论文速读系列一:VoteNet、CBGS、BirdNet、StarNet、STD
如有错误,恳请指出。
参考网上资料,对一些经典论文进行快速思路整理
文章目录
- 1. VoteNet
- 2. CBGS
- 3. BirdNet
- 4. StarNet
- 5. STD
参考网上资料,对一些经典论文进行快速思路整理
1. VoteNet
paper:《Deep Hough Voting for 3D Object Detection in Point Clouds》
结构图:

思路:利用投票的思路先获取物体中心,再进行后续方向尺寸等信息预测
对于点云空间的每个点都可以预测其到某个物体中心的相对距离,这个相对距离可以通过标注信息获取进行有监督训练。那么如过某个区域的大部分点其预测的中心都比较接近,这个中心大概率是某个物体的中心。也就是说,如果某个区域大部分的点都能正确预测到中心点位置,那么投票过后少数服从多数,即可得到中心点。
具体来说,进行最远点采样得到的每个点都进行两个投票结果预测,分别是中心点到该点的偏移量以及中心点feature到该点的feature偏移量,有了预测的偏移量就可以计算出来每个店预测的中心点坐标以及中心点feature。之后,对这些点进行投票,获得K个投票结果(可能是通过聚类的方法实现),对于这些K个采样点进行半径为r的范围分区,通过PointNet网络对这些分区进行聚类,得到K个聚类feature,进行后续边界框尺寸、方向、置信度等信息预测。
VoteNet的流程其实有点类似Two-stage,先获得物体中心再进行pointnet聚合特征修正,与先获得proposal再进行roi聚合特征修正,有点类似。只是这里毕竟没有RPN网络,换一个角度来说就是隐式生成proposal进行优化。
参考资料:
1. VoteNet: Object Detection in Point Clouds ICCV2019
2. CBGS
paper:《Class-balanced Grouping and Sampling for Point Cloud 3D Object Detection》
结构图:
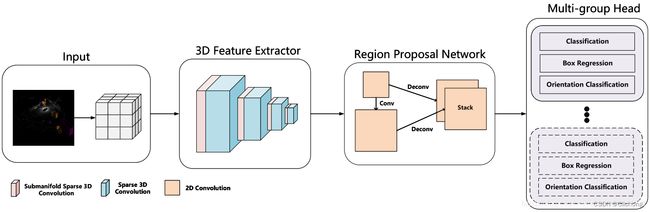
CBGS是一个Two-stage、Anchor-based的网络结构,主要为了解决NuSences数据集中类别不平衡的问题。提出了两种主要方案进行解决:
1)数据增强方面
DS-Sampling:基本思想是把占比较小的类别进行复制,制作出较大数据集,然后针对每个类别用固定比例random sample这个大的数据集,组合出最终数据集,最终数据集的类别密度(类别数量/样本总数)是相近的,这方法可以减缓样本不平均问题。
GT-AUG:将其他场景的GT放在当前场景中,前提是需要进行碰撞测试(这里换了个名字,本质上就是copypaste数据增强)
2)训练策略方面
Class-balanced Grouping:为了解决类別不均衡问题,作者提出Class Grouping的概念,简而言之,将相似形状的类別分成一个群(Group),让该群中样本数量较多的类去提升样本数量较少的类的精度,而每个Group之间的总数量也接近,如此一来,网络在学习时,就能够减缓数量较多类别有主导整个网络的问题。
这里的Group是手工进行区分,主要是透过样本中属于形状进行分组,而且Group之间的样本总数量是相近的。具体分组如下:
- cars (majority classes)
- truck, construction vehicle
- bus, trailer
- barrier
- motorcycle, bicycle
- pedestrian, traffic cone
参考资料:
- https://patrick-llgc.github.io/Learning-Deep-Learning/paper_notes/cbgs.html
- CBGS : 三维点云物体检测的类平衡分组和采样(新自动驾驶数据集nScenes第一名算法)
3. BirdNet
paper:《BirdNet: a 3D Object Detection Framework from LiDAR Information》
BirdNet主要是对点云在bev上的量化投影稍有不同,这里构建了三个通道,分别是:
1)cell内最高点高度(没有像MV3D那样对高度进行切分)
2)cell内所有点intensity的平均值
3)cell内所有点density进行归一化(这里与MV3D不同,对density除以全部cell中的最大值进行归一化),这里对density进行归一化的目的是改善density这个通道在不同线数激光雷达下剧烈变化的问题
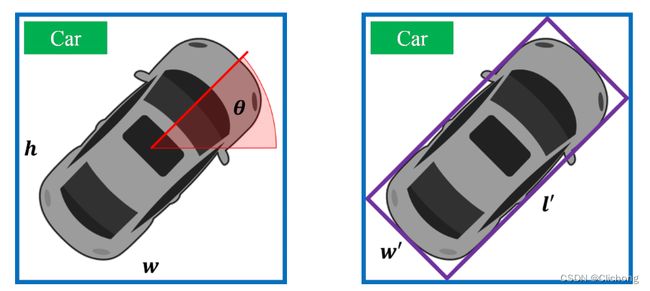
此外,BirdNet在后处理时预测的不是车辆的长和框,而是与坐标轴相平行的车辆外接矩形的外接矩形。然后通过固定每个类别的w,计算每个box的l。
参考资料:
1. BirdNet: a 3D Object Detection Framework from LiDAR Information
4. StarNet
paper:《StarNet: Targeted Computation for Object Detection in Point Clouds》
结构图:

StarNet是一个one-stage、anchor-based的网络,思路大致如下所示:
1)首选去除地面点,然后通过最远距离采样得到一些中心点
2)将这些中心点构建局部坐标,在半径R的领域内选取K个点,通过一些列堆叠的StarNet blocks网络进行特征聚合,得到一个384维的特征C
3)对于每个中心点周围放置GxG个anchor,每个anchor的特征是通过C编码成另外一个D维度的特征
4)每个anchor的D维特征与GT进行回归计算
参考资料:
1. StarNet: Targeted Computation for Object Detection in Point Clouds
5. STD
paper:《STD: Sparse-to-Dense 3D Object Detector for Point Cloud》
结构图:
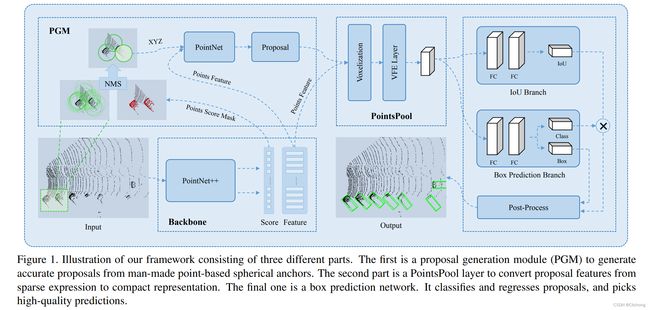
STD是一个Two-stage、改良的anchor-free网络。核心是提出了球状anchor。球状的anchor无需考虑anhcor方向上的设置,所有在数量上是priors anchor是成倍减少的,减少计算量。考虑到球状的anchor与GT的常规iou并不适用,所以辅助提出了PointIoU,用点的交集/点的并集进行一阶段anhcor的筛选。同时,STD可能受到2d检测的启发,在二阶段的proposal进行nms时,使用的是预测的class以及iou预测值的乘积分数(class*iou)来进行nms。
主要流程:
1)对每个点设置一个球状anchor(只需考虑半径,无需考虑方向以及尺寸),利用PointNet++提取点的语义特征以及类别预测,利用nms获取500个anchor。ps:这里的用什么进行nms没有具体说明,可能是每个点lable的score,但是这里我觉得是对每个球状anchor计算PointIoU来筛选。
2)对于获取的proposal中,利用每一个porposal中的点坐标信息(通过anchor中心位置进行归一化)以及语义特征,输入到PointNet网络中来进行类别分数预测以及回归偏移预测,利用class score以及bev iou的联合nms,获取得到300个proposal。这里所获得的proposal是一个特定大小的长方体。(这里以及利用球状的anchor聚合特征获取到了一个特定的proposal,那么就可以正常与3d标注框进行iou计算,那PointIoU是作用于哪一个步骤呢?所以我推测是用于上面的步骤1的)
也就是说,利用PointIoU筛选出500个球状anchor,再聚合每个球状anchor的信息进行proposal生成,利用bev上的iou进行二次nms筛选,最终一阶段获得300个proposal。
3)对proposal中的每个点以规范坐标(减去中心点坐标以及旋转对其)和语义信息作为初始特征,随后将proposal切分成6x6x6大小的subvoxel,对每个subvoxel采用35个点,对这些点特征进行聚合成256维度,最后说的的维度为:l x w x h x 256
4)对候选框的特征进行展平进行MLP处理,一个分支预测iou值;另一个分支预测类别(class)以及回归值(box),这里的iou乘上class score作为第二阶段的nms筛选指标。另外一种做法是将预测的候选框iou作为class的soft label进行预测处理。
损失部分:
1)RPN
semantic segmentation loss:使用focal loss
proposal prediction loss:两个部分,proposal classification loss采用softmax cross-entropy loss;regression loss采用smooth-l1 loss,其中方向采用bin-based的方法
2)Head
proposal prediction loss:与RPN部分一致
3D IoU loss:多了预测分支预测iou
corner loss:8个角损失,一个很好的正则化手段(很多工作常见,可以说是标配)
总结:
提取球形anchor进行特征点的聚集,又是既PartA2、VoxelRCNN之后对proposal体素化在特征聚集范围上的一个改进,同时提出了新的PointIoU的方法。在head上增加了iou分支,进行nms的筛选指标。作为了一个Point-Voxel-based的方法,同时利用了point-based与voxel-based的优势。
最后,这里如果对voxel化的候选框进行3d稀疏卷积编码处理(类似PartA2或者SECOND的Head结构),可能会进一步提升效果。
参考资料:
1.STD: Sparse-to-Dense 3D Object Detector for Point Cloud