Pytorch_hook机制的理解及利用register_forward_hook(hook)中间层输出
参考文献:
【1】梯度计算问题含公式:参考链接1.
【2】pytorch改动和.data和.detch()问题:https://blog.csdn.net/dss_dssssd/article/details/83818181
【3】hook技术介绍:https://www.cnblogs.com/hellcat/p/8512090.html
【4】hook应用->中间层的输出:https://blog.csdn.net/qq_40303258/article/details/106884317
【5】hook函数介绍:参考链接2
需要了解的基本点:
(1)backward()是Pytorch中用来求梯度的方法。
(2)Variable是对tensor的封装,包含了三部分:
- .data:tensor本身
- .grad:对应tensor的梯度
- .grad_fn:该Variable是通过什么方式获得的
(3)pytorch 0.4版本后将tensor和Variable合并在了一起。
x = Variable(torch.randn(2, 1), requires_grad=True) # 利用Variable封装tensor
##等效 x = torch.rand(2,1,requires_grad=True)
x = torch.rand(2,1) # 不等效(4)hook种类分为两种
Tensor级别 register_hook(hook) ->为Tensor注册一个backward hook,用来获取变量的梯度;hook必须遵循如下的格式:hook(grad) -> Tensor or None
nn.Module对象 register_forward_hook(hook)和register_backward_hook(hook)两种方法,分别对应前向传播和反向传播的hook函数。
(5)hook作用:获取某些变量的中间结果的。Pytorch会自动舍弃图计算的中间结果,所以想要获取这些数值就需要使用hook函数。hook函数在使用后应及时删除,以避免每次都运行钩子增加运行负载。
举例说明 Tensor级别 :
例子1(借鉴参考文献1和3)
import torch
from torch.autograd import Variable
def print_grad(grad):
print('grad is \n',grad)
x = Variable(torch.randn(2, 1), requires_grad=True)
## x = torch.rand(2,1,requires_grad=True) # 等效
print('x value is \n',x)
y = x+3
print('y value is \n',y)
z = torch.mean(torch.pow(y, 1/2))
lr = 1e-3
y.register_hook(print_grad)
z.backward() # 梯度求解
x.data -= lr*x.grad.data
print('new x is\n',x)output:
x value is
tensor([[ 2.5474],
[-1.1597]], requires_grad=True)
y value is
tensor([[5.5474],
[1.8403]], grad_fn=)
grad is
tensor([[0.1061],
[0.1843]])
new x is
tensor([[ 2.5473],
[-1.1599]], requires_grad=True) 分析:
对于z来说,求梯度最终求解的是对x的梯度(导数,偏导),因此y是一个中间变量。因此可以用register_hook()来获取其作为中间值的导数,否则z对于y的偏导是获取不到的。x的偏导和y的偏导实际上是相同值,推导如下图。
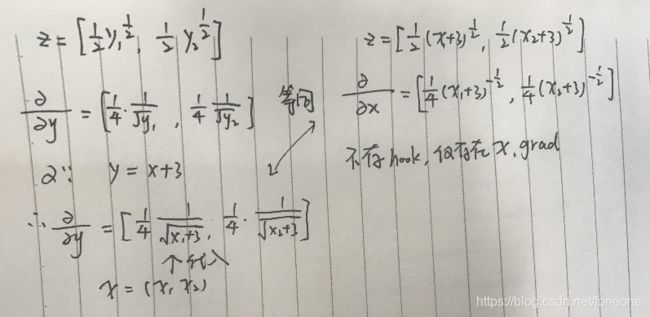
不用register_hook()的例子。
#y.register_hook(print_grad)
z.backward() # 梯度求解
print('y\'s grad is ',y.grad)
print('x\'s grad is \n',x.grad)
x.data -= lr*x.grad.data
print('new x is\n',x)
output:
y's grad is None
x's grad is
tensor([[0.1544],
[0.1099]])
new x is
tensor([[-0.3801],
[ 2.1755]], requires_grad=True)可以看出,z对于x的grad是存在的,但是z对于中间变量y的grad是不存在的。也就验证了Pytorch会自动舍弃图计算的中间结果这句话。
举例说明 Module级别
【1】register_forward_hook(hook)
在网络执行forward()之后,执行hook函数,需要具有如下的形式:
hook(module, input, output) -> None or modified outputhook可以修改input和output,但是不会影响forward的结果。最常用的场景是需要提取模型的某一层(不是最后一层)的输出特征,但又不希望修改其原有的模型定义文件,这时就可以利用forward_hook函数。
import torch
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16*5*5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
out = F.relu(self.conv1(x)) #1
out = F.max_pool2d(out, 2) #2
out = F.relu(self.conv2(out)) #3
out = F.max_pool2d(out, 2)
out = out.view(out.size(0), -1)
out = F.relu(self.fc1(out))
out = F.relu(self.fc2(out))
out = self.fc3(out)
return out
features = []
def hook(module, input, output):
# module: model.conv2
# input :in forward function [#2]
# output:is [#3 self.conv2(out)]
features.append(output.clone().detach())
# output is saved in a list
net = LeNet() ## 模型实例化
x = torch.randn(2, 3, 32, 32) ## input
handle = net.conv2.register_forward_hook(hook) ## 获取整个Lenet模型 conv2的中间结果
y = net(x) ## 获取的是 关于 input x 的 conv2 结果
print(features[0].size()) # 即 [#3 self.conv2(out)]
handle.remove() ## hook删除
以上文字和代码示例,均来自参考文献5中的示例,由于示例对于register_forward_hook(hook)没有过多注解,因此我加了一些注解。
个人理解:register_forward_hook(hook) 作用就是(假设想要conv2层),那么就是根据 model(该层),该层input,该层output,可以将 output获取。
register_forward_hook(hook) 最大的作用也就是当训练好某个model,想要展示某一层对最终目标的影响效果。
例子:【借鉴参考文献4】
class LayerActivations:
features = None
def __init__(self, model, layer_num):
self.hook = model[layer_num].register_forward_hook(self.hook_fn)
# 获取model.features中某一层的output
def hook_fn(self, module, input, output):
self.features = output.cpu()
def remove(self): ## 删除hook
self.hook.remove()
''' 类似于以下格式
class CNNnet1(torch.nn.Module): ## wangluo jiegou
def __init__(self):
super(CNNnet1,self).__init__()
self.features = nn.Sequential(
nn.Conv1d(),
torch.nn.ReLU(),
torch.nn.Conv1d(),
torch.nn.ReLU(),
torch.nn.Conv1d(),
torch.nn.BatchNorm1d(),
torch.nn.MaxPool1d()
torch.nn.ReLU()
)
'''
#### model= CNN()
#### train(model,train_loader,learning_rate,batch_size,epochs)
####
model.eval()
test_dataset = DataSet(test_features, test_labels)
test_loader = DataLoader(test_dataset,batch_size=1,shuffle=True)
img = next(iter(test_loader))[0] # gain a input
for i in range(len(model.features)): # model.features is a nn.Sequential()
conv_out = LayerActivations(model.features,i) # 实例化,获取每一层
ouput = model(img)
act = conv_out.features # gain the ith output
conv_out.remove # delete the hook
plt.imshow(act[0].detach().numpy(),cmap='hot') # output is showed using 热力图
plt.colorbar(shrink=0.4) # 句柄大小
plt.show() 大概画完了就是这个样子[每一层都有一个图,不做过多展示]:
其中 plt.imshow()是热力图画法,详情点击链接。可以把参考文献4中是将所有的中间层画到了一张画布上,因为卷积层尺寸不同,我就没放在一起。
[2]register_backward_hook(hook)
因为暂时没有用到,不做详细讲解,具体可参考参考文献5。