基于PCA的故障诊断方法(matlab)
1. PCA原理分析
PCA的原理主要是将原始数据进行降维。其具体工作原理参照:CodingLabs - PCA的数学原理
2. 数据预处理
训练数据集(只有正样本)为![]() 维数据,即有n个采样值,每个采样值有m个特征。
维数据,即有n个采样值,每个采样值有m个特征。

2.1 数据归一化
将数据X针对每个特征归一化为均值为0,均方根为1的数据。
![]()
其中:


3. PCA降维
3.1 首先求取协方差矩阵
协方差矩阵的公式为:
![]()
计算出来的协方差矩阵为特征m*m维矩阵。
3.2 求取特征值和特征向量
求取协方差矩阵R的特征值和特征向量,并将特征值按照从大到小的顺序排列
![]()
将特征向量按照特征值重新排列后得到:
![]()
3.3 选择合适的k个特征进行PCA降维
可以选择特征值累计大于85%的前k个特征进行PCA降维
![]()
令前k个从大到小的特征值构成对角矩阵![]() ,k个对应的特征向量组成将为矩阵
,k个对应的特征向量组成将为矩阵![]() 。即:
。即:
![]()
![]()
PCA降维后,样本数目仍为n个采样,但是特征数目变为k,降维公式为:
![]()
将X进行重构后得到的X‘的矩阵的计算公式为:
![]()
4. 求取统计量限值
4.1 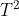 统计量
统计量
4.1.1 统计量的计算公式:
![]()
其中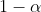 是置信度,
是置信度,![]() 是服从第一自由度为k,第二自由度为n-k的F分布,通常
是服从第一自由度为k,第二自由度为n-k的F分布,通常 取0.01。
取0.01。
另外强调一点是:n是训练数据集的采样数,k为PCA后选择的特征的数量。
4.1.2 计算测试数据的统计量
计算测试数据每个采样值的值。假设测试样本中的一个采样值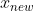 为1*m的一个采样值,该采样值同样经过训练样本的均值和方差进行归一化(注意此处均值和方差使用训练样本的均值和方差,而不是选择训练数据的样本和方差),其计算公式为:
为1*m的一个采样值,该采样值同样经过训练样本的均值和方差进行归一化(注意此处均值和方差使用训练样本的均值和方差,而不是选择训练数据的样本和方差),其计算公式为:
![]()
另外的计算公式也可以简化为:
![]()
其中![]() 表示对角矩阵中的每个元素取-1/2指数,
表示对角矩阵中的每个元素取-1/2指数,![]() 表示2范数的平方。
表示2范数的平方。
4.1.3 故障判定
如系统正常运行,则样本的值应该满足T![]() ,否则则认为出现故障。
,否则则认为出现故障。
4.2 SPE统计量(也称Q统计量)
4.2.1 SPE控制量限值的计算
![]()
其中:

![]()
![]() 是标准正态分布的置信极限。
是标准正态分布的置信极限。
4.2.2 计算测试数据的SPE值
测试数据选择和计算相同的采样值![]() ,同样做相同的归一化处理。
,同样做相同的归一化处理。
![]()
4.3.3 判断是否发生故障
如果系统正常运行,则样本的SPE值应满足![]() ,否则,可认定发生故障。
,否则,可认定发生故障。
5. matlab实现
clc;clear;
%% 1.导入数据
%产生训练数据
num_sample=100;
a=10*randn(num_sample,1);
x1=a+randn(num_sample,1);
x2=1*sin(a)+randn(num_sample,1);
x3=5*cos(5*a)+randn(num_sample,1);
x4=0.8*x2+0.1*x3+randn(num_sample,1);
xx_train=[x1,x2,x3,x4];
% 产生测试数据
a=10*randn(num_sample,1);
x1=a+randn(num_sample,1);
x2=1*sin(a)+randn(num_sample,1);
x3=5*cos(5*a)+randn(num_sample,1);
x4=0.8*x2+0.1*x3+randn(num_sample,1);
xx_test=[x1,x2,x3,x4];
xx_test(51:100,2)=xx_test(51:100,2)+15*ones(50,1);
%% 2.数据处理
Xtrain=xx_train;
Xtest=xx_test;
X_mean=mean(Xtrain);
X_std=std(Xtrain);
[X_row, X_col]=size(Xtrain);
Xtrain=(Xtrain-repmat(X_mean,X_row,1))./repmat(X_std,X_row,1); %标准化处理
%% 3.PCA降维
SXtrain = cov(Xtrain);%求协方差矩阵
[T,lm]=eig(SXtrain);%求特征值及特征向量,特征值排列顺序为从小到大
D=flipud(diag(lm));%将特征值从大到小排列
% 确定降维后的数量
num=1;
while sum(D(1:num))/sum(D)<0.85
num = num+1;
end
P = T(:,X_col-num+1:X_col); %取对应的向量
P_=fliplr(P); %特征向量由大到小排列
%% 4.计算T2和Q的限值
%求置信度为99%时的T2统计控制限,T=k*(n^2-1)/n(n-k)*F(k,n-k)
%其中k对应num,n对应X_row
T2UCL1=num*(X_row-1)*(X_row+1)*finv(0.99,num,X_row - num)/(X_row*(X_row - num));%求置信度为99%时的T2统计控制限
%求置信度为99%的Q统计控制限
for i = 1:3
th(i) = sum((D(num+1:X_col)).^i);
end
h0 = 1 - 2*th(1)*th(3)/(3*th(2)^2);
ca = norminv(0.99,0,1);
QU = th(1)*(h0*ca*sqrt(2*th(2))/th(1) + 1 + th(2)*h0*(h0 - 1)/th(1)^2)^(1/h0); %置信度为99%的Q统计控制限
%% 5.模型测试
n = size(Xtest,1);
Xtest=(Xtest-repmat(X_mean,n,1))./repmat(X_std,n,1);%标准化处理
%求T2统计量,Q统计量
[r,y] = size(P*P');
I = eye(r,y);
T2 = zeros(n,1);
Q = zeros(n,1);
lm_=fliplr(flipud(lm));
%T2的计算公式Xtest.T*P_*inv(S)*P_*Xtest
for i = 1:n
T2(i)=Xtest(i,:)*P_*inv(lm_(1:num,1:num))*P_'*Xtest(i,:)';
Q(i) = Xtest(i,:)*(I - P*P')*Xtest(i,:)';
end
%% 6.绘制T2和SPE图
figure('Name','PCA');
subplot(2,1,1);
plot(1:i,T2(1:i),'k');
hold on;
plot(i:n,T2(i:n),'k');
title('统计量变化图');
xlabel('采样数');
ylabel('T2');
hold on;
line([0,n],[T2UCL1,T2UCL1],'LineStyle','--','Color','r');
subplot(2,1,2);
plot(1:i,Q(1:i),'k');
hold on;
plot(i:n,Q(i:n),'k');
title('统计量变化图');
xlabel('采样数');
ylabel('SPE');
hold on;
line([0,n],[QU,QU],'LineStyle','--','Color','r');
%% 7.绘制贡献图
%7.1.确定造成失控状态的得分
S = Xtest(51,:)*P(:,1:num);
r = [ ];
for i = 1:num
if S(i)^2/lm_(i) > T2UCL1/num
r = cat(2,r,i);
end
end
%7.2.计算每个变量相对于上述失控得分的贡献
cont = zeros(length(r),X_col);
for i = length(r)
for j = 1:X_col
cont(i,j) = abs(S(i)/D(i)*P(j,i)*Xtest(51,j));
end
end
%7.3.计算每个变量的总贡献
CONTJ = zeros(X_col,1);
for j = 1:X_col
CONTJ(j) = sum(cont(:,j));
end
%7.4.计算每个变量对Q的贡献
e = Xtest(51,:)*(I - P*P');%选取第60个样本来检测哪个变量出现问题。
contq = e.^2;
%5. 绘制贡献图
figure
subplot(2,1,1);
bar(contq,'g');
xlabel('变量号');
ylabel('SPE贡献率 %');
hold on;
subplot(2,1,2);
bar(CONTJ,'r');
xlabel('变量号');
ylabel('T^2贡献率 %');训练数据为自己创建的x1,x2,x3和x4,其中x4是和x2,x3相关的变量。测试数据和训练数据完全一致,只不过在第50个数据后在x2上添加了故障。
得到的结果如下:
从上图可以明显看出测试数据在第50个数据开始,T2和SPE值都超限,证明发生故障。
通过贡献图分析,可以看出变量2为故障发生点,与实际情况相符。对于故障发生点还有更精细的方法。此处不做深究。
参考:基于PCA的线性监督分类的故障诊断方法-T2与SPE统计量的计算_And_ZJ的博客-CSDN博客_spe统计量