SuperGlue Learning Feature Matching with Graph Neural Networks
SuperGlue:使用图神经网络学习特征匹配
摘要
本文介绍了 SuperGlue,一种神经网络,通过联合寻找对应关系并拒绝不可匹配的点来匹配两组局部特征。分配是通过求解一个可微的最优值来估计的运输问题,其成本由图形预测
神经网络。我们引入了灵活的上下文聚合基于注意力的机制,使 SuperGlue 能够推理底层 3D 场景和特征分配共同。与传统的、手工设计的启发式方法相比,我们的技术通过端到端学习了几何变换和 3D 世界的规律性的先验从图像对训练。 SuperGlue 优于其他学习方法并取得最先进的结果在具有挑战性的真实室内和室外环境中进行姿态估计的任务。所提出的方法在现代 GPU 上实时执行匹配,并且可以很容易集成到现代 SfM 或 SLAM 系统中。代码和训练过的权重可在以下网址公开获得: github.com/magicleap/SuperGluePretrainedNetwork
一、简介
图像中点之间的对应关系是必不可少的用于估计几何计算机视觉任务中的 3D 结构和相机姿态,例如同步定位和映射(SLAM)和结构化运动(SfM)。 这种对应关系通常由匹配局部特征,这个过程称为数据关联。大视点和光照变化、遮挡、模糊、和缺乏纹理是使 2D 到 2D 数据关联特别具有挑战性的因素。
图像中点之间的对应关系对于估计几何计算机视觉任务中的3D结构和相机姿势至关重要,例如同步定位与建图(SLAM)和三维重建 (SfM)。这种对应关系通常是通过匹配局部特征来估计的,这一过程称为数据关联。大的视点和光照变化、遮挡、模糊和缺乏纹理是使 2D 到 2D 数据关联特别具有挑战性的因素。
在本文中,我们提出了一种新的思考方式特征匹配问题。 我们简单的学习启发式和技巧,而不是学习更好的与任务无关的局部特征。我们使用新颖的神经架构从预先存在的局部特征中提取有目的的去学习匹配的过程使用称为SuperGlue。在 SLAM 的背景下,通常[8]将问题分解为视觉特征提取前端和束调整或姿势估计后端,我们的网络直接位于中间–SuperGlue是一个可学习的中端(见图1)。
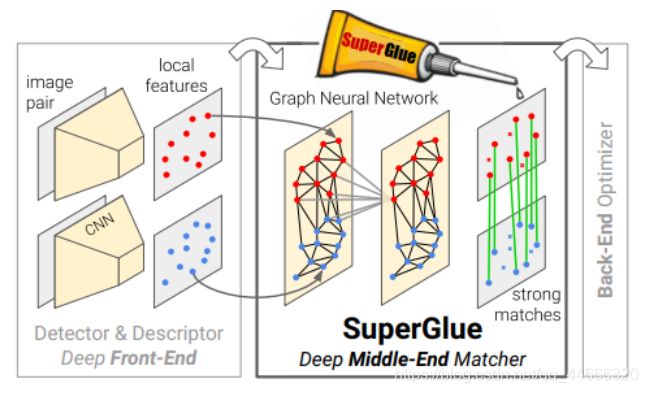
图 1:使用 SuperGlue进行特征匹配。我们的方法从当前的局部特征建立逐点对应关系:它充当人工或学习的前端和后端之间的中间端。SuperGlue使用图神经网络和注意力来解决分配优化问题,并处理部分点可见性并优雅地遮挡,产生部分分配。
在这项工作中,学习特征匹配被视为找到本地特征分配特征之间的部分分配。
目前深度学习在SLAM的应用中,有明显对立的两派,一派主张学习特征和描述子,另一派主张直接端到端学习位姿。
我们先介绍下SuperPoint的整体思路。
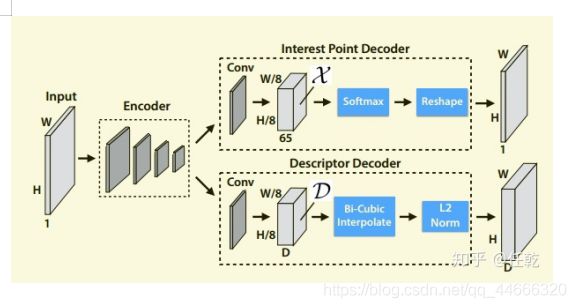
本文一共设计了两个网络,一个是BaseDetector,用于检测角点(注意,此处提取的并不是最终输出的特征点,可以理解为候选的特征点),另一个是SuperPoint网络,输出特征点和描述子。
网络的训练共分为三个步骤:
1)第一步是采用虚拟的三维物体作为数据集,训练网络去提取角点;
2)使用真实场景图片,用第一步训练出来的网络提取角点,这一步称作兴趣点自标注(Interest Point Self-Labeling);
3)对第二步使用的图片进行几何变换得到新的图片,这样就有了已知位姿关系的图片对,把这两张图片输入网络,提取特征点和描述子。
SuperPoint网络是作者在本篇文章中提出的,给了较为详细的介绍,网络的结构如下图:
摘要
本文提出了一种能够同时进行特征匹配以及滤除外点的网络。其中特征匹配是通过求解可微分最优化转移问题( optimal transport problem)来解决,损失函数由GNN来构建;本文基于注意力机制提出了一种灵活的内容聚合机制,这使得SuperGlue能够同时感知潜在的3D场景以及进行特征匹配。该算法与传统的,手工设计的特征相比,能够在室内外环境中位姿估计任务中取得最好的结果,该网络能够在GPU上达到实时,预期能够集成到sfm以及slam算法中。
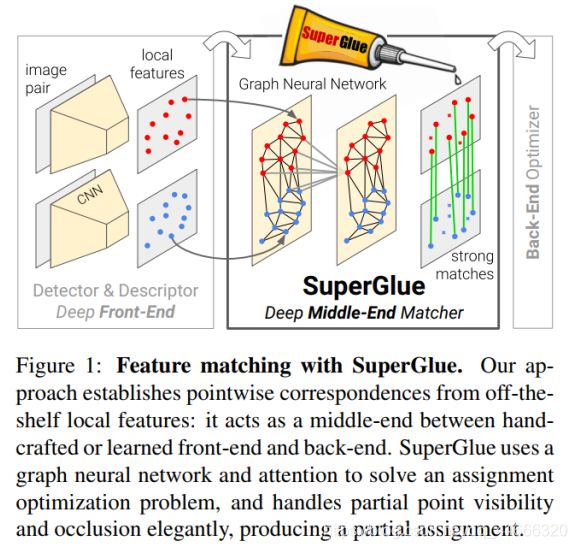
SuperGlue是一种特征匹配网络,它的输入是2张图像中特征点以及描述子(手工特征或者深度学习特征均可),输出是图像特征之间的匹配关系。
作者认为学习特征匹配可以被视为找到两簇点的局部分配关系。作者受到了Transformer的启发,同时将self-和cross-attention利用特征点位置以及其视觉外观进行匹配。
相关工作
局部特征匹配
传统的特征可分5步走:1)提取特征点;2)计算描述子;3)最近邻匹配;4)滤除外点;5)求解几何约束;其中滤除外点一步包括点方法有:计算最优次优比,RANSAC,交叉验证以及neighborhood consensus。
最近的一些工作主要集中在设计特异性更好的稀疏特征上,而它们的匹配算法仍然依赖于NN等策略:在做匹配时并没有考虑特征的结构相似性以及外观相似性。
图匹配
这类方法将特征的匹配问题描述成“二次分配问题(quadratic assignment problems)”,这是一个NP-hard问题,求解这类问题需要复杂不切实际的算子。后来的研究者将这个问题化简成“线性分配问题(linear assignment problems)”,但仅仅用了一个浅层模型,相比之下SuperGlue利用深度神经网络构建了一种合适的代价进行求解。此处需要说明的是图匹配问题可以认为是一种“最佳运输(optimal transport)”问题,它是一种有效但简单的近似解的广义线性分配,即Sinkhorn算法。
深度点云匹配
点云匹配的目的是通过在元素之间聚集信息来设计置换等价或不变函数。一些算法同等的对待这些元素,还有一些算法主要关注于元素的局部坐标或者特征空间。注意力机制可以通过关注特定的元素和属性来实现全局以及依赖于数据的局部聚合,因而更加全面和灵活。SuperGlue借鉴了这种注意力机制。
框架以及原理
特征匹配必须满足的硬性要求是:i)至多有1个匹配点;ii)有些点由于遮挡等原因并没有匹配点。一个成熟的特征匹配模型应该做到:既能够找到特征之间的正确匹配,又可以鉴别错误匹配。
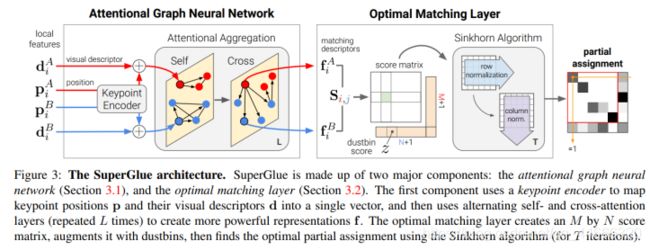
整个框架由两个主要模块组成:注意力GNN以及最优匹配层。其中注意力GNN将特征点以及描述子编码成为一个向量(该向量可以理解为特征匹配向量),随后利用自我注意力以及交叉注意力来回增强(重复L次)这个向量f的特征匹配性能;随后进入最优匹配层,通过计算特征匹配向量的内积得到匹配度得分矩阵,然后通过Sinkhorn算法(迭代T次)解算出最优特征分配矩阵。
公式化
该部分对特征匹配问题建模。给定两张图片A,B,每张图片上都有特征点位置p以及对应的描述子d,所以我们经常用(p,d)来表示图像特征。第i个特征可以表示为pi:=(x,y,c),其中c表示特征点提取置信度,(x,y)表示特征坐标;描述子可以表示为di∈RD,其中D表示特征维度,这里的特征可以是CNN特征,如SuperPoint,或者是传统特征SIFT。假设图像A,B分别有M,N个特征,可以表示为A:={1,…,M}以及B:={1,…,N}。
部分分配矩阵:约束i)和ii)意味着对应关系来自两组关键点之间的部分分配。我们给出一个软分配矩阵P∈[0,1]M×N,根据上述约束,我们有如下关系:
P1N≤1M and P⊤1M≤1N
那我们设计网络的目标就是解算这个分配矩阵P。
注意力GNN
这里有个有意思的说法:特征点的位置以及视觉外观能够提高其特异性。另外一个具有启发性的观点是人类在寻找匹配点过程是具有参考价值的。想一下人类是怎样进行特征匹配的,人类通过来回浏览两个图像试探性筛选匹配关键点,并进行来回检查(如果不是匹配的特征,观察一下周围有没有匹配的更好的点,直到找到匹配点/或没有匹配)。上述过程人们通过主动寻找上下文来增加特征点特异性,这样可以排除一些具有奇异性的匹配。本文的核心就是利用基于注意力机制的GNN实现上述过程,即模拟了人类进行特征匹配。
特征点Encode
首先根据上述说法,特征点位置+描述会获得更强的特征匹配特异性,所以这里将特征点的位置以及描述子合并成每个特征点ii的初始表示(0)xi(0)xi,
(0)xi=di+MLPenc(Pi)
其中MLP表示多层感知机(Multilayer Perceptron ,MLP)此处用于对低维特征升维,上式实际上是将视觉外观以及特征点位置进行了耦合,正因如此,这使得该Encode形式使得后续的注意力机制能够充分考虑到特征的外观以及位置相似度。
下图展示了每层self-attention以及across-attention中权重αij的结果。按照匹配从难到易,文中画出了3个不同的特征点作为演示,绿色特征点(容易),蓝色特征点(中等)以及红色特征点(困难)。对于self-attention,初始时它(某个特征)关联了图像上所有的点(首行),然后逐渐地关注在与该特征相邻近的特征点(尾行)。同样地,cross-attention主要关注去匹配可能的特征点,随着层的增加,它逐渐减少匹配点集直到收敛。绿色特征点在第9层就已经趋近收敛,而红色特征直到最后才能趋紧收敛(匹配)。可以看到无论是self还是cross,它们关注的区域都会随着网络层深度的增加而逐渐缩小。

结论
本文展示了基于注意力的图神经网络对局部特征匹配的强大功能。 SuperGlue的框架使用两种注意力:(i)自我注意力,可以增强局部描述符的接受力;以及(ii)交叉注意力,可以实现跨图像交流,并受到人类来回观察方式的启发进行匹配图像。文中方法通过解决最优运输问题,优雅地处理了特征分配问题以及遮挡点。实验表明,SuperGlue与现有方法相比有了显着改进,可以在极宽的基线室内和室外图像对上进行高精度的相对姿势估计。此外,SuperGlue可以实时运行,并且可以同时使用经典和深度学习特征。
总而言之,论文提出的可学习的中后端(middle-end)算法以功能强大的神经网络模型替代了手工启发式技术,该模型同时在单个统一体系结构中执行上下文聚合,匹配和过滤外点。作者最后提到:若与深度学习前端结合使用,SuperGlue是迈向端到端深度学习SLAM的重要里程碑。(when combined with a deep front-end, SuperGlue is a major milestone towards end-to-end deep SLAM)
传统的ORB,SIFT特征,以及暴力匹配和FLANN匹配方法,请参考https://github.com/Shiaoming/Python-VO

摘要
- 提出了一种能够同时进行特征匹配以及滤除外点的网络;
- 特征匹配是通过求解最优传输问题( optimal transport problem)来解决,损失函数由GNN来构建;
- 基于注意力机制提出了一种灵活的内容聚合机制,这使得SuperGlue能够同时感知潜在的3D场景以及进行特征匹配。
扩展实验说明
由于SuperGlue是做特征匹配的,所以可以用来做VO,我做了一个简单的frame-by-frame的VO:https://github.com/Shiaoming/Python-VO,它对比的特征有:
1.ORB
2.SIFT
3.SuperPoint
4.可以扩展更多特征描述子(欢迎pull request)
对比的匹配方法有:
1.KNN
2.FLANN
3.SuperGlue
4.可以扩展更多匹配方法
实验的数据集:
1.KITTI
2.更多数据集逐渐扩展支持
参考文献
https://vincentqin.gitee.io/posts/superglue/#comments
https://zhuanlan.zhihu.com/p/69515306
https://blog.csdn.net/shizhuoduao/article/details/107120805