onnx runtime参考
onnx runtime example
import onnx
import onnxruntime as ort
import numpy as np
import time
def generate_test_data(input_shapes, input_dtypes, seed=0):
test_datas = []
np.random.seed(seed)
for i in range(len(input_shapes)):
data_np = get_random_data(input_shapes[i], input_dtypes[i])
test_datas.append(data_np)
return test_datas
def get_random_data(shape, dtype, args=None):
min_value = -10
max_value = 10
if dtype.find("int") >= 0:
min_value = 0
return np.random.uniform(min_value, max_value, size=shape).astype(dtype)
model_path = "model.onnx"
input_names = [
"input1",
]
input_shapes = [
[400, 128],
]
input_dtypes = [
"float32",
]
output_names = [
"output",
]
warmup_num = 50
eval_num = 50
input_data_np = generate_test_data(input_shapes, input_dtypes)
feed_dict = dict(zip(input_names, input_data_np))
# ['TensorrtExecutionProvider', 'CUDAExecutionProvider']
ort_sess = ort.InferenceSession(model_path, providers=['CUDAExecutionProvider'])
for i in range(warmup_num):
outputs = ort_sess.run(output_names, feed_dict)
start_time = time.time()
for i in range(eval_num):
outputs = ort_sess.run(output_names, feed_dict)
end_time = time.time()
print("model:", model_path)
print("avg time:", (end_time - start_time) / eval_num)
[print(output.shape) for output in outputs]
ref:(optional) Exporting a Model from PyTorch to ONNX and Running it using ONNX Runtime — PyTorch Tutorials 1.10.1+cu102 documentation
onnx runtime - TensorRT
1.10已经具有tensorrt ep可以直接使用
onnx runtime结构和插件机制
https://www.onnxruntime.ai/docs/reference/execution-providers/
Redirecting…
Redirecting…
ONNX Runtime supports an extensible framework, called Execution Providers (EP), to integrate with the HW specific libraries. This interface enables flexibility for the AP application developer to deploy their ONNX models in different environments in the cloud and the edge and optimize the execution by taking advantage of the compute capabilities of the platform.
ONNX Runtime works with the execution provider(s) using the GetCapability() interface to allocate specific nodes or sub-graphs for execution by the EP library in supported hardware. The EP libraries that are pre-installed in the execution environment process and execute the ONNX sub-graph on the hardware.
The same ONNX Runtime API is used across all EPs. This provides the consistent interface for applications to run with different HW acceleration platforms.
import onnxruntime as rt
#define the priority order for the execution providers
# prefer CUDA Execution Provider over CPU Execution Provider
EP_list = ['TensorrtExecutionProvider', 'CUDAExecutionProvider', 'CPUExecutionProvider']
# initialize the model.onnx
sess = rt.InferenceSession("model.onnx", providers=EP_list)
feed_dict = dict(zip(input_names, input_data_np))
outputs = ort_sess.run(output_names, feed_dict)
print("outputs:", len(outputs))
[print(output.shape) for output in outputs]
看上去是通过设定优先级来确定在同一个op能被多个EP支持时具体选择哪一个EP。
能否在graph pass根据性能再决定使用哪个EP?
onnxruntime-gpu 1.10.0 已经有了tensorrt EP,可以进行量化,还可以进行dump子图等debug操作
onnx runtime附加功能
量化 onnxruntime/onnxruntime/python/tools/quantization/
infer shape onnxruntime/onnxruntime/python/tools/symbolic_shape_infer.py
transformer优化 onnxruntime/onnxruntime/python/tools/transformers/
优化参考
Optimizing BERT model for Intel CPU Cores using ONNX runtime default execution provider
Optimizing BERT model for Intel CPU Cores using ONNX runtime default execution provider - Microsoft Open Source Blog
版本依赖
tensorrt execution provider版本对应:
NVIDIA - TensorRT | onnxruntime
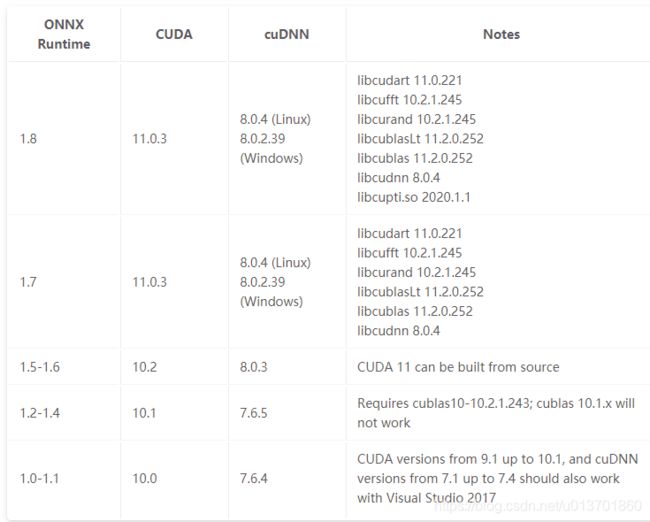
ref:Redirecting…
pip install onnx Protobuf compiler not found解决:
pip install protobuf
apt-get install protobuf-compiler libprotoc-dev