贝叶斯优化LSTM超参数
1、摘要
本文主要讲解:使用贝叶斯优化LSTM超参数
主要思路:
- 下载IMDB数据集,并将其变为序列数据
- 建立LSTM模型并训练
- 画准确率和损失曲线图
2、数据介绍
IMDB 数据集介绍
IMDB 数据集包含来自互联网电影数据库(IMDB)的 50 000 条严重两极分化的评论。数据集被分为用于训练的 25 000 条评论与用于测试的 25 000 条评论,训练集和测试集都包含 50% 的正面评论和 50% 的负面评论。
train_labels 和 test_labels 都是 0 和 1 组成的列表,其中 0代表负面(negative),1 代表正面(positive)

3、相关技术
以下是贝叶斯优化的过程图解:
为了取得这个函数的最小值,贝叶斯是这样去进行优化的
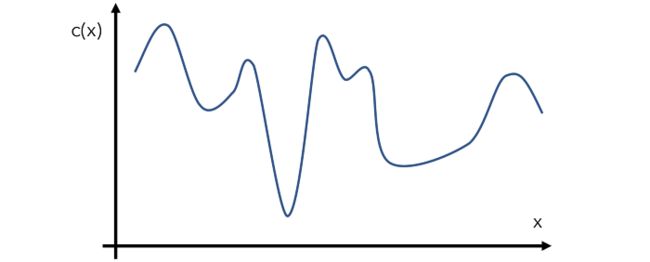

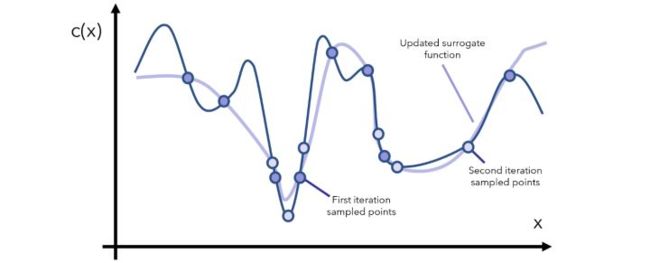
基于构造的代理函数,我们就可以在可能是最小值的点附近采集更多的点,或者在还没有采样过的区域来采集更多的点,有了更多点,就可以更新代理函数,使之更逼近真实的目标函数的形状,这样的话也更容易找到目标函数的最小值,这个采样的过程同样可以通过构建一个采集函数来表示,也就是知道了当前代理函数的形状,如何选择下一个x使得收益最大。
4、完整代码和步骤
首先安装贝叶斯优化依赖包
pip install bayesian-optimization
主运行程序入口
import matplotlib.pyplot as plt
import os
from bayes_opt import BayesianOptimization
from keras.callbacks import EarlyStopping, ModelCheckpoint
from keras.datasets import imdb
from keras.layers import Dense, Embedding, Dropout, LSTM
from keras.models import Sequential
from keras.preprocessing import sequence
def prepare_data(max_features, max_length):
(x_train, y_train), (x_val, y_val) = imdb.load_data(path="imdb.npz",
num_words=max_features,
skip_top=0,
maxlen=None,
seed=113,
start_char=1,
oov_char=2,
index_from=3)
x_train = sequence.pad_sequences(x_train, maxlen=max_length)
x_val = sequence.pad_sequences(x_val, maxlen=max_length)
return (x_train, y_train), (x_val, y_val)
def build_and_evaluate(data, max_features, dropout=0.2, lstm_units=32, fc_hidden=128, lr=3e-4, verbose=False):
(x_train, y_train), (x_val, y_val) = data
model = Sequential()
model.add(Embedding(input_dim=max_features, output_dim=lstm_units, input_length=x_train.shape[1]))
model.add(LSTM(lstm_units))
model.add(Dense(units=fc_hidden, activation='relu'))
model.add(Dropout(dropout))
model.add(Dense(units=1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
history = model.fit(x_train, y_train, validation_data=(x_val, y_val), epochs=100,
batch_size=512, verbose=verbose,
callbacks=[EarlyStopping(monitor='val_loss', patience=5, baseline=None),
ModelCheckpoint(model_dir + '/best_model.h5', monitor='val_loss',
save_best_only=True)])
plot_history(history)
return history.history['val_acc'][-1]
def plot_history(history):
# summarize history for accuracy
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()
def overfit_batch(sample_size=2000):
max_features = 5000
(x_train, y_train), (x_val, y_val) = prepare_data(max_features=max_features, max_length=10)
data = (x_train[:sample_size], y_train[:sample_size]), (x_val[:sample_size], y_val[:sample_size])
history = build_and_evaluate(data, max_features, verbose=True)
plot_history(history)
return history.history['val_acc'][-1]
def bayesian_opt(data, max_features):
optimizer = BayesianOptimization(
f=build_and_evaluate(data, max_features),
pbounds={'dropout': (0.0, 0.5), 'lstm_units': (32, 500), 'fc_hidden': (32, 256)},
)
optimizer.maximize(
init_points=10,
n_iter=30,
)
model_dir = 'models'
if not os.path.exists(model_dir):
os.makedirs(model_dir)
# overfit_batch()
bayesian_opt(prepare_data(max_features=5000, max_length=500), 5000)