剪枝论文一(Network Slimming)
本文介绍一种经典的模型压缩方法Network Slimming,可以实现:
- 减小模型大小
- 减少运行时的内存占用
- 在不影响精度的同时,降低计算操作数
论文中提供的示意图如下,可以看到左侧BN层中橙色的神经元权重较小,因此剪枝之后就去掉了这些层的连接。论文的思路即通过去掉BN层中权重较小的神经元来达到精简网络的目的。
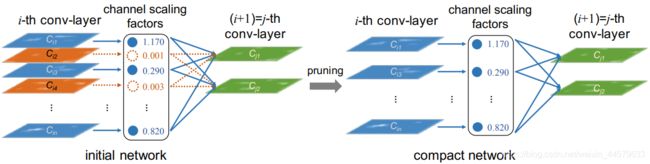
实现去掉权重较小的神经元的流程如下:
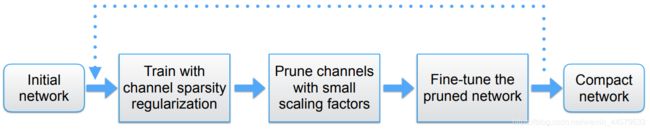
1. sparsity regularization
论文提出,在训练的时候增加稀疏正则化方法。
主要作用:令BN层中权值为0的神经元尽可能多,以达到更好的剪枝效果。
实现方式:添加一个新的loss,其大小为BN层中所有神经元的权值和,使用梯度下降法使这个新的loss尽可能小。
# sparsity-induced惩罚项的附加次梯度下降
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1
2. 划分保留层和剪枝层
步骤为:
- 给定要保留层的比例,记下所有
BN层大于该比例的权重。 - 根据比例设置阈值,根据阈值建立一个
mask,大于阈值的部分为1,小于阈值的部分为0。 - 利用
mask提取保留的神经元。
# 将这些权重排序
y, i = torch.sort(bn) # 这些权重排序
thre_index = int(total * args.percent) # 要保留的数量
thre = y[thre_index] # 最小的权重值
# ===================================预剪枝====================================
pruned = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.abs().clone()
# 小于权重thre的为0,大于的为1,即保留的部分
mask = weight_copy.gt(thre).float().cuda()
# 统计被剪枝的权重的总数
pruned = pruned + mask.shape[0] - torch.sum(mask)
# 权重和偏置分别对应相乘
m.weight.data.mul_(mask)
m.bias.data.mul_(mask)
# 记录每个batchnorm保留的权重和权重数
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
3. 进行BN层的剪枝
进行BN层的剪枝,即丢弃小于阈值的参数;
# ===================================正式剪枝====================================
# 层数
layer_id_in_cfg = 0
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg]
for [m0, m1] in zip(model.modules(), newmodel.modules()):
# 对BN层进行剪枝
if isinstance(m0, nn.BatchNorm2d):
# 获取大于0的所有数据的索引,使用squeeze变成向量
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
if idx1.size == 1: # 只有一个要变成数组的1个
idx1 = np.resize(idx1,(1,))
# 用经过剪枝后的层参数的替换原来的
# x = (x - mean)/war*weight + data
m1.weight.data = m0.weight.data[idx1.tolist()].clone()
m1.bias.data = m0.bias.data[idx1.tolist()].clone()
m1.running_mean = m0.running_mean[idx1.tolist()].clone()
m1.running_var = m0.running_var[idx1.tolist()].clone()
# 下一层
layer_id_in_cfg += 1
# 当前在处理的层的mask
start_mask = end_mask.clone()
# 全连接层不做处理
if layer_id_in_cfg < len(cfg_mask):
end_mask = cfg_mask[layer_id_in_cfg]
4. 进行卷积层剪枝
根据前后BN层的保留层,可以计算得到卷积层保留的卷积核大小(上层BN层输出,下层BN层输入),保留前后BN的对应保留的元素,其余剪枝。
# 对卷积层进行剪枝
elif isinstance(m0, nn.Conv2d):
# 上一层BN层对应的输出mask为start_mask
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
# 下一层BN层对应的输入mask为start_mask
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d}, Out shape {:d}.'.format(idx0.size, idx1.size))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
if idx1.size == 1:
idx1 = np.resize(idx1, (1,))
# 剪枝
[c_out, c_int, k, k]
w1 = m0.weight.data[:, idx0.tolist(), :, :].clone()
w1 = w1[idx1.tolist(), :, :, :].clone()
m1.weight.data = w1.clone()
5. 对FC层进行剪枝
由于FC层的输出是固定的(分类类数),因此只对FC层的输入维度进行剪枝,也是根据上一层BN层的输出,对应保留的元素,其余剪枝。
# 对全连接层进行剪枝
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
# 剪枝
m1.weight.data = m0.weight.data[:, idx0].clone()
m1.bias.data = m0.bias.data.clone()
源代码