Spatio temporally Action Detection Location 系列(1) :AVA Dataset And Action Localization Model
Spatio temporally Action Detection Location 系列(1):AVA数据集与基准模型
- AVA数据集
- Action Localization Model
-
- 5.1 当前研究水平的局限:
- 5.2 方法结构:
- 5.3 Baseline.:
- 5.4 Implementation details:
- 5.5 Linking连接
- Experiments and Analysis
-
- 6.1 Datasets and Metrics
- 6.2. Comparison to the state-of-the-art
- 6.3. Ablation study
AVA数据集
之前写的都是行为检测的,实际中发现大部分需求场景都是多人多动作的,因此要把每个人不同动作区分开来,并实现行为的时序检测和空间定位,因此决定写这个action location detection系列,后续附有一个简单的pytorch实现。
AVA数据集是google发布的一个视频行为检测与定位的视频数据集,包含在430个15分钟的视频片段中标注了的80种原始动作,这些动作由时间和空间定位,产生了1.58M个动作标签。因为网上关于它的介绍已经有很多,可以参考官网和论文《A Video Dataset of Spatio-temporally Localized Atomic Visual Actions》.,本文重点是介绍论文中所提出的action location模型。
Action Localization Model
对应论文的第5节. Action Localization Model
5.1 当前研究水平的局限:
近年来,诸如UCF101或JHMDB等流行动作识别数据集的性能数字有了显著的增长,但我们认为,这可能人为地呈现了当前技术状态的乐观图景。当视频剪辑中只有一个人在一个同样具有视觉特征的背景场景中游泳时,很容易对action进行分类.当演员是多重的,或图像大小很小,或执行的动作只有细微的不同,以及当背景场景不足以告诉我们发生了什么时,就会出现困难。AVA拥有丰富的这些方面,我们会发现在AVA的性能会因此变得很差。事实上,这一发现是由字谜数据集的糟糕性能所预示的。
为了证明我们的观点,我们开发了一种最新的基于多帧时间信息的时空动作定位方法[16,41]。在这里,我们依靠基于I3D[6]的更大时间上下文的影响来进行动作检测。有关我们的方法的概述,请参见下图。
跟随彭和施密德[30],我们应用得更快RCNN算法[31]的端到端定位和分类的行动。然而,在他们的方法中,时间信息丢失在第一层,来自多个帧的输入通道随着时间连接在一起。我们建议使用由卡瑞拉和Zisserman[6]设计的**Inception 3D (I3D)**架构来建模时间上下文。I3D架构是在Inception架构[40]的基础上设计的,但是用3D卷积代替了2D卷积。时间信息保存在整个网络中。
5.2 方法结构:
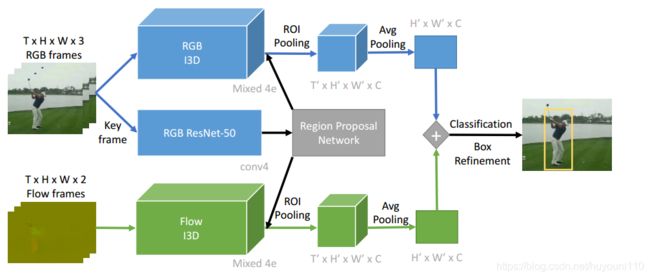
首先,将长度为T的输入帧输入到I3D模型中,提取其三维特征图在网络的混合4e层,尺寸为t0×w0×H0×C,混合4e处的输出特征图的步长为16,等价于ResNet的conv4块.
其次,对于行动建议的生成,我们使用关键帧上的2D ResNet-50模型作为区域建议网络的输入,避免不同输入长度的I3D对生成的行动提案质量的影响.最后,通过二维ROI POOling在所有时间步骤中在相同的空间位置进行池化,把ROI Pooling 扩展为3D。
为了了解光流对动作检测的影响,我们使用平均池将RGB流和光流融合在特征图级。
注:根据图来看结构,在每个时间上2d ROI Pooling,然后拼接为4d特征。然后在时间长度上使用avg平均Pooling,特征变为[H,W,C],在此时可以融合光流信息,然后送入分类层。
5.3 Baseline.:
为了与基于框架的AVA双流方法进行比较,我们实现了[30]的一个变体。我们使用更快的RCNN[31]与ResNet-50[14]共同学习行动建议区域和行动标签.区域建议仅使用RGB流获得。区域分类器以RGB为输入,并叠加光流特征连续5帧。对于I3D方法,我们将conv4 feature map与平均池融合,共同训练RGB和光流。
5.4 Implementation details:
我们实现了FlowNetv2[19]来提取光流特征.我们用异步SGD训练快速rcnn。对于所有的培训任务,我们使用一个验证集来确定培训步骤的数量,其范围从600K到1M迭代。我们将输入分辨率设置为320×400像素。所有其他模型参数都是根据来自[17]的推荐值设置的,这些值经过调优以用于对象检测。:ResNet-50网络由ImageNet预训练模型初始化。对于光流,我们将conv1滤波器复制到输入5帧。该I3D网络由kinetics[22]预训练模型初始化,无论是RGB和光流。注意,尽管I3D是针对64帧输入进行预训练的,但随着时间的推移,网络是完全卷积的,可以接受任意帧作为输入。在培训过程中,所有的特性层都会一起更新反向传播。对输出帧级检测进行后处理,阈值为0.6,非最大抑制。
AVA与现有动作检测数据集的一个关键区别是,AVA的动作标签并不完全是互斥的。为了解决这个问题,我们将标准的softmax损失函数替换为二进制Sigmoid损失之和,每个类一个。我们对AVA使用Sigmoid丢失,对所有其他数据集使用softmax丢失.
5.5 Linking连接
一旦我们有了每个帧级的检测,我们就把它们连接起来,构成行动管。我们报告的视频水平的表现基于平均得分获得的管。我们使用与[38]中描述的相同的链接算法,只是没有应用时间标记。由于AVA的标注频率为1hz,而且每个管子可能有多个标签,因此我们修改了视频级评估协议来估计上限。我们使用地面真值链接来推断检测链接,当计算一个类在地面真值管和检测管之间的IoU分数时,我们只考虑该类标记的管段。
Experiments and Analysis
这里是重点,对每个类别分析了准确率低的原因,是以后努力的方向。
6.1 Datasets and Metrics
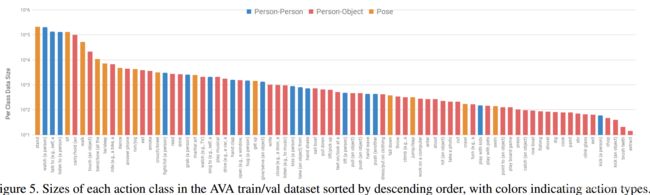
AVA benchmark: 由于AVA中的标签分布大致遵循Zipf定律(下图),并且对非常少的示例进行评估可能不可靠,所以我们使用至少有25个实例的类进行验证和测试,从而对性能进行基准测试。我们得到的基准测试包括210,634个培训、57,371个验证和
在60个类上测试117,441个示例。除非另有说明,我们报告在训练集上训练的结果,并在验证集上进行评估。我们随机选择10%的训练数据进行模型参数调优.
数据集: 此外,我们还分析了标准的视频数据集,以比较难度。JHMDB[20]由21个类中的928个裁剪剪辑组成。我们在消融研究中报告了劈裂的结果,但是为了与目前的技术水平进行比较,结果平均分为三个劈裂。为
UCF101中,我们对一个包含3207个视频的24类子集使用时空注释,这些视频由Singh等人提供。我们在标准的官方split1上进行了实验
指标: 对于评估,我们尽可能遵循标准实践。我们报告了交叉-过度联合(IoU)在帧级和视频级的性能。对于帧级IoU,我们遵循PASCAL VOC challenge[9]使用的标准协议,并使用0.5的IoU阈值报告平均精度(AP)。对于每个类,我们计算平均精度并报告所有类的平均精度。对于视频级IoU,我们在阈值为0.5时计算了地面真值管与连接检测管之间的三维IoU。平均AP是通过对所有类求平均值来计算的.
6.2. Comparison to the state-of-the-art
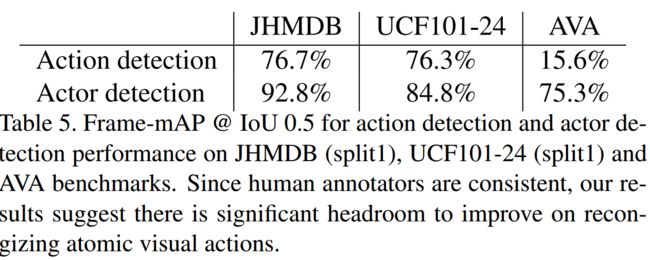
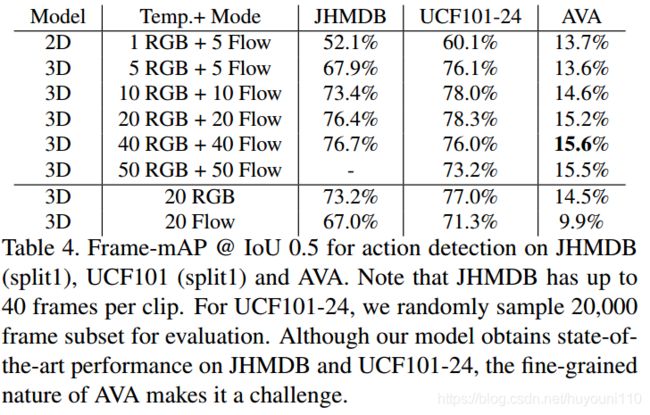
表3显示了我们在两个标准视频数据集上的模型性能.然而,当认识到原子的作用时,情况就不那么乐观了。表4显示,相同的模型在AVA验证集上的性能相对较低 (帧映射为15.6%,帧映射为12.3%,帧映射为0.5 IoU,帧映射为17.9%,帧映射为0.2 IoU),以及测试集(帧映射为14.7%)。我们把这归功于背后的设计原则
AVA:我们收集了一个词汇表,其中上下文和物体线索对动作识别没有那么大的区别。相反,要在AVA取得成功,可能需要识别细粒度的细节和丰富的时间模型,这对视觉动作识别提出了新的挑战.
6.3. Ablation study
时间信息对于识别有多重要?表4显示了时间长度和模型类型的影响。所有的3D模型在JHMDB和UCF101-24上都优于2D基线。对于AVA来说,3D模型在使用超过10帧后表现得更好。我们还可以看到,增加时间窗口的长度有助于跨所有数据集的3D双流模型。
正如预期的那样,结合RGB和光流特性可以在单一输入模态下提高性能。此外,相对于更大的时间背景,AVA受益更多,JHMDB和UCF101,它们的性能在20帧时达到饱和。表1中的这种收益和连续的操作表明,通过利用AVA中丰富的时间上下文,可以获得进一步的收益.
- 定位和识别的挑战有多大? 表5比较了端到端操作定位和识别与类无关的操作定位的性能。定位与端到端检测性能的差距接近60%在AVA中,低于15%在JHMDB和UCF101。
- 这说明AVA的主要困难在于动作分类而不是定位。图9显示了得分很高的错误警报的例子,表明识别的困难在于细粒度的细节
- 哪些类别具有挑战性?培训实例的数量有多重要?
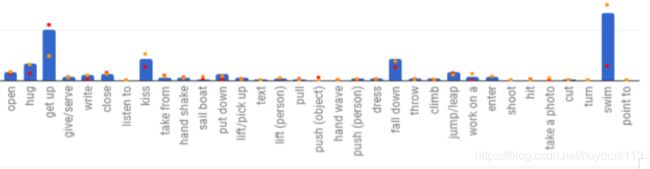
- 图8按类别和培训示例的数量划分了性能。虽然更多的数据通常会产生更好的性能,但异常值表明,并非所有类别的复杂性都是相同的。与场景和对象相关的类别(如游泳)或多样性较低的类别(如跌倒)在训练实例较少的情况下仍能获得较高的性能。相比之下,拥有大量数据的类别,例如触摸和吸烟,获得相对较低的性能,可能是因为它们具有较大的视觉变化,或者需要细粒度的辨别,从而激发了人-对象交互方面的工作[7,12]。
- 我们假设,在识别原子行为方面取得的进展不仅需要像AVA这样的大型数据集,还需要丰富的运动和交互模型.
- 从这里可以看到,错误的基本都是需要细分类的动作.