Transformer BERT KG-BERT
两个重要的知识表示学习综述:
知乎:
1. KG笔记十、知识图谱嵌入(KG Embedding)https://zhuanlan.zhihu.com/p/354867179
2. 刘知远大神《知识表示学习研究进展》的学习小结https://zhuanlan.zhihu.com/p/356147538
3. 知识图谱最新权威综述论文解读:知识表示学习部分https://zhuanlan.zhihu.com/p/141396088
Transformer与BERT的学习笔记 https://github.com/aespresso/a_journey_into_math_of_ml/blob/master/03_transformer_tutorial_1st_part/transformer_1.ipynb
EM 和 F1 是什么?
word-词
区分 text与context
简介
知识图谱不完整的问题激发了知识图补全任务,该任务的目标是评估知识图中不存在的三元组的合理性。
知识补全任务大量的研究工作: 一种常用的方法称为知识图嵌入,它将三元组中的实体和关系表示为实值向量,并用这些向量评估三元组的可信度 缺点是:大多数知识图嵌入模型只使用观察到的三元组事实中的结构信息,存在知识图的稀疏性问题
想到:近年来引入文本信息来丰富知识表征
但是 一方面,学习了独特文本嵌入为相同实体/关系在不同三元组中,这样忽略了上下文信息。
例如,1.在描述史蒂夫·乔布斯时,不同的词应该有不同的重要性权重,与“成立”和“是哪的公民”这两个关系相关,2.“wroteMusicFor”这个关系可以有两个不同的意思“写歌词”和“作曲” 给予不同的实体
另一方面,大规模文本数据中的句法和语义信息没有得到充分利用,它们仅仅使用了实体描述, 关系提及或者实体共现
最近,ELMo (Peters et al. 2018)、GPT (Radford et al. 2018)、BERT (Devlin et al. 2019)和XLNet (Y ang et al. 2019)等预训练语言模型在自然语言处理(NLP)中取得了巨大成功,这些模型可以在大量自由文本数据的情况下学习上下文化的词嵌入,并在许多语言理解任务中实现最先进的性能。其中BERT是最突出的一种,通过掩码语言建模和下一句预测对双向Transformer编码器进行预训练。它可以在预先训练的模型权重中获取丰富的语言知识。
总结:将实体、关系和三元组视为文本序列,并将知识图的补全转化为序列分类问题。然后在这些序列上微调BERT模型,以预测一个三元组或一个关系的可信度 这是第一项使用PLM对三元组进行建模的研究.
相关工作
知识图谱嵌入
这些方法可以根据三元组(h, r, t)的不同评分函数分为翻译距离模型和语义匹配模型。
上述只考虑结构信息,同时可以引入实体类型、逻辑规则和文本描述等不同类型的外部信息来提高性能,对于文本描述,(Socher et al. 2013)首先通过平均实体名称中包含的词嵌入来表示实体,其中的word嵌入是从外部语料库中学习的;(Wang et al. 2014a)提出通过对维基百科锚点和实体名称进行对齐,将实体和words共同嵌入到同一个向量空间中;(Xie et al. 2016)使用卷积神经网络(CNN)对实体描述中的word序列进行编码;(Xiao et al. 2017)提出语义空间投影(semantic space projection, SSP),通过表征事实三元组与文本描述之间的强相关性,共同学习topics和KG嵌入。
尽管这些模型取得了成功,但它们学习实体和关系的相同文本表示,而实体/关系描述中的word在不同的三元组中可能具有不同的含义或重要性权重。
(Wang and Li 2016)提出了一种文本增强的KG嵌入模型TEKE,该模型可以将不同的嵌入分配给不同三元组中的关系,TEKE利用实体和words在实体注释文本语料库中的共现;(Xu et al. 2017)使用带有注意机制的LSTM编码器构造给定不同关系的上下文文本表示;(An et al. 2018)提出了一种准确的文本增强的KG嵌入方法,利用了三元组特定关系提及以及关系提及和实体描述之间的相互注意机制。
虽然这些方法可以处理不同三元组的实体和关系的语义变化,但在大规模的自由文本数据中,它们不能充分利用语法和语义信息,因为它们只利用实体描述、关系提及和与实体的词共现。
预训练语言模型
预训练语言表示模型可以分为两类:基于特征的和微调方法。
传统的词嵌入方法,如Word2Vec (Mikolov et al. 2013)和Glove (Pennington, Socher, and Manning 2014),都是采用基于特征的方法来学习上下文无关的词向量。ELMo (Peters et al. 2018)将传统的词嵌入归纳为上下文感知的词嵌入,在上下文感知的词嵌入中,词的多义性可以得到适当处理。
与基于特征的方法不同,GPT (Radford et al. 2018)和BERT (Devlin et al. 2019)等微调方法使用预先训练的模型体系结构和参数作为特定NLP任务的起点,预训练的模型从自由文本中获取丰富的语义模式。
近年来,研究者们也在KG背景中探索了预训练的语言模型。(Wang, Kulkarni, and Wang 2018)学习了在KG中随机行走生成的实体-关系链(句子)上的上下文嵌入,然后使用嵌入作为TransE等KG嵌入模型的初始化;(Zhang et al. 2019)在KG中加入信息实体以增强BERT语言表示;(Bosselut et al. 2019)使用GPT在常识知识库中生成给定头短语和关系类型的尾短语tokens,该方法不完全适合比较具有已知关系的两个实体的模式,该方法侧重于生成新的实体和关系。
与这些研究不同的是,我们使用实体和关系的名称或描述作为输入和微调BERT来计算三元组的可信分数。
方法
来自transformer的双向编码表示
BERT (Devlin et al. 2019)是建立在多层双向transformer编码器(V aswani et al. 2017)上的最先进的预训练上下文语言表示模型。Transformer编码器是基于自注意机制的。在BERT框架中有两个步骤:预训练和微调。在训练前,BERT在大规模的无标记通用领域语料库(来自BooksCorpus和英语维基百科的3,300M单词)上进行训练,完成两项自我监督任务:掩码语言建模和下一个句子预测。在掩码语言建模中,BERT预测随机掩码输入tokens。在下一句子预测中,BERT预测两个输入句子是否连续。为了进行微调,BERT使用预先训练的参数权重进行初始化,并使用来自下游任务(如句子对分类、问答和序列标注)的标记数据对所有参数进行微调。
知识图谱BERT
为了充分利用上下文表示和丰富的语言模式,我们对预先训练的BERT进行了微调来完成知识图谱补全。
我们将实体和关系表示为它们的名称或描述,然后将名称/描述词序列作为BERT模型的输入句子进行微调。作为原始的BERT,一个“句子”可以是连续文本或单词序列的任意范围,而不是一个实际的语言句子。为了模拟三元组的可信度,我们将(h, r, t)的句子打包成一个单独的序列。序列是指BERT的输入token序列,可以是两个实体名称/描述句子或(h, r, t)的三个句子打包在一起。
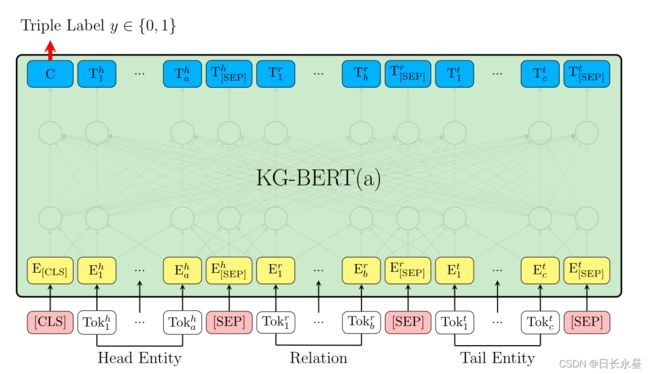
建模三元组的KG-BERT(a)
每个输入序列的第一个token总是一个特殊的分类token[CLS],头部实体表示为包含token的句子,Tok h1, …, Tok ha,e.g., “Steven Paul Jobs was an American business mag-nate, entrepreneur and investor .” or “Steve Jobs” ,关系被表示为一个包含token的句子 Tok r1, …, Tok rb e.g., “founded” 尾部实体表示为包含token的句子 Tokt 1, …, Tok tc “Apple Inc. is an American multinational technology company headquar- tered in Cupertino, California.” or “Apple Inc.” 实体和关系的句子由一个特殊的token[SEP]分开。对于给定的token,其输入表示是通过对相应的token、分割和位置嵌入的求和来构造的,[SEP]分离的不同元素有不同的segment embedding,head和tail实体句子中的token共享相同的segment embedding eA,而关系句子中的token有不同的segment embedding eB ,不同的token在同一位置i∈{1,2,3,…,512}具有相同的位置嵌入。每个输入token i都有一个输入表示 Ei,token表示被输入到BERT模型体系结构中,该体系结构是基于(V aswani等人2017)中描述的原始实现的多层双向变压器编码器。
特殊的[CLS]token和第i-th输入token的最终hidden向量记为C∈R H and Ti∈RH,H是预训练的BERT的hidden state size,最终对应于CLS的hidden state C,用于计算三元组分数的聚合序列表示。在三元组分类微调过程中引入的唯一新参数是分类层权重,W∈R 2×H,三元组的评分函数 τ= (h, r, t)是 sτ=f(h, r, t) =sigmoid(CWT),sτ∈R2
是一个二维实向量,sτ0, sτ1∈[0,1] and sτ0+sτ1= 1,构造正例和负例的三元组集D+ 和 D−,计算交叉熵损失(sτ和三元组标签yτ ),其中yτ 是三元组是正例还是负例的标签, 取0或1。
负样本仍然是负采样, 仅替换头实体和尾实体得来的。
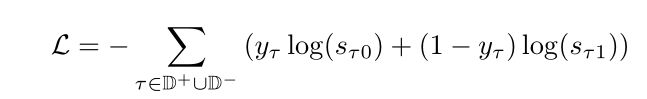
E为实体集合,注意,如果一个三元组已经在正集合中,那么它将不会被视为一个负的例子。通过梯度下降,可以更新预训练的参数权值和新权值W。
预测关系的KG-BERT–KGBERT(b)
我们只使用这两个实体的句子来预测它们之间的关系,在实验中, 作者发现这种结构在直接预测关系时效果要优于KG - BERT(a),负样本仍然来源于负采样, 只是对正例三元组的关系进行替换即可,替换成随机的关系,在KG-BERT(a)中,与[CLS]相对应的最终hidden stateC被用作两个实体的表示,关系预测微调中唯一引入的新参数也是分类层权值 W‘∈R R×H,其中R为KG中的关系数。三元组的评分函数τ= (h, r, t) 是sτ’=f(h, r, t) =softmax(CW‘T),s’τ∈RR 是R维的向量,s‘τ i∈[0,1]以及和为概率1。计算交叉熵损失(s’τ和关系标签)

τ是一个正三元组,Y‘τi是三元组τ的关系标签,y’τ i= 1当 r等于i andy‘τ i= 0 当r不等于i。
实验
1.模型能不能判断没见过的三元组的正确与否?(KG - BERT(a))
2.模型能不能根据给出的单个实体和关系描述预测出另一个实体?(Link Prediction)
3.模型能不能预测两个实体之间的关系?(KG - BERT(b))
Database
我们在六组广泛使用的基准KG数据集上进行了实验:WN11、FB13 、FB15K 、WN18RR、FB15K -237和UMLS 。WN11和WN18RR是WordNet的两个子集,FB15K和FB15K -237是Freebase的两个子集。
WordNet 是一个大型的英语词汇 KG,其中每个实体作为一个同义词集合,由几个单词组成并对应于不同的词义。Freebase是一个关于世界常识的大型知识图谱。UMLS是一个包含语义类型(实体)和语义关系的医学语义网络。WN11和FB13的测试集包含正例和负例的三元组,可以用于三元组分类,WN18RR、FB15K、FB15K -237和UMLS的测试集只包含正确的三元组,我们对这些数据集进行链接(实体)预测和关系预测。表1提供了我们使用的所有数据集的统计信息。
对于WN18RR,我们使用同义词集定义作为实体句子。对于WN11、FB15K和UMLS,我们使用实体名称作为输入句子。对于FB13,我们使用Wikipedia中的实体描述作为输入句子。对于FB15k-237,我们使用了(Xie et al. 2016)的实体描述。对于所有数据集,我们使用关系名作为关系句子。
Baselines
我们将KG- bert与以下几种最先进的KG嵌入方法进行比较。
1.仅使用KG中的结构信息 2.神经张量网络NTN 3.CNN模型 4.带有文本信息的KG嵌入 5.具有实体层次类型的KG嵌入 6.上下文的KG嵌入 7.复杂评估(复值)的KG嵌入 8.对抗性学习框架
设置
我们选择预先训练的12层、12个自注意头、h = 768的BERT-Base模型作为KG-BERT的初始化,然后微调KG-BERT通过Adam在BERT中执行。在我们的初步实验中,我们发现BERT-Base模型总体上比BERT-Large模型能获得更好的结果,而且BERT-Base模型更简单,对超参数选择的敏感性更低。按照原来的BERT,我们在KG-BERT微调中设置了以下超参数:批量大小(batch size):32,学习率:5e-5,信息漏失:0.1,我们还在(Devlin et al. 2019)中尝试了这些超参数的其他值,但没有发现太大的差异。我们为不同的任务调整了epochs的数量,3为三元组分类,5为链接(实体)预测,20为关系预测,我们发现,在关系预测中,更多的epochs可以带来更好的结果,但在其他两项任务中则不然。对于三元组分类训练,我们采样1个负三元组从正三元组的样本,它可以保证二元分类中的类平衡。对于链接(实体)预测训练,我们从采样5个负三元组从一个正三元组,尝试了1、3、5和10,发现5是最好的。
三元组分类
三元组分类的目的是判断给定的三元组(h, r, t)是否正确。表2给出了不同方法对WN11和FB13的三元组分类精度。我们可以看到KG-BERT(a)明显优于所有基线,这表明了我们方法的有效性。我们运行我们的模型10次,发现标准差小于0.2,改善是显著的(p <0.01)。据我们所知,KG-BERT(a)取得了迄今为止最好的结果。为了进行更深入的性能分析,我们注意到TransE无法获得较高的准确性分数,因为它不能处理1-to-N、N-to-1和N-to-N关系。TransH、TransR、TransD、transsparse和TransG通过引入关系特定参数而优于TransE。DistMult的性能相对较好,也可以通过DistMult- hrs中使用的层次关系结构信息进行改进。ConvKB显示了良好的结果,这表明CNN模型可以捕获实体嵌入和关系嵌入之间的全局交互。DOLORES通过整合上下文信息在实体关系随机行走链进一步改进了ConvKB。NTN在FB13上的表现也很有竞争力,这意味着它是一个有表现力的模型,用词嵌入来表示实体是很有帮助的。其他文本增强KG嵌入式TEKE和AATE优于他们的基础模型,如TransE和TransH,展示了外部文本数据的好处,然而,由于丰富语言模式的使用率较低,它们的改进仍然有限。KG-BERT(a)在WN11上比FB13的基线改善更大,因为WordNet是一个语言知识图,更接近预先训练的语言模型所包含的语言模式。
KG-BERT(a)表现良好的主要原因有四个方面:
- 输入序列同时包含实体词序列和关系词序列
- 三元组分类任务与BERT预训练中的下一个句子预测任务非常相似,该任务捕获了大型自由文本中两个句子之间的关系,因此预先训练的BERT权值被很好地定位,用于推断三元组文本中不同元素之间的关系。
- token hidden vectors是上下文嵌入。同一个token可以在不同的三元组中有不同的hidden vectors,因此可以显式地使用上下文信息
- 自我注意机制可以发现与三元组事实相关的最重要的词。
链接预测
链接(实体)预测任务预测缺少的元素,使用评分函数生成的排名来评估结果。
关系预测
针对论文的几点疑惑
-
如果针对单个句子(实体|关系)进行处理,怎么得到丰富的实体关系上下文信息的;又是怎么用在比如问答系统这样的下游任务的
-
如果对输入整个句子进行处理,为何最后 [CLS] batchsize x embeddingdimension
-
预训练语言模型在实际准备的数据集上如何微调得到想要的模型,是不是总共得训练两遍?