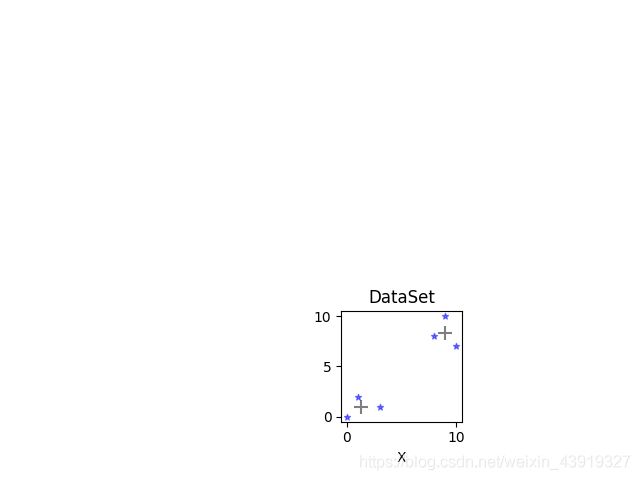
K均值聚类 k-means 对表内数据进行聚类,结果输出散点图
k-means算法
也称k-均值算法,是一种得到广泛使用的据类算法。K-means算法将各个簇内的所有数据样本的均值作为该簇的代表点,主要思想是将迭代过程吧数据集划分为不同的类别,使得评价聚类性能的准则函数达到最优,从而使生成的每个簇内部紧凑,簇之间相互独立。
k- means算法
输入:簇的数目k和包含n个对象的数据库。
输出:k个簇。
步骤
(1)为每个簇确定一个初始簇中心,这样就有k个初始簇中心。
(2)将样本集中的样本按照最小距离原则分配到最邻近的簇。
(3)使用每个簇中的样本均值作为新的簇中心。
(4)重复步骤(2)、(3),直到簇中心不再变化。
(5)结束,得到k个簇。
k- means算法对初始簇中心较敏感,相似度的计算方法会影响簇的划分。常见的似度计算方法有欧几里得距离、曼哈顿距离和闵可夫斯基距离等
**
题目:使用k均值聚类算法对表中的数据进行聚类。数据用表里的数据,注意K=2;显示输出结果散点图。
**

k-means.py
from numpy import *
import matplotlib.pyplot as plt
def loadDataSet(fileName):
dataMat = []
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split(' ')
fltLine = list(map(float, curLine))
dataMat.append(fltLine)
return dataMat
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2)))
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k, n)))
for j in range(n):
minJ = min(dataSet[:, j])
maxJ = max(dataSet[:, j])
rangeJ = float(maxJ - minJ)
centroids[:, j] = minJ + rangeJ * random.rand(k, 1)
return centroids
def kMeans(dataSet, k, distMeans=distEclud, createCent=randCent):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m, 2)))
centroids = createCent(dataSet, k)
clusterChanged = True
while clusterChanged:
clusterChanged = False
for i in range(m):
minDist = inf
minIndex = -1
for j in range(k):
distJI = distMeans(centroids[j, :], dataSet[i, :])
if distJI < minDist:
minDist = distJI
minIndex = j
if clusterAssment[i, 0] != minIndex: clusterChanged = True
clusterAssment[i, :] = minIndex, minDist ** 2
print(centroids)
for cent in range(k):
ptsInClust = dataSet[nonzero(clusterAssment[:, 0].A == cent)[0]]
centroids[cent, :] = mean(ptsInClust, axis=0)
return centroids, clusterAssment
datMat = mat(loadDataSet('testSet.txt'))
myCentroids, clustAssing = kMeans(datMat, 2)
clustAssing = clustAssing.tolist()
myCentroids = myCentroids.tolist()
xcord = [[], []]
ycord = [[], []]
datMat = datMat.tolist()
m = len(clustAssing)
for i in range(m):
if int(clustAssing[i][0]) == 0:
xcord[0].append(datMat[i][0])
ycord[0].append(datMat[i][1])
elif int(clustAssing[i][0]) == 1:
xcord[0].append(datMat[i][0])
ycord[0].append(datMat[i][1])
fig = plt.figure()
ax = fig.add_subplot(3, 4, 11)
ax.scatter(xcord[0], ycord[0], s=20, c='b', marker='*', alpha=.5)
ax.scatter(xcord[1], ycord[1], s=20, c='r', marker='D', alpha=.5)
ax.scatter(myCentroids[0][0], myCentroids[0][1], s=100, c='k', marker='+', alpha=.5)
ax.scatter(myCentroids[1][0], myCentroids[1][1], s=100, c='k', marker='+', alpha=.5)
plt.title('DataSet')
plt.xlabel('X')
plt.show()
testSet.txt
0 0
1 2
3 1
8 8
9 10
10 7
最后结果如图