python笔记—>数据分析
目录
一、numpy库的使用方法
1、利用numpy中的array()创建数组
2、利用numpy中的arange()创建数组
3、随机数组创建
4、查看数组属性
5、数组选取
1、一维数组选取
2、二维数组选取
6、数组重塑及转置
1、一维数组重塑
2、二维数组重塑
3、数组转置
7、数组操作
1、添加数组元素
2、删除数组元素
3、缺失值处理
4、重复值处理
5、数组的拼接及拆分
6、数组运算
二、pandas库的使用方法
1、Series及DataFrame对象使用
1、Series对象
2、DataFrame对象
2、读取查看数据
1、使用pandas读取excel中的数据
2、使用pandas读取csv文件
3、选择性读取数据
3、pandas数据处理
1、数据增删查改
2、缺失值处理
3、处理重复值
4、数据排序
5、装置数据表行列
6、将数据表转换为树形结构
7、数据拼接
8、数据的统计运算
9、数据的分布情况
10、相关系数分析
11、分组数据汇总
12、创建数据透视表
一、numpy库的使用方法
1、利用numpy中的array()创建数组
import numpy as np #导入库numpy 命名为np
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) #创建多维数组
c = np.array([1, 2, 3, 4]) #创建一维数组
print(a)
print (c)[[1 2 3]
[4 5 6]
[7 8 9]]
[1 2 3 4]
2、利用numpy中的arange()创建数组
import numpy as np
a=np.arange(1,20,4)
b=np.arange(10)
c=np.arange(1,6)
print(a)
print(b)
print(c)[ 1 5 9 13 17]
[0 1 2 3 4 5 6 7 8 9]
[1 2 3 4 5]
3、随机数组创建
import numpy as np
a=np.random.randn(3)
b=np.random.randn(3,2)
c=np.random.rand(5)
d=np.random.rand(2,3)
e=np.random.randint(1,3,4)
f=np.random.randint(1,5,(2,2))
print("a:",a)
print("b:",b)
print("c:",c)
print("d",d)
print("e:",e)
print("f:",f)a: [-0.08651285 -0.66598846 -1.95221718]
b: [[ 0.80910325 0.27852996]
[ 1.26057639 0.07053796]
[ 1.48869689 -1.73556879]]
c: [0.26452326 0.87471068 0.36306038 0.95570711 0.29538408]
d [[0.05603988 0.6907821 0.33998311]
[0.08633272 0.54519208 0.59673932]]
e: [2 1 1 1]
f: [[1 2]
[4 1]]
4、查看数组属性
import numpy as np
arr=np.array([[1,2],[3,4],[5,6]])
arr1=arr.astype(float) #数组类型转换
print(arr.shape) #数组行列
print(arr.shape[0]) #数组行
print(arr.shape[1]) #数组列
print(arr.size) #数组元素个数
print(arr.dtype) #数组类型
print(arr1,arr1.dtype)
print(arr.ndim) #查看数组维度(3, 2)
3
2
6
float64
[[1 2 3 4]
[5 6 7 8]]
int32
3
5、数组选取
1、一维数组选取
import numpy as np
arr=np.array([6,57,18,95,17,1,12])
print(arr[2])
print(arr[-2])
print(arr[2:])
print(arr[:2])
print(arr[1:6:3])
print(arr[::2])
print(arr[:2:])
print(arr[2::])
18
1
[18 95 17 1 12]
[ 6 57]
[57 17]
[ 6 18 17 12]
[ 6 57]
[18 95 17 1 12]
2、二维数组选取
import numpy as np
arr=np.array([[1,2,3,4],[21,31,41,51],[13,14,15,16],[6,7,8,9]])
print(arr[1,2])
print(arr[2])
print(arr[:,3])
print("1、",arr[1:3])
print("2、",arr[2:])
print("3、",arr[:2])
print("4",arr[:,3:])
print("5",arr[:,:2])
print("6",arr[1:3,2:4])41
[13 14 15 16]
[ 4 51 16 9]
1、 [[21 31 41 51]
[13 14 15 16]]
2、 [[13 14 15 16]
[ 6 7 8 9]]
3、 [[ 1 2 3 4]
[21 31 41 51]]
4 [[ 4]
[51]
[16]
[ 9]]
5 [[ 1 2]
[21 31]
[13 14]
[ 6 7]]
6 [[41 51]
[15 16]]
6、数组重塑及转置
1、一维数组重塑
import numpy as np
arr=np.array([1,23,4,6,79,8])
a=arr.reshape(2,3)
b=arr.reshape(3,2)
print("a:",a)
print("b:",b)a: [[ 1 23 4]
[ 6 79 8]]
b: [[ 1 23]
[ 4 6]
[79 8]]
2、二维数组重塑
import numpy as np
arr=np.array([[1,2,3,4],[5,6,7,8],[9,10,11,12]])
a=arr.reshape(4,3)
b=arr.reshape(2,6)
c=arr.flatten()
d=arr.ravel()
print("a",a)
print("b",b)
print("c",c)
print("d",d)a [[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
b [[ 1 2 3 4 5 6]
[ 7 8 9 10 11 12]]
c [ 1 2 3 4 5 6 7 8 9 10 11 12]
d [ 1 2 3 4 5 6 7 8 9 10 11 12]
3、数组转置
import numpy as np
arr=np.array([[1,2,4,5],[6,7,8,9,],[12,3,21,11]])
print(arr.T)
print()
print(np.transpose(arr))[[ 1 6 12]
[ 2 7 3]
[ 4 8 21]
[ 5 9 11]]
[[ 1 6 12]
[ 2 7 3]
[ 4 8 21]
[ 5 9 11]]
7、数组操作
1、添加数组元素
import numpy as np
arr=np.array([[1,2,3],[4,5,6]])
arr1=np.append(arr,[[7,8,0]])
print(arr1)
print()
print(np.append(arr,[[2,3,4]],axis=0))
print()
print(np.append(arr,[[1,2],[3,4]],axis=1))
print()
print(np.insert(arr,1,[3,4,8]))
print()
print(np.insert(arr,1,[7,8],axis=1))
print()
print(np.insert(arr,2,[8,2,3],axis=0))[1 2 3 4 5 6 7 8 0]
[[1 2 3]
[4 5 6]
[2 3 4]]
[[1 2 3 1 2]
[4 5 6 3 4]]
[1 3 4 8 2 3 4 5 6]
[[1 7 2 3]
[4 8 5 6]]
[[1 2 3]
[4 5 6]
[8 2 3]]
2、删除数组元素
import numpy as np
arr=np.array([[1,2,3],[4,5,6],[7,8,9]])
print(np.delete(arr,3))
print()
print(np.delete(arr,1,axis=0))
print()
print(np.delete(arr,2,axis=1))[1 2 3 5 6 7 8 9]
[[1 2 3]
[7 8 9]]
[[1 2]
[4 5]
[7 8]]
3、缺失值处理
import numpy as np
arr=np.array([2,3,5,6,7,np.nan,8,9])
print(arr)
arr[np.isnan(arr)]=0
print()
print(arr)[ 2. 3. 5. 6. 7. nan 8. 9.]
[2. 3. 5. 6. 7. 0. 8. 9.]
4、重复值处理
import numpy as np
arr=np.array([2,3,4,5,6,7,2,3,2,4,5,3,2,5,6,2])
print(np.unique(arr))
arr1,counts=np.unique(arr,return_counts=True)
print(counts)[2 3 4 5 6 7]
[5 3 2 3 2 1]
5、数组的拼接及拆分
import numpy as np
arr=np.array([1,2,3,4,6,7,8,5,9,0,8,6])
arr1=np.array([[1,2,3,4],[3,4,7,8]])
arr2=np.array([[5,6,7,8],[8,9,10,12]])
print(np.concatenate((arr1,arr2),axis=0))
print()
print(np.concatenate((arr1,arr2),axis=1))
print()
print(np.hstack((arr1,arr2)))
print()
print(np.vstack((arr1,arr2)))
print()
print(np.hsplit(arr1,2))
print()
print(np.vsplit(arr2,2))
print()
print(np.split(arr,4))
print()
print(np.split(arr,[2,6]))
print()
print(np.split(arr,[2,4,5]))[[ 1 2 3 4]
[ 3 4 7 8]
[ 5 6 7 8]
[ 8 9 10 12]]
[[ 1 2 3 4 5 6 7 8]
[ 3 4 7 8 8 9 10 12]]
[[ 1 2 3 4 5 6 7 8]
[ 3 4 7 8 8 9 10 12]]
[[ 1 2 3 4]
[ 3 4 7 8]
[ 5 6 7 8]
[ 8 9 10 12]]
[array([[1, 2],
[3, 4]]), array([[3, 4],
[7, 8]])]
[array([[5, 6, 7, 8]]), array([[ 8, 9, 10, 12]])]
[array([1, 2, 3]), array([4, 6, 7]), array([8, 5, 9]), array([0, 8, 6])]
[array([1, 2]), array([3, 4, 6, 7]), array([8, 5, 9, 0, 8, 6])]
[array([1, 2]), array([3, 4]), array([6]), array([7, 8, 5, 9, 0, 8, 6])]
6、数组运算
import numpy as np
arr1=np.array([[1,2,3],[2,3,4]])
arr2=np.array([[5,6,7],[8,9,5]])
print(arr1+arr2)
print()
print(arr1*arr2)
print()
print(arr1+3)
print()
print(arr2*2)
print()
print(arr1.sum(),arr1.sum(axis=0),arr1.sum(axis=1))
print()
print(arr1.mean(),arr1.mean(axis=0),arr1.mean(axis=1))
print()
print(arr1.max(),arr1.max(axis=0),arr1.max(axis=1))[[ 6 8 10]
[10 12 9]]
[[ 5 12 21]
[16 27 20]]
[[4 5 6]
[5 6 7]]
[[10 12 14]
[16 18 10]]
15 [3 5 7] [6 9]
2.5 [1.5 2.5 3.5] [2. 3.]
4 [2 3 4] [3 4]
二、pandas库的使用方法
1、Series及DataFrame对象使用
1、Series对象
import pandas as pd
s=pd.Series(['足球','羽毛球','乒乓球','排球'])
s1=pd.Series(['足球','羽毛球','乒乓球','排球'],index=['a1','a2','a3','a4'])
s2=pd.Series({'b1':'足球','b2':'羽毛球','b3':'乒乓球','b4':'排球'})
print(s)
print(s1)
print(s2)0 足球
1 羽毛球
2 乒乓球
3 排球
dtype: object
a1 足球
a2 羽毛球
a3 乒乓球
a4 排球
dtype: object
b1 足球
b2 羽毛球
b3 乒乓球
b4 排球
dtype: object
2、DataFrame对象
import pandas as pd
df=pd.DataFrame(['苹果',3],['梨子',4])
df1=pd.DataFrame([['苹果',3],['梨子',4]],columns=['水果','单价'],index=['a1','a2'])
df2=pd.DataFrame({'水果':['苹果','梨子'],'单价':[2,3]})
df3=pd.DataFrame({'水果':['苹果','梨子'],'单价':[2,3]},index=['b1','b2'])
print(df)
print(df1)
print(df2)
print(df3) 0
梨子 苹果
4 3
水果 单价
a1 苹果 3
a2 梨子 4
水果 单价
0 苹果 2
1 梨子 3
水果 单价
b1 苹果 2
b2 梨子 3
2、读取查看数据
1、使用pandas读取excel中的数据
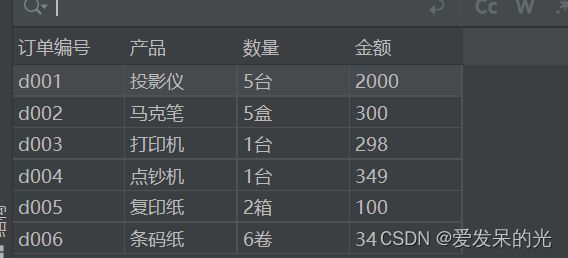
import pandas as pd
data1=pd.read_excel('订单表.xlsx',sheet_name=3) #read_excel(r"文件地址",sheet_name=指定读取第几个位置的sheet)
data2=pd.read_excel('订单表.xlsx',sheet_name=3,header=0)
data3=pd.read_excel('订单表.xlsx',sheet_name=3,header=2)
data4=pd.read_excel('订单表.xlsx',sheet_name=3,header=None)
data5=pd.read_excel('订单表.xlsx',sheet_name=3,index_col=0)
data6=pd.read_excel('订单表.xlsx',sheet_name=3,index_col=2)
data7=pd.read_excel('订单表.xlsx',sheet_name=3,usecols=[3])
data8=pd.read_excel('订单表.xlsx',sheet_name=3,usecols=[1,3])
print("1")
print(data1)
print("2")
print(data2)
print("3")
print(data3)
print("4")
print(data4)
print("5")
print(data5)
print("6")
print(data6)
print("7")
print(data7)
print("8")
print(data8) 1
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
2
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
3
d002 马克笔 5盒 300
0 d003 打印机 1台 298
1 d004 点钞机 1台 349
2 d005 复印纸 2箱 100
3 d006 条码纸 6卷 34
4
0 1 2 3
0 订单编号 产品 数量 金额
1 d001 投影仪 5台 2000
2 d002 马克笔 5盒 300
3 d003 打印机 1台 298
4 d004 点钞机 1台 349
5 d005 复印纸 2箱 100
6 d006 条码纸 6卷 34
5
产品 数量 金额
订单编号
d001 投影仪 5台 2000
d002 马克笔 5盒 300
d003 打印机 1台 298
d004 点钞机 1台 349
d005 复印纸 2箱 100
d006 条码纸 6卷 34
6
订单编号 产品 金额
数量
5台 d001 投影仪 2000
5盒 d002 马克笔 300
1台 d003 打印机 298
1台 d004 点钞机 349
2箱 d005 复印纸 100
6卷 d006 条码纸 34
7
金额
0 2000
1 300
2 298
3 349
4 100
5 34
8
产品 金额
0 投影仪 2000
1 马克笔 300
2 打印机 298
3 点钞机 349
4 复印纸 100
5 条码纸 34
2、使用pandas读取csv文件
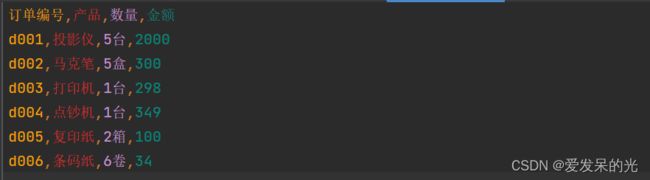
import pandas as pd
data1=pd.read_csv('订单表.csv')
data2=pd.read_csv('订单表.csv',nrows=2)
print(data1)
print(data2) 订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
3、选择性读取数据
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
data1=pd.read_excel('订单表.xlsx',sheet_name=3,index_col=0)
print(data.head())
print()
print(data.head(2)) #查看前2行
print()
print(data.shape) #查看行列数
print()
data.info() #查看数据类型
print()
print(data['金额'].dtype)#查看”金额“的数据类型
data['金额']=data['金额'].astype('float64')
print(data.head(2))
print()
print(data1.loc['d001']) #读取索引为d001的数据
print()
print(data.iloc[2]) #读取第3行数据
print()
print(data.iloc[1:5]) #读取第2-5行数据
print()
a=data['金额']<200
print(data[a]) #读取金额小于200的数据
print()
print(data['金额'])
print()
print(data.iloc[:,1:4]) #读取2-4列数据
print()
print(data.iloc[:,[0,3]]) #读取第1和第4列数据
print()
print(data1.loc[['d001', 'd005'], ['产品', '金额']]) #读取'd001', 'd005'的产品和金额数据
print()
print(data1.iloc[[2, 4], [0, 2]]) #读取第3、5行的第一列和第三列数据订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
(6, 4)
RangeIndex: 6 entries, 0 to 5
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单编号 6 non-null object
1 产品 6 non-null object
2 数量 6 non-null object
3 金额 6 non-null int64
dtypes: int64(1), object(3)
memory usage: 320.0+ bytes
int64
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000.0
1 d002 马克笔 5盒 300.0
产品 投影仪
数量 5台
金额 2000
Name: d001, dtype: object
订单编号 d003
产品 打印机
数量 1台
金额 298.0
Name: 2, dtype: object
订单编号 产品 数量 金额
1 d002 马克笔 5盒 300.0
2 d003 打印机 1台 298.0
3 d004 点钞机 1台 349.0
4 d005 复印纸 2箱 100.0
订单编号 产品 数量 金额
4 d005 复印纸 2箱 100.0
5 d006 条码纸 6卷 34.0
0 2000.0
1 300.0
2 298.0
3 349.0
4 100.0
5 34.0
Name: 金额, dtype: float64
产品 数量 金额
0 投影仪 5台 2000.0
1 马克笔 5盒 300.0
2 打印机 1台 298.0
3 点钞机 1台 349.0
4 复印纸 2箱 100.0
5 条码纸 6卷 34.0
订单编号 金额
0 d001 2000.0
1 d002 300.0
2 d003 298.0
3 d004 349.0
4 d005 100.0
5 d006 34.0
产品 金额
订单编号
d001 投影仪 2000
d005 复印纸 100
产品 金额
订单编号
d003 打印机 298
d005 复印纸 100
3、pandas数据处理
1、数据增删查改
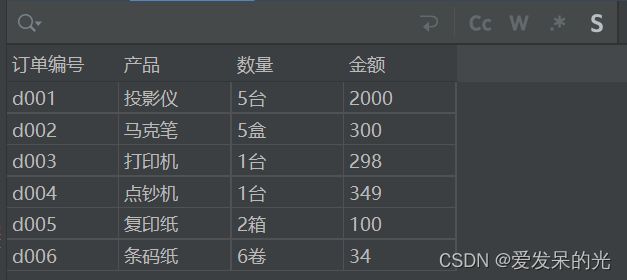
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
dataes=pd.read_excel('订单表.xlsx',sheet_name=3,index_col=0)
data=data.head(3)
datas=data
print(data)
print('1')
data1 =data.isin(['d002','马克笔']) #查找'd002','马克笔'所在的位置
print(data1)
print('2')
data2 = data['产品'].isin(['马克笔']) #查找产品中的马克笔
print(data2)
print('3')
data.replace('马克笔', '钢笔', inplace=True) #更改表中数据马克笔为钢笔
print(data)
print('4')
data.replace(['投影仪', '打印机'], '电子设备', inplace=True) #更改表中数据钢笔投影仪, 打印机为电子设备
print(data)
print('5')
datas.replace({'钢笔':'毛笔', 300:98, 298:188},inplace=True) #更改表中数据钢笔为毛笔,300为98,298为188
print(datas)
print('6')
datas['报废年限']=[10,10,5] #增加一列报废年限数据
print(datas)
print('7')
datas.insert(2,'保险期限',[1,1,3]) #插入保险期限到第三列
print(datas)
print('8')
d1=datas.drop(['产品'],axis=1) #删除产品列
print(d1)
print('9')
d2=datas.drop(datas.columns[[2, 5]],axis=1) #删除第三和第五列
print(d2)
print('10')
d3=datas.drop(columns=['数量']) #删除数量列
print(d3)
print('11')
print(dataes,'\n12')
e1=dataes.drop(['d001', 'd004','d002'], axis=0) #删除'd001', 'd004','d002'行
print(e1,'\n13')
e2=dataes.drop(dataes.index[[2,4]],axis=0) #删除第3和第5行
print(e2,'\n14')
e3=dataes.drop(index=['d002','d004']) #删除d002、d004行
print(e3)
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
1
订单编号 产品 数量 金额
0 False False False False
1 True True False False
2 False False False False
2
0 False
1 True
2 False
Name: 产品, dtype: bool
3
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 钢笔 5盒 300
2 d003 打印机 1台 298
4
订单编号 产品 数量 金额
0 d001 电子设备 5台 2000
1 d002 钢笔 5盒 300
2 d003 电子设备 1台 298
5
订单编号 产品 数量 金额
0 d001 电子设备 5台 2000
1 d002 毛笔 5盒 98
2 d003 电子设备 1台 188
6
订单编号 产品 数量 金额 报废年限
0 d001 电子设备 5台 2000 10
1 d002 毛笔 5盒 98 10
2 d003 电子设备 1台 188 5
7
订单编号 产品 保险期限 数量 金额 报废年限
0 d001 电子设备 1 5台 2000 10
1 d002 毛笔 1 5盒 98 10
2 d003 电子设备 3 1台 188 5
8
订单编号 保险期限 数量 金额 报废年限
0 d001 1 5台 2000 10
1 d002 1 5盒 98 10
2 d003 3 1台 188 5
9
订单编号 产品 数量 金额
0 d001 电子设备 5台 2000
1 d002 毛笔 5盒 98
2 d003 电子设备 1台 188
10
订单编号 产品 保险期限 金额 报废年限
0 d001 电子设备 1 2000 10
1 d002 毛笔 1 98 10
2 d003 电子设备 3 188 5
11
产品 数量 金额
订单编号
d001 投影仪 5台 2000
d002 马克笔 5盒 300
d003 打印机 1台 298
d004 点钞机 1台 349
d005 复印纸 2箱 100
d006 条码纸 6卷 34
12
产品 数量 金额
订单编号
d003 打印机 1台 298
d005 复印纸 2箱 100
d006 条码纸 6卷 34
13
产品 数量 金额
订单编号
d001 投影仪 5台 2000
d002 马克笔 5盒 300
d004 点钞机 1台 349
d006 条码纸 6卷 34
14
产品 数量 金额
订单编号
d001 投影仪 5台 2000
d003 打印机 1台 298
d005 复印纸 2箱 100
d006 条码纸 6卷 34
2、缺失值处理
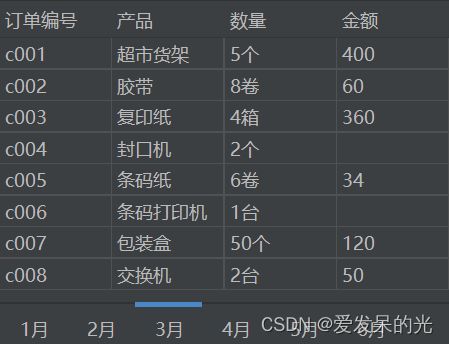
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=2)
print(data,'\n')
data.info() #每一列的缺失值情况
print()
a=data.isnull() #判断是否为缺失值
print(a,'\n')
b=data.dropna() #删除有缺失值的行
print(b,'\n')
c=data.dropna(how='all') #删除全部为缺失值的行
print(c,'\n')
d=data.fillna(0) #用0填充所有缺失值
print(d,'\n')
e=data.fillna({'金额':16}) #用16填充金额列的缺失值
print(e)订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
5 c006 条码打印机 1台 NaN
6 c007 包装盒 50个 120.0
7 c008 交换机 2台 50.0
RangeIndex: 8 entries, 0 to 7
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 订单编号 8 non-null object
1 产品 8 non-null object
2 数量 8 non-null object
3 金额 6 non-null float64
dtypes: float64(1), object(3)
memory usage: 384.0+ bytes
订单编号 产品 数量 金额
0 False False False False
1 False False False False
2 False False False False
3 False False False True
4 False False False False
5 False False False True
6 False False False False
7 False False False False
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
4 c005 条码纸 6卷 34.0
6 c007 包装盒 50个 120.0
7 c008 交换机 2台 50.0
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
5 c006 条码打印机 1台 NaN
6 c007 包装盒 50个 120.0
7 c008 交换机 2台 50.0
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 0.0
4 c005 条码纸 6卷 34.0
5 c006 条码打印机 1台 0.0
6 c007 包装盒 50个 120.0
7 c008 交换机 2台 50.0
3、处理重复值

import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=2)
print(data,'\n')
a=data.drop_duplicates() #删除相同的行
print(a,'\n')
b=data.drop_duplicates(subset='产品') #删除产品名重复的行
print(b,'\n')
c=data.drop_duplicates(subset='产品',keep='first') #删除产品名相同的行 ,保留第一次出现的行
print(c,'\n')
d=c=data.drop_duplicates(subset='产品',keep='last') #删除产品名相同的行 ,保留最后出现的行
print(d,'\n')
e=c=data.drop_duplicates(subset='产品',keep=False) #删除所有产品名重复的行
print(e) 订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
5 c001 超市货架 5个 400.0
6 c002 胶带 8卷 999.0
7 c003 复印纸 4箱 36.0
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
6 c002 胶带 8卷 999.0
7 c003 复印纸 4箱 36.0
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
订单编号 产品 数量 金额
0 c001 超市货架 5个 400.0
1 c002 胶带 8卷 60.0
2 c003 复印纸 4箱 360.0
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
订单编号 产品 数量 金额
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
5 c001 超市货架 5个 400.0
6 c002 胶带 8卷 999.0
7 c003 复印纸 4箱 36.0
订单编号 产品 数量 金额
3 c004 封口机 2个 NaN
4 c005 条码纸 6卷 34.0
4、数据排序
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
print(data,'\n')
a=data.sort_values(by='金额',ascending=True) #按金额从小到大排序
print(a,'\n')
b=data.sort_values(by='金额',ascending=False) #按金额从大到小排序
print(b,'\n')
c=data['金额'].rank(method = 'average',ascending=False) #method设置为'average',表示在数据有重复值时,返回重复值的平均排名;
print(c,'\n')
d=data['金额'].rank(method = 'first',ascending=False) #method设置为'first',则表示在数据有重复值时,越先出现的数据排名越靠前
print(d)订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
订单编号 产品 数量 金额
5 d006 条码纸 6卷 34
4 d005 复印纸 2箱 100
2 d003 打印机 1台 298
1 d002 马克笔 5盒 300
3 d004 点钞机 1台 349
0 d001 投影仪 5台 2000
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
3 d004 点钞机 1台 349
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
0 1.0
1 3.0
2 4.0
3 2.0
4 5.0
5 6.0
Name: 金额, dtype: float64
0 1.0
1 3.0
2 4.0
3 2.0
4 5.0
5 6.0
Name: 金额, dtype: float64
5、装置数据表行列

import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
print(data,'\n')
a=data.T
print(a) 0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
0 1 2 3 4 5
订单编号 d001 d002 d003 d004 d005 d006
产品 投影仪 马克笔 打印机 点钞机 复印纸 条码纸
数量 5台 5盒 1台 1台 2箱 6卷
金额 2000 300 298 349 100 34
6、将数据表转换为树形结构
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
print(data,'\n')
a=data.stack()
print(a)订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
0 订单编号 d001
产品 投影仪
数量 5台
金额 2000
1 订单编号 d002
产品 马克笔
数量 5盒
金额 300
2 订单编号 d003
产品 打印机
数量 1台
金额 298
3 订单编号 d004
产品 点钞机
数量 1台
金额 349
4 订单编号 d005
产品 复印纸
数量 2箱
金额 100
5 订单编号 d006
产品 条码纸
数量 6卷
金额 34
dtype: object
7、数据拼接
import pandas as pd
data1=pd.read_excel('订单表.xlsx',sheet_name=3)
data2=pd.read_excel('订单表.xlsx',sheet_name=4)
print(data1,'\n')
print(data2,'\n')
a=pd.merge(data1,data2)
print(a,'\n')
b=pd.merge(data1,data2,how='outer')
print(b,'\n')
c=pd.merge(data1,data2,on='产品')
print(c,'\n')
d=pd.concat([data1,data2])
print(d,'\n')
e=pd.concat([data1,data2],ignore_index=True)
print(e,'\n')
f=data1.append(data2)
print(f,'\n')
g=data1.append({'订单表':'d008','产品':'超市货架','数量':'8个','金额':'640'},ignore_index=True)
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
订单编号 产品 数量 金额
0 e001 点钞机 1台 349
1 e002 复印纸 2箱 100
2 e003 展板 2个 150
3 e004 培训椅 5个 345
4 e005 文件柜 2个 150
5 e006 广告牌 4个 269
6 e007 办公沙发 2个 560
7 e008 包装盒 50个 120
8 e009 交换机 2台 50
Empty DataFrame
Columns: [订单编号, 产品, 数量, 金额]
Index: []
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
6 e001 点钞机 1台 349
7 e002 复印纸 2箱 100
8 e003 展板 2个 150
9 e004 培训椅 5个 345
10 e005 文件柜 2个 150
11 e006 广告牌 4个 269
12 e007 办公沙发 2个 560
13 e008 包装盒 50个 120
14 e009 交换机 2台 50
订单编号_x 产品 数量_x 金额_x 订单编号_y 数量_y 金额_y
0 d004 点钞机 1台 349 e001 1台 349
1 d005 复印纸 2箱 100 e002 2箱 100
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
0 e001 点钞机 1台 349
1 e002 复印纸 2箱 100
2 e003 展板 2个 150
3 e004 培训椅 5个 345
4 e005 文件柜 2个 150
5 e006 广告牌 4个 269
6 e007 办公沙发 2个 560
7 e008 包装盒 50个 120
8 e009 交换机 2台 50
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
6 e001 点钞机 1台 349
7 e002 复印纸 2箱 100
8 e003 展板 2个 150
9 e004 培训椅 5个 345
10 e005 文件柜 2个 150
11 e006 广告牌 4个 269
12 e007 办公沙发 2个 560
13 e008 包装盒 50个 120
14 e009 交换机 2台 50
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
0 e001 点钞机 1台 349
1 e002 复印纸 2箱 100
2 e003 展板 2个 150
3 e004 培训椅 5个 345
4 e005 文件柜 2个 150
5 e006 广告牌 4个 269
6 e007 办公沙发 2个 560
7 e008 包装盒 50个 120
8 e009 交换机 2台 50
8、数据的统计运算
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=4)
a=data.sum() #求各列数据之和
print(a,'\n')
b=data['金额'].sum() #求金额的和
print(b,'\n')
c=data.mean() #求各列数据的平均值
print(c,'\n')
d=data['金额'].mean() #求金额的平均值
print(d,'\n')
e=data.max() #求各列数据的最大值
print(e,'\n')
f=data['金额'].max() #求金额的最大值
print(f)订单编号 e001e002e003e004e005e006e007e008e009
产品 点钞机复印纸展板培训椅文件柜广告牌办公沙发包装盒交换机
数量 1台2箱2个5个2个4个2个50个2台
金额 2093
dtype: object
2093
金额 232.555556
dtype: float64
232.55555555555554
订单编号 e009
产品 点钞机
数量 5个
金额 560
dtype: object
560
报错:
数据的统计运算.py:7: FutureWarning: Dropping of nuisance columns in DataFrame reductions (with 'numeric_only=None') is deprecated; in a future version this will raise TypeError. Select only valid columns before calling the reduction.
c=data.mean() #求各列数据的平均值
9、数据的分布情况
import pandas as pd
data=pd.read_excel('订单表.xlsx',sheet_name=3)
print(data,'\n')
a=data.describe() #获取全部数据的分布情况
print(a,'\n')
b=data['金额'].describe() #获取金额数据分分布情况
print(b)
订单编号 产品 数量 金额
0 d001 投影仪 5台 2000
1 d002 马克笔 5盒 300
2 d003 打印机 1台 298
3 d004 点钞机 1台 349
4 d005 复印纸 2箱 100
5 d006 条码纸 6卷 34
金额
count 6.000000
mean 513.500000
std 738.873128
min 34.000000
25% 149.500000
50% 299.000000
75% 336.750000
max 2000.000000
count 6.000000
mean 513.500000
std 738.873128
min 34.000000
25% 149.500000
50% 299.000000
75% 336.750000
max 2000.000000
Name: 金额, dtype: float64
10、相关系数分析
import pandas as pd
data = pd.read_excel('相关性分析.xlsx')
print(data,'\n')
a = data.corr()
print(a,'\n')
b = data.corr()['年销售额(万元)']
print(b)代理商编号 年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
0 A-001 20.5 15.6 2.00 0.80
1 A-003 24.5 16.7 2.54 0.94
2 B-002 31.8 20.4 2.96 0.88
3 B-006 34.9 22.6 3.02 0.79
4 B-008 39.4 25.7 3.14 0.84
5 C-003 44.5 28.8 4.00 0.80
6 C-004 49.6 32.1 6.84 0.85
7 C-007 54.8 35.9 5.60 0.91
8 D-006 58.5 38.7 6.45 0.90
年销售额(万元) 年广告费投入额(万元) 成本费用(万元) 管理费用(万元)
年销售额(万元) 1.000000 0.996275 0.914428 0.218317
年广告费投入额(万元) 0.996275 1.000000 0.918404 0.223187
成本费用(万元) 0.914428 0.918404 1.000000 0.284286
管理费用(万元) 0.218317 0.223187 0.284286 1.000000
年销售额(万元) 1.000000
年广告费投入额(万元) 0.996275
成本费用(万元) 0.914428
管理费用(万元) 0.218317
Name: 年销售额(万元), dtype: float64
11、分组数据汇总
import pandas as pd
data = pd.read_excel('产品统计表.xlsx')
print(data,'\n1')
a = data.groupby('产品')
print(a,'\n2')
b = data.groupby('产品').sum()
print(b,'\n3')
c = data.groupby('产品')['利润(元)'].sum()
print(c,'\n')编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
0 a001 背包 16 65 60 960 3900 2940
1 a002 钱包 90 187 50 4500 9350 4850
2 a003 背包 16 65 23 368 1495 1127
3 a004 手提包 36 147 26 936 3822 2886
4 a005 钱包 90 187 78 7020 14586 7566
5 a006 单肩包 58 124 63 3654 7812 4158
6 a007 单肩包 58 124 58 3364 7192 3828
1
2
成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
产品
单肩包 116 248 121 7018 15004 7986
手提包 36 147 26 936 3822 2886
背包 32 130 83 1328 5395 4067
钱包 180 374 128 11520 23936 12416
3
产品
单肩包 7986
手提包 2886
背包 4067
钱包 12416
Name: 利润(元), dtype: int64
12、创建数据透视表
import pandas as pd
data = pd.read_excel('产品统计表.xlsx')
print(data,'\n1:')
a = pd.pivot_table(data, values = '利润(元)', index = '产品', aggfunc = 'sum')
print(a,'\n2:')
b = pd.pivot_table(data, values = ['利润(元)', '成本(元)'], index = '产品', aggfunc = 'sum')
print(b)编号 产品 成本价(元/个) 销售价(元/个) 数量(个) 成本(元) 收入(元) 利润(元)
0 a001 背包 16 65 60 960 3900 2940
1 a002 钱包 90 187 50 4500 9350 4850
2 a003 背包 16 65 23 368 1495 1127
3 a004 手提包 36 147 26 936 3822 2886
4 a005 钱包 90 187 78 7020 14586 7566
5 a006 单肩包 58 124 63 3654 7812 4158
6 a007 单肩包 58 124 58 3364 7192 3828
1:
利润(元)
产品
单肩包 7986
手提包 2886
背包 4067
钱包 12416
2:
利润(元) 成本(元)
产品
单肩包 7986 7018
手提包 2886 936
背包 4067 1328
钱包 12416 11520