Hadoop完全分布式搭建
目录
1. 以master为原型复制虚拟机slave1,slave2,并更改主机名和IP地址
2. 关闭防火墙和防火墙自启动
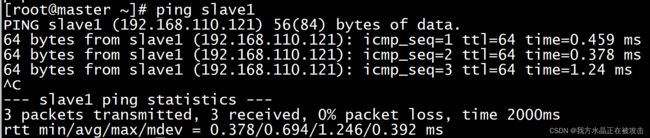
3. 通过 vi /etc/hosts添加映射,确保虚拟机集群之间可以互相ping通
4. 虚拟机各节点实现时间同步
5. 修改各节点hadoop配置文件
6.在 master 节点上修改/simple/hadoop-2.7.7/etc/hadoop/masters,
7.在 master 节点上修改/simple/hadoop-2.7.7/etc/hadoop/slaves,
8.将 master 节点 hadoop 文件分发给数据节点 hadoop 文件,
9.将 master 节点 JDK 文件分发给数据节点 JDK 文件
10.将主节点 master 的环境变量文件分发给 slave1、slave2
11.在 slave1、slave2 节点激活环境变量文件
12.在 master 节点执行格式化 NameNode。
1. 以master为原型复制虚拟机slave1,slave2,并更改主机名和IP地址
更改ip地址和主机名参考上一篇hadoop伪分布搭建
2. 关闭防火墙和防火墙自启动
systeemctl stop firewalld.service
systemctl disable firewalld.service3. 通过 vi /etc/hosts添加映射,确保虚拟机集群之间可以互相ping通

4. 虚拟机各节点实现时间同步
1.在所有的节点上修改配置文件:vi /etc/sysconfig/ntpd(修改如下图所示)
2.使用命令启动时间同步服务:systemctl start ntpd
3. 查看时间同步 date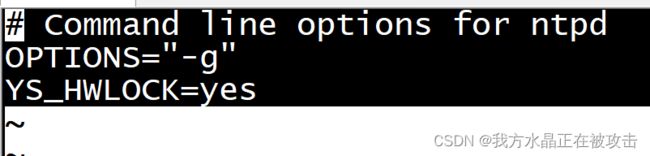
5. 修改各节点hadoop配置文件
1.修改core-site.xml
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
/simple/hadoop-2.7.7/tmp
2.修改hadoop-env.sh
export JAVA_HOME=/usr/local/src/java
export HADOOP_PERFIX=/usr/local/src/hadoop
export
HADOOP_OPTS="-Djava.library.path=$HADOOP_PERFIX/lib:$HADOOP_PERFIX/lib/natice"3.修改hdfs-site.xml
dfs.namenode.name.dir
file:/simple/hadoop-2.7.7/hdfs/name
dfs.datanode.data.dir
file:/simple/hadoop-2.7.7/hdfs/data
dfs.replication
3
4.修改mapred-site.xml
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
master:10020
mapreduce.jobhistory.webapp.address
master:19888
5.修改yarn-site.xml
yarn.resourcemanager.address
master:8032
yarn.resourcemanager.scheduler.address
master:8030
yarn.resourcemanager.resource-tracker.address
master:8031
yarn.resourcemanager.admin.address
master:8033
yarn.resourcemanager.webapp.address
master:8088
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce,shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
6.在 master 节点上修改/simple/hadoop-2.7.7/etc/hadoop/masters,
vi /simple/hadoop-2.7.7/etc/hadoop/masters
master7.在 master 节点上修改/simple/hadoop-2.7.7/etc/hadoop/slaves,
vi /simple/hadoop-2.7.7/etc/hadoop/slaves
slave1
slave2 8.将 master 节点 hadoop 文件分发给数据节点 hadoop 文件,
scp -r /simple/hadoop-2.7.7/ root@slave1:/simple/
scp -r /simple/hadoop-2.7.7/ root@slave2:/simple/9.将 master 节点 JDK 文件分发给数据节点 JDK 文件
scp -r /simple/jdk1.8.0_171/ root@slave1:simple/
scp -r /simple/jdk1.8.0_171/ root@slave1:simple/10.将主节点 master 的环境变量文件分发给 slave1、slave2
scp -r /etc/profile root@slave1:/etc/
scp -r /etc/profile root@slave2:/etc/11.在 slave1、slave2 节点激活环境变量文件
[root@slave1 ~]# source /etc/profile
[root@slave2 ~]# source /etc/profile12.在 master 节点执行格式化 NameNode。
(此命令在正确的情况下只能执行一遍,多次执行会造成 namenode 节点与 datanode 节点的 ID 不一致出错)
提示:出现其他进程能正常启动,datanode 也能正常启动,而 namenode 无法启动,
原因:namenode 的 clusterID 值与 datanodeclusterID 值不一样,
处理方法:由Hadoop安装目录,进入到hdfs目录,此目录中有name和data目录,在name和data目录里都有一个文件current,这两个current文件中包含了clusterID号,将name和data目录中的current 文件删除,重新对 namenode格式化,然后启动hadoop进程。
执行 cd /simple/hadoop-2.7.7/bin 执行 hdfs 格式化命令:./hdfs namenode -format
13.master 启动集群,按次序执行以下启动脚本:
start-dfs.sh
start-yarn.sh14.在 master 节点,输入 jps ,出现 SecondaryNameNode,NameNode,Jps,ResourceManager表示启动正确
15.在slave节点,输入jps,出现Jps,NodeManager,DataNode表示启动正确
16.关闭节点,在每台虚拟机上执行
stop-dfs.sh
stop-yarn.sh