快乐的强化学习2——DQN及其实现方法
快乐的强化学习2——DQN及其实现方法
- 学习前言
-
- 简介
- DQN算法的实现
- 具体实现代码
学习前言
刚刚从大学毕业,近来闲来无事,开始了机器学习的旅程,深度学习是机器学习的重要一环,其可以使得机器自我尝试,并通过结果进行学习。

在机器学习的过程中,我自网上了解到大神morvanzhou,一个从土木工程转向了计算机的“聪明绝顶”的、英语特好的男人。
morvanzhou的python个人主页,请有兴趣的同学关注大神morvanzhou的python教程。
简介
DQN是一种结合了深度学习与强化学习的一种学习方法,它以强化学习Q-Learning为基础,结合tensorflow的神经网络。强化学习Q-Learning是一种非常优秀的算法,但是由于现在许多问题的环境非常复杂,如果把每一种环境都单独列出来,整个Q表会非常大,且更新的时候检索时间较长。所以如果可以不建立Q表,只通过每个环境的特点就可以得出整个环境的Q-Value,那么Q表庞大冗杂的问题就迎刃而解了。
其与常规的强化学习Q-Learning最大的不同就是,DQN在初始化的时候不再生成一个完整的Q-Table,每一个观测环境的Q值都是通过神经网络生成的,即通过输入当前环境的特征Features来得到当前环境每个动作的Q-Value,并且以这个Q-Value基准进行动作选择。
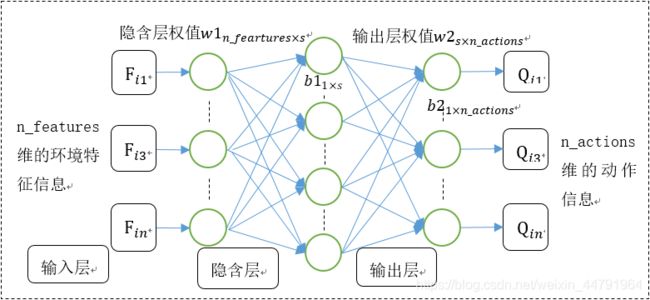
DQN一共具有两个神经网络,一个是用于计算q_predict,一个是用于计算q_next的。用于计算q_predict的神经网络,我们简称其为Net_Pre,预测结果被称作Q估计;用于计算q_next我们简称其为Net_Next。预测结果被加工后称作Q现实
DQN的更新准则与Q-Learning的更新准则类似,都是通过所处的当前环境对各个动作的预测得分,下一步的环境的实际情况进行得分更新的,但是DQN更新的不再是Q表,而是通过所处的当前环境对各个动作的预测得分和下一步的环境的实际情况二者的误差更新Net_Pre和Net_Next的参数。
如果大家对Q-Learning还有疑惑,请大家关注我的另一篇博文https://blog.csdn.net/weixin_44791964/article/details/95410737
DQN算法的实现
接下来我将以小男孩取得玩具为例子,讲述DQN算法的执行过程。

在一开始的时候假设小男孩不知道玩具在哪里,Net_Pre和Net_Next都是随机生成的,在进行第一步动作前,小男孩通过Net_Pre获得其对于当前环境每一个动作的得分的预测值,并在其中优先选择得分最高的一个动作作为下一步的行为Action,并且通过该Action得到下一步的环境。
# 刷新环境
env.render()
# DQN 根据观测值选择行为
action = RL.choose_action(observation)
# 环境根据行为给出下一个 state, reward, 是否终止
observation_, reward, done = env.step(action)
在获得所处的当前环境对各个动作的预测得分和下一步的环境的实际情况的时候,常规的Q-Learning便可以通过:
self.q_table.loc[observation_now, action] += self.lr * (q_target - q_predict)
进行Q-Table更新,但是DQN不一样,DQN会将这一步按照一定的格式存入记忆,当形成一定规模的时候再进行Net_Pre的更新。在python中,其表示为:
# 控制学习起始时间和频率 (先累积一些记忆再开始学习)
if (step > 200) and (step % 5 == 0):
RL.learn()
可能同学们会很奇怪,为什么是进行Net_Pre的更新而不是进行Net_Pre和Net_Next的更新,其实是因为通过Net_Pre得到的Q_predict的是人物对当前环境的认知,而通过Net_Next通过一定处理之后获得的Q_target是下个环境的实际得分,我们只能通过下个环境的实际得分来更新人物对当前环境的认知。
这是否意味着Net_Next不需要更新呢?答案是否定的,因为当前的Net_Next都是随机生成的,其并没有考虑地图上的一个重要信息,就是每个环境的reward。当小男孩掉下悬崖的时候,他的得分是-1;当小男孩拿到玩具的时候,他的得分是1。因此,每当进行一定次数的Net_Pre的更新后,就要将最新的Net_Pre的参数赋值给Net_Next。
在python中,其表示为:
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
那么Net_Pre的参数又是如何更新的呢,通过Net_Pre得到的Q_predict的是人物对当前环境的认知,而通过Net_Next通过一定处理之后获得的Q_target是下个环境的实际得分,那么Q_target-Q_predict得到便是实际与预测之间的差距,即Q现实与Q估计的差距,我们将其作为cost传入tensorflow,便可以使用一定的优化器缩小cost,实现Net_Pre神经网络的训练。接下来让我们看看学习过程是如何实现的。
def learn(self):
# 确认是否到达了需要进行两个神经网络的参数赋值的代数,是则赋值
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# 根据当前memory当中的size进行提取,在没有到达memory_size时,根据当前的memory里的数量进行提取,提取的数量都是batchsize
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
#根据sample_index提取出batch
batch_memory = self.memory[sample_index, :]
#通过神经网络获得q_next和q_eval。
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:],
self.s: batch_memory[:, :self.n_features],
})
#该步主要是为了获得q_next, q_eval的格式
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
#取出eval的每一个行为
eval_act_index = batch_memory[:, self.n_features].astype(int)
#取出eval的每一个得分
reward = batch_memory[:, self.n_features + 1]
#取出每一行的最大值、取出每个环境对应的最大得分
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
#利用q_target和q_predict训练
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
#如果存在epsilon_increment则改变epsilon的值
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
可能大家看完这个还是一头雾水,现在,我将以伪代码的方式,将整个DQN执行一遍给大家看一下。
初始化测试环境对象
初始化DQN的大脑对象
step = 0
for episode in range(TIMES):
初始化环境
while(1):
#刷新环境
env.render()
#根据观测值选择行为
action = RL.choose_action(observation)
#获得环境下一步行为,判断下一步环境是否终止, 获得下一步环境的得分。
observation_, reward, done = env.step(action)
#调用存储函数存储记忆
RL.store_transition(observation, action, reward, observation_)
#先累积一些记忆再开始学习
if (step > 200) and (step % 5 == 0):
RL.learn()
#将下一个 state_ 变为 下次循环的 state
#如果终止, 就跳出循环
if done:
break
step += 1 # 总步数
在整个函数的执行过程中DQN的大脑包括以下部分,其对应的功能为
| 模块名称 | 作用/功能 |
|---|---|
| 初始化 | 初始化学习率、可执行动作、全局学习步数、记忆库大小、每次训练的batch大小、两个神经网络等参数 |
| 动作选择 | 根据当前所处的环境特征和Net_Pre获得当前环境各个动作的Q_Value,并进行动作选择 |
| 学习 | 通过Net_Next获得q_next,再通过一定运算得到q_target,根据q_predict和q_target进行网络更新 |
| 记忆存储 | 按照一定格式存储 当前环境特点、下一步环境特点、得分reward、当前环境的动作。 |
具体实现代码
具体的实现代码分为三个部分,这是第一部分,主函数:
from maze_env import Maze
from RL_brain import DeepQNetwork
def run_maze():
step = 0 # 用来控制什么时候学习
for episode in range(300):
# 初始化环境
observation = env.reset()
while True:
# 刷新环境
env.render()
# DQN 根据观测值选择行为
action = RL.choose_action(observation)
# 环境根据行为给出下一个 state, reward, 是否终止
observation_, reward, done = env.step(action)
# DQN 存储记忆
RL.store_transition(observation, action, reward, observation_)
# 控制学习起始时间和频率 (先累积一些记忆再开始学习)
if (step > 200) and (step % 5 == 0):
RL.learn()
# 将下一个 state_ 变为 下次循环的 state
observation = observation_
# 如果终止, 就跳出循环
if done:
break
step += 1 # 总步数
# end of game
print('game over')
env.destroy()
if __name__ == "__main__":
env = Maze()
RL = DeepQNetwork(env.n_actions, env.n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=200, # 每 200 步替换一次 target_net 的参数
memory_size=2000, # 记忆上限
# output_graph=True # 是否输出 tensorboard 文件
)
env.after(100, run_maze)
env.mainloop()
RL.plot_cost() # 观看神经网络的误差曲线
第二部分是DQN的大脑:
import numpy as np
import pandas as pd
import tensorflow as tf
np.random.seed(1)
tf.set_random_seed(1)
# Deep Q Network off-policy
class DeepQNetwork:
def __init__(
self,
n_actions,
n_features,
learning_rate=0.01,
reward_decay=0.9,
e_greedy=0.9,
replace_target_iter=300,
memory_size=500,
batch_size=32,
e_greedy_increment=None,
output_graph=False,
):
self.n_actions = n_actions #动作数量
self.n_features = n_features #观测环境的特征数量
self.lr = learning_rate #学习率
self.gamma = reward_decay
self.epsilon_max = e_greedy #处于epsilon范围内时,选择value值最大的动作
self.replace_target_iter = replace_target_iter #进行参数替换的轮替代数
self.memory_size = memory_size #每个memory的size
self.batch_size = batch_size #训练batch的size
self.epsilon_increment = e_greedy_increment
self.epsilon = 0 if e_greedy_increment is not None else self.epsilon_max
self.learn_step_counter = 0 # 初始化全局学习步数
# 初始化用于存储memory的地方 [s, a, r, s_]
self.memory = np.zeros((self.memory_size, n_features * 2 + 2))
# 利用get_collection获得eval和target两个神经网络的参数
self._build_net()
t_params = tf.get_collection('target_net_params')
e_params = tf.get_collection('eval_net_params')
# 将e的参数赋予t
self.replace_target_op = [tf.assign(t, e) for t, e in zip(t_params, e_params)]
self.sess = tf.Session()
#如果output_graph==True则在tensorboard上输出结构
if output_graph:
tf.summary.FileWriter("logs/", self.sess.graph)
self.sess.run(tf.global_variables_initializer())
#用于存储历史cost值
self.cost_his = []
def _build_net(self):
# ------------------ build evaluate_net ------------------
self.s = tf.placeholder(tf.float32, [None, self.n_features], name='s')
#输入值,列的内容为观测到的环境的特点,一共有n个,用于计算对当前环境的估计
self.q_target = tf.placeholder(tf.float32, [None, self.n_actions], name='Q_target')
#该层神经网络用于计算q_eval
with tf.variable_scope('eval_net'):
# 神经网络的参数
c_names =['eval_net_params', tf.GraphKeys.GLOBAL_VARIABLES] #collection的名字
n_l1 = 10 #隐含层神经元的数量
w_initializer = tf.random_normal_initializer(mean = 0., stddev = 0.3) #初始化正态分布生成器
b_initializer = tf.constant_initializer(0.1) #常数生成器
# q_eval神经网络的第一层
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s, w1) + b1)
# q_eval神经网络的第二层
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_eval = tf.matmul(l1, w2) + b2
with tf.variable_scope('loss'): # q_eval神经网络的损失值,其将q_eval的损失值和q_target对比
self.loss = tf.reduce_mean(tf.squared_difference(self.q_target, self.q_eval))
with tf.variable_scope('train'): # 利用RMSPropOptimizer进行训练
self._train_op = tf.train.RMSPropOptimizer(self.lr).minimize(self.loss)
# ------------------ build target_net ------------------
self.s_ = tf.placeholder(tf.float32, [None, self.n_features], name='s_') # input
#该层神经网络用于计算q_target
with tf.variable_scope('target_net'):
#神经网络的参数
c_names = ['target_net_params', tf.GraphKeys.GLOBAL_VARIABLES]
#q_target第一层
with tf.variable_scope('l1'):
w1 = tf.get_variable('w1', [self.n_features, n_l1], initializer=w_initializer, collections=c_names)
b1 = tf.get_variable('b1', [1, n_l1], initializer=b_initializer, collections=c_names)
l1 = tf.nn.relu(tf.matmul(self.s_, w1) + b1)
#q_target第二层
with tf.variable_scope('l2'):
w2 = tf.get_variable('w2', [n_l1, self.n_actions], initializer=w_initializer, collections=c_names)
b2 = tf.get_variable('b2', [1, self.n_actions], initializer=b_initializer, collections=c_names)
self.q_next = tf.matmul(l1, w2) + b2
def store_transition(self, s, a, r, s_):
#判断是否有memory_counter属性。没有则加入。该部分用于存储当前状态,action,得分,预测状态。
if not hasattr(self, 'memory_counter'):
self.memory_counter = 0
#将当前状态,action,得分,预测状态进行水平堆叠
transition = np.hstack((s, [a, r], s_))
#index保证在memory_size以内
index = self.memory_counter % self.memory_size
#self.memory中加入一行
self.memory[index, :] = transition
#数量加1
self.memory_counter += 1
def choose_action(self, observation):
#变成可以输入给神经网络的行向量
observation = observation[np.newaxis, :]
if np.random.uniform() < self.epsilon:
#如果在epsilon内,通过运算得出value最大的action,否则随机生成action
actions_value = self.sess.run(self.q_eval, feed_dict={self.s: observation})
action = np.argmax(actions_value)
else:
action = np.random.randint(0, self.n_actions)
return action
def learn(self):
# 确认是否到达了需要进行两个神经网络的参数赋值的代数,是则赋值
if self.learn_step_counter % self.replace_target_iter == 0:
self.sess.run(self.replace_target_op)
print('\ntarget_params_replaced\n')
# 根据当前memory当中的size进行提取,在没有到达memory_size时,根据当前的memory里的数量进行提取,提取的数量都是batchsize
if self.memory_counter > self.memory_size:
sample_index = np.random.choice(self.memory_size, size=self.batch_size)
else:
sample_index = np.random.choice(self.memory_counter, size=self.batch_size)
#根据sample_index提取出batch
batch_memory = self.memory[sample_index, :]
q_next, q_eval = self.sess.run(
[self.q_next, self.q_eval],
feed_dict={
self.s_: batch_memory[:, -self.n_features:],
self.s: batch_memory[:, :self.n_features],
})
q_target = q_eval.copy()
batch_index = np.arange(self.batch_size, dtype=np.int32)
#取出eval的每一个行为
eval_act_index = batch_memory[:, self.n_features].astype(int)
#取出eval的每一个得分
reward = batch_memory[:, self.n_features + 1]
#取出每一行的最大值
q_target[batch_index, eval_act_index] = reward + self.gamma * np.max(q_next, axis=1)
#训练
_, self.cost = self.sess.run([self._train_op, self.loss],
feed_dict={self.s: batch_memory[:, :self.n_features],
self.q_target: q_target})
self.cost_his.append(self.cost)
#如果存在epsilon_increment则改变epsilon的值
self.epsilon = self.epsilon + self.epsilon_increment if self.epsilon < self.epsilon_max else self.epsilon_max
self.learn_step_counter += 1
def plot_cost(self):
import matplotlib.pyplot as plt
plt.plot(np.arange(len(self.cost_his)), self.cost_his)
plt.ylabel('Cost')
plt.xlabel('training steps')
plt.show()
第三部分为运行环境:
"""
Reinforcement learning maze example.
Red rectangle: explorer.
Black rectangles: hells [reward = -1].
Yellow bin circle: paradise [reward = +1].
All other states: ground [reward = 0].
This script is the environment part of this example.
The RL is in RL_brain.py.
View more on my tutorial page: https://morvanzhou.github.io/tutorials/
"""
import numpy as np
import time
import sys
if sys.version_info.major == 2:
import Tkinter as tk
else:
import tkinter as tk
UNIT = 40 # pixels
MAZE_H = 4 # grid height
MAZE_W = 4 # grid width
class Maze(tk.Tk, object):
def __init__(self):
super(Maze, self).__init__()
self.action_space = ['u', 'd', 'l', 'r']
self.n_actions = len(self.action_space)
self.n_features = 2
self.title('maze')
self.geometry('{0}x{1}'.format(MAZE_H * UNIT, MAZE_H * UNIT))
self._build_maze()
def _build_maze(self):
self.canvas = tk.Canvas(self, bg='white',
height=MAZE_H * UNIT,
width=MAZE_W * UNIT)
# create grids
for c in range(0, MAZE_W * UNIT, UNIT):
x0, y0, x1, y1 = c, 0, c, MAZE_H * UNIT
self.canvas.create_line(x0, y0, x1, y1)
for r in range(0, MAZE_H * UNIT, UNIT):
x0, y0, x1, y1 = 0, r, MAZE_W * UNIT, r
self.canvas.create_line(x0, y0, x1, y1)
# create origin
origin = np.array([20, 20])
# hell
hell1_center = origin + np.array([UNIT * 2, UNIT])
self.hell1 = self.canvas.create_rectangle(
hell1_center[0] - 15, hell1_center[1] - 15,
hell1_center[0] + 15, hell1_center[1] + 15,
fill='black')
# hell
# hell2_center = origin + np.array([UNIT, UNIT * 2])
# self.hell2 = self.canvas.create_rectangle(
# hell2_center[0] - 15, hell2_center[1] - 15,
# hell2_center[0] + 15, hell2_center[1] + 15,
# fill='black')
# create oval
oval_center = origin + UNIT * 2
self.oval = self.canvas.create_oval(
oval_center[0] - 15, oval_center[1] - 15,
oval_center[0] + 15, oval_center[1] + 15,
fill='yellow')
# create red rect
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# pack all
self.canvas.pack()
def reset(self):
self.update()
time.sleep(0.1)
self.canvas.delete(self.rect)
origin = np.array([20, 20])
self.rect = self.canvas.create_rectangle(
origin[0] - 15, origin[1] - 15,
origin[0] + 15, origin[1] + 15,
fill='red')
# return observation
return (np.array(self.canvas.coords(self.rect)[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
def step(self, action):
s = self.canvas.coords(self.rect)
base_action = np.array([0, 0])
if action == 0: # up
if s[1] > UNIT:
base_action[1] -= UNIT
elif action == 1: # down
if s[1] < (MAZE_H - 1) * UNIT:
base_action[1] += UNIT
elif action == 2: # right
if s[0] < (MAZE_W - 1) * UNIT:
base_action[0] += UNIT
elif action == 3: # left
if s[0] > UNIT:
base_action[0] -= UNIT
self.canvas.move(self.rect, base_action[0], base_action[1]) # move agent
next_coords = self.canvas.coords(self.rect) # next state
# reward function
if next_coords == self.canvas.coords(self.oval):
reward = 1
done = True
elif next_coords in [self.canvas.coords(self.hell1)]:
reward = -1
done = True
else:
reward = 0
done = False
s_ = (np.array(next_coords[:2]) - np.array(self.canvas.coords(self.oval)[:2]))/(MAZE_H*UNIT)
return s_, reward, done
def render(self):
# time.sleep(0.01)
self.update()
除了环境部分外,主函数部分和DQN大脑部分我都进行了详细的备注,由于涉及到模块间的调用,需要设置文件名称,三个文件的名称分别为:run_this.py,RL_brain.py,maze_env.py。
由于代码并不是自己写的,所以就不上传github了,不过还是欢迎大家关注我和我的github
https://github.com/bubbliiiing/
希望得到朋友们的喜欢。
有不懂的朋友可以评论询问噢。