有可能为True,但是概率并不是最大
if _complete == True:
cur_beam.add(_probility,_complete,_seq,_decoder_input,_decoder_hidden)
else:
decoder_output_t, decoder_hidden,_ = self.forward_step(_decoder_input, _decoder_hidden,encoder_outputs)
value, index = torch.topk(decoder_output_t, config.beam_width) # [batch_size=1,beam_widht=3]
#3. 从output中选择topk(k=beam width)个输出,作为下一次的input
for m, n in zip(value[0], index[0]):
decoder_input = torch.LongTensor([[n]]).to(config.device)
seq = _seq + [n]
probility = _probility * m
if n.item() == word_sequence.EOS:
complete = True
else:
complete = False
#4. 把下一个实践步骤需要的输入等数据保存在一个新的堆中
cur_beam.add(probility,complete,seq,
decoder_input,decoder_hidden)
#5. 获取新的堆中的优先级最高(概率最大)的数据,判断数据是否是EOS结尾或者是否达到最大长度,如果是,停止迭代
best_prob,best_complete,best_seq,_,_ = max(cur_beam)
if best_complete == True or len(best_seq)-1 == config.max_len: #减去sos
return self._prepar_seq(best_seq)
else:
#6. 则重新遍历新的堆中的数据
prev_beam = cur_beam
def _prepar_seq(self,seq):#对结果进行基础的处理,共后续转化为文字使用
if seq[0].item() == word_sequence.SOS:
seq= seq[1:]
if seq[-1].item() == word_sequence.EOS:
seq = seq[:-1]
seq = [i.item() for i in seq]
return seq
2.3 修改seq2seq
你在干什么 >>>>> 你想干啥?
你妹 >>>>> 不是我
你叫什么名字 >>>>> 你猜
你个xx >>>>> 你才是,你
你是xx >>>>> 是你是x
笨蛋啊 >>>>> 我不是,你
闲聊机器人的优化
1. seq2seq中使用
teacher forcingteacher frocing是什么,当时我们的输入和输出很相似,所以当时我们的teacher forcing是在每个time step中实现的,那么现在我们的输入和输出不同的情况下,该如何使用呢?teacher forcinguse_teacher_forcing = random.random() > 0.5
if use_teacher_forcing: #使用teacher forcing
for t in range(config.max_len):
decoder_output_t, decoder_hidden, decoder_attn_t = self.forward_step(decoder_input, decoder_hidden,
encoder_outputs)
decoder_outputs[:, t, :] = decoder_output_t
#使用正确的输出作为下一步的输入
decoder_input = target[:, t].unsqueeze(1) # [batch_size,1]
else:#不适用teacher forcing,使用预测的输出作为下一步的输入
for t in range(config.max_len):
decoder_output_t ,decoder_hidden,decoder_attn_t = self.forward_step(decoder_input,decoder_hidden,encoder_outputs)
decoder_outputs[:,t,:] = decoder_output_t
value, index = torch.topk(decoder_output_t, 1) # index [batch_size,1]
decoder_input = index
2. 使用梯度裁剪
梯度消失(梯度过小,在多层计算后导致其值太小而无法计算)和梯度爆炸(梯度过大,导致其值在多层的计算后太大而无法计算)。梯度裁剪的手段,来抑制过大的梯度,能够有效防止梯度爆炸。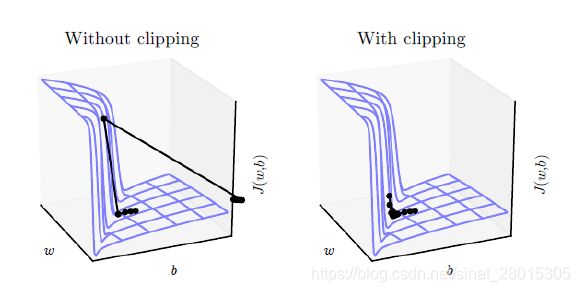
from torch.nn.utils import clip_grad_norm_
loss.backward()
#进行梯度裁剪
# clip = [5,10,15]
nn.utils.clip_grad_norm_(model.parameters(),[5,10,15])
optimizer.step()
3. 其他优化方法
询问名字分类后,直接返回名字