学习python/pytorch过程中遇到的知识点
Pytorch
-
torch.backends.cudnn.deterministic和torch.backends.cudnn.benchmark这两个参数,用于固定算法,使每次运行结果都一样。将deterministic置为True的话,每次返回的卷积算法将是确定的,即默认算法。如果配合上设置 Torch 的随机种子为固定值的话,应该可以保证每次运行网络的时候相同输入的输出是固定的。
benchmark作用是优化cudnn的运行,cuda可以加快程序运行速度,自动寻找最适合当前配置的高效算法,来达到优化运行效率的问题。因此将benchmark设置为True可以提高运行速度,但是每次运行的cuda底层最优算法可能不同,导致程序的结果可能有一些差异。
所以如果在训练阶段,可以如下设置:def set_seed(myseed=2022): # 设置numpy随机种子 np.random.seed(myseed) # 设置python随机种子 random.seed(myseed) # 固定cuda底层优化算法 torch.backends.cudnn.deterministic = True torch.backends.cudnn.benchmark = False os.environ['CUBLAS_WORKSPACE_CONFIG'] = ':4096:8' # 设置cpu和cuda的随机数种子 torch.manual_seed(myseed) # 用于自查自己的代码是否包含不确定的算法,报错说明有 torch.use_deterministic_algorithms(True) # 固定环境变量种子 os.environ['PYTHONHASHSEED'] = str(myseed)此外,这里面还有许多固定算法,参考我的注释和这篇博客,这里就不再介绍了。该代码段可以直接复制使用。
-
特别注意,出了固定种子外,还需要固定装载数据集的方法,具体可直接copy以下代码,也可参考pytorch的官网
# 固定装载数据集初始化 def worker_init(worked_id): worker_seed = torch.initial_seed() % 2**32 np.random.seed(worker_seed) random.seed(worker_seed) DataLoader(dataset, batch_size, shuffle, num_workers,pin_memory=True,worker_init_fn=worker_init) -
在需要生成随机数据的实验中,每次实验都需要生成数据。设置随机种子是为了确保每次生成固定的随机数,参考
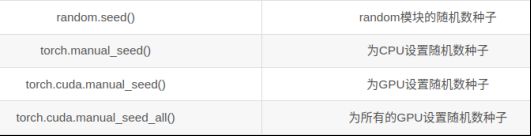
深度学习网络模型中初始的权值参数通常都是初始化成随机数,random.seed()、torch.manual_seed()、torch.cuda.manual_seed()、torch.cuda.manual_seed_all()用法总结(备注,在torch1.8及以后版本中,只使用torch.manual_seed()就可以同时固定cpu和cuda了)
-
关于
Pytorch默认的参数初始化问题,参考
用自己的话总结一下:Pytorch中默认会初始化参数,这个初始化在调用神经网络时已经给初始好了,不需要自己手动初始化。系统默认初始化参数时也是用random的相关函数,这也是为什么我们需要设置seed了,因为设置seed后,每次初始化的参数值是一模一样的。
此外,也可以手动初始化参数。自动初始化参数是可以满足大多数情况的,但是针对有些特定的RNN、CNN的网络,有更适合收敛的参数,因此可以默认,但也可以手动初始化参数。 本人写的手动初始化参数的文章 -
有关报错:
RuntimeError: Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed)问题。
翻译一下就是:第二次尝试在图中向后遍历时,保存的临时变量已经被释放。
报错的代码如下:feature = feature_extractor(total_data) domain_pred = domain_classifier(feature) loss = critical_domain(domain_pred, total_label) running_D_loss += loss.detach().item() * len(train_data) loss.backward() domain_optimizer.step() label_pred = label_predictor(feature[:train_data.shape[0]]) domain_pred = domain_classifier(feature)我们在有关GAN或者类似与GAN的运算中,往往会需要不同的神经网络求损失函数,反向传播等。但是执行反向传播(backward)时会释放临时变量,例如上面的程序feature变量在第一次loss.backward()时已经释放了,结果下面又一次调用,这样是不可以的!!
正确的做法是domain_pred = domain_classifier(feature.detach())或者在调用时重新再写一遍feature = feature_extractor(total_data)detach阻断了反向传播,这个变量不进行反向传播,也就不释放了呗。 -
with是上下文管理器,除可用于打开文件,还经常用于with torch.no_grad():这句话是用在testing神经网络时加上的。神经网络在反向传播时会自动求导,占用内存,在testing时不需要反向传播(自动求导),所以加上这句话更好,当然,加不加不影响结果,可能影响测试速度。 -
squeeze属性的作用就是对tensor变量进行维度压缩,去除维数为1的的维度。例如,一个3×2×1×2×1的tensor,squeeze()之后便成了3×2×2。存储的数据并没有发生变化,但是去除了“多余”的维度信息:如果没有为1的维度,则不进行操作。参考 -
nn.Sequential:一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行

-
深度学习时会看见如下3行代码:
import gc del train, train_label, train_x, train_y, val_x, val_y gc.collect()是用来清理内存的,加载的数据比较多,加载完了后将内存释放出来
-
model.train()和model.eval():
在使用pytorch构建神经网络的时候,训练过程中会在程序上方添加一句model.train(),作用是启用batch normalization和drop out(如果model中加入了batch normalization和drop out就会启用,没加入就不会启用,换言之,没加入的话这句就没作用)。
在使用pytorch构建神经网络的时候,测试过程不启用Batch.Normalization和Dropout,沿用train过程中Batch.Normalization的均值和标准差。(具体可以参考李宏毅老师2021年Batch.Normalization这一节的解释,大体意思是实际使用时,数据是一个个来的,不太可能一下子给你一大堆,但是我们不可能等到一个batch时再计算,所以只能沿用训练过程中batch的平均值) -
torch.max()使用方法:在分类问题中,通常需要使用max()函数对softmax()函数的输出值进行操作,求出预测值索引,然后与标签进行比对,计算准确率。这里面有两个参数,一个是tensor,一个是dim。假设tensor是5*100的维度,dim=1,就代表将列的维度去掉,只保留行的维度。也就是新返回的tensor只有1行5列。 参考 -
类似的还有
torch.argmax()与上述区别在于返回只有一个下标的索引 参考1 参考2 -
_, train_pred = torch.max(outputs, 1)经常会遇到这种表达,前面的_,表示忽略掉第一个返回值(个人理解为“假取值”) -
tqdm是循环显示进度条的库,在训练比较慢时可以看看训练到哪里了
tqdm可用于所有可迭代对象,所以可以直接用在dataloader上,例如:
for data, target in tqdm(train_loader):
也可以将它与enumerate结合,例如:
for i, x in enumerate(tqdm(dataloader)):
特别要注意,如果有with tqdw as pbar这样的话就不用pbar.close了,如果是其他方式调用的tqdm,结束时一定得加close函数 参考1 参考2 参考3 -
pytorch中view()函数用途:reshape tensor的形状(view()的作用相当于numpy中的reshape,重新定义矩阵的形状。)详见 -
pytorch中
tensor维度转换view()和permute():permute是将tensor中任意维度调换,注意是维度调换 ,而不是任意修改维度,只是调换维度;view是修改维度,相当于reshape 参考 -
torch.cat:张量拼接,将两个张量拼接到一起,dim=1为水平拼接,dim=0为竖直拼接,参考 -
np.hstacknp.vstack矩阵拼接 详解https://blog.csdn.net/a1058420631/article/details/94137505 -
for data in train_dataloader:是以一个batch传进去的,data是一个batch的数据,而不是一个单独的数据,假设一个batch是200,trainloader总共是2000,那么就循环10次,每一次循环就更新一次参数,直到把整个数据循环完(循环10次就更新10次参数);最外面还有个epoch,epoch等于5就是把这个过程重复5次。 -
统计样本预测正确的个数,以下两种都可以:
(A==B).sum()或者np.equal(A,B).sum()

-
Dataset中的__getitem__(self,index)和__len__()方法
第一,这两个方法必须要重写,不能省略。
第二,__getitem__(self,index)中的index参数怎么传参的?Dataloader会调用Dataset中的__len__()函数,并把__len__()函数的返回值送入__getitem__(),当做index参数。
第三,__len__()中需要返回数据的长度(总共多少个数据),__getitem__()需要编写支持数据集索引的函数并返回。
第四,__getitem__()中返回的数据顺序可以是任意的:因为后续你会执行dataloader = Dataloader(XXX,XXX,XXX),然后你训练或测试时,dataloader会存放__getitem__()中返回的数据,只要自己的数据能对得上就行。(通过这条语句拿出:for x, y in dataloader) -
model中的forward(self,x)函数,参考
举个简单的例子class NeuralNet(nn.Module): …… model = NeuralNet() pred = model(data_x)因为我们在训练时会调用
model函数,并且会把数据data_x传入model中,底层自动调用forward方法计算结果,而这个data_x就是forward函数的参数!

-
最重要的一点,Pytorch中的返回的
loss值,是每个数据的平均值。通俗的理解就是:尽管每次传入一个batch,但这个loss,并不是所有的batch总和,而是每一个数据的平均值。
其次,我们可能需要求一次epoch的loss平均值,这时候每一次batch返回的loss值都相加,最后再除以len(dataloader),例如下面:for x,y in train_dataloader: loss_train = criterion(pred, data_y) total_loss_train += loss_train avg_loss = total_loss_train / len(train_dataloader) -
接上条,为什么我们最终除以的是
len(train_dataloader),这个len(train_dataloader)代表了什么?代表了有多少个batch!而不是总共有多少个数据,这一定要注意! 如果我们想知道总共有多少数据,应该用len(train_dataloader.dataset)所以如果我们除以的是len(train_dataloader.dataset),那么前面的loss每次相加时,得乘以batch_size! 然而这有个缺点,因为你的len(train_dataloader)*batch_size不一定等于 total data ,因为数据集不一定是batchsize的整数倍,会有轻微的误差。所以,我们求平均loss时,只推荐第一种方法(用len(train_dataloader),得出batch的数目) -
pytorch detach() item() cpu()的理解
detach()是阻断反向传播的,深度学习中每一步运算都被记录在计算图中,例如我们计算loss,然后用loss做迭代。可是当我们需要显示出loss时,这个显示loss的步骤也会被记录在计算图中去计算,这会影响深度学习的。因此加上个detach函数表明,我这句话和你们深度学习的内容无关了。
进一步理解了detach()方法的含义 : 如果requires_grad=True那么需要detach,否则会反向传播计算梯度;如果requires_grad=False那没必要detach,因此本来就不会反向传播。
因此总结,需不需要detach,取决于requires_grad的取值(平时定义一个tensor,默认梯度取值是False,是不需要的,但是你计算出来的loss是critical函数得出的,虽然你看不见critical函数内部的咋写的,但是你想想,loss是需要反向传播的,所以一定requires_grad是Tru,那么自然就需要detach函数了)。
cpu(),一方面,因为深度学习的数据都在cuda上,所以cpu的内存可能读不到(虽然实测还是能的),为了保险起见,将loss这些数据转移到cpu上来读。另一方面,如果不加上这个,打印出来显示的是tensor(data,cuda),加上cpu(),显示的是tensor(data)
item(),返回tensor中的数值,返回的是标量data,如果不加上item(),显示的是tensor(data) -
transforms.ToTensor()这个函数的用法?ToTensor()将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可。 参考
总结一下:① 、起到了一个reshape的作用 ;②、起到归一化的作用。 其实不难理解为什么起到这两点作用,因为PIL的读取的图片格式本来就是(H, W, C),所以肯定要进行一步转换;且transforms这个库就是针对图像的,而将图像像素的归一化是最基础的操作之一,所以totensor都替我们做好了。 -
transforms.Normalize()函数的用法?这个函数是起到归一化的作用。 参考
第一,它是怎么用的?
回答:output = (input - mean) / std如果是三通道的话,就是三个通道分别计算,如果单通道的话,就计算一个通道。
第二,怎么写?
回答:三通道:transforms.Normalize(std=(0.5,0.5,0.5),mean=(0.5,0.5,0.5)),单通道:transforms.Normalize(std=(0.5,),mean=(0.5,))(补充:区间是[-1, 1])
第三:RGB单个通道的值是[0, 255],所以一个通道的均值应该在127附近才对。如果Normalize()函数去计算 x = (x - mean)/std ,因为RGB是[0, 255],算出来的x为什么落在[-1, 1]区间?
回答:因为在使用这个函数前会先应用torchvision.transforms.ToTensor函数,该函数是[0,1]的范围
第四,在我看的了论文代码里面是这样的:torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])为什么就确定了这一组数值,这一组数值是怎么来的?
回答: [0.485, 0.456, 0.406]这一组平均值是从imagenet训练集中抽样算出来的

-
反归一化:有些时候处理的图是归一化的,如果想变为原来的像素,需要执行反归一化,只需令
Mean = -Mean/Std,Std=1/Std,然后再次调用torchvision.transforms.Normalize函数,将反归一化后的平均值和标准差输入进去,即可实现。(当然,许多操作中直接进行了 img=(img+1)/2 操作,效果与反归一化一模一样, 这是由于dataset中往往会先Totensor,转换为0-1,再(0.5,0.5,0.5)的归一化为[-1,1] 因此上述操作等同于反归一化) -
接上条,如果归一化时不是(0.5,0.5,0.5)这样简单的数怎么办呢?一方面还是通过上述公式手动计算,然后调用归一化函数。另一方面,如果步调用归一化函数,也可以采用如下代码:
cifar_10_mean = (0.491, 0.482, 0.447) # mean for the three channels of cifar_10 images cifar_10_std = (0.202, 0.199, 0.201) # std for the three channels of cifar_10 images # convert mean and std to 3-dimensional tensors for future operations mean = torch.tensor(cifar_10_mean).to(device).view(3, 1, 1) std = torch.tensor(cifar_10_std).to(device).view(3, 1, 1) #反归一化 img = ((img) * std + mean).clamp(0, 1) # to 0-1 scale虽然这个img的维度是(batch, channel, height, weight)四维的,反归一化的维度是三维的的,不过tensor相乘时会自动转换为同样的size。
-
不同激活函数:
Sigmoid/ReLU/LeakyReLU/PReLU/ELU等等,各自长什么形状? 参考 -
drop_last的作用?在Dataloader类中有一个drop_last的选项,drop_last是作用是什么?我们的数据集个数与batch_size的大小往往不成整数关系,如果drop_last是False,那么最后剩下了多少余数,就读进来多少余数;如果drop_last是True,那么就把余数丢掉。 -
GAN生成器、判别器 编写思路,见如下两篇文章 文章1 文章2 -
注意,Pytorch中卷积接口所需的RGB图像尺寸是(CHW)通道、长度、宽度。而我们读进来的图像尺寸大多数情况下是HWC,长度、宽度、通道。因此当我们把图像数据送进卷积层时,必须要先进行尺寸转换!!
至于为什么pytorch选择设计成chw而不是hwc(毕竟传统的读图片的函数opencv的cv2.imread或者sklearn的imread都是读成hwc的格式的)。个人感觉是因为pytorch做矩阵加减乘除以及卷积等运算是需要调用cuda和cudnn的函数的,而这些接口都设成成chw格式了,故而pytorch为了方便起见也设计成chw格式了
那新问题就来了,cuda和cudnn为什么设计成chw格式呢?我想这是由于涉及到图片操作的都是和卷积相关的,而内部做卷积运算的加速设计成chw在操作上会比hwc处理起来更容易,更快。题主如果想进一步了解可以google一下cudnn的卷积实现。 -
关于
PyTorch中提供的这个sampler模块,用来对数据进行采样。默认采用SequentialSampler,它会按顺序一个一个进行采样。
什么时候会用Sample采样器呢?比如在模型参数初始化、加载数据集时!
例如加载数据集时,会有shuffle参数,在每个epoch中对整个数据集data进行shuffle重排。如果我们shuffle是False的话,就默认不洗牌,其实也就是顺序采样数据集;如果我们的shuffle是True的话,就是洗牌,也就是随机采样数据集(RandomSampler)。换句话说,dataloader中如果shuffle是true,则默认为RandomSampler。如果shuffle为false,则默认是顺序采样SequentialSampler,如果想自己定义采样器,shuffle设置为false,然后自己定义采样器。详细可以参考:文章
同理,模型初始化时也是需要采样器的,这点在前面的内容有提过。# 如果想自己定义采样器,就按照如下格式 train_sampler = RandomSampler(train_dataset) train_dataloader = DataLoader(train_dataset, sampler=train_sampler, batch_size=batch_size) -
transforms.Lambda有时官方提供的方法并不能够满足你的需要,这时候你就需要自定义自己的transform策略,方法就是使用transforms.Lambda。具体可以参考:文章self.transform = transforms.Compose([ transforms.Lambda(lambda x: x.to(torch.float32)), transforms.Lambda(lambda x: 2. * x / 255. - 1.), ])该
transforms.Lambda函数使用方法通常如上,注意这里面还有个lambda x函数。
关于lambda x 这是python中的一个隐匿函数 冒号左边是传入的参数,冒号右边是表达式 表达式计算出来的值就直接作为transforms.Lambda的参数了,其实很容易理解,我是对x做操作,我把x传入了隐匿函数中,然后后面的表达式就对x进行了操作,x的值就改变了,把改变的x值(图像信息)传入transforms中,就等同于对图像变换了呗 -
注意魔法函数是可以调用的, getitem也可以调用,不过需要给个参数(给它一个参数,就只会出现一个数,并不是像加载数据集时给一个参数就出现循环,是因为dataloader内部做了循环操作而已,这点要注意。),例如:
print(f'number of images = {adv_set.__len__()}') print(f'number of images = {adv_set.__getitem__(5)}') -
clone()、detach()、data等张量复制操作。
clone():返回一个和源张量同形状、类型、设备的张量,与源张量不共享数据内存,但提供梯度的回溯(源张量梯度是True,复制后也是True,源张量是False,复制后也是False)。detach():返回一个和源张量同形状、类型、设备的张量,与源张量共享数据内存,不提供梯度计算,即requires_grad=False,因此脱离计算图。.data:与detach()一样,共享数据内存,不提供梯度计算,但是detach更安全一点,所以能用detach就用detach。
将detach()和clone结合起来用,可以创建出数据相同,完全独立的新tensor。常见的手段便是 b = a.clone().detach() 或是 b = a.detach().clone() 参考 -
在做攻击任务时,看到过如下代码,可根据该代码进一步理解优化器和反向传播的含义:
def fgsm(model, x, y, loss_fn, epsilon=epsilon): x_adv = x.detach().clone() # initialize x_adv as original benign image x x_adv.requires_grad = True # need to obtain gradient of x_adv, thus set required grad loss = loss_fn(model(x_adv), y) # calculate loss loss.backward() # calculate gradient x_adv = x_adv + epsilon * x_adv.grad.detach().sign() return x_adv乍一看好像这个训练不需要更新参数,没有
optimizer.step(),其实不是这样的。backward的的作用是反向传播计算梯度,有了backward这一步后,梯度已经计算出来了,通常后面再跟一步迭代参数(step)就行。代码中这个迭代参数不是通过optimizer实现的,而是通过自己定义了x_adv = x_adv + epsilon * x_adv.grad.detach().sign()实现,梯度保存在变量中,所以直接根据梯度操作了变量,这也意味着我们写代码时不一定要照搬optimizer.step(),也可以自己实现自己的优化器。 -
注意什么时候用
argmax(维度)(求最大值下标),什么时候用softmax(维度)(求概率) -
unsqueeze();squeeze():前者是增加一个为1的维度,例unsqueeze(2)就是将(2,2)变为(2,2,1),后者是减少一个为1的维度。 参考1 参考2
numpy.squeeze(a,axis = None)
1)a表示输入的数组; 2)axis用于指定需要删除的维度,但是指定的维度必须为单维度,否则将会报错; 3)axis的取值可为None 或 int 或 tuple of ints, 可选。若axis为空,则删除所有单维度的条目; 4)返回值:数组。 5) 不会修改原数组; -
.item()和.data的区别:.data返回的是一个tensor,而.item()返回的是一个具体的数值。注意:对于元素不止一个的tensor列表,使用item()会报错 -
tensor的尺寸用size函数,而不是shape函数,例如adv_x.data.size() -
image pixel value should be unsigned int !!!
np.uint8 -
想知道
dataloader读入的数据,不能直接print(dataloader)这没法达到预期。必须要这么写:print(dataloader.dataset),这个dataset是固定的名字,和自己写的程序定义的变量名无关。后续也可在此基础上进行更多的操作,例如dataloader.dataset[5]dataloader.dataset.__getitem__(5)dataloader.dataset.__len__() -
如果我们在训练时既需要训练资料,又需要测试资料,那如何将训练资料、测试资料同时读取呢?
可以采用这样的代码:enumerate+zip的用法(主要是zip方法)for i, ((source_data, source_label), (target_data, _)) in enumerate(zip(source_dataloader, target_dataloader)): -
CrossEntropyLoss、BCELoss 、BCEWithLogitsLoss的区别:
CrossEntropyLoss:用于多分类问题,其内部已包含了一个softmax层
BCELoss:binary cross entropy 用于二分类问题,输入这个函数前,数据需要先手动转换到0-1之间(通常用sigmod函数转换),例如一些图片已经经过0-1归一化后,就可以采用BCELoss计算损失,而不能用BCEWithLogitsLoss计算(否则会再进行一次sigmod缩小转换)
BCEWithLogitsLoss:sigmod函数+BCELoss函数,数据输入这个函数前,不需要转换为0-1之间,函数内部会自动转换。 -
有关pytorch的采样/分布问题:
from torch.distributions import Categorical,以下面三行代码为例:action_dist = Categorical(action_prob) action = action_dist.sample() log_prob = action_dist.prob(action)action_prob里面包含了四个动作的概率。Categorical是一个类,action_dist是这个类的实例。action_dist.sample()是这个类的方法,作用是根据action_prob的概率进行采样,比如第一个位置概率大,那么采样采到的概率就大。action就是采样采到的位置下标。然后把这个下标输入到action_dist.prob(action)中,就是根据这个下标把值取出来。 参考
Python
-
with..as用法:python操作文件时,需要打开文件,最后手动关闭文件。通过使用with...as...不用手动关闭文件。当执行完内容后,自动关闭文件,简化了程序,例如with open("/tmp/foo.txt") as file: data = file.read() -
shape函数得到矩阵长度,一般有两种用法:np.shape(array)这种直接返回矩阵的所有维度的长度,比如(3,2)这种;另一种array.shape[1]返回第二维的长度;前者是当做函数用,后者是当做属性用 -
用
len()函数计算二维数组的长度,只计算有多少行,不计算列数 -
在程序中常常使用
# TODO这个是用来提醒此处还有什么没做,一般用于计划安排,进度跟踪,沟通交流,是一个很好的代码风格 -
python中的一些变量,有全局变量、局部变量、类变量、实例变量。
全局变量:在所有函数和class外定义的变量
局部变量:在所有函数和class的方法内的变量
类变量:在class内,不在class的方法内的变量
实例变量:在class方法内用self修饰的变量
全局变量的作用域可以作用在任何地方,局部变量作用在函数内/方法内;类变量和实例变量就作用在类中。
不过要特别注意,类变量和实例变量最大的不同在于:类变量的每个实例所拥有的是同一个内存,在一个实例中修改,会改变其他实例中的值;而实例变量的单独的内存,每个实例只能修改自己的值,不能修改其他实例的值。详见1 详见2 -
Python的enumerate()函数是一个将可遍历的数据对象(元组、列表、字符串等)组合为一个索引序列,可同时输出数据和数据下标 详见1 详见2 -
有关
if __name__ == “__main__”的理解:__name__是当前模块名,当模块被直接运行时模块名为__main__。这句话的意思就是,当模块被直接运行时,以下代码块将被运行,当模块是被导入时,代码块不被运行。(另一种理解:设我写了个程序A,在这个A里面我分了两部分,分别是1,2,并在1,2之间插入if name main,这就表示2只能在A程序中执行,如果A被插入到了B程序中,那么在程序B中只执行1,不执行2。) -
python中的zip()和zip(*)的用法和区别:前者是将对象中对应位置的元素打包成一个个元组,然后返回由这些元组组成的列表。后者与zip相反,可理解为解压,为zip的逆过程。mel, speaker = zip(*batch)参考 -
a=list()和a=[]定义一个列表 -
np.inf表示无限大的正数,可以这么用:best_loss = np.inf然后再循环选取best_loss的最小值 -
data[:,y] data[x,:]的含义

-
np.random.rand()函数,随机生成服从(0,1)分布的样本值,np.random.randn(),随机生成服从正态分布的样本值 用法参考
numpy.random.randint的用法:返回一个随机整型数,常用np.random.randint(10,30,1)意思是在10-30的范围内,返回一个数(这个“1”是输出随机数的尺寸。比如size = (m, n, k)则输出同规模的一个数组。size默认是None的,仅仅返回满足要求的单一随机数) 详见 -
python的list和array是有区别的(例如list是有逗号的,array之间是没有逗号的(空格代替)),有些函数要求参数是array所以就必须是array,array和list两者可以相互转换 -
numpy中的ravel函数,将数组扁平化(将数组拉成一维数组)

-
python中range()函数返回的是一个可迭代对象,通常可以这么用:
for i in range(10): for i in range(2,10): for i in range(2,10,2):参考 -
Python中经常看见data[0][5],data[0,5]这两种读取方法,在数组中既可以依次读取,也可以用切片的方式读取,这是因为数组中存放的数据类型都一样,所以可以切片读取。但是列表可以存放不同类型的数据,因此列表中每个元素的大小可以相同,也可以不同,也就不支持切片读取!python中数组和列表读取一列的方法 -
关于
numpy的astype(bool)和astype(int),以及int()的区别:int()针对一个数取整,不能对数组这么用;.astype(int)针对数组、列表取整数,不能对一个数这么用(一个处理标量,另一个处理向量) 详见 -
python中的unique();a = np.unique(A),对于一维数组或者列表,unique函数去除其中重复的元素,并按元素由大到小返回一个新的无元素重复的元组或者列表 参考 -
python中index的作用:index()函数用于从列表中找出某个值第一个匹配项的索引位置。 -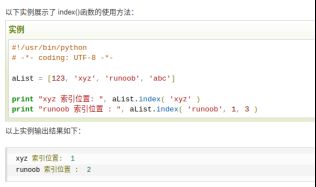
-
python中tolist()命令 ,将数据或矩阵转换为列表 -
np.set_printoptions(threshold=sys.maxsize)函数(或者np.set_printoptions(threshold=np.inf)),将全部信息量都打印出来,有时候print(array)太大,只会打印前面和后面的一部分,中间一大部分就不打印了,这样可以强制让python都打印出来。
这里的np.inf只是为了保证这个阈值足够大,以至于所有长度的数组都能完整打印,读者也可以根据自己的实际情况进行设置。比如,threshold=10000,那么数组长度<=10000的数组可以完整打印;数组长度>10000:以省略的形式打印。 -
Python中
单斜杠/表示浮点数除法,返回浮点结果;双斜杠//表示整数除法。 -
python中
flatten(dim),经常用在深度学习,图像处理/图像拉直时(从cnn layer 进入linear layer中)。具体用法如下:参考 -
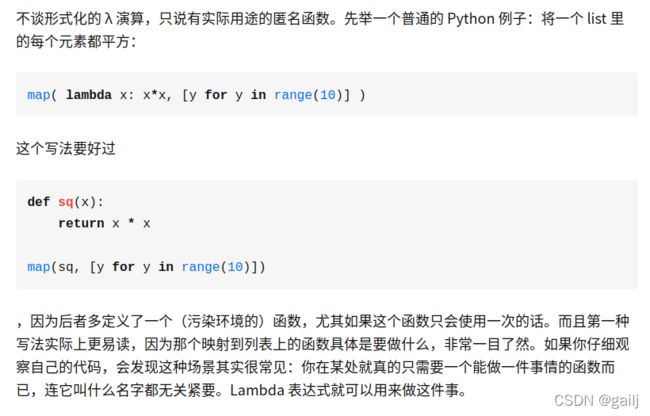
有关
lambda x这是python中的一个隐匿函数 通常这么用:f = lambda x : x + 1,冒号左边是传入的参数,冒号右边是表达式,表达式算出来的值就给了f句柄。如果程序中有一些函数只使用了一次,那就没必要去定义这个函数了,会造成函数环境污染。这时候用隐匿函数就比较方便了。
-
f'{data_dir}/*'前面的f是什么作用 ? 等同于'{}/*'.format(class_dir),是format函数的一种简单写法。format函数是大括号内不加东西,然后在外层用.format来添加,如果前面加上了f,就可以直接在大括号内添加变量等东西了,是一种简化版,怎么写都可以。 -
os.path.relpath():把绝对路径转换为相对路径,也可以认为是一种路径截断。参考:https://blog.csdn.net/Hunter_Murphy/article/details/108043298 -
sign()是干啥的:符号函数 以y轴为分界线,x>0 y取1,x<0 y取-1 -
clamp(min,x,max):用来将某个值“钳”住、限制在某个区间(min~max), 参考https://blog.csdn.net/qq_35649072/article/details/103432558 -
round()函数取值四舍五入 -
np.r_[];np.c_[]:np.r_就是把两矩阵上下相加,要求操作后列数不变;np.c_就是把两矩阵左右相加,要求行数不变 参考 -
plt.tight_layout() 作用,让图像排列整齐,参考 https://blog.csdn.net/Du_Shuang
-
Image.fromarray():实现array到image的转换,通常是将数组变为图像,然后保存起来 (需要引入 from PIL import Image ) 完整代码如下:from PIL import Image im = Image.fromarray(example.astype(np.uint8)) # image pixel value should be unsigned int im.save(os.path.join(adv_dir, name)) #注意这个name必须要指定图片的名字和类型 -
shutil.copytree(old_path,new_path):复制文件夹(需要引入import shutil),具体操作 参考 -
sorted()排序操作:y = sorted(x),默认升序。https://www.cnblogs.com/huchong/p/8296025.html
-
Notebook在远程服务器上运行,因此无法渲染Gym的环境,需要在远程服务器上虚拟一个显示窗口。可以下载pyvirtualdisplay库,使用这三行代码,就可以虚拟出远程服务器上显示界面
from pyvirtualdisplay import Display virtual_display = Display(visible=0, size=(1400, 900)) virtual_display.start()