语音识别入门
语音识别(Automatic Speech Recognition, ASR)
引言
语音识别: 将语音识别成文本。
微信上的语音转为文字功能。还有一些语音助手,Siri,Cortana,小度,小爱同学等等。
语音是声音的一种。声音是由振动产生的,通过空气传播到达耳朵,空气的某些地方稠密,有些稀疏,不断变化,声波到达耳朵。
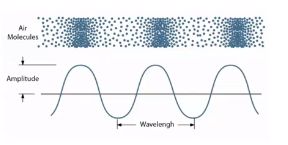
振动的快慢,就是频率。人耳能听到的频率范围:20Hz-20000Hz。
语音是种特殊的声音,为什么呢?因为它是人发出的声音,里面包含了丰富的信息。其他声音不含任何信息的叫作噪音。
语音是高度结构化的振动。总的来说,它是一种既随机,又具有极强的规律性,结构性的信号。语音是极至浓缩的信息源。内容、情感、说话人、年龄等等信息都在里面。
这是耳蜗,人耳对声音的感知原理。

基于语音的人机交互:
传统的人机交互仍有局限(只用键盘鼠标),希望实现更自由、更自然的沟通(行为,表情,语言,生理信号等)。
语音是下一代人机交互的核心(用语言传递的信息比其他方式更多)。
语音识别,是人机交互中最重要的技术之一。(包括:关键词检出、设备唤醒、语音翻译等)
语音识别
基础知识
语音信号处理基础可参考我其他博客。
把每一段时域的波形变换到频域,就得到语谱图。
如下图,上面波形,下面对应的语谱图。这是宽带语谱图,所以其中明显的黑条纹就是共振峰。

大家可以想象一下吹笛子的过程,类似人的发音过过程(准确说是萧,因为笛子两头开口,萧只有一头)。
吹笛子时,声音在笛子空腔内型形成功共鸣,使得某些频率被加强,某些频率被减弱,加强或减弱哪些频率取决于笛子的哪个孔被堵住。也即是说笛子声音的共振峰对应不同的孔,语音的共振峰对应不同的口型。口型又对应着说了什么话。
所以,共振峰代表了说了什么话。
世界上第一个ASR系统(1952年):
识别0-9的10个数字。横轴第一共振峰F1,纵轴第二共振峰F2.。

那共振峰就可以识别,ASR这件事是不是就结束了?
实际不是。还存在如下问题。一直到如今2022年,70年过去了,ASR仍然是一个很热的研究领域。

那这么多困难,一下也很难解决,我们就只关注核心困难。
主要有下面三点:

不确定性:同一个人发一个单词不一样,不同情绪,不同环境下发也不一样。比如下图两个波形都是”你们“,但完全不一样。

序列化:
1.”你们好啊“这四个字,波形上有上万个点的序列,但只对应了4个字的序列。所以怎么对齐?也算是个关键问题。
2.发音前后有相关性,语言的相关性,所以是有序性的。

知识融合:单靠波形、频谱很难识别出语音中的信息,还需要借助语言、语义信息。比如,每个字都懂,连成一句话就不懂了。
ASR早期:模式匹配方法
基于线性预测(LPC)的共振峰特征:
考虑人的发音过程,基于源-滤波模型,喉头产生的激励,通过口腔等器官的调制,产生了不同语音。那么已知语音,就用一个逆滤波产生激励,和声道信息(共振峰)。

得到共振峰后,还需要考虑两个序列的对齐:
如果模板里是比较长的发音,实际发的音比较短,就涉及对齐问题,提出了DTW算法。(详细我博客有)

总结:

ASR中期:统计模型方法
如果系统比较复杂呢,每句话都需要一个模板,需要很多个模板,模板匹配方法就不现实了。所以把模板就总结成了一个统计模型。这样就到80年代。
特征:
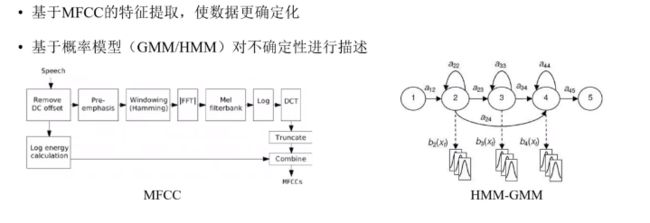
也提出了更复杂的特征,MFCC(详细见我其他博客)。
根据人耳对不同频率的听觉感知,设计了梅尔滤波器组。

MFCC:更具有分区性的特征。
可以看到,对不同的音,MFCC取出其中三维,画出图,该特征对不同音具有很强的区分性。
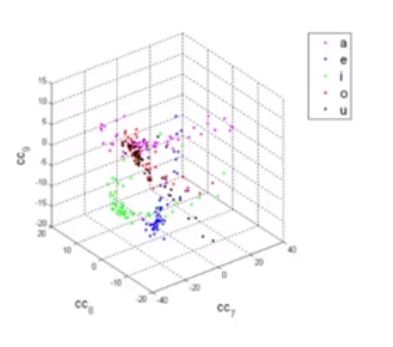
但对狗叫声、猫叫声、男的女的声进行MFCC特征提取,发现该特征在空间中一片混乱,说明它对发音的特性不敏感,只对发音内容相关。

模型:
用概率模型描述语音生成过程的不确定性。
最经典的GMM-HMM模型。
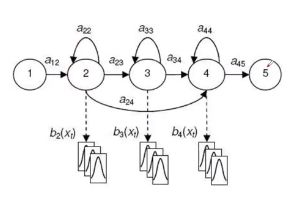
- 隐马尔可夫模型HMM:描述不定长序列
将发音过程描述成状态,小圈代表开头和结尾状态。每个状态有一定概率停留,也有一定概率变到下一个状态,所以就可以表示各种长度的序列(太长的序列,大不了在某个状态多停留会)
- 高斯混合模型GMM:描述不确定性
多个高斯模型混在一起,就能描述非常复杂的分布。

利用HMM + GMM 模型,先描述再推理。
每个音在发音空间的分布都可用一个GMM描述。
- 语言模型:引入语言信息


N-gram语言模型:
常见的比如,在搜索引擎里输入“我们”,就会出现下面的可能的搜索。


一般来说语言模型不限形式。最简单的方式,把一个句子分解,就是看每个词在大的语料库中所占比例。但如果句子很长,就很难,所以就拆解成片段。这就是N-gram模型。
N = 2,或3等等。N=2如:已知两个字,推下两个字。
N-gram是一个生成模型,可以从无到有的生成文字段落等。
理论基础确立:
A是语音,W是文本。求P(W|A),根据贝叶斯公式,就等价于求如下:如果声学模型P(A|W)和语言模型P(W)都是精确的,那么基于该公式得到的结果就是最优的。

此时可以识别连续的句子了,而不是孤立词了。
词典:知道一个词是由哪些音素组成的。
上下文规则:和上下文相关的发音(音素状态)。

这种方式写系统太复杂,出现了如下方法:
把之前的映射变成有限状态转移机的结构。

现代ASR的解码过程本质是一个搜索过程:给定一段语音,在所有可能的句子里找到和该语音最匹配的句子。

这样ASR过程就简化了很多。
总结:

这个阶段ASR表面看好像发展的很好了,实际还存在几个问题:

细想想,一切都很肤浅…
所以2011年深度学习引入了语音识别。
ASR当前:深度学习方法
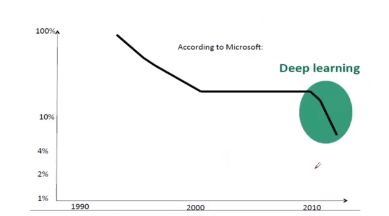
可以看到下图,纵轴是错误率,横轴是年份,随着技术的发展,2010年后ASR系统的错误率越来越低,甚至低于人类(人识别错误率在5%左右)
回顾问题一:不确定性
但随着深度学习的发展,人们发现DNN提取的声学特征(鲁棒性)具有更强的任务相关性,更宽的上下文(原来只是一帧或上下几帧),层次学习获得更强的抽象性和不变性(即使加入噪音,提取的特征也不会受影响,因为抽象所以不易变)。
之前人工设计的特征只是人们拍脑袋想出来的,性能好坏不好说,可扩展性不好。

用DNN代替了GMM计算似然值。
下面是GMM的一个音素的分布,GMM易混淆,区分性不强。

所以用DNN后验概率代替GMM计算似然值。2011-2014年,流行的是混合hybrid=HMM+DNN模型。

回顾问题二:序列识别问题
hybrid模型未解决序列问题,还是在用HMM离散建模。等2014后,提出了RNN模型解决序列不定长问题。
RNN优点:

解读:
- 状态连续:更好的描述语音信号连续的变化过程。
- 时序累积性:一个输入和下一个输入相关,前后相关。
- 端到端:不仅学习了帧之间声学相关性,还学习了长时的语言模型需要的相关性。
目前经典的两种RNN序列模型:
- CTC:引入空字符实现不定长匹配(HMM只是在某个状态进行不定时长的循环)
- Seq2seq+attention:模型内部学习对齐过程。
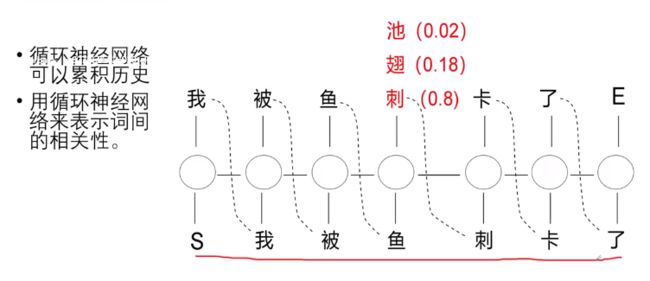
回顾问题三:引入语言信息
“我被鱼”已经累积到状态里了,来预测下一个字。
总结:

深度学习语音识别发展历程
随着深度学习技术的发展从 2012 年开始,语音识别技术经历了革命性的变化,基本可概括为三个阶段:
- 基于 DNN-HMM(深度神经网络 - 隐马尔科夫模型)的语音识别
- 基于 CTC(连接时序分类)的端到端语音识别
- 基于 Attention 的端到端语音识别
首先从 HMM+DNN 系统升级到 HMM+CNN/LSTM 系统,再升级到后来的 CTC 系统,近两年则逐渐转为基于 Transformer 的纯端到端系统。
与传统的 DNN-HMM 混合模型相比,端到端语音识别系统指的是,省略掉了 GMM-HMM 系统得到对齐信息和上下文相关音素的步骤,无需多次迭代,直接从神经网络开始训练。主要包括连接时序分类(CTC)模型、递归神经网络转换器(RNN-T)模型、基于注意力机制的序列到序列(Attention based Seq2Seq)模型。传统与端到端算法对比:
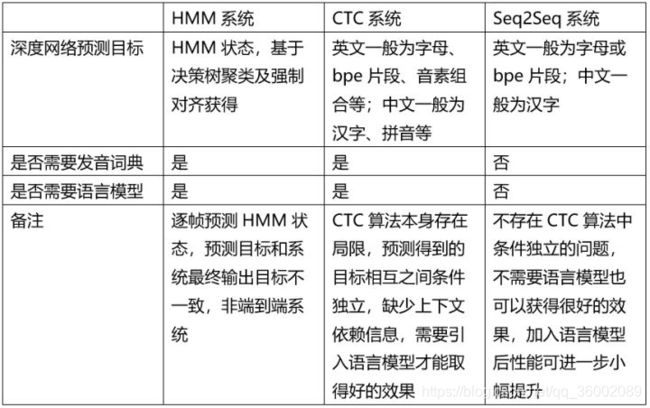
问题:
1.端到端技术的好处?
传统语音算法在不同语种识别基础建模单元上,语言学信息是不一样的,如汉语是基于拼音的声母韵母、英语则是英文的音素,这种技术架构对指定语种的语言学知识依赖较大,也难以扩展到多语种识别。端到端技术用统一的网络进行建模,尽量减少语种相关的发音词典编辑、建模单元选择等工作,基于数据驱动而非语言学信息来构建系统,这样后续成果也可以快速迁移到其他语言上。
2.端到端技术的局限?
由于是纯数据驱动,端到端语音识别系统没有充分利用到先验的各种语言学知识,在实际使用场景下想要达到比较好的效果,相比于传统算法需要更多的标注数据来做模型训练,虽然系统构建简化了但数据收集难度上升了;而且和其它深度学习系统类似,模型的可解释性不高,错误样例的分析与优化难度大;此外,目前的端到端技术都是序列到序列的映射,缺少传统系统中逐帧分类的信息,因此对于一些需要非常精确的时间对齐信息的场景并不适用。
3.目前较新端到端模型Transformer
在端到端这个技术体系内,对于语音识别这种序列到序列(Seq2Seq)问题,参考机器翻译的经验以及业界最近的论文成果,Transformer 网络结构相比其它结构有更好的性能。采用基于注意力(Attention)机制的 Transformer 网络结构,并做了各种细节优化,如引入多任务学习机制(Multi-Task Learning),在编码端加入 CTC 损失函数,加速模型收敛,同时在解码时利用 CTC 得分避免 Attention 错误;在解码端引入逐字的语种分类任务,加强模型对语种的区分能力。
当前主流网络
声学模型:
当前主流的深度学习语音识别系统中用于声学模型建模的神经网络的结构主要有三种:
-
递归神经网络(Recursive neural network, RNN)
核心思想是同一层中当前时刻的隐层输出的计算需要依赖于上一时刻的隐层输出。
简单的递归神经网络由于梯度消失的问题,能够看到的历史信息十分有限,通常经过十几次的递归之后梯度就消失为零了。因此,目前主流的递归神经网络通常都带有门控结构,保证梯度在递归的过程中不会那么快的消失,其中比较典型的结构是长短时记忆模型和门控循环单元GRU结构。 -
卷积神经网络(Convolutional neural network, CNN)
核心思想在于卷积和池化两个操作。
卷积操作的连接方式是局部连接,因此可以获取对于局部结构信息的精确表达,而池化操作则通过降低分辨率的方式,配合卷积操作克服局部信息本身不够稳定的问题。通过对语谱图不断的进行卷积和池化操作,卷积神经网络看到的语音特征时间和频域上的跨度不断增加,整个神经网络建模的尺度也逐渐的从局部变为整体。这种从局部到整体的建模方式可以对语音特征中谐波、共振峰等信息进行非常精确的建模,从而提升音素状态的区分性。
当然也可以结合这两种,通过级联或并联,如2015年的CLDNN。
- Transformer神经网络
核心思想在于使用了一种自注意力机制代替卷积或者递归操作来实现对长时上下文的建模,通过不断叠加前馈层和自注意力层,不断的增强对长时上下文的表达。
由于采用了一种基于内容的相似性度量来表示相邻帧之间的相关性,自注意力机制对于窗口内的所有语音巾贞都是一视同仁的,不存在递归神经网络的梯度消失问题,相比之下能够看到更加长时的上下文信息。相比卷积神经网络,自注意力机制中相邻帧之间的连接权重不是一个固定的参数,而是通过内积的方式计算得到的,从而能够大幅减少参数量,使得模型更加的紧致。

语言模型:(两种)
-
N-gram语言模型:基于N阶马尔科夫假设,认为当前词出现的概率只和前面历史的N-1个词相关。
-
神经网络语言模型
早期是前馈神经网络结构。当前主流是RNN语言模型。
实际应用中,对于高频的、常用的词或者词串来说,N-gram的概率会更加的可信,而对于相对生僻的词串来说,神经网络语言模型的输出概率会更加可信,因此,我们会同时使用这两种语言模型。为了减少计算量,通常会采用两遍解码的策略,先利用N-gram语言模型解码得到多条候选识别结果(N-best),然后再利用神经网络语言模型和N-gram语言模型的平均输出概率来对N-best进行重排序。
研究前沿

- 目标标注数据较少,所以引入自监督。SOTA。
- 不同的语音任务,不同的语音信息在统一空间表示。
- TTS和ASR结合等
那基于深度学习的ASR存在哪些问题呢?

- 比如1万条数据,其中大多数数据都是常见数据,少见数据的比例很低,所以训出的模型对常见数据擅长,对少见数据不好处理,这就是统计偏置问题。
- ASR怎么解码出来的文本具体处理过目前还不清楚。
- 模型对不同人群有不同表现,是否会受黑客攻击之类的。