CVPR_2022:Beyond a Pre-Trained Object Detector论文阅读
Beyond a Pre-Trained Object Detector:Cross-Modal Textual and Visual Context for Image Captioning
论文地址:Beyond a Pre-Trained Object Detector
论文代码地址:Github
Abstract
当前在视觉字幕方面取得的重大进展,主要依赖于将预训练得到的特征和经过object detector提取的特征作为自回归模型的输入。但是这种方法的受限关键是模型的输出受到了object detector的限制,特别是在跨数据集object detector的时候,认定这样的输出能表示所有必要的特征的假设是不成立的。在本文中,我们对基于这种假设的图模型进行推理,并且提出添加一个辅助输入来表示缺失的信息,如对象关系。我们特别建议从Visual Genome数据集中挖掘属性和关系,并根据它们来调整caption模型。更重要的是,我们提出(并表明这是至关重要的)使用多模态预训练模型(CLIP)来检索这些上下文的描述。此外,因为object detector models是被冻结的,在训练的时候不能够被优化。因此我们建议对object detector和图像的描述进行条件化处理,并在定性和定量上表明这可以改善grounding。我们在image caption上验证了我们的方法,对预训练多模态模型的每个组成部分和重要性进行了彻底分析,并证明了在当前技术状态下的显著改进,特别是CIDEr +7.5%和BLEU-4指标+1.3%。
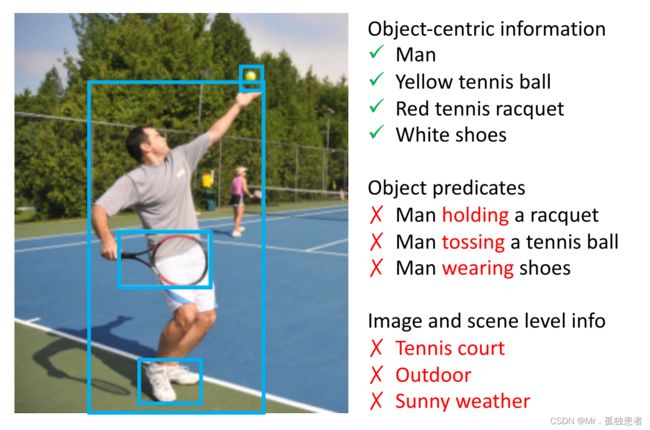
图1:大多数现有的VL方法通过预先训练的对象检测器检测到的一组对象对输入图像进行编码。
这组被检测到的对象可能能够提供以对象为中心的信息,如对象类、位置和属性,但可能无法编码对目标VL任务同样重要的其他信息,如对象谓词和图像/场景级信息。(可以从图中看到仅仅进行object detection会丢失目标的运动状态信息以及目标所处的背景信息)
1.Introduction
对于视觉和语言(VL)任务,如image caption,将输入图像编码为包含下游语言任务相关信息的表示是至关重要的。早期的工作使用ImageNet预训练模型对输入图像进行编码,而最近的工作通过使用object detector检测到的对象(例如在Visual Genome上训练的Faster R-CNN)实现了更好的性能。通过object detector检测到的对象拥有图像更细粒度的信息,例如物体种类、位置和属性等,因此可以获得更好的性能。
尽管成功地用检测到的对象对输入图像进行编码,但object detector在Visual Genome等数据集上进行了预先训练,并在目标VL任务(在不同的数据集上)训练期间保持冻结。这导致了如图1所示的两个主要问题:(1)检测器可能擅长于编码以对象为中心的信息,但不擅长于目标VL任务所需的许多其他类型的信息,如对象和图像/场景级信息之间的关系;(2)被检测对象和输入图像之间的条件关系没有针对目标VL任务进行联合优化,因此在发送到VL模型之前,object detector计算出的特征不能被进一步细化。举个例子:
对(1)来说,现有的大部分工作都遵循之前的工作,在Visual Genome上对object detector进行预训练,以实现目标的检测和属性分类,这也意味着对象特征可能擅长编码以对象为中心的信息,如对象所属的类别、位置和属性,但不擅长编码其他关键信息,以image caption幕为例;如图1所示,这些关键信息包括对象之间的关系(对象谓词),图像/场景级信息等。因此,本文的第一个目标是为被检测对象提供补充信息。
受视觉Visual Genome数据集构造方式的启发,我们提议以上下文文本描述的形式为图像子区域提供补充但必要的信息,然而,生成图像子区域的描述需要训练另一种图像字幕模型,这本身可能不是一项容易的任务。因此,我们建议将文本生成问题转化为一个跨模态检索问题:给定一个图像子区域,从描述数据库中检索最相关的前k个文本描述。进行跨模态检索的一种方法是搜索视觉上相似的图像,并返回该图像的配对文本。然而,我们认为,我们可以有效地利用最近在大规模图像和文本对(CLIP)上的跨模态预训练方面的进展,直接检索给定图像的相关文本。CLIP有两个分支,CLIP- i和CLIP- t,分别将图像和文本编码为全局特征表示,并训练将成对的图像和文本放到一起,将未成对的图像和文本放到一起。我们在第4.3节中表明,与通过视觉相似性间接检索的文本描述相比,通过CLIP检索的文本描述与图像内容更相关,通过CLIP检索到的文本描述提供了丰富和互补的信息,从而大大提高了性能。
对(2)来说,在训练VL任务的时候我们都会冻结object detector的参数,这意味着被检测对象和输入图像之间的条件作用关系没有与目标VL任务共同优化。因此,从object detector检测到的对象特征并不一定完全适用于image caption领域。因此,本文的第二个目标是通过结合目标VL任务来强化检测目标和输入图片的条件关系
为了加强(2)的条件关系,我们应该以一种尽可能保留与目标VL任务相关信息的方式将输入图像编码为一个全局特征表示。本文选择CLIP模型的图像分支CLIP- i作为图像编码器。由于CLIP也在跨模态VL任务上进行了预训练,我们在第4.3节中展示,与仅在图像数据集上预训练的模型相比,它可以更好地编码与目标VL任务相关的信息。然后,我们使用一个与目标VL任务联合优化的全连接(FC)层来建模条件关系。
在本文中,我们在图像字幕的VL任务上验证了我们提出的方法。通过解决上述使用冻结预训练目标检测器的两个问题,我们的方法改进了SoTA图像字幕模型M2, CIDEr中提高了+7.2%,BLEU-4中提高了+1.3%。
综上所述,我们作出了以下贡献:
1.发现了使用来自预训练对象检测器的被检测对象对输入图像进行编码的潜在问题
2.利用CLIP的跨模态联合嵌入空间,提出了一种跨模态检索模块,该模块能检索一组上下文文本描述,该描述用来补充检测到的对象信息
3.提出一种图像调理模块,加强和共同优化被检测对象与输入图像之间的条件关系,使特征更有效,支持接地等任务
4.大幅改进SoTA仅对象baseline模型,并为提议的两个模块和每个模块中的设计选择提供彻底的定量和定性分析。
2.Method
2.1Graphical Model

图2:(a)大多数现有的image caption模型的图形模型,其中X是输入图像,O是由预先训练过的冻结对象检测器检测到的一组对象;(b)我们提出的带有新引入节点T的模型,该模型表示图像子区域的一组文本描述。
现有的大多数工作都用如图2a所示的图形模型来建模图像配图问题,其中给定一个输入图像X,一个预先训练过的冻结对象检测器检测到一组对象O,并以O为条件生成标题Y。图2a所示的链结构图形模型可以推导为:
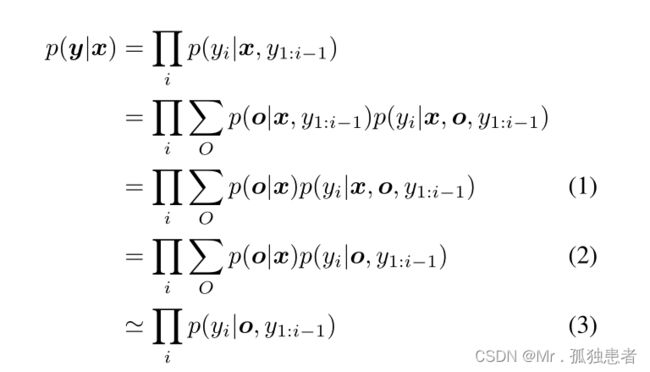
(1)能推导到(2)是因为我们假设了o完全编码x的所有必要信息,因此yi与x有条件独立。(3)约等于(2)是因为研究者通常采用argmax和阈值从对象检测器中选择一组固定的被检测对象。因此从上面导出的图形模型中,我们可以清楚地看到冻结的预先训练过的对象检测器所产生的两个主要问题。
首先,假设o完全编码了x的所有必要信息是不一定成立的。在实践中,在Visual Genome上预训练的用于对象检测和属性预测的对象检测器可能无法编码x的关键信息,如对象之间的关系和图像/场景级信息。其次,被检测对象o和输入图像x之间的条件关系由预先训练的冻结对象检测器计算,并没有与目标图像字幕任务联合优化。因此,在发送到自动回归标题生成模型之前,冻结的预先训练的对象检测器计算出的特征不能被优化,导致潜在的糟糕特征,特别是当它们在不同的数据集上训练时。
为了缓解问题(1),一个基本的解决方案是预先训练对象检测器来预测其他信息,例如对象之间的谓词,以便o可以对更完整的信息进行编码。然而,有效地训练网络来建模对象之间的交互,特别是跨数据集仍然是一个开放的研究问题。因此,在本文中,我们建议在模型中增加一个节点T,如图2b所示,对与O互补的信息进行编码,而无需对目标检测器进行重新训练。通过同时包含O和T,对X的信息进行了更完整的编码,从而更好地支持了方程1和方程2之间的条件独立假设。因此我们的改进后的生成公式可以表示为

为了缓解问题(2),我们建议使用一个全连接(FC)层,以输入图像X的特征为条件,细化每个检测目标的特征。FC层与图像字幕任务的训练目标联合优化,以加强O和X之间的条件关系。我们表明,这种特征细化可以定性和定量改进的结果。

图3:模型架构。我们提出(1)一个跨模态检索模块来检索一组上下文文本描述,这些文本描述提供了与被检测对象相补充的信息,如黄色框所示。我们还提出(2)一个图像调理模块来加强被检测对象和输入图像之间的条件关系,如绿色框所示。带有阴影模式的模型(文本编码器、图像编码器和对象检测器)被预先训练并保持固定。只有fc和字幕模型为目标VL任务进行训练。L符号表示沿特征维的拼接操作。每个标记(□符号)代表一个d维特征向量。图像特征(绿色令牌)在拼接操作之前被广播。
我们在图3中说明了整个模型。为了解决问题(1),我们引入了一个跨模态检索模块(黄框),从输入图像中检索一组文本描述T,其编码的信息与被检测对象O互补。为了解决问题(2),我们引入了一个图像调理模块(绿框)来加强被检测对象和输入图像之间的条件关系。我们方法的关键在于,这两种方法都允许我们利用最近引入的大规模跨模态模型。在本节的其余部分中,我们将描述如何在第2.2节中获得T,以及如何在第2.3节中建模条件关系。
2.2Text Descriptions

图4:最相关的五个文本描述分别对应于(a)原始图像,(b)图像分成五块,©图像分成九块。对于分成五块和九块的图像,我们展示了对应蓝框里的图像所检索到的文本描述。
在上一节中,我们引入了T,这是一组文本描述,它提供了与被检测对象o相补充的信息。想象一下,当一个人被要求描述一幅图像时,他可能首先关注图像的局部区域,然后逐渐将局部信息合并,生成对整个图像的最终描述。同样,我们建议为图像子区域生成如图4所示的文本描述,以便这些描述包含更多的细节,并提供更完整的输入图像信息,以便在后期进行合并。与其训练另一种标题模型来生成图像子区域的描述(这本身可能不是一项容易的任务),我们建议从描述数据库中检索每个图像子区域的前k个最相关的描述,从而将这变成一个跨模态检索问题。我们描述跨模态检索的三个步骤如下。
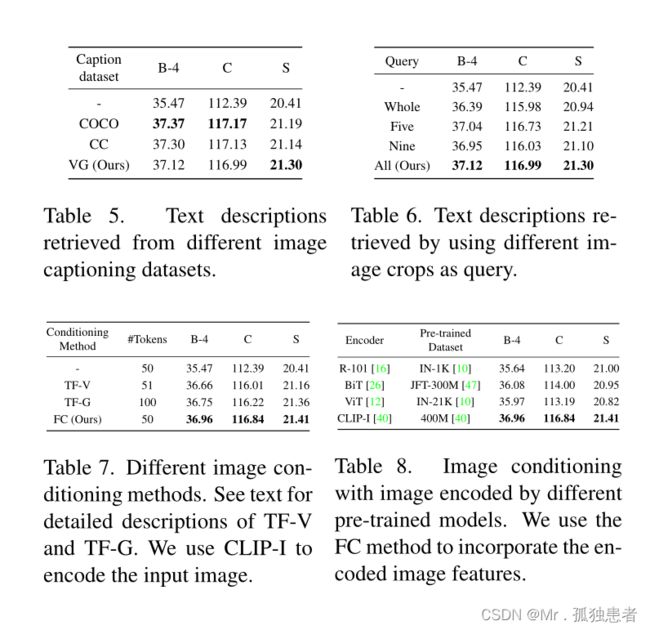
描述数据库:描述数据库是一个图像子区域的相关文本描述的来源,我们选择最相关的前k个。在本文中,我们建议解析来自Visual Genome数据集(该数据集已被普遍用于训练对象检测器)的标注,以构建描述数据库。我们没有从Visual Genome中获取包含许多相似句子的区域描述,而是解析属性和关系的注释。具体来说,属性注释采用“属性-对象”对的形式。我们首先将对象名称转换为其同义词集规范形式,然后收集所有“属性-对象”对。另一方面,关系注释采用“主语-谓词-对象”三连词的形式。类似地,我们将主题和对象名称转换为它们的同义词集规范形式,然后收集所有“主题-谓词-对象”三联。最终,我们将收集到的所有“属性-对象”对和“主题-谓词-对象”三元组合并,并删除重复的内容,以构建描述数据库。
文本描述检索。我们的目标是在给定图像子区域查询的描述数据库中检索最相关的前k个文本描述。这涉及到两个子问题:(1)如何生成图像子区域(2)如何在图像和文本之间进行跨模态检索。对于(1),我们建议生成原图像的分成五份(图4b)和分成九份(图4c)。这些crop可能包含多个对象,而不仅仅是一个单一的对象,如果我们能够检索到crop的良好文本描述,这对于捕获对象之间的交互是有益的。对于(2),我们建议利用CLIP[40]的跨模态联合嵌入来解决这个跨模态检索问题。CLIP模型有两个分支:图像分支CLIP- i和文本分支CLIP- t,分别将图像和文本编码为全局特征表示。CLIP针对大规模的图像和文本对进行训练,这样配对的图像和文本在嵌入空间中被放到一起,而未配对的图像和文本被分开。在预先训练的CLIP模型下,跨模态检索问题变成了在CLIP的跨模态嵌入空间中的最近邻搜索。具体来说,我们使用CLIP-T将描述数据库中的所有文本描述编码为搜索键。五个crop和九个crop的图像子区域以及原始图像被CLIP-I编码作为query。然后,我们在描述数据库中搜索余弦相似度分数最高的前k个文本描述。因此,我们将有一组检索到的文本描述T = {ti,j,k|i∈{original, five,nine}, j∈{1,2,…, #cropsi}, k∈{1,2,…, top-k}},其中下标I表示它是来自原始图像、五个crop与九个crop;下标j表示ti的第j种crop(例如,左上、右下等表示5种crop);#crop {original, 5,9}分别等于{1,5,9};下标k表示前k次检索。图4显示了前5个结果的一些示例。
文本编码。在检索文本描述集T = {ti,j,k}后,我们使用预先训练的文本编码器将它们中的每一个编码为全局表示。在本文中,我们使用一个冻结的预训练CLIP- t作为文本编码器,因为CLIP在VL任务上也进行了类似的预训练,因此它可以更好地从检索到的文本描述中为目标VL任务编码相关信息。上面描述的三个步骤,从构建描述数据库到搜索描述数据库,最后为T编码检索到的文本描述,可以对基准数据集中的每个图像以与检测到的对象o相同的方式离线完成。为了进一步区分不同的i(原始的、五个crop或九个crop)和j(对于ti的第j种crop),我们为不同的i和j对ti、j、k添加了一个可学习的嵌入。
2.3Image Conditioning
在2.1节中,我们提出对被检测对象O和输入图像X之间的条件关系进行建模和强化,以便在发送到字幕模型之前,对目标检测器计算出的特征进行细化。由于文本描述也是通过预训练的CLIP模型离线检索的,我们同样希望加强检索到的文本描述T和输入图像x之间的条件关系,如图3的绿色框所示,我们建议在输入图像上对每个检测到的对象和检索到的文本描述进行条件化,并通过完全连接(FC)层对这种条件关系建模。

Image Captioning
将图像条件对象(o)和文本描述(o)合并到图像标题模型中是很简单的。
如式1所示,图像标题模型通常是一个自回归模型p(yi|o, y1:i−1),它以一个被检测对象的序列o为输入。因此,在不修改图像字幕模型的情况下,我们只需要沿着序列维数z = [ˆo, ˆtoriginal, ˆtfive, ˆtnine]将图像条件对象口令o和口令文本描述口令ti串联起来,并将z作为p(yi|z, y1:i−1)输入其中。然后,可以用常用的最大对数似然损失来训练模型,并使用CIDEr评分作为奖励对RL损失进行微调,方法与前面相同。
3. Experiments
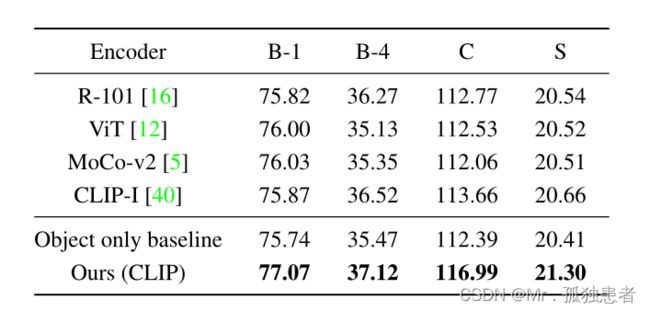
MS-COCO Karpathy split测试集上的图像字幕结果

Detector pre-training v.s. transformer pre-training.

消融实验

用不同的图像编码器通过视觉相似度检索文本描述