9月12日OpenCV学习笔记——基于 Dlib 库的人脸检测
文章目录
- 前言
- 一、基于 Dlib 的人脸检测
-
- 1、From 图片
- 2、From 摄像头
- 二、基于 Dlib 库人脸关键点检测
-
- 1、From 图片
- 2、From 摄像头
- 三、基于 face_recognition 人脸关键点检测
- 四、基于 Dlib 库人脸跟踪
前言
本文为9月12日OpenCV学习笔记——基于 Dlib 库的人脸检测,分为四个章节:
- 基于 Dlib 的人脸检测;
- 基于 Dlib 库人脸关键点检测;
- 基于 face_recognition 人脸关键点检测;
- 基于 Dlib 库人脸跟踪。
一、基于 Dlib 的人脸检测
- Dlib: 深度学习开源工具,有很多训练好的人脸特征提取模型供开发者使用。
- HOG 方向梯度直方图(Histogram of Oriented Gradient):
- 是一种特征描述子,用于从图像数据中提取特征;
- 特征描述子的作用:图像的简化表示,仅包含有关图像的最重要信息。
1、From 图片
import cv2 as cv
import dlib
import numpy as np
import matplotlib.pyplot as plt
# 方法:显示图片
def show_image(image, title):
img_RGB = image[:, :, ::-1] # BGR to RGB
plt.title(title)
plt.imshow(img_RGB)
plt.axis("off")
# 方法:绘制人脸矩形框
def plot_rectangle(image, faces):
for face in faces:
cv.rectangle(image, (face.left(), face.top()), (face.right(), face.bottom()), (255, 0, 0), 4)
return image
# 主函数
def main():
# 读取一张图片
img = cv.imread("./family.jpg")
# 灰度转换
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 调用 Dlib 库中的检测器
detector = dlib.get_frontal_face_detector()
dets_result = detector(gray, 1) # 1: 代表将图片放大一倍
# 给检测出的人脸绘制矩形框
img_result = plot_rectangle(img.copy(), dets_result)
# 创建画布
plt.figure(figsize=(9, 6))
plt.suptitle("face detection with dlib", fontsize=14, fontweight="bold")
# 显示最终的检测效果
show_image(img_result, "Face Detection")
plt.show()
if __name__ == '__main__':
main()

2、From 摄像头
import cv2 as cv
import dlib
# 方法:绘制人脸矩形框
def plot_rectangle(image, faces):
for face in faces:
cv.rectangle(image, (face.left(), face.top()), (face.right(), face.bottom()), (255, 0, 0), 4)
return image
# 主函数
def main():
# 打开摄像头读取视频
capture = cv.VideoCapture(0)
# 判断摄像头是否正常工作
if capture.isOpened() is False:
print("Camera Error!")
# 读取每一帧
while True:
ret, frame = capture.read()
print(ret)
if ret:
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 调用 Dlib 库中的检测器
detector = dlib.get_frontal_face_detector()
dets_result = detector(gray, 1)
# 绘制检测结果
dets_image = plot_rectangle(frame, dets_result)
# 实时显示最终的检测效果
cv.imshow("Face Detection with dlib", dets_image)
# 按键 “ESC” 退出
if cv.waitKey(1) ==27:
break
# 释放资源
capture.release()
cv.destroyAllWindows()
if __name__ == '__main__':
main()
二、基于 Dlib 库人脸关键点检测
- 获取人脸检测器:
dlib.get_frontal_face_detector( ); - 预测人脸关键点:
dlib.shape_predictor( ).
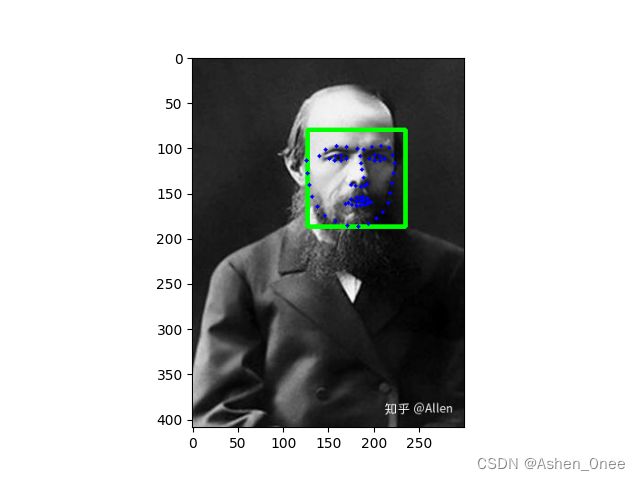
1、From 图片
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
import dlib
# 读取一张图片
img = cv.imread("Tors.jpg")
# 调用人脸检测器
detector = dlib.get_frontal_face_detector()
# 加载预测关键点模型(68 个关键点)
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
# 灰度转换
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 人脸检测
faces = detector(gray, 1) # 1: 放大 1倍;0:原始大小
# 循环,遍历每一张人脸,给人脸绘制矩形框和关键点
for face in faces: # 坐标:(x, y, w, h)
# 绘制矩形框
cv.rectangle(img, (face.left(), face.top()), (face.right(), face.bottom()), (0, 255, 0), 4)
# 预测关键点
shape = predictor(img, face)
# 获取关键点的坐标
for pt in shape.parts(): # 返回的是元组
# 获取横纵坐标
pt_position = (pt.x, pt.y)
# 绘制关键点
cv.circle(img, pt_position, 2, (0, 0, 255), -1)
# 显示整个效果
plt.imshow(img)
plt.show()
2、From 摄像头
import cv2 as cv
import dlib
# 打开摄像头
capture = cv.VideoCapture(0)
# 获取人脸检测器
detector = dlib.get_frontal_face_detector()
# 获取人脸关键点检测模型
predictor = dlib.shape_predictor("shape_predictor_68_face_landmarks.dat")
while True:
# 读取每一帧
ret, frame = capture.read()
# 灰度转换
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 人脸检测
faces = detector(gray, 1)
# 绘制每张人脸的矩形框和关键点
for face in faces:
# 绘制矩形框
cv.rectangle(frame, (face.left(), face.top()), (face.right(), face.bottom()), (0, 255, 0), 5)
# 检测关键点
shape = predictor(gray, face)
# 获取关键点的坐标
for pt in shape.parts():
# 每个点的坐标
pt_position = (pt.x, pt.y)
# 绘制关键点
cv.circle(frame, pt_position, 2, (255, 0, 0), -1)
if cv.waitKey(1) & 0xFF == ord("q"):
break
# 显示效果
cv.imshow("Face Detection Landmark", frame)
capture.release()
cv.destroyAllWindows()
三、基于 face_recognition 人脸关键点检测
- 最简单的人脸识别工具;
- 使用 Dlib 最先进的人脸识别技术构建而成,具有深度学习功能。
import cv2 as cv
import matplotlib.pyplot as plt
import face_recognition
# 方法:显示图片
def show_image(image, title):
plt.title(title)
plt.imshow(image)
plt.axis("off")
# 方法:绘制关键点
def show_landmarks(image, landmarks):
for landmarks_dict in landmarks:
for landmarks_key in landmarks_dict.keys():
for pt in landmarks_dict[landmarks_key]:
cv.circle(image, pt, 2, (0, 0, 255), -1)
return image
# 主函数
def main():
# 读取图片
img = cv.imread("Tors.jpg")
# 灰度转换
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 调用 face_recognition 中的方法:face_landmarks()
face_marks = face_recognition.face_landmarks(gray, None, "large") # "large":68 个点
# print(face_marks)
# 绘制关键点
img_result = show_landmarks(img, face_marks)
# 创建画布
plt.figure(figsize=(9, 6))
plt.suptitle("Face Landmarks with face_recognition", fontsize=14, fontweight="bold")
# 显示整体效果
show_image(img_result, "Landmarks")
plt.show()
if __name__ == '__main__':
main()

四、基于 Dlib 库人脸跟踪
- 补充功能:
- 保存视频:
frame_width = capture.get(cv.CAP_PROP_FRAME_WIDTH)
frame_height = capture.get(cv.CAP_PROP_FRAME_HEIGHT)
fps = capture.get(cv.CAP_PROP_FPS)
# 设置视频格式
fourcc = cv.VideoWriter_fourcc(*"XVID")
# 设置输出格式
output = cv.VideoWriter("./record.avi", fourcc, int(fps), (int(frame_width), int(frame_height)), True)
……
output.write(frame)
- 信息提示:
# 增加功能二:信息提示
def show_info(frame, tracking_state):
pos1 = (20, 40)
pos2 = (20, 80)
cv.putText(frame, "'1': reset", pos1, cv.FONT_HERSHEY_COMPLEX, 0.5, (255, 255, 255))
# 根据状态显示不同的信息
if tracking_state is True:
cv.putText(frame, "tracking now ...", pos2, cv.FONT_HERSHEY_COMPLEX, 0.5, (255, 0, 0))
else:
cv.putText(frame, "no tracking ...", pos2, cv.FONT_HERSHEY_COMPLEX, 0.5, (0, 255, 0))
完整代码:
import cv2 as cv
import dlib
# 增加功能二:信息提示
def show_info(frame, tracking_state):
pos1 = (20, 40)
pos2 = (20, 80)
cv.putText(frame, "'1': reset", pos1, cv.FONT_HERSHEY_COMPLEX, 0.5, (255, 255, 255))
# 根据状态显示不同的信息
if tracking_state is True:
cv.putText(frame, "tracking now ...", pos2, cv.FONT_HERSHEY_COMPLEX, 0.5, (255, 0, 0))
else:
cv.putText(frame, "no tracking ...", pos2, cv.FONT_HERSHEY_COMPLEX, 0.5, (0, 255, 0))
# 主函数
def main():
# 打开摄像头
capture = cv.VideoCapture(0)
# 基于 Dlib 库获取人脸检测器
detector = dlib.get_frontal_face_detector()
# 基于 Dlib 库实时跟踪
tracktor = dlib.correlation_tracker()
# 跟踪状态
tracking_state = False
# 增加功能一:保存视频
frame_width = capture.get(cv.CAP_PROP_FRAME_WIDTH)
frame_height = capture.get(cv.CAP_PROP_FRAME_HEIGHT)
fps = capture.get(cv.CAP_PROP_FPS)
# 设置视频格式
fourcc = cv.VideoWriter_fourcc(*"XVID")
# 设置输出格式
output = cv.VideoWriter("./record.avi", fourcc, int(fps), (int(frame_width), int(frame_height)), True)
# 循环读取每一帧
while True:
ret, frame = capture.read()
print(ret)
# 显示提示信息
show_info(frame, tracking_state)
# 若没有跟踪,启动跟踪器
if tracking_state is False:
gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
dets = detector(gray, 1) # 返回检测到的人脸
if len(dets) > 0:
tracktor.start_track(frame, dets[0])
tracking_state = True
# 若正在跟踪,实时获取人脸的位置,显示出来
if tracking_state is True:
tracktor.update(frame) # 实时更新画面
position = tracktor.get_position() # 获取人脸的坐标
cv.rectangle(frame, (int(position.left()), int(position.top())), (int(position.right()), int(position.bottom())), (0, 255, 0), 3)
key = cv.waitKey(1) & 0xFF
if key == ord("q"):
break
if key == ord('1'): # 按 1 重置视频
tracking_state = False
cv.imshow("Face tracking", frame)
# 保存视频
output.write(frame)
capture.release()
cv.destroyAllWindows()
if __name__ == '__main__':
main()