GAN学习记录(五)——循环生成对抗网络CycleGan
循环生成对抗网络CycleGan实现风格迁移
dataset
- https://people.eecs.berkeley.edu/~taesung_park/CycleGAN/datasets/vangogh2photo.zip
GitHub地址:https://github.com/yunlong-G/tensorflow_learn/blob/master/GAN/CycleGan.ipynb
environment
- python=3.6
- tensorflow=1.13.1
- scipy=1.2.1
- keras=2.2.4
- keras-contrib=2.0.8
结构简介
如果要用普通GAN将照片转换为绘画(或着反过来),需要使用成对的图像进行训练。而CycleGAN是一种特殊的GAN,无须使用成对图像进行训练,便可以将图像从一个领域 变换到另一个领域 。CycleGAN训练学习两种映射的生成网络。绝大多数GAN训练只一个生成网络,而CycleGAN会训练两个生成网络和两个判别网络。CycleGAN包含如下两个生成网络。
- 生成网络A:学习映射 G : X → Y G:X\rightarrow Y G:X→Y,其中 X X X是源领域, Y Y Y是目标领域。该映射接收源领域 A A A的图像,将其转换成和目标领域 B B B中的图像相似的图像。简单说来,该网络旨在学习能使 G ( X ) G(X) G(X)和 Y Y Y相似的映射。
- 生成网络B:学习映射 F : Y → X F:Y\rightarrow X F:Y→X,接收目标领域 B B B的图像,将其转换成和源领域 A A A中图像相似的图像。类似地,该网络旨在学习能使 F ( G ( X ) ) F(G(X)) F(G(X))和 X X X相似的映射。
两个网络的架构相同,但都单独训练。
CycleGAN包含如下两个判别网络。
- 判别网络A:判别网络A负责区分生成网络B生成的图像(用 F ( Y ) F(Y) F(Y)表示)和源领域A中的真实图像(表示为 X X X)。
- 判别网络B:判别网络B负责区分生成网络A生成的图像(用$G(X) 表 示 ) 和 目 标 领 域 B 中 的 真 实 图 像 ( 表 示 为 表示)和目标领域B中的真实图像(表示为 表示)和目标领域B中的真实图像(表示为Y$)。
两个网络的架构相同,也需要单独训练。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s465uGrQ-1620893448088)(attachment:268fb040-17fc-47fd-aca7-33fd02e347b5.png)]
损失函数
总损失函数
L ( G , F , D x , D y ) = L G A N ( G , D Y , X , Y ) + L G A N ( F , D X , Y , X ) + λ L c y c ( G , F ) L(G,F,D_x,D_y) = L_{GAN}(G,D_Y,X,Y)+L_{GAN}(F,D_X,Y,X)+\lambda L_{cyc}(G,F) L(G,F,Dx,Dy)=LGAN(G,DY,X,Y)+LGAN(F,DX,Y,X)+λLcyc(G,F)
对抗损失
对抗损失是来自概率分布A或概率分布B的图像和生成网络生成的图像之间的损失。该网络涉及两个映射函数,都需要应用对抗损失。
L G A N ( G , D Y , X , Y ) = E y p d a t a ( y ) [ l o g D Y ( y ) ] + E x p d a t a ( x ) [ l o g ( 1 − D Y ( G ( x ) ) ] L_{GAN}(G,D_Y,X,Y)=E_{y~p_{data}(y)}[logD_Y(y)]+E_{x~p_{data}(x)}[log(1-D_Y(G(x))] LGAN(G,DY,X,Y)=Ey pdata(y)[logDY(y)]+Ex pdata(x)[log(1−DY(G(x))]
CycleGAN包含两个生成器G和F,对应两个判别器DX和DY,下面以生成器G和判别器DY进行分析(F和DX的原理与之相同):
- G G G输入 X X X绘画,输出 G ( X ) G(X) G(X)图片,使 D Y D_Y DY判断 G ( X ) G(X) G(X)与 Y Y Y越来越相似。
- F F F输入 Y Y Y绘画,输出 F ( Y ) F(Y) F(Y)图片,使 D X D_X DX判断 F ( Y ) F(Y) F(Y)与 X X X越来越相似。
循环一致损失
对抗性损失能够让生成器 G G G和生成器 F F F学习到域 Y Y Y和域 X X X的分布,但是却没有保证从 X X X得到 G ( X ) G(X) G(X)时图像的内容不变,因为 G ( X ) G(X) G(X)只需要符合域 Y Y Y分布即可,并没有对其施加约束,所以 X X X到 G ( X ) G(X) G(X)包含很多种可能的映射。
利用循环一致性损失来进行约束,即 X X X通过 G G G生成 G ( X ) G(X) G(X)后,再通过 F F F,生成 F ( G ( X ) ) F(G(X)) F(G(X))并使其接近于X。
L c y c ( G , F ) = E x p d a t a ( x ) [ ∣ ∣ F ( G ( x ) ) − x ∣ ∣ 1 ] + E y p d a t a ( y ) [ ∣ ∣ G ( F ( y ) ) − y ∣ ∣ 1 ] L_{cyc}(G,F)=E_{x~p_{data}(x)}[||F(G(x))-x||_1]+E_{y~p_{data}(y)}[||G(F(y))-y||_1] Lcyc(G,F)=Ex pdata(x)[∣∣F(G(x))−x∣∣1]+Ey pdata(y)[∣∣G(F(y))−y∣∣1]
构建CycleGAN
# 导入需要的包
import time
from glob import glob
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from keras import Input, Model
from keras.callbacks import TensorBoard
from keras.layers import Conv2D, BatchNormalization, Activation, Add, Conv2DTranspose, \
ZeroPadding2D, LeakyReLU
from keras.optimizers import Adam
from keras_contrib.layers import InstanceNormalization
from scipy.misc import imread, imresize
Using TensorFlow backend.
残差块
def residual_block(x):
"""
Residual block
"""
res = Conv2D(filters=128, kernel_size=3, strides=1, padding="same")(x)
res = BatchNormalization(axis=3, momentum=0.9, epsilon=1e-5)(res)
res = Activation('relu')(res)
res = Conv2D(filters=128, kernel_size=3, strides=1, padding="same")(res)
res = BatchNormalization(axis=3, momentum=0.9, epsilon=1e-5)(res)
return Add()([res, x])
生成器
def build_generator():
"""
Create a generator network using the hyperparameter values defined below
"""
input_shape = (128, 128, 3)
residual_blocks = 6
input_layer = Input(shape=input_shape)
# First Convolution block
x = Conv2D(filters=32, kernel_size=7, strides=1, padding="same")(input_layer)
x = InstanceNormalization(axis=1)(x)
x = Activation("relu")(x)
# 2nd Convolution block
x = Conv2D(filters=64, kernel_size=3, strides=2, padding="same")(x)
x = InstanceNormalization(axis=1)(x)
x = Activation("relu")(x)
# 3rd Convolution block
x = Conv2D(filters=128, kernel_size=3, strides=2, padding="same")(x)
x = InstanceNormalization(axis=1)(x)
x = Activation("relu")(x)
# Residual blocks
for _ in range(residual_blocks):
x = residual_block(x)
# Upsampling blocks
# 1st Upsampling block
x = Conv2DTranspose(filters=64, kernel_size=3, strides=2, padding='same', use_bias=False)(x)
x = InstanceNormalization(axis=1)(x)
x = Activation("relu")(x)
# 2nd Upsampling block
x = Conv2DTranspose(filters=32, kernel_size=3, strides=2, padding='same', use_bias=False)(x)
x = InstanceNormalization(axis=1)(x)
x = Activation("relu")(x)
# Last Convolution layer
x = Conv2D(filters=3, kernel_size=7, strides=1, padding="same")(x)
output = Activation('tanh')(x)
model = Model(inputs=[input_layer], outputs=[output])
return model
判别器
def build_discriminator():
"""
Create a discriminator network using the hyperparameter values defined below
"""
input_shape = (128, 128, 3)
hidden_layers = 3
input_layer = Input(shape=input_shape)
x = ZeroPadding2D(padding=(1, 1))(input_layer)
# 1st Convolutional block
x = Conv2D(filters=64, kernel_size=4, strides=2, padding="valid")(x)
x = LeakyReLU(alpha=0.2)(x)
x = ZeroPadding2D(padding=(1, 1))(x)
# 3 Hidden Convolution blocks
for i in range(1, hidden_layers + 1):
x = Conv2D(filters=2 ** i * 64, kernel_size=4, strides=2, padding="valid")(x)
x = InstanceNormalization(axis=1)(x)
x = LeakyReLU(alpha=0.2)(x)
x = ZeroPadding2D(padding=(1, 1))(x)
# Last Convolution layer
output = Conv2D(filters=1, kernel_size=4, strides=1, activation="sigmoid")(x)
model = Model(inputs=[input_layer], outputs=[output])
return model
载入图片
def load_images(data_dir):
imagesA = glob(data_dir + '/testA/*.*')
imagesB = glob(data_dir + '/testB/*.*')
allImagesA = []
allImagesB = []
for index, filename in enumerate(imagesA):
imgA = imread(filename, mode='RGB')
imgB = imread(imagesB[index], mode='RGB')
imgA = imresize(imgA, (128, 128))
imgB = imresize(imgB, (128, 128))
if np.random.random() > 0.5:
imgA = np.fliplr(imgA)
imgB = np.fliplr(imgB)
allImagesA.append(imgA)
allImagesB.append(imgB)
# Normalize images
allImagesA = np.array(allImagesA) / 127.5 - 1.
allImagesB = np.array(allImagesB) / 127.5 - 1.
return allImagesA, allImagesB
def load_test_batch(data_dir, batch_size):
imagesA = glob(data_dir + '/testA/*.*')
imagesB = glob(data_dir + '/testB/*.*')
imagesA = np.random.choice(imagesA, batch_size)
imagesB = np.random.choice(imagesB, batch_size)
allA = []
allB = []
for i in range(len(imagesA)):
# Load images and resize images
imgA = imresize(imread(imagesA[i], mode='RGB').astype(np.float32), (128, 128))
imgB = imresize(imread(imagesB[i], mode='RGB').astype(np.float32), (128, 128))
allA.append(imgA)
allB.append(imgB)
return np.array(allA) / 127.5 - 1.0, np.array(allB) / 127.5 - 1.0
保存训练结果
def save_images(originalA, generatedB, recosntructedA, originalB, generatedA, reconstructedB, path):
"""
Save images
"""
fig = plt.figure()
ax = fig.add_subplot(2, 3, 1)
ax.imshow(originalA)
ax.axis("off")
ax.set_title("Original")
ax = fig.add_subplot(2, 3, 2)
ax.imshow(generatedB)
ax.axis("off")
ax.set_title("Generated")
ax = fig.add_subplot(2, 3, 3)
ax.imshow(recosntructedA)
ax.axis("off")
ax.set_title("Reconstructed")
ax = fig.add_subplot(2, 3, 4)
ax.imshow(originalB)
ax.axis("off")
ax.set_title("Original")
ax = fig.add_subplot(2, 3, 5)
ax.imshow(generatedA)
ax.axis("off")
ax.set_title("Generated")
ax = fig.add_subplot(2, 3, 6)
ax.imshow(reconstructedB)
ax.axis("off")
ax.set_title("Reconstructed")
plt.savefig(path)
def write_log(callback, name, loss, batch_no):
"""
Write training summary to TensorBoard
"""
summary = tf.Summary()
summary_value = summary.value.add()
summary_value.simple_value = loss
summary_value.tag = name
callback.writer.add_summary(summary, batch_no)
callback.writer.flush()
集成训练
if __name__ == '__main__':
data_dir = "../dataset/vangogh2photo/"
batch_size = 4
epochs = 1000
mode = 'train'
if mode == 'train':
# 载入数据
imagesA, imagesB = load_images(data_dir=data_dir)
# 迭代器设置
common_optimizer = Adam(0.0002, 0.5)
#定义网络,训练判别器
discriminatorA = build_discriminator()
discriminatorB = build_discriminator()
discriminatorA.compile(loss='mse', optimizer=common_optimizer, metrics=['accuracy'])
discriminatorB.compile(loss='mse', optimizer=common_optimizer, metrics=['accuracy'])
# 构建生成网络
generatorAToB = build_generator()
generatorBToA = build_generator()
"""
创建对抗网络
"""
inputA = Input(shape=(128, 128, 3))
inputB = Input(shape=(128, 128, 3))
# 构建两个生成器
generatedB = generatorAToB(inputA)
generatedA = generatorBToA(inputB)
# 构建重构网络
reconstructedA = generatorBToA(generatedB)
reconstructedB = generatorAToB(generatedA)
generatedAId = generatorBToA(inputA)
generatedBId = generatorAToB(inputB)
# 使判别器不被训练
discriminatorA.trainable = False
discriminatorB.trainable = False
probsA = discriminatorA(generatedA)
probsB = discriminatorB(generatedB)
# 整体网络构建
adversarial_model = Model(inputs=[inputA, inputB],
outputs=[probsA, probsB, reconstructedA, reconstructedB,
generatedAId, generatedBId])
adversarial_model.compile(loss=['mse', 'mse', 'mae', 'mae', 'mae', 'mae'],
loss_weights=[1, 1, 10.0, 10.0, 1.0, 1.0],
optimizer=common_optimizer)
# 利用tensorboard记录训练数据
tensorboard = TensorBoard(log_dir="logs/{}".format(time.time()), write_images=True, write_grads=True,
write_graph=True)
tensorboard.set_model(generatorAToB)
tensorboard.set_model(generatorBToA)
tensorboard.set_model(discriminatorA)
tensorboard.set_model(discriminatorB)
real_labels = np.ones((batch_size, 7, 7, 1))
fake_labels = np.zeros((batch_size, 7, 7, 1))
for epoch in range(epochs):
print("Epoch:{}".format(epoch))
dis_losses = []
gen_losses = []
num_batches = int(min(imagesA.shape[0], imagesB.shape[0]) / batch_size)
print("Number of batches:{}".format(num_batches))
for index in range(num_batches):
print("Batch:{}".format(index))
# 获得样例图片
batchA = imagesA[index * batch_size:(index + 1) * batch_size]
batchB = imagesB[index * batch_size:(index + 1) * batch_size]
# 利用生成器生成图片
generatedB = generatorAToB.predict(batchA)
generatedA = generatorBToA.predict(batchB)
# 对判别器A训练区分真假图片
dALoss1 = discriminatorA.train_on_batch(batchA, real_labels)
dALoss2 = discriminatorA.train_on_batch(generatedA, fake_labels)
# 对判别器B训练区分真假图片
dBLoss1 = discriminatorB.train_on_batch(batchB, real_labels)
dbLoss2 = discriminatorB.train_on_batch(generatedB, fake_labels)
# 计算总的loss值
d_loss = 0.5 * np.add(0.5 * np.add(dALoss1, dALoss2), 0.5 * np.add(dBLoss1, dbLoss2))
print("d_loss:{}".format(d_loss))
"""
训练生成网络
"""
g_loss = adversarial_model.train_on_batch([batchA, batchB],
[real_labels, real_labels, batchA, batchB, batchA, batchB])
print("g_loss:{}".format(g_loss))
dis_losses.append(d_loss)
gen_losses.append(g_loss)
"""
每一次都保留loss值
"""
write_log(tensorboard, 'discriminator_loss', np.mean(dis_losses), epoch)
write_log(tensorboard, 'generator_loss', np.mean(gen_losses), epoch)
# 每10个世代进行一次效果展示
if epoch % 10 == 0:
# 得到测试机图片A,B
batchA, batchB = load_test_batch(data_dir=data_dir, batch_size=2)
# 利用生成器生成图片
generatedB = generatorAToB.predict(batchA)
generatedA = generatorBToA.predict(batchB)
# 的到重构图片
reconsA = generatorBToA.predict(generatedB)
reconsB = generatorAToB.predict(generatedA)
# 保存原生图片,生成图片,重构图片
for i in range(len(generatedA)):
save_images(originalA=batchA[i], generatedB=generatedB[i], recosntructedA=reconsA[i],
originalB=batchB[i], generatedA=generatedA[i], reconstructedB=reconsB[i],
path="results/gen_{}_{}".format(epoch, i))
# 保存模型
generatorAToB.save_weights("./weight/generatorAToB.h5")
generatorBToA.save_weights("./weight/generatorBToA.h5")
discriminatorA.save_weights("./weight/discriminatorA.h5")
discriminatorB.save_weights("./weight/discriminatorB.h5")
elif mode == 'predict':
# 构建生成网络并载入权重
generatorAToB = build_generator()
generatorBToA = build_generator()
generatorAToB.load_weights("./weight/generatorAToB.h5")
generatorBToA.load_weights("./weight/generatorBToA.h5")
# 获得预测的图片
batchA, batchB = load_test_batch(data_dir=data_dir, batch_size=2)
# 保存预测图片
generatedB = generatorAToB.predict(batchA)
generatedA = generatorBToA.predict(batchB)
reconsA = generatorBToA.predict(generatedB)
reconsB = generatorAToB.predict(generatedA)
for i in range(len(generatedA)):
save_images(originalA=batchA[i], generatedB=generatedB[i], recosntructedA=reconsA[i],
originalB=batchB[i], generatedA=generatedA[i], reconstructedB=reconsB[i],
path="results/test_{}".format(i))
训练30个世代

训练50个世代

训练100世代

预测结果
只需要将main中mode = 'train’改成mode = ‘predict’,再提一下就是,main中的epoch = 1000 大家更具自己需要重新设置就好,还有现在的代码是都训练完才会保存模型,可以修改成10个世代保存一次。


训练过程记录
loss值
我们在训练时利用tensorboard记录的判别器和生成器的loss值,之后可以在cmd窗口到logs目录前,使用tensorboard --logdir = ./logs命令可视化训练过程loss值变化
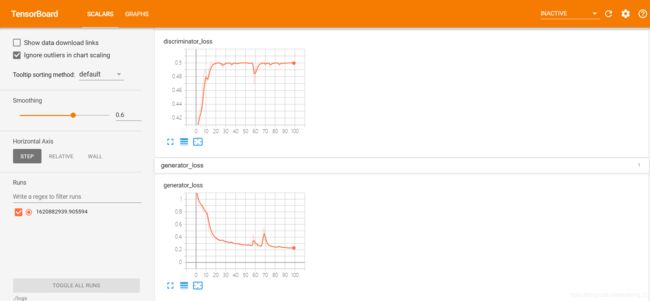
同时,通过上部的选项按键可以看到网络的结构图
小结
本次实验利用CycleGan实现油画风格到照片风格的转变,因为利用自己电脑运行代码,只运行了100个世代已经花费了两个多小时,达到的按效果还不是很明显,可以看到的是图片转成油画比较接近了,但是优化到照片还缺少了一定的清晰度。在之后的学习再尝试别的的网络学习了。