Spatio temporally Action Detection Location 系列(2) :A Better Baseline for AVA
Spatio temporally Action Detection Location 系列(2):A Better Baseline for AVA
- 一 简介
- 二 Model and Approach
- 三 Experiments:
- 四 与ava不同:
- 五 不同配置影响:
- 六 I3D结构:
- 七 code
一 简介
这篇论文很短,提供了一个改进的方法,流程也更为简单,本文还是主要介绍模型框架.
我们在AVA数据集上引入了一个简单的动作本地化基线。 该模型建立在更快的R-CNN边界框检测框架之上,适用于纯时空特征 - 在我们的案例中,仅由在Kinetics上预先训练的I3D模型生成。 该模型在AVA v2.1的验证集上获得21.9%的平均AP,而原始AVA论文(在Kinetics和ImageNet上预先训练)中使用的最佳RGB时空模型的平均AP为14.5%,高于11.3%。 使用在ImageNet上预训练的ResNet-101图像特征提取器的公共可用基线。 我们的最终模型在val /测试集上获得了22.8%/ 21.9%mAP,并且优于CVPR 2018年对AVA挑战的所有提交。
二 Model and Approach
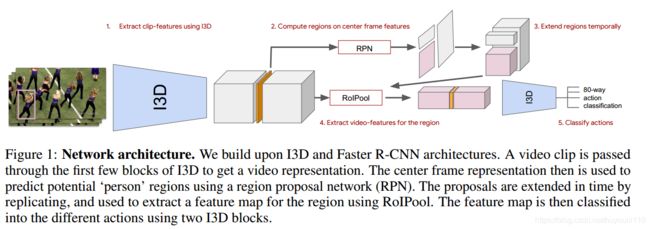
- 如上图,基于在kinetics预训练的I3D和faster rcnn,输入围绕关键帧的64帧;首先到“Mixed_4f”层,取出中间层对应的特征;经过标准RPN,提取建议box,取前300个建议区域,然后再提取特征进行分类。
- 关键帧经过RPN后是2D的,沿时间维度复制成3D。(------1 不同,我没有复制------)
- 然后使用ROIPooling。其中RoIPooling针对每个时间点的2Dfeature做,最后在时间轴上concat,形成4D feature
- 之后再进入I3D最后两层,直到 Mixed_5c,然后分类到80个类别。类别判断是非排他的,即不是softmax,而是一个box可以多分类。box的回归不会管具体的类别。最后我们对每个类再使用nms,保持前300个得分最高的box
三 Experiments:
input_size : 320 by 400 fix this (------4 不同,我用240 * 320 ------)
batch:3 videos with 64 frames each,(------3 不同,我用16 or 32 ------)
augment:left-right flip,spatial cropping.
train: 500k steps using SGD (------3 不同,我用16 or 32 ------) 2500 * 100 = 25w
i3d:pretrained on Kinetics-400 or the larger Kinetics-600.
四 与ava不同:
1 ava使用resnet生成rpn,i3d分类;我们直接使用I3D
2 ava在ROI-POOLING后使用全局平均池化,我们模型保存时空的自然特性一直到分类层。
3 ava的box有80个不同类的回归 ,我们使用了与分类无关的box回归,对应于faster-rcnn中的class_agnostic参数.
4 只使用RGB
5 ava pretrained on ImageNet then Kinetics-400,我们 pretrained on Kinetics-400 or the larger Kinetics-600
五 不同配置影响:
1 Kinetics pretrained model 提升2%
2 box与分类无关可以提升4%,因为我们检测的一直是人,这一步很重要,因为检测的目标都是人,所以box不应做区分。
3 数据增强很重要,5%
六 I3D结构:
1 输入 :16帧,112*112
self.features = nn.Sequential(
BasicConv3d(input_channel, 64, kernel_size=7, stride=2, padding=3), # (64, 384, 56, 56)
nn.MaxPool3d(kernel_size=(1,3,3), stride=(1,2,2), padding=(0,1,1)), # (64, 384, 28, 28)
BasicConv3d(64, 64, kernel_size=1, stride=1), # (64, 384, 28, 28)
BasicConv3d(64, 192, kernel_size=3, stride=1, padding=1), # (192, 384, 28, 28)
nn.MaxPool3d(kernel_size=(1,3,3), stride=(1,2,2), padding=(0,1,1)), # (192, 384, 14, 14)
Mixed_3b(), # (256, 384, 14, 14)
Mixed_3c(), # (256, 384, 14, 14)
nn.MaxPool3d(kernel_size=(3, 3, 3), stride=(2, 2, 2), padding=(1, 1, 1)), # (480, 192, 7, 7)
Mixed_4b(),# (512, 192, 7, 7)
Mixed_4c(),# (512, 192, 7, 7)
Mixed_4d(),# (512, 192, 7, 7)
Mixed_4e(),# (528, 192, 7, 7)
Mixed_4f(),# (832, 192, 7, 7)
#
#nn.MaxPool3d(kernel_size=(2, 2, 2), stride=(2, 2, 2), padding=(0, 0, 0)), # (832, 96, 3, 3)
nn.MaxPool3d(kernel_size=(2, 1, 1), stride=(2, 1, 1), padding=(0, 0, 0)), # (832, 96, 7, 7)
Mixed_5b(), # (832, 96, 7, 7)
Mixed_5c(), # (1024, 96, 7, 7)
#
nn.AvgPool3d(kernel_size=(2, 7, 7), stride=1),# (1024, 8, 1, 1)
nn.Dropout3d(dropout_keep_prob),
nn.Conv3d(1024, num_classes, kernel_size=1, stride=1, bias=True),# (400, 8, 1, 1)
)
self.spatial_squeeze = spatial_squeeze
self.softmax = nn.Softmax()
七 code
参考该模型,基于faster-rcnn和i3d做了一个简单的pytorch实现,可以训练预测action location.稍后上传放出.