基于Pytorch通过实例详细剖析CNN
文章目录
-
-
- 一、前言
-
- 1)免责声明
- 2)写点我自己的理解
- 3)看本文之前需要了解的知识
- 二、实例说明
-
- 1)要解决什么问题
- 2)CNN网络模型训练组数据
- 3)CNN网络模型
- 三、基于Pytorch的CNN网络模型代码
- 四、深入剖析
- 1)learning rate和epoch怎么确定?
- 2)看看权重是怎样的
- 3)理解loss.backward()
- 4)理解optimize.step()
- 5)为什么要用zero_grad()?
-
一、前言
1)免责声明
按照国际惯例,最先是免责声明:本文只是我自己学习卷积神经网络的理解,内容不乏不准确甚至错误的地方,希望批评指正,共同进步。
2)写点我自己的理解
本人对于学习的态度一贯是“在学会走之前,要先学会跑,然后再学会走”,对于CNN以及深度学习理论,在网上可以找到大量的学习资料及培训课程,但是这些往往都是人云亦云,知其然不知其所以然,一上来就讲很多复杂的理论,而没有把握住CNN的本质。
卷积神经网络,或者说任意一种神经元网络模型其本质都是通过多个非线性运算的线性组合,得到期望的目标函数,给定输入之后能得到正确(接近正确)的输出。其本质并不复杂。
之所以我们见到的很多深度学习网络模型很复杂,是因为要解决的现实问题很复杂,就好像一座宫殿很复杂,但是其本质都是用一块块简单的砖头堆叠起来的。
本文的主旨在于,用一个简化的实例,来深入学习卷积神经元网络(CNN)
3)看本文之前需要了解的知识
本文对于卷积神经网络理论不再做任何赘述,只需要了解最基本的卷积层操作以及有基本的Pytorch编程基础即可看懂本文。
二、实例说明
1)要解决什么问题
我们要构建一个这样的卷积神经网络: 对于给定的一个3×3矩阵,如果矩阵中所有元素都一样,比如
[6, 6, 6]
[6, 6, 6]
[6, 6, 6]
则输出“1”(True)。如果所有元素都不一样(随机数),则输出“0”(False)。
2)CNN网络模型训练组数据
训练组数据包含真样本(Train_set_true)从-50~49共100个:
[-50, -50, -50] [-49, -49, -49] [-48, -48, -48] …[0, 0, 0] …[49, 49, 49]
[-50, -50, -50] [-49, -49, -49] [-48, -48, -48] …[0, 0, 0] …[49, 49, 49]
[-50, -50, -50] [-49, -49, -49] [-48, -48, -48] …[0, 0, 0] …[49, 49, 49]
还有假样本(Train_set_false)使用torch.rand()随机生成100个3×3矩阵。
3)CNN网络模型
- 模型结构:卷积层(stride为1,kernel为2×2)+LeakyReLu+卷积层(stride为1,kernel为2×2)+Sigmoid。由于问题并不复杂,只构建很简单的模型结构就能实现;
- 损失函数:本文的实例是一个典型的二分类问题(判断是否),采用BCE(Binary CrossEntropy)损失函数,本实例损失函数有两个:判断为真的损失函数(loss_true)和判断为假的损失函数(loss_false );
- 优化函数:Adadelta(关于不同优化函数的介绍推荐一篇文章:优化函数介绍,这里为什么选Adadelta,其实选择其他优化函数估计结果也差不多,因为这个实例确实太简单了)
在现实中当然没有这么简单的CNN应用,不过本实例可以看作是现实问题的抽象。输入的这200个训练组矩阵可以看作是200张现实生活中的照片,而所有元素都相等的100个矩阵可以看作照片中有“行人”的照片,而随机生成的100个矩阵可以看作是没有“行人”的照片。我们要做的就是构建一个卷积神经网络模型,这个模型可以判断照片中有“行人”的概率。
三、基于Pytorch的CNN网络模型代码
附在最后
四、深入剖析
1)learning rate和epoch怎么确定?
本文最开始已经说明,CNN网络模型其实更接近工程应用。learning rate和epoch的确定并没有什么理论方法。我认为就是试出来的。。。
以下是learning rate=0.5,epoch=200的结果(蓝色是判断为真的损失函数(loss_true),红色是判断为假的损失函数(loss_false ))
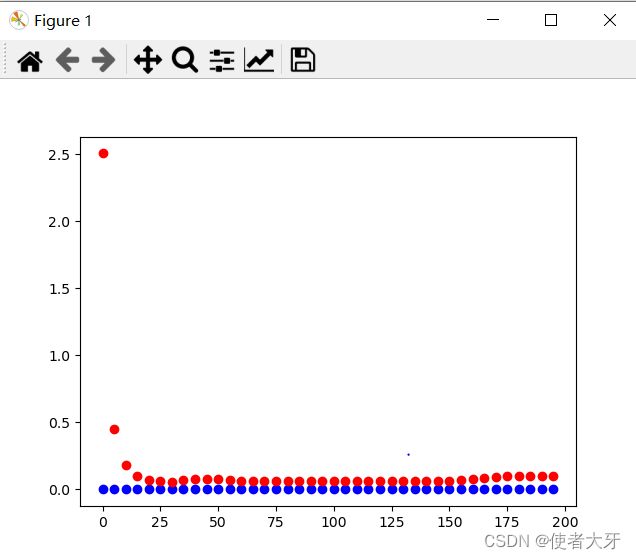
2)看看权重是怎样的
使用.state_dict()函数每隔20个epoch打印一下权中,可以看到每个卷积层的weight和bias。(这里节省篇幅,就只列最后一个权重参数)
OrderedDict([('model.0.weight', tensor([[[[-0.4180, 0.8206],
[ 0.5418, -0.9463]]]])), ('model.0.bias', tensor([0.0090])), ('model.2.weight', tensor([[[[-1.0951, -0.4438],
[-0.7047, -0.8174]]]])), ('model.2.bias', tensor([6.7611]))])
对于实际应用的网络模型,权重文件会很大,而且也“看”不出什么。但是对于这个简单的模型可以打印出权重值,甚至可以不妨手算一下。
从这个实例的权值可以看出,主要起作用的是第一层卷积,其kernel的4个元素求和约为0,如果原始数据(被卷积的矩阵)元素相近那么,第一层卷积输出几乎就是[0],第二层卷积再加一个比较大的bias,再经过sigmoid之后就约为1。如果原始数据元素偏差较大(随机生成),那么第一层卷积大概率会生成一个正值(因为第一个卷积层bias为正),第二层卷积的kernel元素全部为绝对值较大的负值,卷积操作后输出也是一个较大的负值,所以经过Sigmoid之后会基本为0。
3)理解loss.backward()
反向传播其实就是函数对变量求偏导,做个简单的实例就可以理解。
import torch
a = torch.tensor([1],dtype=float,requires_grad=True)
b = torch.tensor([4],dtype=float,requires_grad=True)
c = a**3 + b
c.backward()
print(a.grad)
print(b.grad)
------------------------------输出------------------------------------
tensor([3.], dtype=torch.float64)
tensor([1.], dtype=torch.float64)
对loss函数进行求偏导是为了给下一步.step()操作(让权值逼近loss最小结果)
4)理解optimize.step()
用上一步求出的偏导值对权值进行更新,更新方式和优化函数的种类有关(SGD, Momentum, Adams…),以随机梯度下降(SGD)为例说明:
- 如果求得的偏导为负,则增加一个步长。如果求得的偏导为正,则减少一个步长;
- 步长大小=learning rate×偏导绝对值
高中数学知识
5)为什么要用zero_grad()?
这是一个令新手很费解的操作,但是也很好解释。上面说了.step()是用“上一步求出的偏导值对权值进行更新”,那如果.step()前面有多个求出的偏导值( .backward() )那该怎么办?取最近一个?
实际上.step()会取上面所有的偏导值进行求和,再进行.step()操作,这显然不是我们想要的。所以要用zero_grad()清空除了我们想要的偏导值的其他偏导值(说的有点绕,意思就是去掉之前反向传递得到的数值,只按本次的偏导进行更新权值)
可以试试把zero_grad()注释掉看看loss会不会收敛。
最后附上源码
import torch
import matplotlib.pyplot as plt
import numpy
import codecs
class CNN(torch.nn.Module):
def __init__(self):
super(CNN,self).__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2),
torch.nn.LeakyReLU(),
torch.nn.Conv2d(in_channels=1, out_channels=1, kernel_size=2),
torch.nn.Sigmoid() #最后一个要用sigmoid,否则loss的输入可能不在0~1之间
)
def forward(self, x):
return self.model(x)
cnn = CNN()
train_base = numpy.ones([1,1,3,3])
train_set_true = torch.tensor([i*train_base for i in range(-50,50,1)]) #生成(batch=100,in_channel=1,out_channel=1,3,3)的训练数据集,这些都是真样本,符合规律
train_set_false = torch.rand(100,1,1,3,3)*100-50 #生成(batch=100,in_channel=1,out_channel=1,3,3)的训练数据集,这些都是假样本,都是噪声点
train_set_true = train_set_true.to(torch.float64)
train_set_false = train_set_false.to(torch.float64)
train_target_true = torch.ones(1,1,1,1) #生成训练目标,真目标为1
train_target_false = torch.zeros(1,1,1,1) #生成训练目标,假目标为0
cnn_loss = torch.nn.BCELoss() #定义损失函数为二分交叉熵
cnn_opt = torch.optim.Adadelta(cnn.parameters(),lr=0.5) #定义cnn权重的优化函数为adadelta
epoch = 200
for i in range(epoch):
for iteration,train_sample_true in enumerate(train_set_true):
cnn_opt.zero_grad() #训练的过程通常使用mini-batch方法,所以如果不将梯度清零的话,梯度会与上一个batch的数据相关,因此该函数要写在反向传播和梯度下降之前。
cnn_output_true = cnn(train_sample_true.to(torch.float32))
loss_true = cnn_loss(cnn_output_true, train_target_true)
loss_true.backward()
cnn_opt.step() #optimizer.step()函数的作用是执行一次优化步骤,通过梯度下降法来更新参数的值。因为梯度下降是基于梯度的,所以在执行optimizer.step()函数前应先执行loss.backward()函数来计算梯度。
for iteration, train_sample_false in enumerate(train_set_false):
cnn_opt.zero_grad()
cnn_output_false = cnn(train_sample_false.to(torch.float32))
loss_false = cnn_loss(cnn_output_false, train_target_false)
loss_false.backward()
cnn_opt.step()
if i%5 == 0 :
loss_true_numpy = loss_true.detach().numpy()
loss_false_numpy = loss_false.detach().numpy()
plt.scatter(i, loss_true_numpy, c='b')
plt.scatter(i, loss_false_numpy, c='r')
if i%20 == 0:
print(cnn.state_dict())
plt.show()
if __name__ == '__main__':
print(cnn(torch.tensor([[[[200,200,200],[200,200,200],[200,200,200]]]]).to(torch.float32)))
print(cnn(torch.tensor([[[[11.11,11.11,11.11],[11.11,11.11,11.11],[11.11,11.11,11.11]]]]).to(torch.float32)))
print(cnn(torch.tensor([[[[10,-43,7],[49,50,-51],[39,-59,71]]]]).to(torch.float32)))
print(cnn(torch.tensor([[[[5.6,9.8,100],[12,65,6],[0.7,43,4]]]]).to(torch.float32)))