【MySQL】MySQL数据库结构与操作

✨个人主页:bit me
✨当前专栏:MySQL数据库
✨每日一语:自从厌倦于追寻,我已学会一觅即中,自从一股逆风袭来,我已能抗御八面来风,驾舟而行。
目 录
- 一. 数据库介绍
-
- 1.1 什么是数据库
- 1.2 数据库分类
- 二. MySQL的结构
-
- 2.1 MySQL服务器和客户端
- 2.2 MySQL服务器是如何组织数据的
- 三. 数据库的操作
-
- 3.1 创建数据库
- 3.2 显示当前的数据库
- 3.3 使用数据库
- 3.4 删除数据库
- 四.常用数据类型
-
- 4.1 数值类型
- 4.2 字符串类型
- 4.3 日期类型
- 五.表的操作
-
- 5.1 创建表
- 5.2 查看有哪些表
- 5.3 查看表结构
- 5.4 删除表
- 5.5 创建数据库表
一. 数据库介绍
1.1 什么是数据库
和我们表面所见一样,顾名思义就是用来储存数据的
存储数据用文件就可以了,为什么还要弄个数据库?
文件保存数据有以下几个缺点:
- 文件的安全性问题
- 文件不利于数据查询和管理
- 文件不利于存储海量数据
- 文件在程序中控制不方便
为了解决上述问题,专家们设计出更加利于管理数据的软件——数据库,它能更有效的管理数据。数据库可以提供远程服务,即通过远程连接来使用数据库,因此也称为数据库服务器。
1.2 数据库分类
数据库大体可以分为 关系型数据库 和 非关系型数据库
-
关系型数据库(RDBMS):
是指采用了关系模型来组织数据的数据库。 简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。
基于标准的SQL,只是内部一些实现有区别。常用的关系型数据库如:
1.Oracle:甲骨文产品,适合大型项目,适用于做复杂的业务逻辑,如ERP、OA等企业信息系统。收费。,世界上最强数据库,对数据安全性要求极高且收费高
2.MySQL:属于甲骨文,不适合做复杂的业务。开源免费,所以广受欢迎。
3.SQL Server:微软的产品,安装部署在windows server上,适用于中大型项目。收费。
典型特征:使用 " 数据表 " 的格式来组织数据的
-
非关系型数据库:
(了解)不规定基于SQL实现。现在更多是指NoSQL数据库,如:
1.基于键值对(Key-Value):如 memcached、redis
2.基于文档型:如 mongodb
3.基于列族:如 hbase
4.基于图型:如 neo4j
所以Nosql是不用数据表来组织数据的
关系型数据库与非关系型数据库的 区别:
| 关系型数据库 | 非关系型数据库 |
|---|---|
| 是使用SQL | 不强制要求,一般不基于SQL实现 |
| 支持事务支持 | 不支持事务支持 |
| 支持复杂操作 | 不支持复杂操作 |
| 海量读写操作效率低 | 海量读写操作效率高 |
| 基本结构基于表和列,结构固定 | 基本结构灵活性比较高 |
| 使用场景在业务方面的OLTP系统 | 使用场景在用于数据的缓存、或基于统计分析的OLAP系统 |
注:OLTP(On-Line Transaction Processing)是指联机事务处理,OLAP(On-Line AnalyticalProcessing)是指联机分析处理。
二. MySQL的结构
2.1 MySQL服务器和客户端
MySQL是一个 ” 客户端 - 服务器 “ 结构的程序
- 客户端:主动的一方就是客户端
- 服务器:被动的一方就是服务器
一个服务器可能同一时刻要给多个客户端提供服务
例如我们生活中的例子:
我们去餐厅就餐,我们要求老板来一份青椒炒肉丝盖浇饭,没一会儿,老板就端上来了一碗香喷喷的盖浇饭
此时我们就可以把这一事件的性质代入到数据库中:
客户端给服务器发送的数据,称为 ” 请求 “(来一份青椒炒肉丝盖浇饭)
服务器给客户端返回的数据,称为 “ 相应 ”(端上来了一碗香喷喷的盖浇饭)
咱们安装的MySQL是既带有客户端,也带有服务器
MySQL客户端(默认自带命令行客户端):
除此之外,还有一些第三方客户端(有些是带图形化界面的)
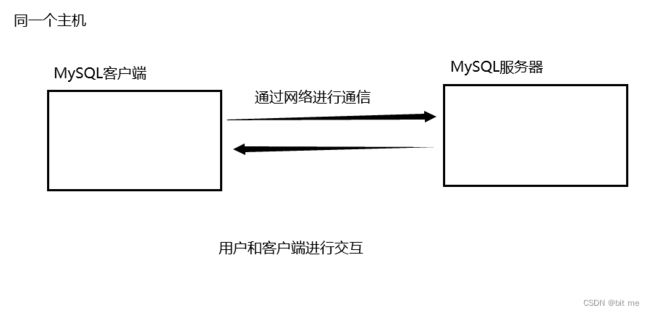
MySQL客户端和MySQL服务器可以在同一个主机上,也可以在不同的主机上。
在实际工作中更常见的是客户端和服务器在不同的主机上,而我们学习中客户端和服务器更多的是在同一个主机上(虽然是同一个主机,但是仍然是通过网络进行通信的)
对于MySQL来说,储存和管理数据都是由MySQL服务器来负责的!!
因此MySQL服务器要比MySQL客户端复杂很多,甚至可以认为MySQL服务器就是MySQL的本体,大部分时候谈及MySQL就是代指了MySQL服务器
2.2 MySQL服务器是如何组织数据的
一个MySQL服务器可以包含多个 " 数据库 " ,此处的 " 数据库 " 其实是 " 数据集合 ",这里面就放了一些具有关联关系的数据
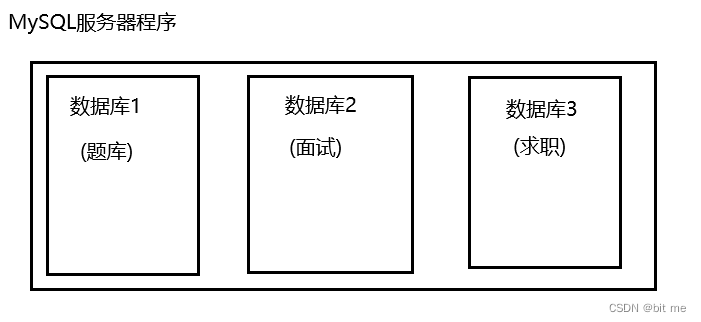
例如我们牛客网为例:
题库:各种公司往年真题,在线编程,专项练习
面试:各种工程师面经以及详细题目汇总
求职:校招,社招,实习生的招聘
以上的这些项目都没必要每个数据都安排一个主机,一个主机,一个MySQL服务器就可以管理起来,但是为了不让这些数据相互影响,因此逻辑上分开了,也就放到不同的数据库里了
每个数据库(数据集合)里面有很多数据表
例如题库表:通过率,排行榜…
一个表里有很多行,每一行称为 " 一条记录 "
每一行也有很多列,每个列表示不同的含义,每一列,也称为一个" 字段 " (field)
所以综合就是:数据库 --> 数据表 – > 行 --> 列
不仅是MySQL这样组织数据,只要是关系型数据库,都是按照上述的结构来组织数据的
三. 数据库的操作
3.1 创建数据库
create database 数据库名;
示例:
- 创建名为java的数据库

当我们看到如上就是数据库创建成功了
会有很多人疑问0.00 sec是什么
sec ==》 second 秒
表示时间的,也反应了计算机的操作效率,换句话说为什么会有非关系型数据库的存在呢?因为非关系型数据库约束更少,效率更高,也更适合于当下流行的 " 分布式系统 "
注意:
- create,database都是SQL中的关键字,不能拼写错误了,单词中间有空格(一个或者多个都行,一般是一个)
- 关键词不区分大小写
- 末尾分号不要遗忘,是英文分号
说明:当我们创建数据库没有指定字符集和校验规则时,系统使用默认字符集:utf8,校验规则是:utf8_ general_ ci
字符集描述了储存的数据都支持啥样的字符,校验规则就描述了当前字符之间该如何进行比较(比较字符串大小,相等关系,一般都是默认规则,很少进行手动干预)
3.2 显示当前的数据库
show databases;
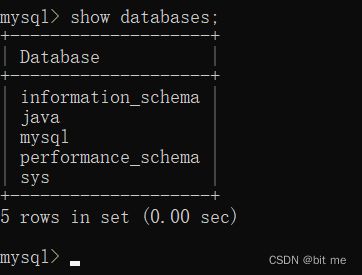
我们可以看到除了我们自己创建的数据库java,还有一些系统自带的数据库
注意:
- 此处databases是复数,输出的是很多数据库,不要忘记加s
- 打印数据库会有很多系统自带的数据库也存在
3.3 使用数据库
use 数据库名;
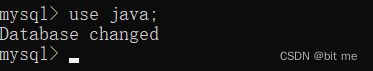
这样我们就选中数据库java完成了
3.4 删除数据库
drop database 数据库名;
示例:
- 删除名为java的数据库
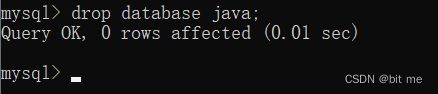
这样就完成了我们的数据库的删除,我们打印出来看看验证一下
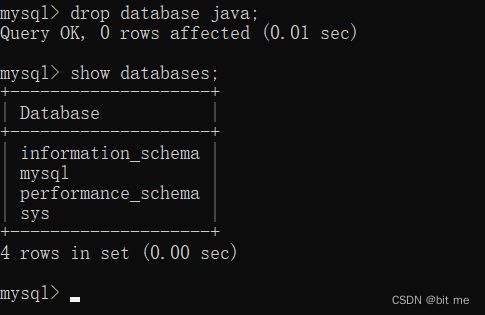
此时就可以看到java数据库确实被删除了
说明:
- 数据库删除以后,内部看不到对应的数据库,里边的表和数据全部被删除
- 千万不要随意删除数据库!!!(特别是不要在公司的生产环境服务器上进行删除)
在此处我们拓展一下关于如何避免不小心删库的带来的危害或者把损失降到最低呢?
- 权限:设置少数人有可以修改和删除数据库的权限
- 备份:把数据拷贝一份,存到另外的地方
- 硬盘数据恢复:由于MySQL是把数据存储在硬盘上,所以删除了数据库的数据,是可以在硬盘上恢复数据的
我们在这里详细讲解下如何恢复硬盘数据的:
操作系统为了方便进行管理,把整个硬盘分为了若干个 " 盘块 " ,每个盘块都可以保存一定的数据,所以实际上每个文件可能是由一个或者多个盘块上面的数据组成的
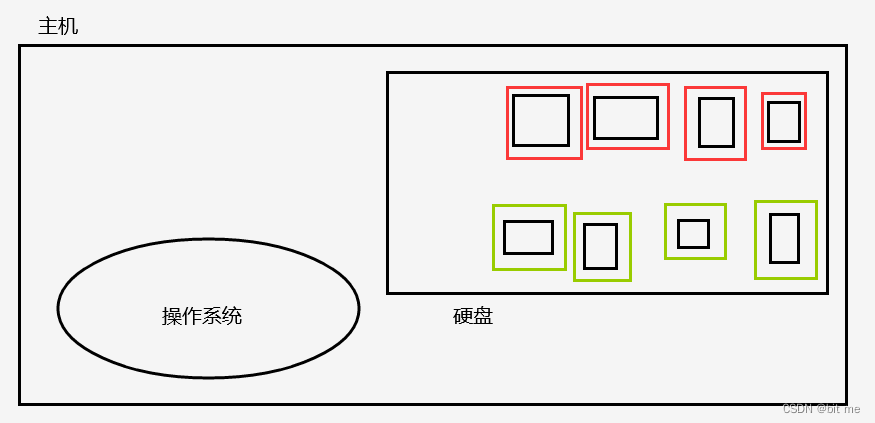
当操作系统删除文件的时候,为了提高删除动作的效率,在删除的时候并不是真的把硬盘上之前保存的数据擦除掉,而只是把该文件对应的盘块标记成 " 无效状态 ",因此一旦出现误删库的情况下,就要尽快让主机断电,就避免了操作系统把这些被标记成无效的盘块给分配出去!!!(不一定百分之百能恢复,大概率是只能恢复一部分)
四.常用数据类型
MySQL是一个关系型数据库,典型特点就是通过表的形式来组织数据的,表格的特点就是 " 特别整齐 " ,每一行,列数都是一样的,每一列,数据都是同类的(数据类型相同),数据类型一方面能够方便我们对数据进行处理,一方面也能够针对数据进行校验和检查。
4.1 数值类型
分为整型和浮点型:
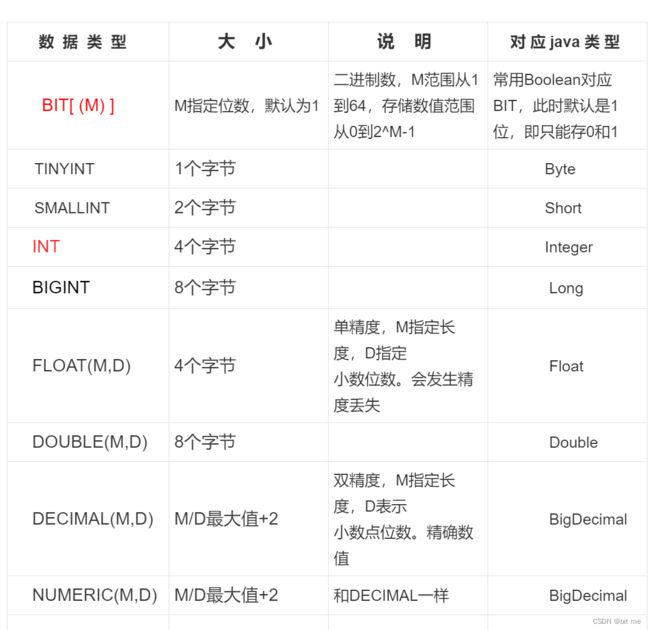
扩展:
- 数值类型可以指定为无符号(unsigned),表示不取负数。
- 1字节(bytes)= 8bit。
- 对于整型类型的范围:
1.有符号范围:-2 ^(类型字节数8-1)到2 ^(类型字节数8-1)-1,如int是4字节,就是-2 ^ 31到2 ^ 31-1
2.无符号范围:0到2 ^(类型字节数*8)-1,如int就是2 ^ 32 - 1
尽量不使用unsigned,对于int类型可能存放不下的数据,int unsigned同样可能存放不下,与其如此,还不如设计时,将int类型提升为bigint类型。
- DECIMAL相比于FLOAT和DOUBLE,可以更精确的表示小数。DECIMAL相当于通过字符串的方式来表示浮点数,优势就是能够精确表示,精确计算;但是劣势就是计算时消耗的更多,储存空间也更多。除非是特别需要,才考虑使用DECIMAL
4.2 字符串类型
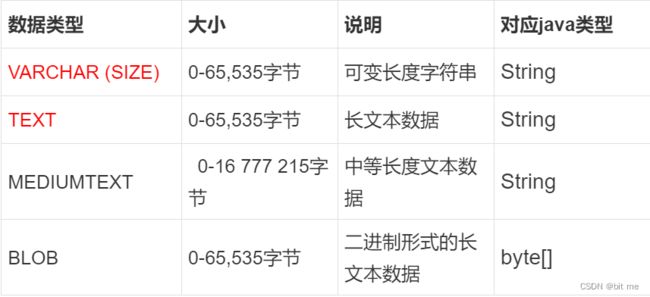
扩展:
-
VARCHAR (SIZE)是最常用的类型
例如:varchar(50),这个字段最多存50个字符(注意不是字节),也可能更短。动态的根据存入的数据长度来自适应空间。(一个字节固定为8个bit,一个字符就不是了,取决于具体的字符编码,Java中默认使用的是Unicode编码,utf8还不太一样,背后有着千丝万缕的关系) -
65535字节 – > 拓展:一个字节表示的整数:-128 => 127 --> 0 => 256 ;两个字节表示的整数:-32768 => 32767 --> 0 => 65535 ;四个字节表示的整数:-21亿 => 21亿 – > 0 =>42亿9千万
-
上面三个存储的是文本数据,BLOB存储的是二进制数据。(文本数据:里面存储的数据都是ASCLL字符,二进制数据:啥数据都有可能)
4.3 日期类型

- TIMESTAMP 时间戳:以1970年1月1日0时0分0秒作为基准时刻,计算当前时刻和基准时刻的秒数之差
- 在百度里可以搜索到时间戳,最大表示21亿,现在已达到16亿了,一旦到达极限,很多代码都会失效,不建议使用,推荐使用DATATIME

总结一下常用的类型:int , bigint , double , decimal , varchar , datetime。
五.表的操作
5.1 创建表
create table 表名(列名 类型,列名 类型…);
- 和常见的编程语言不同,SQL中列名写在前,类型写在后,C++,Java都是把类型写在前,变量名写在后,但是像Go,Python类型也是写在变量名的后面的
想要创建表,就需要先有一个数据库,并且选中之
- 我们上面已经创建了一个Java数据库,选中Java数据库即可
mysql> use java;
Database changed
- 创建一个学生表,带有id和name
mysql> create table student(id int, name varchar(20));
Query OK, 0 rows affected (0.02 sec)
创建表的时候,必须要明确表结构,也就是有哪些列,每个列是啥类型,叫啥名字
注意:
- 同一个数据库中,不能有两个表,名字相同
- 创建表的时候,表名或者列名,不能和SQL的关键字冲突,如果非要使用需要把表名用反引号`引起来
拓展:
当我们有的时候创建表语句,可能比较复杂比较长,就可以分成多行来写
mysql> create table test(
-> id int,
-> name varchar(20));
Query OK, 0 rows affected (0.01 sec)
但是体验感却不是很好,多行编辑,一旦按了回车,就再也退不回去了,例如:
mysql> create table test2(
-> id int,
-> name varchar(20),
->
我们意识到只有两个类型的时候,当开启第三个回车的时候就回不去了
解决办法:
可以在其他编辑器里把SQL写好,然后复制粘贴过来!!!
也可以是记事本,其他文本编辑器,都可以,最主要的时编写好SQL语句,再复制粘贴过来就可以

复制粘贴到我们的命令行里
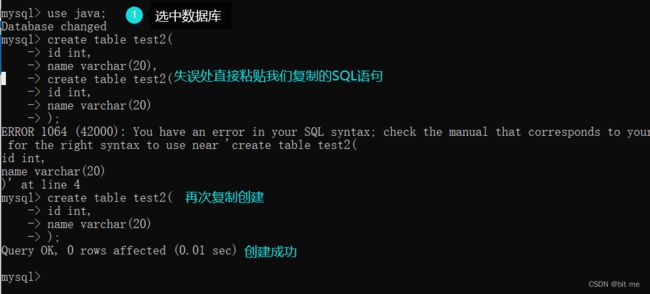
于是test2表就创建好了(其实在坏的表里加个 ; 就可以退出,上面操作其实也一样)
5.2 查看有哪些表
在选中数据库的前提下,使用show tables; 来查看当前数据库里有哪些表
mysql> show tables;
+----------------+
| Tables_in_java |
+----------------+
| student |
| test |
| test2 |
+----------------+
3 rows in set (0.00 sec)
5.3 查看表结构
desc 表名;
查看这个表里面的列和类型
mysql> desc student;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int(11) | YES | | NULL | |
| name | varchar(20) | YES | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.00 sec)
- 每一列都是都是一个字段,Field,表示表这里有几列
- int(11)的意思不是占11个bit位,int就是固定4个字节,占32个比特位,11表示的是打印数字的时候,显示数据的最大宽度是11位数,11只是影响在客户端中的显示,不影响数据的最大储存和计算
- varchar(20)约束存储的时候最多存20个字符
- Null表示这一列是否可以为空(不填,选填项)
- Key后期再提及
- Default是默认值,此处的Null就是说,默认的默认值是Null(不填),也能手动修改默认值
- Extra额外的默认值,后面再详解
5.4 删除表
drop table;
实例操作:
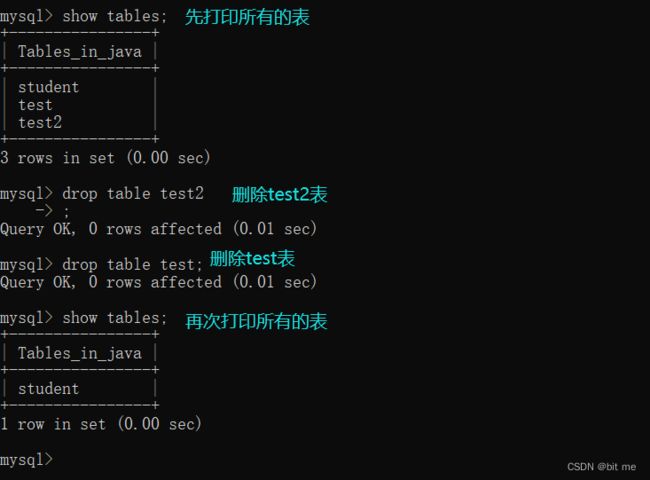
先打印存在的所有的表,然后分别删除test2,test,就可以看到最后打印确实没有,被删除了
注意:
- 删表操作非常危险!!!危害比删库,只多不少!!!
- 表面上看,一个库里包含很多表,删库,就会直接把所有的表都带走(如果真的删库了,程序在运行的时候只要涉及到数据库操作,100%报错!!!第一时间就可以发现问题,但是如果是删表,100个表,删了其中的1个表,此时程序运行的时候,可就不一定第一时间报错了!!!很可能程序"带伤运行",虽然程序能跑,但是结果是错的,它的问题不能第一时间暴露出来)
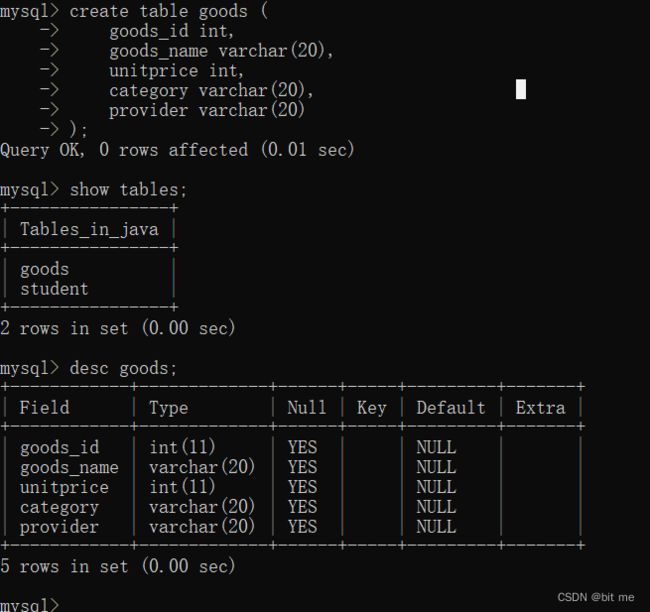
5.5 创建数据库表
创建商品goods,赋予一些属性(商品编号,名称,单价的单位是分,分类,供应商名称)
mysql> create table goods (
-> goods_id int,
-> goods_name varchar(20),
-> unitprice int,
-> category varchar(20),
-> provider varchar(20)
-> );
括号里的数字,我们处于学习阶段就可以随便写,够用就可以
在实际的开发中是要根据产品需求来确定的
表的建立和查询: