机器学习-40-GAN-07-Feature Extraction(InfoGAN,VAE-GAN,BiGAN,Feature Disentangle(Voice Conversion))
文章目录
-
- Feature Extraction
-
- InfoGAN
-
- 问题引出
- What is InfoGAN?
- 结果
- VAE-GAN
-
- VAE-GAN
- Algorithm
- BiGAN
-
- BiGAN
- Algorithm
- BiGAN架构设计解析
- Triple GAN
- Domain-adversarial training
- Voice Conversion(声音转换)
- Feature Disentangle(特征解耦)
Feature Extraction
本节主要介绍InfoGAN,VAE-GAN,BiGAN和Triple GAN,可以用于做feature extraction。还介绍了Domain-adversarial training,Voice Conversion(声音转换)以及Feature Disentangle(特征解耦)。
InfoGAN
问题引出
我们知道最基本的GAN就是输入一个随机的向量,输出一个图片。以手写数字为例,我们希望修改随机向量的某一维,能改变数字的特想,比如角度,粗细,数字等,但是实际上貌似没什么大的影响。下图就是个例子,每一行的每一列都是改变了某一个维度,然后得到的结果,貌似看不到某一维度的具体含义,比如我们并不知道为什么第三行第六列为什么会突然多一个小尾巴。如下图:

我们可能直观的会认为每个维度应该就是一个特征,分布可能是这样的:
不同颜色代表不同特征的分布,在蓝色块中的vector作为input的时候,我们希望会输出蓝色的特征;在绿色块中的vector作为input的时候,我们希望会输出绿色的特征。这里我们假设input的vector只有两维(x,y),我们期待某种特征的分布是有规律性的,当我们改变某一维度,我们希望它对应的某种特征会发生改变,比如图中的y的值,我们希望改变y的值,它output的特征会从蓝色变为绿色或者是其它颜色。
如果真这样话就方便了,但是实际上或许是这样的分布:

很蛋疼的分布,很难区分不同维度表示的特征。我们如果像上面一样单纯的改变某一个维度,它output的特征可能并不能达到我们想要的效果!
那怎么用他变成我们想象中的分布呢,可以使用InfoGAN。
What is InfoGAN?
下面是InfoGAN的架构:
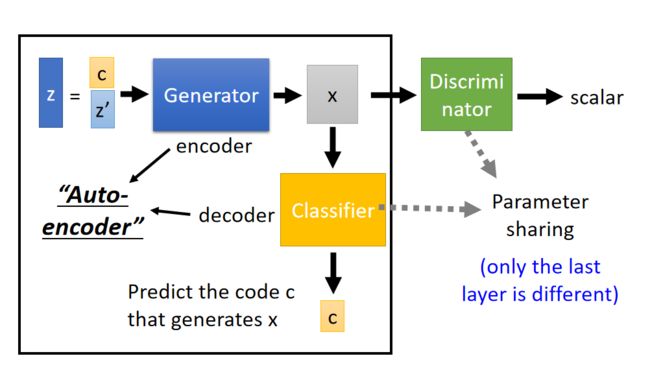
上面与就是传统的GAN,差别是输入z可以视为两部分组成: c 和 z ′ c和z' c和z′
这里可以把Generator看做是encoder,分类器Classifier看做是decoder,两个组成一个“autoencoder”,这里的autoencoder是带引号的,因为原来我们学过的autoencoder是将图片经过encoder变成编码,然后再把编码经过decoder变回图片。这里是将编码经过encoder变成图片,然后再把图片经过decoder变回编码。
当然,模型中还要有Discriminator,不然就不叫GAN了。
如果没有Discriminator,Generator为了让Classifer辨识出c ,直接就可以把c 贴到x中,这样根本就没有训练到。所以加上Discriminator可以让输出的图片像真实图片。
在实作上由于Classifier和Discriminator都是吃同样的参数,除了最后一层不同。所以,它们两个通常会share参数,只不过一个输出的是code,一个是scalar。
那么为什么加了Classifier可以work?为什么可以解决input features不明确的问题?
因为只有在训练Generator的过程中,学习到了c影响x的关系,Classifier才能正确的从x中分辨出c来。
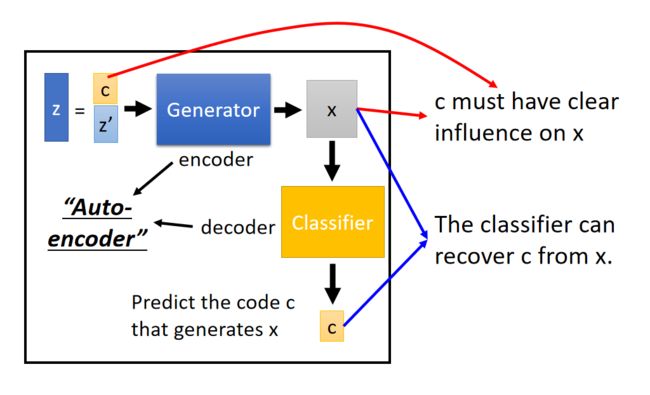
在图中我们看到还有一个 z ′ z' z′,这个东西代表一些随机的东西,就是我们也不知道这些东西影响输出的那些方面。
这里的c不是预先划分好的,而是应为我们设置了c,才训练出c影响了那些特征。这种思路就使得c与x的某些特征有了对应关系,并不是c本身就指定了x的某些特征,而是这种架构的设计,使得c与x的某些特征存在了关系。
结果
感兴趣的可以去看一下这篇paper

- (a):修改第一维,会发现数字发生了变化
- (b):修改原先的GAN中的第一维,基本没有什么变化
- ©:修改第二维,数字的角度发生变化
- (d):修改第三维,笔画的粗细发生变化
VAE-GAN
VAE-GAN
Anders Boesen, Lindbo Larsen, Søren Kaae Sønderby, Hugo Larochelle, Ole Winther, “Autoencoding beyond pixels using a learned similarity metric”, ICML. 2016
顾名思义是VAE和GAN的结合体,可以说用GAN来强化VAE,也可以说用VAE来强化GAN,毕竟双方都有缺点,互补好呀。
从VAE的角度来看:如果只是VAE追求输入x和decoder还原的x之间的reconstruction error的最小化,那么得到结果是不真实的(很模糊),因为他的其中的一个目的是输入和输出最小差异,所以可能会有很多像素为了差异最小,取了平均值,所以看起来就会模糊。那么加上Discriminator之后,可以促使生成的图片更加接近真实图片(否则不能通过Discriminator的分辨)。但VAE训练可以得到一个良好结构的潜在空间(连续性、低维度),其中任意点都可以被映射为一张逼真的图像。
从GAN的角度来看:Generator是看过真实的图片,并且要以还原真实图片为目标的,逼着生成器去生成清晰的图片。但它并不单单是想要骗过Discriminator这么简单,而且它的潜在空间可能没有良好结构,所以加了VAE的GAN会比较稳。

-
前半部分是一个VAE:数据集中图像向量 x x x通过编码器得到低维向量 z z z,再通过解码器还原为 x x x。训练中要让还原尽可能接近,但对于图像向量 x x x,单纯的VAE会导致生成的图像是模糊的;
-
后半部分是一个GAN:生成器从向量 z z z产生图像 x x x,再由判别器进行真假判断;
-
VAE GAN将两者结合在一起,共用解码器/生成器,实现图像的生成。在该结构的训练中,判别器提供了图像真假的限制,使得VAE的重建能产生更清晰/真实的图像;而VAE中得到的 z z z使得生成器的输入不仅仅是完全随机的向量,而是由真实图像编码得到的,相当于多了一个监督信息(原本生成器是看不到真实图像的,只能通过判别器的输出来学习产生图像,而判别器的输出只是一个标量,用来指导高维向量的生成是很艰难的),因此在VAE的重建作用下生成器产生的向量 x x x会更符合图像的结构。
对于VAE GAN,其中三个组件的训练的目标如下:
| Encoder | Generator(Decoder) | Discriminator |
|---|---|---|
| ➢Minimize reconstruction error ➢z close to normal |
➢ Minimize reconstruction error ➢ Cheat discriminator |
➢ Discriminate real, generated and reconstructed images |
- 编码器要minimize重建误差,同时令 z z z接近正太分布(因为GAN中的z就是从正态分布中取样的
- 解码器/生成器同时也要minimize重建误差,并且使得重建图像骗过判别器(让判别器给高分);
- 判别器需要分辨真实图像,生成图像和重建图像(对判别器来说,重建图像也是假的)
具体算法看下面吧!
Algorithm

-
初始化 E n En En(Encoder), D n Dn Dn(Decoder/Generator), D i s Dis Dis(Discriminator)
-
迭代进行:
-
从数据库中随机抽取M个真实样本 { x 1 , x 2 , . . . x M } \{x^1,x^2,...x^M\} {x1,x2,...xM}
-
利用Encoder生成M个code { z ~ 1 , z ~ 2 , . . . , z ~ M } \{\tilde{z}^1,\tilde{z}^2,...,\tilde{z}^M\} {z~1,z~2,...,z~M}
z ~ i = E n ( x i ) \tilde{z}^i = En(x^i) z~i=En(xi) -
利用Decoder生成M个图像 { x ~ 1 , x ~ 2 , . . . , x ~ M } \{\tilde{x}^1,\tilde{x}^2,...,\tilde{x}^M\} {x~1,x~2,...,x~M}
x ~ i = D e ( z ~ i ) \tilde{x}^i = De(\tilde{z}^i) x~i=De(z~i) -
从一个先验分布 P ( z ) P(z) P(z)中抽样M个code { z 1 , z 2 , . . . , z M } \{z^1,z^2,...,z^M\} {z1,z2,...,zM}
-
将这些随机抽样的code利用Decoder生成M个图像 { x ^ 1 , x ^ 2 , . . . , x ^ M } \{\hat{x}^1,\hat{x}^2,...,\hat{x}^M\} {x^1,x^2,...,x^M}
x ^ i = D e ( z i ) \hat{x}^i = De(z^i) x^i=De(zi) -
通过更新 E n En En来降低Reconstruction Error ∣ ∣ x ~ i − x i ∣ ∣ ||\tilde{x}^i-x^i|| ∣∣x~i−xi∣∣,且使 P ( z ) P(z) P(z)和 P ( x ~ i ∣ x i ) P(\tilde{x}^i|x^i) P(x~i∣xi) 越接近越好(即使 K L ( P ( x ~ i ∣ x i ) ∣ P ( z ) ) KL(P(\tilde{x}^i|x^i)|P(z)) KL(P(x~i∣xi)∣P(z))越小越好)
-
通过更新 D n Dn Dn来减低Reconstruction Error ∣ ∣ x ~ i − x i ∣ ∣ ||\tilde{x}^i-x^i|| ∣∣x~i−xi∣∣,且使 D i s ( x ~ i ) Dis(\tilde{x}^i) Dis(x~i)和 D i s ( x ^ i ) Dis(\hat{x}^i) Dis(x^i)越大越好
-
通过更新 D i s Dis Dis来是 D i s ( x i ) Dis(x^i) Dis(xi)越大越好,使 D i s ( x ~ i ) Dis(\tilde{x}^i) Dis(x~i)和 D i s ( x ^ i ) Dis(\hat{x}^i) Dis(x^i)越小越好
-
这里的Discriminator是二分类(区分真实和生成图片),还有一种做法是做成三分类的分类器,将reconstruction image和通过先验分布随机生成的image视为不同的类型:

BiGAN
BiGAN
BiGAN同样是在编码解码的基础上进行改动,不过编码器和解码器不再是串联的结构,如下图:

-
编码器输入真实图片向量,输出编码;
-
解码器输入随机编码向量,输出图像向量。
注意:上图中编码器和解码器对应的 z z z和 x x x是不同的。这样编码器和解码器其实并无关联,因此借用判别器:其输入是pairs,由图像向量和其对应的编码组成。把编码器和解码器中的 z z z和 x x x都组合起来输入,判别器分辨pairs来自于编码器还是解码器(两者差异性可能是:编码器的pairs中, x x x更符合图像向量的结构;解码器的pairs中, z z z更服从正态分布。但是判别器的输入是 z z z和 x x x啊,应该是会根据两者间的关系进行判别的。或许也可以尝试一下判别器分别判别 z z z或 x x x的效果。到这里,感觉判别器之前用来单纯判别 x x x,现在 判别 z z z和 x x x的pairs,能否用来判别 z z z或者其他东西呢?)。BiGAN的具体算法如下图:
Algorithm

-
初始化 E n En En(Encoder), D n Dn Dn(Decoder/Generator), D i s Dis Dis(Discriminator)
-
迭代进行:
-
从数据库中随机抽取M个真实样本 { x 1 , x 2 , . . . x M } \{x^1,x^2,...x^M\} {x1,x2,...xM}
-
利用Encoder生成M个code { z ~ 1 , z ~ 2 , . . . , z ~ M } \{\tilde{z}^1,\tilde{z}^2,...,\tilde{z}^M\} {z~1,z~2,...,z~M}
z ~ i = E n ( x i ) \tilde{z}^i = En(x^i) z~i=En(xi) -
从一个先验分布 P ( z ) P(z) P(z)中抽样M个code { z 1 , z 2 , . . . , z M } \{z^1,z^2,...,z^M\} {z1,z2,...,zM}
-
将这些随机抽样的code利用Decoder生成M个图像 { x ~ 1 , x ~ 2 , . . . , x ~ M } \{\tilde{x}^1,\tilde{x}^2,...,\tilde{x}^M\} {x~1,x~2,...,x~M}
x ~ i = D e ( z i ) \tilde{x}^i = De(z^i) x~i=De(zi) -
通过更新 D i s Dis Dis来使 D i s ( x i , z ~ i ) Dis(x^i,\tilde{z}^i) Dis(xi,z~i)越大越好,使 D i s ( x ~ i , z i ) Dis(\tilde{x}^i,z^i) Dis(x~i,zi)越小越好(这个高低分的选择应该是随意的,感觉这里的编码器和解码器其实都是生成器的作用,不过一个是生成高维向量,一个生成低维向量。不过难易程度有没有区别呢,比如从高维生成低维更容易些?这可不可以作为判别器给谁高分低分的依据呢?)
-
通过更新 E n , D e En,De En,De来使 D i s ( x i , z ~ i ) Dis(x^i,\tilde{z}^i) Dis(xi,z~i)越小越好,使 D i s ( x ~ i , z i ) Dis(\tilde{x}^i,z^i) Dis(x~i,zi)越大越好(为了骗过Discriminator)
-
BiGAN架构设计解析

那么BiGAN为什么如此设计呢?判别器的作用一直是用来找两个分布间的差异(真实图像和生成图像向量分布间的散度),在BiGAN中判别器的输入是来自两个地方(编码器和解码器)的pairs,就是在找这两个地方的pairs分别服从的分布间的差异,再让两者差异变小,分布逐渐接近(所谓的分布是pairs的分布,其实就是 x x x和对应的 z z z的联合分布)。
不过为什么要靠近这两个联合分布呢?每个联合分布中都有一个变量是假的(编码器中 z z z是假的,解码器中 x x x是假的),但是我们是没有真的 x x x和 z z z组成的pairs的,因为真实图像数据集和先验分布 z z z的采样是不对应的。所以这个靠近两个联合分布的过程是不是相当于间接地组成比较真实合理的配对( x x x, z z z)呢?合理的pairs其实 ( x , z ) (x,z) (x,z)就是好的生成器啊,就是GAN的目标。
课程中的解释:
靠近两个联合分布,达到最优状态时的编码器和解码器功能如下图:
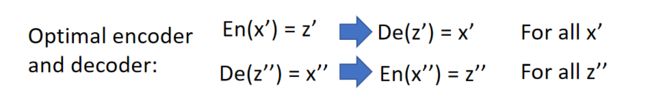
两者是完美的逆过程(训练中就相当于在训练一个"Auto-encoder",同时也训练其相反的结构,如下图左边所示),训练后就会得到一个完美的"Auto-encoder",那为什么不直接训练一个"Auto-encoder"呢?注意上面说的情况是达到最优状态时两者效果相当,即两者的全局最优值相同,如下图右边所示:

但是单纯的"Auto-encoder"在训练中是无法达到最优值的,所以这两种方法的结果是不一样的:仅利用"Auto-encoder"重建的图像总是模糊的,而且语义内容是不变的;但BiGAN产生的结果就是清晰而且内容不同的图像(这才有生成的意义)。
举个例子:VAE是输入一只鸟得到一只同样的模糊的鸟,而BiGAN输入一只鸟,得到另外一只鸟。
可不可以理解为:"Auto-encoder"训练只是找输入 x x x对应的 z z z,这个 z z z要能够最好地重建 x x x。所以这个 z z z只是根据输入 x x x产生的,完全依赖于该 x x x;而BiGAN中,编码解码分开,都加入了随机性(编码器中产生的 z z z是无限制的,解码器中产生的 x x x是没有真实图像限制的),随机性一定程度上是不是可以理解为“生成”。所以BiGAN既保留了随机性,又保证了编码解码的重建性。
Triple GAN
Chongxuan Li, Kun Xu, Jun Zhu, Bo Zhang, “Triple Generative Adversarial Nets”, arXiv 2017
Triple GAN结构如下图:
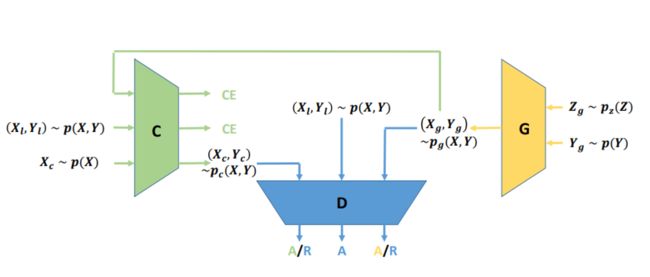
蓝色是Discriminator,黄色是Generator,绿色是Classifier。
如果不看Classifier,就是一个conditional GAN。输入一个vector,并且输入一个条件vector(比如:文字),按条件生成另外一个东西(图片)。
G吃一个vector Z g Z_g Zg和一个condition vector Y g Y_g Yg,然后产生一个 X g X_g Xg,把 ( X g , Y g ) (X_g,Y_g) (Xg,Yg)丢到Discriminator里面,D要分辨 ( X g , Y g ) (X_g,Y_g) (Xg,Yg)是生成数据,从数据库里面sample出来的数据是真实数据。
加了一个Classifier后,整个Triple GAN就是一个半监督学习(semi-supervisor learning)模型:少量的标记数据,大量的无标签数据,对应到Conditional GAN中就是少量图像有condition,即上图中的 p a i r s ( x , y ) pairs(x,y) pairs(x,y),大量数据无 y y y。可以看到Classifier可以学三部分的东西:
- ( X l , Y l ) ∼ p ( X , Y ) (X_l,Y_l)\sim p(X,Y) (Xl,Yl)∼p(X,Y):将少量的真实数据pairs用来训练分类器,使其学会给X分类,得到标签Y
- ( X g , Y g ) ∼ p g ( X , Y ) (X_g,Y_g)\sim p_g(X,Y) (Xg,Yg)∼pg(X,Y):生成器会从其输入的 p a i r ( Z , Y ) pair(Z,Y) pair(Z,Y)得到对应的 p a i r ( X , Y ) pair(X,Y) pair(X,Y),也可以作为训练集训练分类器,相当于扩从数据
- X c ∼ p ( X ) X_c\sim p(X) Xc∼p(X):只有X,而没有Y,通过分类器获取Y,得到一个 p a i r ( X , Y ) pair(X,Y) pair(X,Y)
通过这种办法,我们就可以获取大量的training data。然后判别器将判别 p a i r s ( x , y ) pairs(x,y) pairs(x,y) 来自于分类器,真实数据还是生成器。
Domain-adversarial training
Hana Ajakan, Pascal Germain, Hugo Larochelle, François Laviolette, Mario Marchand, Domain-Adversarial Training of Neural Networks, JMLR, 2016
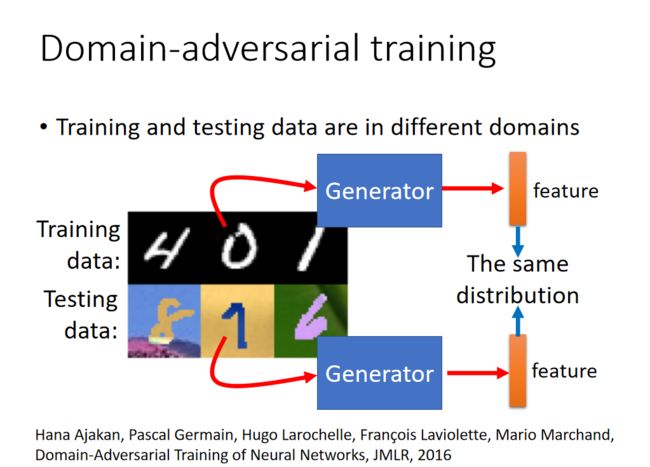
假设训练集中的数据和测试集数据属于不同的Domain(有一些差别),可能我们的模型预测效果就会不理想,如下图所示:

训练集图片是黑白的,然而测试集却是彩色的,可以作如下改进:
加入生成器,将训练集和测试集的图像通过生成器提取特征,让特征服从相同的分布(有点common space的感觉),整体结构如下图:

首先生成器(感觉在这里就是个编码器)对输入的图像提取特征,特征输入Domain classifier(其实也是判别器,我们的判别器其中一个作用就是找两个分布之间的差异,而我们要求通过生成器的特征分布尽量相同)对所属Domain进行判断,训练中要让其分类准确度越来越高,同时特征也输入Label predictor预测图片标签,训练中让标签预测越来越准确。
这样生成器就有两个目标:
- 提取出的特征要保证图像语义信息保留(Label predictor的准确性)
- 还要保证能够轻易区分出属于哪个Domain(Domain classifier的准确性)。
这里注意一下,虽然论文中是三个模块(network)一起train的,但是分开迭代train会比较稳(先训练Domain Classifer,再训练feature extractor)。
接下来的Feature Disentangle(特征解耦)就是基于这个技术来实现的
Voice Conversion(声音转换)
在将接下来的内容前,我们先来补充一点声音转换的知识。
声音转换,大家对这一项技术的起源应该都是柯南了,柯南拿着变声器然后发出毛利小五郎的声音。

声音转换注意两点,声音转换的输入端长度与输出段长度不一定是一致相等的,甚至在很多时候不相等更加好能会更好。第二点,声音转换都是基于图像形式的音频特征进行转换,也就是我们先将音频转化成为图像,然后对图像在进行端到端训练,所以我们输出的结果也是图像。 所以需要用Vocode的方式将输出的图像还原成为声音。
Vocode传统方法就是Griffin-Lim algorithm,深度学习的方法这里主要介绍WaveNet.
声音转换的方法,我们根据数据的分布可以分为2大类,一类是Parallel Data,另一类是Unparallel Data。 对于parallel data很直觉的做法就是端到端训练一个模型在进行测试。但是他会面对数据集难收集的问题。所以在实作中Unparallel Data是我们面临的比较多的。
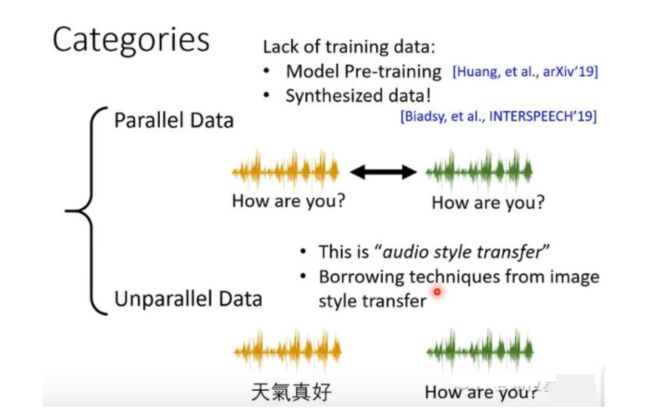
面对不平衡音频数据,进行处理的方法可以分为2类。第一类是特征分离(Feature Disentangle),第二类是直接转换( Direct Transformation)。特征分离很好理解就是我们要将声音进转化,我们将音频的特征先进行分离一种只保留语者说话腔调的讯息,一种只保留声音的语义的信息,然后我们如果要将A的声音转化成为B的声音我们只要把A的腔调改为B的腔调语义部分进保留。(当然也可以进行情绪的转化)最后通过解码器输出结果。

Direct Transformation:这种方法我们之前也有讲过,但是我们当时是用图像来进行举例的,虽然在文章的结尾我们也有提及。可以参考下面的三篇文章:
机器学习-37-Unsupervised Condition GAN(无监督的有条件GAN)
Voice Conversion——学习笔记
语音转换Voice Conversion —直接转换技术
Feature Disentangle(特征解耦):接下来会说
Feature Disentangle(特征解耦)
为了讲清楚这个东西,我们用语音为例,这个技术也可以用在图像处理等方面。
假设我们训练一个语音的AE,Original Seq2seq Auto-encoder

把一段声音信息压缩为code,在把code还原回声音信号。目标是input和ouput越接近越好。中间抽取出来的code我们希望它能够代表这段声音信息的特征,但是这个是不可能的,因为这一段声音信息还包含了其他信息,如:说话人的信息、环境的信息。
因此我们想要知道在这个code中那些维度代表了发音的信息,不包含其他信息。这里就是要用到Feature Disentangle的技术。
从字面上理解Disentangle是解开的意思,各种信息的特征交织打结在一起,要把它解开。这样我们就知道那些维度代表发音的信息,哪些维度代表语者的信息。
具体做法:
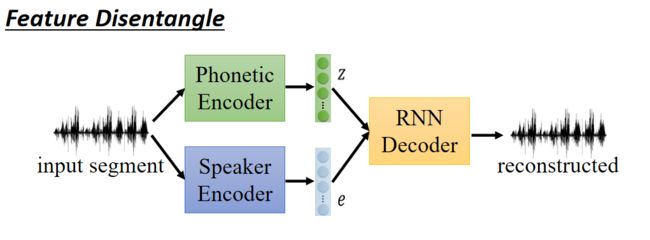
train两个Encoder,一个学习语音信息,一个学习语者信息。这样训练出来的语音Encoder可以处理与人无关的语音,直接提取出语音特征;训练出来的语者Encoder可以用来做为识别语者身份的声纹特征。
如何分布训练上面两个Encoder?
先看训练语者信息的Encoder,这个时候Assume that we know speaker ID of segments.
我们假设我们知道那些声音信号是来自同一个语者,这个很好弄,可以把同一个人说的话切开,变成几个小段语音,就得到同一个人说的不同语音。
如果两个语音来自相同的人(说的语音内容不一样,但是说话的人是同一个),我们希望下图中两个语者信息的Encoder的输出越接近越好:
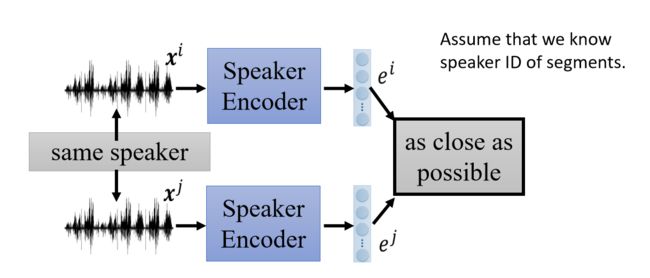
如果两个语音来自不同的人(说话的人不是同一个),我们希望下图中两个语者信息的Encoder的输出越不同越好(接近某个阈值):

但是上面的模型中Encoder得到的code也是可以包含语音信息的,不单单是语者信息。这里就要用到Domain-adversarial training
而对于Phonetic Encoder,那么可以通过引入一个Speaker Classifier来判断输入的两段音频是否是同一个人所讲的,而Phonetic Encoder的目标就是要使得编码得到的特征 z i 和 z j z^i和z^j zi和zj 可以尽可能的去迷惑Speaker Classifier,该Encoder的作用就相当于是Generator,而Speaker Classifier的作用就相当于是Discriminator,具体的结构如下所示:
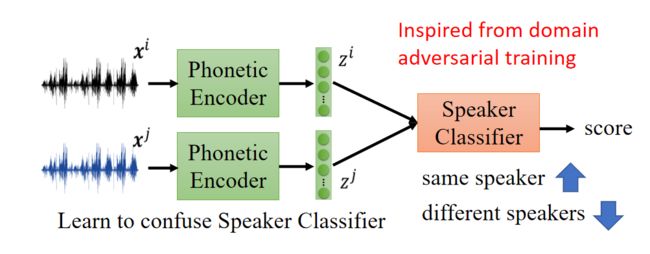
直观上的理解就是,Speaker Classifier要区分出不同的说话人,主要依靠的是说话人相关的特征信息,而Phonetic Encoder想要欺骗Speaker Classifer的话就需要使得编码的输出 z i 和 z j z^i和z^j zi和zj的分布尽可能接近,也就是说尽可能的滤掉语者信息而只保留发音的相关信息,以下的实验结果可以验证这个想法。
论文的结果如下图,左边两个是针对语音,右边两个是针对语者。
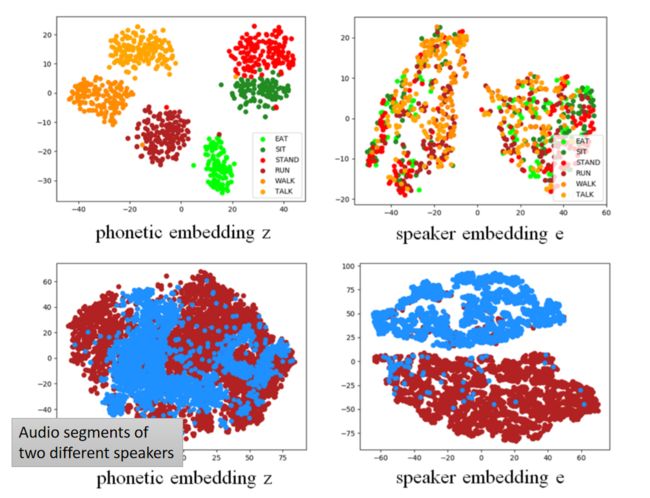
从图中的可视化结果可以看出Phonetic Encoder编码得到的embedding z z z ,可以将不同的词汇映射到空间中的不同位置,而Speaker Encoder编码得到的embedding e e e 则可以将不同的Speaker映射到空间中的不同位置,刚好印证了最初的设计想法,通过特殊的训练方法使得不同的Encoder注重不用的类型的Feature。