深度学习撞上推荐系统——02 GFM MLP NCF Pytorch代码实现
GMF模型
1.从深度学习的视角可以理解为矩阵分解模型,其中矩阵分解层的用户隐向量和物品隐向量可以看做是一种Embedding方法,然后将Embedding后的向量进行点积 最后通过一个线性层输出
2.模型结构如下

所以输入的模型中的数据有num_users(user的数量),num_items(item的数量),embed_dim(Embedding的维度)
模型需要输入的数据inputs里面应该为[userId,itemID]
该模型的特点:
- 点积:让用户和物品向量进行交互为了进一步让向量在个维度上进行充分的交叉。
代码如下:
import datetime
import numpy as np
import pandas as pd
from collections import Counter
import heapq
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import warnings
warnings.filterwarnings('ignore')
from torchsummary import summary
# 一些超参数设置
topK = 10
num_factors = 8
num_negatives = 4
batch_size = 64
lr = 0.001
# 数据在processed Data里面
train = np.load('ProcessedData/train.npy', allow_pickle=True).tolist()
testRatings = np.load('ProcessedData/testRatings.npy').tolist()
testNegatives = np.load('ProcessedData/testNegatives.npy').tolist()
num_users, num_items = train.shape
# 制作数据 用户打过分的为正样本, 用户没打分的为负样本, 负样本这里采用的采样的方式
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [], [], []
num_items = train.shape[1]
for (u, i) in train.keys(): # train.keys()是打分的用户和商品
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instance
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
#print(u, j)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
user_input, item_input, labels = get_train_instances(train, num_negatives)
train_x = np.vstack([user_input, item_input]).T
labels = np.array(labels)
# 构建成Dataset和DataLoader
train_dataset = TensorDataset(torch.tensor(train_x), torch.tensor(labels).float())
dl_train = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
class GMF(nn.Module):
def __init__(self,num_users,num_items,embed_dim,reg=[0,0]):
super(GMF,self).__init__()
self.MF_Embedding_User=nn.Embedding(num_embeddings=num_users,embedding_dim=embed_dim)
self.MF_Embedding_Item=nn.Embedding(num_embeddings=num_items,embedding_dim=embed_dim)
self.linear=nn.Linear(embed_dim,1)
self.sigmoid=nn.Sigmoid()
def forward(self,input):
input=input.long()
MF_Embedding_User=self.MF_Embedding_User(input[:, 0])
MF_Embedding_Item=self.MF_Embedding_Item(input[:, 1])
predict=torch.mul(MF_Embedding_User,MF_Embedding_Item)
linear=self.linear(predict)
output=self.sigmoid(linear)
output=output.squeeze(-1)
return output
# Global variables that are shared across processes
_model = None
_testRatings = None
_testNegatives = None
_K = None
# HitRation
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
# NDCG
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return np.log(2) / np.log(i+2)
return 0
def eval_one_rating(idx): # 一次评分预测
rating = _testRatings[idx]
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
items.append(gtItem)
# Get prediction scores
map_item_score = {}
users = np.full(len(items), u, dtype='int32')
test_data = torch.tensor(np.vstack([users, np.array(items)]).T)
predictions = _model(test_data)
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i].data.numpy()
items.pop()
# Evaluate top rank list
ranklist = heapq.nlargest(_K, map_item_score, key=lambda k: map_item_score[k]) # heapq是堆排序算法, 取前K个
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return hr, ndcg
def evaluate_model(model, testRatings, testNegatives, K):
"""
Evaluate the performance (Hit_Ratio, NDCG) of top-K recommendation
Return: score of each test rating.
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testNegatives = testNegatives
_testRatings = testRatings
_K = K
hits, ndcgs = [], []
for idx in range(len(_testRatings)):
(hr, ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return hits, ndcgs
# 训练参数设置
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=lr)
# 计算出初始的评估
(hits, ndcgs) = evaluate_model(net, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR=%.4f, NDCG=%.4f' %(hr, ndcg))
# 模型训练
best_hr, best_ndcg, best_iter = hr, ndcg, -1
epochs = 20
log_step_freq = 10000
print('开始训练')
for epoch in range(epochs):
# 训练阶段
net.train()
loss_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
features, labels = features, labels
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
loss_list=[]
if step % log_step_freq == 0:
loss_list.append(loss_sum/step)
print(("[step = %d] loss: %.3f") %
(step, loss_sum/step))
# 验证阶段
net.eval()
(hits, ndcgs) = evaluate_model(net, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
torch.save(net.state_dict(), 'Pre_train/m1-1m_GMF.pkl')
loss_list=[]
loss_list.append(loss_sum/step)
hr_list=[]
hr_list.append(hr)
NDCG_list=[]
NDCG_list.append(ndcg)
info = (epoch, loss_sum/step, hr, ndcg)
print(("\nEPOCH = %d, loss = %.3f, hr = %.3f, ndcg = %.3f") %info)
print('Finished Training...')
NCF模型
打字字母啥的太费劲了 直接看手写笔记吧


import datetime
import numpy as np
import pandas as pd
from collections import Counter
import heapq
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import warnings
warnings.filterwarnings('ignore')
from torchsummary import summary
# 一些超参数设置
topK = 10
num_factors = 8
num_negatives = 4
batch_size = 64
lr = 0.001
# 数据在processed Data里面
train = np.load('ProcessedData/train.npy', allow_pickle=True).tolist()
testRatings = np.load('ProcessedData/testRatings.npy').tolist()
testNegatives = np.load('ProcessedData/testNegatives.npy').tolist()
num_users, num_items = train.shape
# 制作数据 用户打过分的为正样本, 用户没打分的为负样本, 负样本这里采用的采样的方式
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [], [], []
num_items = train.shape[1]
for (u, i) in train.keys(): # train.keys()是打分的用户和商品
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instance
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
#print(u, j)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
user_input, item_input, labels = get_train_instances(train, num_negatives)
train_x = np.vstack([user_input, item_input]).T
labels = np.array(labels)
# 构建成Dataset和DataLoader
train_dataset = TensorDataset(torch.tensor(train_x), torch.tensor(labels).float())
dl_train = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self, num_users, num_items, layers=[20, 64, 32, 16], regs=[0, 0]):
super(MLP, self).__init__()
self.MF_Embedding_User = nn.Embedding(num_embeddings=num_users, embedding_dim=layers[0]//2)
self.MF_Embedding_Item = nn.Embedding(num_embeddings=num_items, embedding_dim=layers[0]//2)
# 全连接网络
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(layers[:-1], layers[1:]))])
self.linear = nn.Linear(layers[-1], 1)
self.sigmoid = nn.Sigmoid()
def forward(self, inputs):
# 这个inputs是一个批次的数据, 所以后面的操作切记写成inputs[0], [1]这种, 这是针对某个样本了, 我们都是对列进行的操作
# 先把输入转成long类型
inputs = inputs.long()
# MF的前向传播 用户和物品的embedding
MF_Embedding_User = self.MF_Embedding_User(inputs[:, 0]) # 这里踩了个坑, 千万不要写成[0], 我们这里是第一列
MF_Embedding_Item = self.MF_Embedding_Item(inputs[:, 1])
# 两个隐向量堆叠起来
x = torch.cat([MF_Embedding_User, MF_Embedding_Item], dim=-1)
# l全连接网络
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.linear(x)
output = self.sigmoid(x)
output=output.squeeze(-1)
return output
# 看一下这个网络
model = MLP(1, 1, [20, 64, 32, 16, 8]) # 全连接网络可以随意扩展
summary(model, input_size=(2,))
## 设置
layers = [num_factors*2, 64, 32, 16, 8]
model = MLP(num_users, num_items, layers)
# Global variables that are shared across processes
_model = None
_testRatings = None
_testNegatives = None
_K = None
# HitRation
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
# NDCG
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return np.log(2) / np.log(i+2)
return 0
def eval_one_rating(idx): # 一次评分预测
rating = _testRatings[idx]
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
items.append(gtItem)
# Get prediction scores
map_item_score = {}
users = np.full(len(items), u, dtype='int32')
test_data = torch.tensor(np.vstack([users, np.array(items)]).T)
predictions = _model(test_data)
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i].data.numpy()
items.pop()
# Evaluate top rank list
ranklist = heapq.nlargest(_K, map_item_score, key=lambda k: map_item_score[k]) # heapq是堆排序算法, 取前K个
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return hr, ndcg
def evaluate_model(model, testRatings, testNegatives, K):
"""
Evaluate the performance (Hit_Ratio, NDCG) of top-K recommendation
Return: score of each test rating.
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testNegatives = testNegatives
_testRatings = testRatings
_K = K
hits, ndcgs = [], []
for idx in range(len(_testRatings)):
(hr, ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return hits, ndcgs
# 训练参数设置
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr)
# 计算出初始的评估
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK)
# 模型训练
best_hr, best_ndcg, best_iter = hr, ndcg, -1
epochs = 20
log_step_freq = 10000
for epoch in range(epochs):
# 训练阶段
model.train()
loss_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
features, labels = features, labels
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = model(features)
loss = loss_func(predictions, labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
if step % log_step_freq == 0:
print(("[step = %d] loss: %.3f") % (step, loss_sum/step))
# 验证阶段
model.eval()
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
torch.save(model.state_dict(), 'Pre_train/m1-1m_MLP.pkl')
info = (epoch, loss_sum/step, hr, ndcg)
print(("\nEPOCH = %d, loss = %.3f, hr = %.3f, ndcg = %.3f") %info)
print('Finished Training...')
训练结果
start training....
[step = 10000] loss: 0.290
[step = 20000] loss: 0.290
[step = 30000] loss: 0.290
[step = 40000] loss: 0.291
[step = 50000] loss: 0.291
[step = 60000] loss: 0.291
[step = 70000] loss: 0.291
EPOCH = 0, loss = 0.291, hr = 0.575, ndcg = 0.324
[0.5751655629139073]
[0.3239830483525621]
[0.29118310283853677]
[step = 10000] loss: 0.289
[step = 20000] loss: 0.289
[step = 30000] loss: 0.289
[step = 40000] loss: 0.290
[step = 50000] loss: 0.290
[step = 60000] loss: 0.290
[step = 70000] loss: 0.290
EPOCH = 1, loss = 0.291, hr = 0.577, ndcg = 0.322
[0.5771523178807947]
[0.3217358813225827]
[0.29051399411566703]
[step = 10000] loss: 0.288
[step = 20000] loss: 0.288
[step = 30000] loss: 0.289
[step = 40000] loss: 0.289
[step = 50000] loss: 0.289
[step = 60000] loss: 0.289
[step = 70000] loss: 0.290
EPOCH = 2, loss = 0.290, hr = 0.571, ndcg = 0.322
[step = 10000] loss: 0.288
[step = 20000] loss: 0.288
[step = 30000] loss: 0.289
[step = 40000] loss: 0.289
[step = 50000] loss: 0.289
[step = 60000] loss: 0.289
[step = 70000] loss: 0.289
EPOCH = 3, loss = 0.289, hr = 0.573, ndcg = 0.321
[step = 10000] loss: 0.287
[step = 20000] loss: 0.288
[step = 30000] loss: 0.288
[step = 40000] loss: 0.288
[step = 50000] loss: 0.289
[step = 60000] loss: 0.289
[step = 70000] loss: 0.289
EPOCH = 4, loss = 0.289, hr = 0.575, ndcg = 0.324
[step = 10000] loss: 0.287
[step = 20000] loss: 0.287
[step = 30000] loss: 0.288
[step = 40000] loss: 0.288
[step = 50000] loss: 0.288
[step = 60000] loss: 0.288
[step = 70000] loss: 0.288
EPOCH = 5, loss = 0.288, hr = 0.577, ndcg = 0.324
[step = 10000] loss: 0.287
[step = 20000] loss: 0.287
[step = 30000] loss: 0.288
[step = 40000] loss: 0.288
[step = 50000] loss: 0.288
[step = 60000] loss: 0.288
[step = 70000] loss: 0.288
EPOCH = 6, loss = 0.288, hr = 0.575, ndcg = 0.325
[step = 10000] loss: 0.285
[step = 20000] loss: 0.286
[step = 30000] loss: 0.286
[step = 40000] loss: 0.287
[step = 50000] loss: 0.287
[step = 60000] loss: 0.287
[step = 70000] loss: 0.287
EPOCH = 7, loss = 0.288, hr = 0.578, ndcg = 0.326
[0.578476821192053]
[0.3256224358082742]
[0.2875433361290872]
[step = 10000] loss: 0.286
[step = 20000] loss: 0.286
[step = 30000] loss: 0.286
[step = 40000] loss: 0.287
[step = 50000] loss: 0.287
[step = 60000] loss: 0.287
[step = 70000] loss: 0.287
EPOCH = 8, loss = 0.287, hr = 0.577, ndcg = 0.324
[step = 10000] loss: 0.285
[step = 20000] loss: 0.285
[step = 30000] loss: 0.286
[step = 40000] loss: 0.286
[step = 50000] loss: 0.286
[step = 60000] loss: 0.287
[step = 70000] loss: 0.287
EPOCH = 9, loss = 0.287, hr = 0.575, ndcg = 0.325
[]
[]
[]
[step = 10000] loss: 0.285
[step = 20000] loss: 0.286
[step = 30000] loss: 0.286
[step = 40000] loss: 0.286
[step = 50000] loss: 0.286
[step = 60000] loss: 0.286
[step = 70000] loss: 0.286
EPOCH = 10, loss = 0.286, hr = 0.577, ndcg = 0.326
[]
[]
[]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.285
[step = 30000] loss: 0.285
[step = 40000] loss: 0.285
[step = 50000] loss: 0.286
[step = 60000] loss: 0.286
[step = 70000] loss: 0.286
EPOCH = 11, loss = 0.286, hr = 0.577, ndcg = 0.323
[]
[]
[]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.284
[step = 30000] loss: 0.284
[step = 40000] loss: 0.284
[step = 50000] loss: 0.285
[step = 60000] loss: 0.285
[step = 70000] loss: 0.286
EPOCH = 12, loss = 0.286, hr = 0.584, ndcg = 0.331
[0.5839403973509933]
[0.3306596866817331]
[0.2857730609305933]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.284
[step = 30000] loss: 0.284
[step = 40000] loss: 0.285
[step = 50000] loss: 0.285
[step = 60000] loss: 0.285
[step = 70000] loss: 0.285
EPOCH = 13, loss = 0.286, hr = 0.579, ndcg = 0.325
[]
[]
[]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.284
[step = 30000] loss: 0.284
[step = 40000] loss: 0.284
[step = 50000] loss: 0.285
[step = 60000] loss: 0.285
[step = 70000] loss: 0.285
EPOCH = 14, loss = 0.285, hr = 0.585, ndcg = 0.329
[0.5846026490066225]
[0.32850985491245704]
[0.28524806334910374]
[step = 10000] loss: 0.283
[step = 20000] loss: 0.283
[step = 30000] loss: 0.283
[step = 40000] loss: 0.284
[step = 50000] loss: 0.284
[step = 60000] loss: 0.285
[step = 70000] loss: 0.285
EPOCH = 15, loss = 0.285, hr = 0.576, ndcg = 0.323
[]
[]
[]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.284
[step = 30000] loss: 0.284
[step = 40000] loss: 0.284
[step = 50000] loss: 0.284
[step = 60000] loss: 0.285
[step = 70000] loss: 0.285
EPOCH = 16, loss = 0.285, hr = 0.581, ndcg = 0.327
[]
[]
[]
[step = 10000] loss: 0.283
[step = 20000] loss: 0.283
[step = 30000] loss: 0.283
[step = 40000] loss: 0.284
[step = 50000] loss: 0.284
[step = 60000] loss: 0.284
[step = 70000] loss: 0.284
EPOCH = 17, loss = 0.285, hr = 0.584, ndcg = 0.328
[]
[]
[]
[step = 10000] loss: 0.284
[step = 20000] loss: 0.284
[step = 30000] loss: 0.284
[step = 40000] loss: 0.284
[step = 50000] loss: 0.284
[step = 60000] loss: 0.284
[step = 70000] loss: 0.284
EPOCH = 18, loss = 0.285, hr = 0.580, ndcg = 0.324
[]
[]
[]
[step = 10000] loss: 0.283
[step = 20000] loss: 0.283
[step = 30000] loss: 0.284
[step = 40000] loss: 0.284
[step = 50000] loss: 0.284
[step = 60000] loss: 0.284
[step = 70000] loss: 0.284
EPOCH = 19, loss = 0.284, hr = 0.582, ndcg = 0.327
Finished Training...
GMF+MLP模型
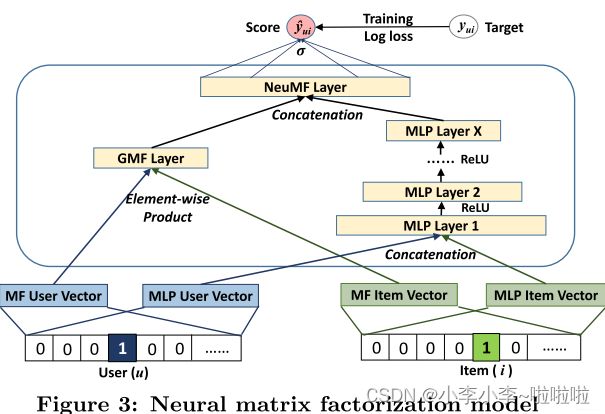
这个模型非常好理解了
个人的理解的区别为
- .Embedding层:把输入的User 和Item 进行MF向量的Embedding 和MLP的Embedding
- 然后将MF的Embedding向量进行点积操作 ,将MLP的EMbedding进行合并然后将合并的向量送入多层神经网络中。
- 最后将点积的MF向量 和多层神经网络输出的向量进行合并 最后将合并之后的向量输入到线性层中进行预测
代码如下:
import datetime
import numpy as np
import pandas as pd
from collections import Counter
import heapq
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import warnings
warnings.filterwarnings('ignore')
from torchsummary import summary
# 一些超参数设置
topK = 10
num_factors = 8
num_negatives = 4
batch_size = 64
lr = 0.001
# 数据在processed Data里面
train = np.load('ProcessedData/train.npy', allow_pickle=True).tolist()
testRatings = np.load('ProcessedData/testRatings.npy').tolist()
testNegatives = np.load('ProcessedData/testNegatives.npy').tolist()
# 制作数据 用户打过分的为正样本, 用户没打分的为负样本, 负样本这里采用的采样的方式
def get_train_instances(train, num_negatives):
user_input, item_input, labels = [], [], []
num_items = train.shape[1]
for (u, i) in train.keys(): # train.keys()是打分的用户和商品
# positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
# negative instance
for t in range(num_negatives):
j = np.random.randint(num_items)
while (u, j) in train:
j = np.random.randint(num_items)
#print(u, j)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input, item_input, labels
user_input, item_input, labels = get_train_instances(train, num_negatives)
train_x = np.vstack([user_input, item_input]).T
labels = np.array(labels)
# 构建成Dataset和DataLoader
train_dataset = TensorDataset(torch.tensor(train_x), torch.tensor(labels).float())
dl_train = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
class NeuralMF(nn.Module):
def __init__(self,num_users,num_items,mf_embed_dim,layers):
super(NeuralMF,self).__init__()
#Embedding 层
self.MF_Embedding_User=nn.Embedding(num_embeddings=num_users,embedding_dim=mf_embed_dim)
self.MF_Embedding_Item=nn.Embedding(num_embeddings=num_items,embedding_dim=mf_embed_dim)
self.MLP_Embedding_User=nn.Embedding(num_embeddings=num_users,embedding_dim=layers[0]//2)
self.MLP_Embedding_Item=nn.Embedding(num_embeddings=num_items,embedding_dim=layers[0]//2)
#全连接层
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(layers[:-1], layers[1:]))])
self.linear = nn.Linear(layers[-1], mf_embed_dim)
#线性层
self.linear2=nn.Linear(2*mf_embed_dim,1)
self.sigmod=nn.Sigmoid()
def forward(self,inputs):
inputs=inputs.long()
MF_Embedding_User=self.MF_Embedding_User(inputs[:,0])
MF_Embedding_Item=self.MF_Embedding_Item(inputs[:,1])
MF_vec=torch.mul(MF_Embedding_User,MF_Embedding_Item)
MLP_Embedding_User=self.MLP_Embedding_User(inputs[:,0])
MLP_Embedding_Item=self.MLP_Embedding_Item(inputs[:,1])
#将向量进行拼接后然后将其送入到全连接层
x=torch.cat([MLP_Embedding_User,MLP_Embedding_Item],dim=-1)
for linear in self.dnn_network:
x=linear(x)
x=F.relu(x)
MLP_vec=self.linear(x)
#将两个合并
vector=torch.cat([MF_vec,MLP_vec],dim=-1)
#预测层 线性层
linear=self.linear2(vector)
output=self.sigmod(linear)
output=output.squeeze(-1)
return output
num_users,num_items=train.shape
## 设置
layers = [num_factors*2, 64, 32, 16]
model = NeuralMF(num_users, num_items, num_factors, layers)
# Global variables that are shared across processes
_model = None
_testRatings = None
_testNegatives = None
_K = None
# HitRation
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
# NDCG
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return np.log(2) / np.log(i+2)
return 0
def eval_one_rating(idx): # 一次评分预测
rating = _testRatings[idx]
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
items.append(gtItem)
# Get prediction scores
map_item_score = {}
users = np.full(len(items), u, dtype='int32')
test_data = torch.tensor(np.vstack([users, np.array(items)]).T)
predictions = _model(test_data)
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i].data.numpy()
items.pop()
# Evaluate top rank list
ranklist = heapq.nlargest(_K, map_item_score, key=lambda k: map_item_score[k]) # heapq是堆排序算法, 取前K个
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return hr, ndcg
def evaluate_model(model, testRatings, testNegatives, K):
"""
Evaluate the performance (Hit_Ratio, NDCG) of top-K recommendation
Return: score of each test rating.
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testNegatives = testNegatives
_testRatings = testRatings
_K = K
hits, ndcgs = [], []
for idx in range(len(_testRatings)):
(hr, ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return hits, ndcgs
# 训练参数设置
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=model.parameters(), lr=lr)
# 计算出初始的评估
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
print('Init: HR=%.4f, NDCG=%.4f' %(hr, ndcg))
# 模型训练
best_hr, best_ndcg, best_iter = hr, ndcg, -1
print('start training....')
epochs = 20
log_step_freq = 10000
for epoch in range(epochs):
# 训练阶段
model.train()
loss_sum = 0.0
for step, (features, labels) in enumerate(dl_train, 1):
features, labels = features, labels
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = model(features)
loss = loss_func(predictions, labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
if step % log_step_freq == 0:
print(("[step = %d] loss: %.3f") % (step, loss_sum/step))
# 验证阶段
model.eval()
hr_list=[]
ndcg_list=[]
loss_list=[]
(hits, ndcgs) = evaluate_model(model, testRatings, testNegatives, topK)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
if hr > best_hr:
best_hr, best_ndcg, best_iter = hr, ndcg, epoch
hr_list.append(hr)
ndcg_list.append(ndcg)
loss_list.append(loss_sum/step)
torch.save(model.state_dict(), 'Pre_train/m1-1m_MLP.pkl')
info = (epoch, loss_sum/step, hr, ndcg)
print(("\nEPOCH = %d, loss = %.3f, hr = %.3f, ndcg = %.3f") %info)
print(hr_list)
print(ndcg_list)
print(loss_list)
print('Finished Training...')
训练结果
start training....
[step = 10000] loss: 0.371
[step = 20000] loss: 0.368
[step = 30000] loss: 0.366
[step = 40000] loss: 0.364
[step = 50000] loss: 0.364
[step = 60000] loss: 0.363
[step = 70000] loss: 0.362
EPOCH = 0, loss = 0.362, hr = 0.446, ndcg = 0.247
[0.4461920529801324]
[0.24665692194874442]
[0.3615081424313008]
[step = 10000] loss: 0.356
[step = 20000] loss: 0.355
[step = 30000] loss: 0.355
[step = 40000] loss: 0.354
[step = 50000] loss: 0.354
[step = 60000] loss: 0.354
[step = 70000] loss: 0.354
EPOCH = 1, loss = 0.354, hr = 0.450, ndcg = 0.251
[0.45049668874172183]
[0.25060382488628974]
[0.35396337600438554]
[step = 10000] loss: 0.350
[step = 20000] loss: 0.350
[step = 30000] loss: 0.351
[step = 40000] loss: 0.351
[step = 50000] loss: 0.350
[step = 60000] loss: 0.350
[step = 70000] loss: 0.349
EPOCH = 2, loss = 0.348, hr = 0.472, ndcg = 0.258
[0.47218543046357614]
[0.2581062288833335]
[0.3481580679601909]
[step = 10000] loss: 0.335
[step = 20000] loss: 0.334
[step = 30000] loss: 0.333
[step = 40000] loss: 0.331
[step = 50000] loss: 0.330
[step = 60000] loss: 0.328
[step = 70000] loss: 0.326
EPOCH = 3, loss = 0.325, hr = 0.502, ndcg = 0.278
[0.5024834437086093]
[0.27812582380637824]
[0.325182699872265]
[step = 10000] loss: 0.306
[step = 20000] loss: 0.305
[step = 30000] loss: 0.304
[step = 40000] loss: 0.303
[step = 50000] loss: 0.303
[step = 60000] loss: 0.302
[step = 70000] loss: 0.301
EPOCH = 4, loss = 0.301, hr = 0.541, ndcg = 0.301
[0.5408940397350993]
[0.301453770482002]
[0.30071208906625324]
[step = 10000] loss: 0.288
[step = 20000] loss: 0.288
[step = 30000] loss: 0.287
[step = 40000] loss: 0.287
[step = 50000] loss: 0.287
[step = 60000] loss: 0.287
[step = 70000] loss: 0.287
EPOCH = 5, loss = 0.287, hr = 0.569, ndcg = 0.320
[0.5690397350993377]
[0.3197982144366359]
[0.28653216629144124]
[step = 10000] loss: 0.278
[step = 20000] loss: 0.278
[step = 30000] loss: 0.278
[step = 40000] loss: 0.278
[step = 50000] loss: 0.278
[step = 60000] loss: 0.278
[step = 70000] loss: 0.278
EPOCH = 6, loss = 0.278, hr = 0.591, ndcg = 0.333
[0.5913907284768212]
[0.3329951807529053]
[0.2780010957392207]
[step = 10000] loss: 0.270
[step = 20000] loss: 0.272
[step = 30000] loss: 0.272
[step = 40000] loss: 0.272
[step = 50000] loss: 0.272
[step = 60000] loss: 0.273
[step = 70000] loss: 0.273
EPOCH = 7, loss = 0.273, hr = 0.600, ndcg = 0.341
[0.5996688741721854]
[0.3412463814496145]
[0.2726059490596333]
[step = 10000] loss: 0.268
[step = 20000] loss: 0.268
[step = 30000] loss: 0.268
[step = 40000] loss: 0.268
[step = 50000] loss: 0.269
[step = 60000] loss: 0.269
[step = 70000] loss: 0.269
EPOCH = 8, loss = 0.269, hr = 0.610, ndcg = 0.346
[0.6099337748344371]
[0.3455881971393328]
[0.2691765811218056]
[step = 10000] loss: 0.264
[step = 20000] loss: 0.265
[step = 30000] loss: 0.266
[step = 40000] loss: 0.266
[step = 50000] loss: 0.266
[step = 60000] loss: 0.267
[step = 70000] loss: 0.267
EPOCH = 9, loss = 0.267, hr = 0.614, ndcg = 0.349
[0.6142384105960265]
[0.3488014429028774]
[0.2670171557082331]
[step = 10000] loss: 0.262
[step = 20000] loss: 0.263
[step = 30000] loss: 0.264
[step = 40000] loss: 0.264
[step = 50000] loss: 0.265
[step = 60000] loss: 0.265
[step = 70000] loss: 0.265
EPOCH = 10, loss = 0.266, hr = 0.615, ndcg = 0.352
[0.614569536423841]
[0.3520316801750179]
[0.2655882040162689]
[step = 10000] loss: 0.261
[step = 20000] loss: 0.262
[step = 30000] loss: 0.263
[step = 40000] loss: 0.263
[step = 50000] loss: 0.264
[step = 60000] loss: 0.265
[step = 70000] loss: 0.265
EPOCH = 11, loss = 0.265, hr = 0.616, ndcg = 0.354
[0.615728476821192]
[0.3540029758631938]
[0.2647231956259677]
[step = 10000] loss: 0.261
[step = 20000] loss: 0.262
[step = 30000] loss: 0.263
[step = 40000] loss: 0.263
[step = 50000] loss: 0.264
[step = 60000] loss: 0.264
[step = 70000] loss: 0.264
EPOCH = 12, loss = 0.264, hr = 0.618, ndcg = 0.353
[0.6175496688741722]
[0.35274068000467834]
[0.26397280253223415]
[step = 10000] loss: 0.260
[step = 20000] loss: 0.261
[step = 30000] loss: 0.261
[step = 40000] loss: 0.262
[step = 50000] loss: 0.262
[step = 60000] loss: 0.262
[step = 70000] loss: 0.263
EPOCH = 13, loss = 0.263, hr = 0.622, ndcg = 0.357
[0.6218543046357616]
[0.35705638777070575]
[0.2628108871733074]
[step = 10000] loss: 0.260
[step = 20000] loss: 0.260
[step = 30000] loss: 0.261
[step = 40000] loss: 0.261
[step = 50000] loss: 0.261
[step = 60000] loss: 0.262
[step = 70000] loss: 0.262
EPOCH = 14, loss = 0.262, hr = 0.627, ndcg = 0.359
[0.6271523178807947]
[0.3586146519427854]
[0.262244005493884]
[step = 10000] loss: 0.257
[step = 20000] loss: 0.259
[step = 30000] loss: 0.260
[step = 40000] loss: 0.261
[step = 50000] loss: 0.261
[step = 60000] loss: 0.261
[step = 70000] loss: 0.262
EPOCH = 15, loss = 0.262, hr = 0.631, ndcg = 0.362
[0.6307947019867549]
[0.3624748399043986]
[0.261853505862301]
[step = 10000] loss: 0.259
[step = 20000] loss: 0.260
[step = 30000] loss: 0.260
[step = 40000] loss: 0.261
[step = 50000] loss: 0.261
[step = 60000] loss: 0.261
[step = 70000] loss: 0.261
EPOCH = 16, loss = 0.262, hr = 0.625, ndcg = 0.358
[step = 10000] loss: 0.260
[step = 20000] loss: 0.259
[step = 30000] loss: 0.261
[step = 40000] loss: 0.261
[step = 50000] loss: 0.261
[step = 60000] loss: 0.261
[step = 70000] loss: 0.262
EPOCH = 17, loss = 0.262, hr = 0.624, ndcg = 0.357
[]
[]
[]
[step = 10000] loss: 0.259
[step = 20000] loss: 0.260
[step = 30000] loss: 0.261
[step = 40000] loss: 0.261
[step = 50000] loss: 0.261
[step = 60000] loss: 0.261
[step = 70000] loss: 0.262
EPOCH = 18, loss = 0.262, hr = 0.629, ndcg = 0.359
[step = 10000] loss: 0.260
[step = 20000] loss: 0.260
[step = 30000] loss: 0.261
[step = 40000] loss: 0.261
[step = 50000] loss: 0.262
[step = 60000] loss: 0.262
[step = 70000] loss: 0.262
EPOCH = 19, loss = 0.262, hr = 0.632, ndcg = 0.360
*从训练的结果来看 GMF+MLP的结果是比GMF 和MLP好的
*
NCF的局限性:仅仅是引入了用户ID向量和物品ID向量 但是在数据集中还有很多有价值的信息。