动作/行为识别调研
动作识别调研
- 1. 简介
-
- 1.1 基本概念
- 1.2 难点
- 2. 人体动作识别系统
-
- 2.1 传统方法
-
- 2.1.1 iDT框架
- 2.2 深度学习方法
-
- 2.2.1 Two-Stream双流架构
- 2.2.2 3D卷积架构
- 2.2.3 CNN+LSTM架构
- 2.2.4 GCN架构
- 相关文献
1. 简介
动作识别(Action Recognition),就是从视频片段(可视为2D帧序列)中分辨人的动作类型,常用数据库包括UCF101,HMDB51等。相当于对视频进行分类。常用的方法有Two Stream,SlowFast,TSN,C3D,I3D等等
时序动作定位(Temporal Action Localization),不仅要知道一个动作在视频中是否发生,还需要知道动作发生在视频的哪段时间(包括开始和结束时间)。特点是需要处理较长的,未分割的视频。且视频通常有较多干扰,目标动作一般只占视频的一小部分。常用数据库包括HUMOS2014/2015, ActivityNet等。相当于对视频进行指定行为的检测。
时空动作检测(Spatial-temporal Action Detection),类似目标检测,不仅需要定位视频中可能存在行为动作的视频段,还需要将其分类,即:localization+recognition。而定位存在行为动作的视频段是一个更加艰巨的任务。常用的方法有SlowFast,SlowOnly等等。
- 从操作角度,可以看作将视频转换为多个RGB帧,再对多帧组合进行特征提取,最后融合并分类。
- 从实现方法,可以分为传统方法和深度学习方法,目前传统方法最好的是iDT,深度学习有双流框架,3D卷积框架等等方法。
- 从检测角度,一般分为基于骨骼点检测和基于RBG视频检测,也有数据来源深度传感器。
K i n e t i c s − 400 数 据 集 上 的 动 作 识 别 Kinetics-400数据集上的动作识别 Kinetics−400数据集上的动作识别
A V A 数 据 集 上 的 时 空 动 作 检 测 AVA数据集上的时空动作检测 AVA数据集上的时空动作检测
N T U − R G B + D − 120 数 据 集 上 的 基 于 骨 骼 点 检 测 的 动 作 识 别 NTU-RGB+D-120数据集上的基于骨骼点检测的动作识别 NTU−RGB+D−120数据集上的基于骨骼点检测的动作识别
1.1 基本概念
-
图像识别的四类任务:
- 分类-Classification:解决“是什么?”的问题,即给定一张图片或一段视频判断里面包含什么类别的目标。
- 定位-Location:解决“在哪里?”的问题,即定位出这个目标的的位置。
- 检测-Detection:解决“在哪里?是什么?”的问题,即定位出这个目标的位置并且知道目标物是什么。
- 分割-Segmentation:分为实例的分割(Instance-level)和场景分割(Scene-level),解决“每一个像素属于哪个目标物或场景”的问题。
-
动作识别vs姿态估计:姿态估计是在RGB图像或视频中描绘出人体的形状,包括关键点的检测,如下图所示。使用姿态估计的骨骼点数据也可作为动作识别的输入。
-
动作识别vs目标检测(Object Detection):目标检测是识别图片或者视频中有哪些物体以及物体的位置,也就是进行目标定位加上分类。如果用目标检测算法进行行为识别的弊端是缺乏前后语义相关性,假如摔倒的判断是由一个从"站立-滑倒-倒下"的过程,我们才能判断为摔倒,不能凭借目标检测算法检测到人是倒下的就判断为摔倒。
-
光流(optical flow):
-
当人的眼睛观察运动物体时,物体的景象在人眼的视网膜上形成一系列连续变化的图像,这一系列连续变化的信息不断“流过”视网膜(即图像平面),好像一种光的“流”,故称之为光流。
-
光流法是利用图像序列中像素在时间域上的变化以及相邻帧之间的相关性来找到上一帧跟当前帧之间存在的对应关系,从而计算出相邻帧之间物体的运动信息的一种方法。
-
光流的物理意义
-
光流是空间运动物体在观察成像平面上的像素运动的瞬时速度。
-
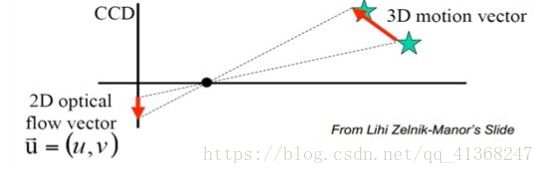
光流通常被表述为估计世界真实三维运动的二维投影的问题,可以被看作是连续帧之间的位移矢量场,用 (,)表示某帧t上的一点(u,v)变化到下一帧t+1相应的位置时的位移矢量的变化。_{}^{} 和_^ 分别表示位移矢量的水平和垂直分量。如下图所示:
-
-
光流场
- 光流场是一个二维矢量场,它反映了图像上每一点灰度的变化趋势,可看成是带有灰度的像素点在图像平面上运动而产生的瞬时速度场。它包含的信息即是各像点的瞬时运动速度矢量信息。


- 光流场是一个二维矢量场,它反映了图像上每一点灰度的变化趋势,可看成是带有灰度的像素点在图像平面上运动而产生的瞬时速度场。它包含的信息即是各像点的瞬时运动速度矢量信息。
-
1.2 难点
-
计算量大,耗时大。
-
需要考虑上下文。
-
网络结构的设计。
-
光流问题。
- 计算量较大;
- 难以描述长时间的动作。
-
其他视觉任务的通病。
- 类内和类间差异, 同样一个动作,不同人的表现可能有极大的差异;
- 环境差异, 遮挡、多视角、光照、低分辨率、动态背景;
- 时间变化, 人在执行动作时的速度变化很大,很难确定动作的起始点,从而在对视频提取特征表示动作时影响最大;
- 缺乏标注良好的大的数据集。
2. 人体动作识别系统

人 体 动 作 识 别 系 统 人体动作识别系统 人体动作识别系统
人体动作识别系统的流程为:首先捕获一段视频,并处理成动作表征的数据集,接着提取动作表征的特征,例如骨骼点(Pose-based),兴趣点(Interest Point-based)等等,然后进行特征降维,并分割为训练、检测、验证数据集。得到数据集后,在训练阶段,使用传统/深度学习方法,进行动作识别的模型训练,在检测阶段,将测试集数据输入到训练好的模型中,得到相应的行为识别检测结果。
2.1 传统方法
在传统的行为识别模型中,通常都是先提取手工特征(HOG,HOF,Dense Trajectories等),然后使用分类器进行分类。其中iDT (improved dense trajectories) 是深度学习进入该领域前传统方法中效果最好,稳定性最好,可靠性最高的方法,不过算法速度很慢(在于计算光流速度很慢)。
2.1.1 iDT框架
iDT的基本思路为利用光流场来获得视频序列中的一些轨迹,再沿着轨迹提取HOF,HOG,MBH,trajectory4种特征,其中HOF基于灰度图计算,另外几个均基于dense optical flow(密集光流)计算。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。
- Fisher Vector 特征编码 主要思想是使用高斯分布来拟合单词 而不是简简单单的聚类产生中心点
Dense Trajectories and Motion Boundary Descriptors for Action Recognition
Action Recognition with Improved Trajectories
2.2 深度学习方法
- 基于骨骼关键点检测:从相机的骨骼检测技术,或者姿态估计算法获取骨骼点数据;然后将骨架数据输入神经网络中,最后得到行为类别。 经典方法包括ST-NBNN,Deformable Pose Traversal Convolution,以及最近比较火热的图卷积方法(例如ST-GCN)。
- 基于RGB视频检测: 基于RBG视频分帧后的集合中捕获时空特征,并融合多帧结果进行输出。目前常用的架构有双流,3D卷积,CNN+LSTM,其中双流架构,精度相对更高,但需要额外提取光流,因此速度较慢;3D卷积架构通常属于端到端结构,速度更快,但精度相对更慢,通常会结合双流+3D卷积进一步提升精度;此外CNN+LSTM架构在性能表现上都不是很优秀。
2.2.1 Two-Stream双流架构
双流架构的开山之作:Two Stream CNN,如图所示。

将视频分成空间域和时间域,空间域以单帧RGB作为输入,携带有关视频中描绘的场景和对象的信息。时间域以多帧密度光流场为输入,能够描述多帧之间的动作变化。因此,Two Streams网络分为两个分支:
- 一个分支输入原始视频的RGB 图像(捕获空间信息);
- 一个分支输入RGB 图像计算得到的光流(捕获时间信息)。
Two-stream convolutional networks for action recognition in videos.
再比如最近很火的SlowFast Stream
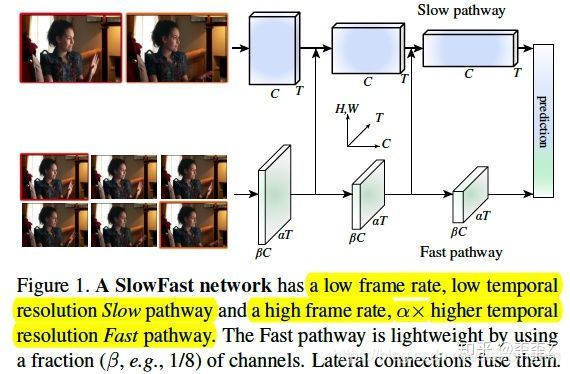
类似Two Stream,SlowFast Stream也是由双流构成,一条为快速流 (Fast Stream),一条为慢速流 (Slow Stream), 而传统的双流架构中每条数据流代表不同的模态(RGB+光流)。
- 一个分支用来捕获图像或稀疏帧所提供的空间语义信息,它以较低的帧率和较慢的刷新速度运行。
- 一个分支负责快速捕获运动的变化,它以较快的更新速度和高时间分辨率运行。
- 慢速流中包含了更多的空间信息 ,而快速流中包含了更多的时序信息 。
Two-stream convolutional networks for action recognition in videos
2.2.2 3D卷积架构
3D convolution 直接将2D卷积扩展到3D(添加了时间维度),直接提取包含时间和空间两方面的特征。可直接使用单RBG视频流进行3D卷积输出结果,属于端到端网络,方法较快,但是精度会比双流网络稍差一点。为了提升精度,可以加入双流架构。该方法的开山之作是C3D。

Learning Spatiotemporal Features with 3D Convolutional Networks
2.2.3 CNN+LSTM架构
因为视频除了空间维度外,最大的痛点是时间序列问题。而众所周知,RNN网络在NLP方向取得了傲人的成绩,非常适合处理序列。所以除了上述两大类方法以外,另外还有一大批的研究学者希望使用RNN网络思想来解决动作识别问题。
该类框架的思想是使用CNN处理空间信息,使用LSTM处理时序信息。LCRN为代表之作,如图所示。
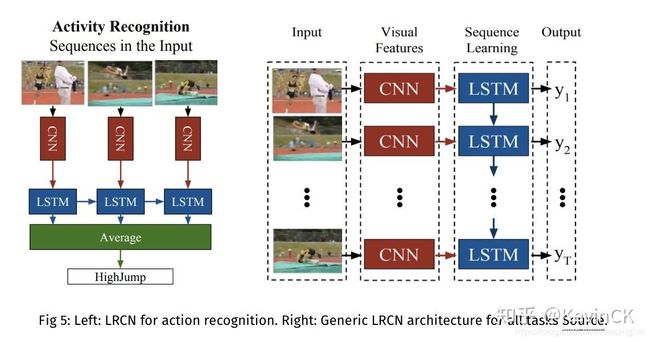
也可以进一步加入双流架构提升精度。
Long-term Recurrent Convolutional Networks for Visual Recognition and Description
2.2.4 GCN架构
人体的骨骼图本身就是一个拓扑图,因此将GCN运用到动作识别上是一个非常合理的想法。但不同于传统的图结构数据,人体运动数据是一连串的时间序列,在每个时间点上具有空间特征,而在帧于帧之间则具有时间特征,如何通过图卷积网络来综合性的发掘运动的时空特征,是目前的行为识别领域的研究热点。例如ST-GCN。

Spatial Temporal Graph Convolutional Networks for Skeleton Based Action Recognition
相关文献
待续