【论文精读】基于周期编码深度自编码器的心肺音盲单耳声源分离
文章信息
Blind Monaural Source Separation on Heart and Lung Sounds Based on Periodic-Coded Deep Autoencoder
基于周期编码深度自编码器的心肺音盲单耳声源分离
2020年,来自IEEE JOURNAL OF BIOMEDICAL AND HEALTH INFORMATICS期刊,Q1,IF=7.021
Abstract
听诊是诊断心血管和呼吸系统疾病的最有效方法。为了达到准确的诊断,设备必须能够识别来自各种临床情况的心肺音。然而,录制的胸音混合了心音和肺音。因此,在预处理阶段有效地分离这两种声音至关重要。
机器学习的最新进展在单声道声源分离方面取得了进展,但大多数众所周知的技术都需要配对混合声音和单个纯声音进行模型训练。由于制备纯心肺音很困难,因此必须考虑特殊设计才能得出有效的心肺声音分离技术。
在这项研究中,我们提出了一种新的周期性编码深度自动编码器(PC-DAE)方法,通过假设心率和呼吸频率之间的不同周期性,以无监督的方式分离混合心肺音。PC-DAE受益于基于深度学习的模型,通过提取代表性特征并考虑心肺音的周期性来进行分离。
我们在两个数据集上评估了PC-DAE。第一个包括来自学生听诊模型(SAM)的声音,第二个是通过在现实世界条件下录制胸部声音来准备的。实验结果表明,PC-DAE在标准化评估指标方面优于多个知名分离工作。此外,波形和频谱图证明了PC-DAE与现有方法相比的有效性。还证实,通过使用所提出的PC-DAE作为预处理阶段,可以显着提高心音识别精度。实验结果证实了PC-DAE的有效性及其在临床应用中的潜力。
Introduction
现有方法
研究心肺音产生的物理模型和分类机制
- 信号处理方法(如归一化平均香农能量),基于高频的方法,基于机器学习的模型(神经网络分类器、决策树)
- 采用S1-S2和S2-S1区间的信息,以进一步提高分类精度
- 高斯混合模型、NN分类器、支持向量机、各种类型的声学特征(功率谱密度值,希尔伯特-黄变换)已被用于进行肺部声音识别
- 测量的信号通常是心肺声音的混合,纯心/肺声信号通常无法获得,有效地分离心肺声音较困难
心肺音频谱范围
- 正常心音(第一(S1)和第二(S2)心音)的频率范围主要是20-150赫兹
- 一些高频杂音可能达到100-600赫兹,甚至达到1000赫兹
- 正常肺音的频率范围为100-1000赫兹(气管音范围为850赫兹至1000赫兹)
- 异常肺音作为喘息的不定声音跨越400-1600赫兹的宽频率范围
- 湿啰音和啰音的范围为100-500赫兹
心肺音分离技术方法——传统滤波方法(问题:频段重叠)
- 自适应过滤
- 经验模态分解
- 离散小波变换
- 将信号转换为时频域(STFT),与连续小波变换(CWT)结合,通过带通滤波器滤除心音分量
盲源分离算法
独立成分分析(ICA)及其扩展,不需要对源的先验知识;
至少需要两个传感器;
心脏音源之间的独立性假设也在某种程度上是乐观的。
非负矩阵分解(NMF)
单通道;
处理重叠频段能力好。
深度学习
直接将混合源分解为目标源,效果好于NMF;
受数据集影响大,很难获取纯净心/肺音信号。
本文工作
周期性编码深度自动编码器(PC-DAE),基于无监督学习,分离心肺音。
首先采用DAE模型提取混合声音的高度表现力表示;
接下来在潜在表示上应用调制频率分析(MFA);
根据神经元在调制域中的属性对神经元进行分组,然后对混合声音进行分离;
优点:与典型的基于学习的方法相比,不需要标记的训练数据(即成对的混合声音和单个纯声音),它受益于周期性结构,可提供比传统方法优越的分离性能。
第二节:回顾NMF/DAE算法。
第三节:介绍PC-DAE。
第四节:实验设计和结果,其中设计了两个数据集并用于测试提出的PC-DAE模型。第一个是来自学生听诊模型(SAM)数据库的心声图信号,第二个是在真实条件下制备的。实验结果证实了PC-DAE分离混合心肺音的有效性,在三个标准化评估指标、基于分离波形和频谱图的定性比较以及心音识别精度方面优于直接聚类NMF(DC-NMF)、PC-NMF和深度聚类(DC)等相关工作。
Related Works
非负矩阵分解(NMF)
将矩阵V分解为字典矩阵W和编码矩阵H,W和H的乘积近似为V,所有矩阵的项均为非负数。
基于NMF的声源分离可分为有监督(有独立声源声音)和无监督(无独立声源声音)。
有监督NMF
预训练的固定谱矩阵
W S = [ W 1 S … W M S ] W^S=[W^S_1\dots W_M^S] WS=[W1S…WMS]
其中M是声源的数量,矩阵 W S W^S WS由每个声源的特征组成,被预先提供。
包含多种声音的记录被NMF分解为 W S W^S WS和 H T H^T HT,把 H T H^T HT分解成M块
H T = [ H 1 T H ˙ M T ] H^T=[H_1^T\dot H_M^T] HT=[H1TH˙MT]
其中M是声源的数量,通过将 W i S W_i^S WiS和 H i T H_i^T HiT相乘,即可得到独立声源。
无监督NMF
由于独立声源声音不可获得,必须应用一些统计假设,一种直观的方法是将H中的向量聚类到几个不同的组,特定的声音可以通过H中的一组向量与W一起重建。
使用另一个概念设计了PC-NMF,即将不同源声音的周期性属性纳入分离框架。PC-NMF考虑编码矩阵 H T H^T HT作为时间向量,并利用周期性差异的性质来分离生物声音。由于心音和肺音在周期性特征上不同(心率和呼吸频率非常不同),因此可以通过PC-NMF模型很好地分离混合心肺音,如第4节所述。
深度自动编码器(DAE)
DAE©完全卷积体系结构如下图,由编码器E和解码器D组成。

编码器层数 K E K_E KE,解码器层数 K D K_D KD,总层数 K A L L = L D + K E K_{ALL}=L_D+K_E KALL=LD+KE。
编码器将输入 x x x编码到中间潜在空间 l ( K E ) = E ( x ) l^{(K_E)}=E(x) l(KE)=E(x),解码器通过 y = D ( l ( K E ) ) y=D(l^{(K_E)}) y=D(l(KE))重构输出,重构的输出 y y y近似等于 x x x。使用均方误差MSE测量x和y间的差值,最小化MSE是训练DAE模型的目标。
通过使用全连接层和全卷积层,可以分别构建DAE(F)和DAE©,下图为两种类型的DAE的第k层和第k+1层的连接,从左到右分别为全连接层、卷积、解卷积。
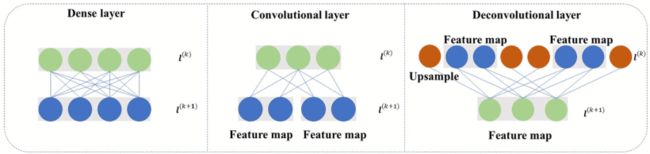
DAE(F) 通过全连接单元形成编码器和解码器,对于编码器:
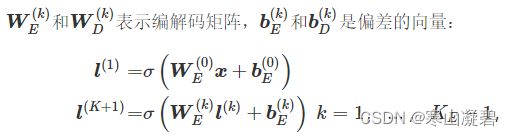
对于解码器, M M M代表潜在空间中神经元的总数:

在 DAE(C) 中,编码器由执行卷积函数的卷积单元组成, l j ( k ) ∈ R M ∗ N l_j^{(k)}∈R^{M*N} lj(k)∈RM∗N是第 k k k层中的第 j j j个特征图, I I I是通道总数:
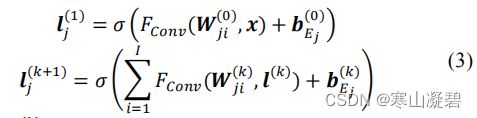
每个编码层有 J J J个滤波器: { W 1 , … . W J } , W j ∈ R L ∗ 1 \{W_1,\dots.W_J\},W_j∈R^{L*1} {W1,….WJ},Wj∈RL∗1, L L L是卷积核大小, W j i = ( w 1 , … , w i ) W_{ji}=(w_1,\dots,w_i) Wji=(w1,…,wi)是 W j W_j Wj的第 i i i个通道。在 k + 1 k+1 k+1层特征图中的每个神经元 l j ( k + 1 ) l_j^{(k+1)} lj(k+1)是 W j W_j Wj与之前所有特征图 l ( ) l^{()} l(k)的感受野通过卷积操作的元素加权积, b j ( k ) b_j^{(k)} bj(k)表示偏置,相应的卷积操作如图3(a)。

解码器由反卷积单元组成,其中 K A L L K_{ALL} KALL表示DAE©中的总层数:

在反卷积期间,第 k k k层的所有特征图 l ( ) l^{()} l(k)首先经历零填充,然后进行反卷积过程(具有函数 F D e c o n v ( ⋅ ) F_{Deconv}(⋅) FDeconv(⋅)).每个解码层都有 J J J个滤波器: { W 1 , … . W J } , W j ∈ R L ∗ 1 \{W_1,\dots.W_J\},W_j∈R^{L*1} {W1,….WJ},Wj∈RL∗1, L L L是卷积核大小, W j i = ( w 1 , … , w i ) W_{ji}=(w_1,\dots,w_i) Wji=(w1,…,wi)是 W j W_j Wj的第 i i i个通道。在 k + 1 k+1 k+1层中的每个神经元 l j ( k + 1 ) l_j^{(k+1)} lj(k+1)是 W j W_j Wj与之前所有特征图 l ( ) l^{()} l(k)的感受野通过反卷积操作的元素加权积, b j ( k ) b_j^{(k)} bj(k)表示偏置,相应的卷积操作如图3(b)。
The Proposed Method
PC-DAE是一种基于DAE的无监督声源分离方法,下图为PC-DAE的框架。
deactivate the non-target neurons:使非目标神经元失活
sparse NMF clustering:稀疏的NMF聚类

在进行分离时,首先通过短时傅里叶变换(STFT)将记录的声音转换为频域和相位部分,再将频谱特征转换为对数功率谱(LPS), X = [ x 1 , … , x n , … , x N ] X=[x_1,\dots,x_n,\dots,x_N] X=[x1,…,xn,…,xN]表示输入,N是X的帧数,然后DAE通过 E ( ⋅ ) E(·) E(⋅)编码混合的心肺LPS,把 X X X转换为潜在表征的矩阵 L ( k E ) = [ l 1 K E , … , l n K E , … , l N K E ] L^{(k_E)}=[l_1^{K_E},\dots,l_n^{K_E},\dots,l_N^{K_E}] L(kE)=[l1KE,…,lnKE,…,lNKE]。解码器 D ( ⋅ ) D(·) D(⋅)把潜在表征的矩阵重构回原始频谱特征,采用反向传播算法训练DAE的参数,以最小化MSE,由于输入输出相同,可以用无监督的方式训练DAE。
使用经过训练的 DAE,将周期分析应用于潜在表示,以识别对应于心音和肺音的两个不相交的神经元部分。基本概念是考虑不同周期源的时间信息。此外,为了按周期对时间信息进行分类,通过调制频率分析仪(MFA)将编码矩阵转换为周期性编码矩阵P。在这里,我们采用了离散傅里叶变换(DFT)来执行MFA。周期性编码矩阵具有明显的周期性特征。由于心音和肺音具有不同的周期性,因此编码矩阵可以从整个编码矩阵 P P P中分离出心脏编码矩阵和肺编码矩阵。之后,每个源编码矩阵由解码器转换并重建,以获得分离的心音的LPS序列 Y h e a r t Y^{heart} Yheart和肺音 Y L u n g Y^{Lung} YLung,然后通过应用逆短时傅里叶变换(ISTFT)将输出的LPS特征转换回波形域信号。
A. 周期分析算法(MFA,调制频率分析仪)
首先使用等式(1)-(4)中的编码器和解码器训练DAE(F)或DAE©模型,然后输入心肺音混合序列X,以获得潜在特征,潜在表示和时间序列的集合是矩阵 L = [ l 1 ( K E ) , l 2 ( K E ) , … , l N ( K E ) ] L=[l_1^{(K_E)},l_2^{(K_E)},\dots,l_N^{(K_E)}] L=[l1(KE),l2(KE),…,lN(KE)],因此我们获得了:

其中 L ∈ R M ∗ N L∈R^{M*N} L∈RM∗N, j j j是神经元标签, 1 ≤ j ≤ M 1\leq j\leq M 1≤j≤M, n n n是时间戳, 1 ≤ n ≤ N 1\leq n\leq N 1≤n≤N, N N N是总帧数。
我们假设在潜在表征中,一些神经元被心音激活,而另一些则被肺音激活。基于这个假设,我们可以在潜在表示空间中分离混合心肺音。为了确定每个神经元是由心音还是肺音激活的,我们转置原始 L L L以获得 Z m i x = L T Z^{mix}=L^T Zmix=LT( T T T表示矩阵转置),因此可获得:
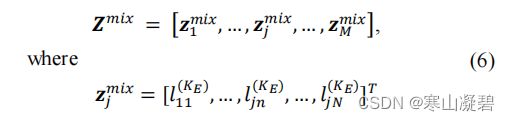
伴随 Z m i x Z^{mix} Zmix,我们打算将整个神经元集分成两组,一组对应于心音,另一组对应于肺音。更具体地说,当纯心音输入DAE时,只有一组对应于心音的神经元被激活,而对应于肺音的另一组神经元被停用。另一方面,当纯肺音输入DAE时,与肺音对应的神经元组被激活,而与心音对应的另一组神经元被停用。确定这两组神经元的策略是基于心音和肺音的周期性。
算法1显示了周期分析的详细过程。为了分析每个子矩阵 z j m i x z_j^{mix} zjmix的周期性,我们通过对 z j m i x z_j^{mix} zjmix应用MFA,形成周期编码矩阵 P = [ p 1 , … , p j , … , p M ] P=[p_1,\dots,p_j,\dots,p_M] P=[p1,…,pj,…,pM],其中 p j = ∣ M F A ( z j m i x ) ∣ p_j=|MFA(z_j^{mix})| pj=∣MFA(zjmix)∣。
当我们使用DFT进行MFA时,我们有 p j ∈ R ( N / 2 + 1 ) p_j∈R^{(N/2+1)} pj∈R(N/2+1),这里我们采用系数NMF聚类方法将 P P P中的向量聚类为两组,方程(8)显示了NMF的聚类过程,也是通过最小化误差函数实现,在编码矩阵 H p H_p Hp( P T P^T PT的转置)中得分最高的基础上, Z m i x Z^{mix} Zmix的聚类分配可以确定。
![]()
其中, W p W_p Wp表示聚类质心, H p = [ h 1 , … , h j , … , h M ] H_p=[h_1,\dots,h_j,\dots,h_M] Hp=[h1,…,hj,…,hM]表示聚类成员, h j ∈ R k ∗ 1 h_j∈R^{k*1} hj∈Rk∗1,k被设定为基础的集群量, λ \lambda λ表示表示稀疏性惩罚因子, ∣ ∣ ⋅ ∣ ∣ ||⋅|| ∣∣⋅∣∣表示 $L1 范 数 , 并 且 范数,并且 范数,并且∥⋅∥^2_F$表示Frobenius距离。
在编码矩阵 H p H_p Hp中 h j h_j hj的基础上,聚类结果 C = [ c 1 , … , c j , … , c M ] C=[c_1,\dots,c_j,\dots,c_M] C=[c1,…,cj,…,cM]由 h j h_j hj的最大得分决定。在这种情况下, c j ∈ c_j∈ cj∈{心,肺},聚类结果分配给 z j m i x z_j^{mix} zjmix。根据分配的聚类结果, Z m i x Z^{mix} Zmix分别通过停用不属于目标的子矩阵来实现 Z h e a r t Z^{heart} Zheart和 Z L u n g Z^{Lung} ZLung的分离。
在获得每个源的编码矩阵后,我们将其解码:

在我们所提出的方法中,为了获得分离的声音的优越性能,我们首先计算这两个声音的比例掩码,其定义为:

通过估计出的 M h e a r t M^{heart} Mheart和 M l u n g M^{lung} Mlung,我们通过下式,获得心脏的LPS Y h e a r t Y^{heart} Yheart和肺的LPS Y l u n g Y^{lung} Ylung:
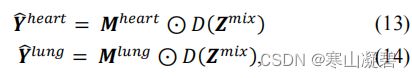
其中 ⊙ ⊙ ⊙表示逐元素乘法,然后 Y h e a r t Y^{heart} Yheart和 Y l u n g Y^{lung} Ylung与原始相位一同被用于获取分离的心肺波形。
算法1:编码矩阵上的MFA
输入:混合心肺编码矩阵 Z m i x Z^{mix} Zmix,其中 Z m i x ∈ R M ∗ N Z^{mix}∈R^{M*N} Zmix∈RM∗N。
输出:心音的编码矩阵 Z h e a r t Z^{heart} Zheart和肺音的编码矩阵 Z L u n g Z^{Lung} ZLung。
对 j = 1 j = 1 j=1到 M M M,计算 p = ∣ M F A ( ) ∣ p_ = | MFA(_^{})| pj=∣MFA(zjmix)∣;
对 P P P中的向量 [ p 1 , … , p j , … , p M ] [p_1,\dots,p_j,\dots,p_M] [p1,…,pj,…,pM]执行聚类;
获得 P P P的标签 c = [ c 1 , … , c M ] c=[c_1,\dots,c_M] c=[c1,…,cM],其中只有两个标签 c j c_j cj{心或肺};
分派标签 c j c_j cj给 z j m i x z_j^{mix} zjmix;
设定 σ m i n ∈ R M ∗ N \sigma_{min}∈R^{M*N} σmin∈RM∗N,其中 σ m i n \sigma_{min} σmin是一个向量,其系数是潜在神经元的最小值;
对每个 t = [ h e a r t ; l u n g ] t=[heart;lung] t=[heart;lung],初始化 Z t = Z m i x Z^t=Z^{mix} Zt=Zmix;
对 j = 1 j=1 j=1到 M M M,如果 c j ≠ t c_j≠t cj=t,赋值 z j t = σ m i n z_j^t=\sigma_{min} zjt=σmin;
返回 Z t Z^t Zt。
Experiments
A.实验设置
PC-DAE(F),PC-DAE(C),DC-NMF(直接聚类NMF),PC-NMF,DC-DAE(基于DAE的深度聚类)。
PC-NMF和PC-DAE共享类似的功能,其中PC-DAE对心肺声音分离的潜在表示执行聚类。
为了公平比较,本研究中实施的DC-NMF,PC-NMF和DC-DAE是以无监督的方式进行的。
对于所有方法,混合信号的频谱图作为输入,分离的心肺音作为输出。
DAE(F)模型结构
由七个隐藏层组成,这些层中的神经元数分别为1024、512、256、128、256、512 和 1024。
DAE©模型结构
编码器由三个卷积层组成:
第一层有32个过滤器,卷积核大小为 1×4;
第二层有16个过滤器,卷积核大小为1×3;
第三层有8个过滤器,卷积核大小为1×3的编码器。
解码器由四层组成:
第一层有8个反卷积过滤器,内核大小为 1×3;
第二层有16个反卷积滤波器,内核大小为1×3;
第三层有32个反卷积滤波器,内核大小为1×4;
第四层有1个核大小为1×1的反卷积滤波器。
卷积和反卷积单元都采用 1 的步幅。整流线性单元用于编码器和解码器,优化器是Adam。使用基于无监督NMF的方法作为基线,其中NMF的基数设置为20,L2范数作为损失函数。
NMF方法
NMF方法首先将输入频谱图V分解为基矩阵W和权重矩阵H,其中W作为声音基(包括心音和肺音),H是加权系数,公式为:
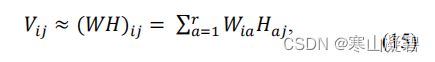
其中, V i j V_{ij} Vij是包含多个声源的矩阵V的第ij分量, W i a W_{ia} Wia和 H a j H_{aj} Haj是 H H H的第 i a ia ia和 a j aj aj分量。
对于无监督的源分离,加权系数矩阵 H H H被聚类为几个不同的组。在进行分离时,可以通过使用 H H H中对应于目标源的向量组来重构感兴趣的目标源。
由于聚类直接应用于加权矩阵,我们把这种方法称为DC-NMF,作为第一个基线系统。
PC-NMF不是直接进行聚类,而是根据单个声源的周期性对H中的向量进行聚类;PC-NMF也被作为第二条基线实施。
DC-DAE©:深度学习聚类
最近,一种结合了深度学习算法和聚类过程的深度聚类技术被提出,并被证实对语音和音乐分离有效。深度聚类的基本理论与DC-NMF相似,因为聚类是应用在潜在表征中,而不是加权矩阵。由于深度学习模型首先将输入的频谱图转化为更有代表性的潜伏特征,潜伏特征的聚类可以提供更好的分离结果。在这项研究中,我们实现了深度聚类方法作为另一种比较方法。在实现深度聚类方法时,我们使用DAE©的模型架构作为基于深度学习的模型;因此,该方法的术语为DC-DAE©。
评价指标
对于本研究中进行的所有分离方法,我们可以获得分离的心肺声。我们用纯心肺声作为参考来计算分离性能,并采用三个标准化的评价指标,即信号失真率(SDR)、信号干扰比(SIR)和信号伪影比(SAR)来评价分离性能。在声源分离任务中,有三种类型的噪声:由于错过分离的噪声( e i n t e r f e_{interf} einterf)、由于重建过程的噪声( e a r t i f e_{artif} eartif),以及扰动噪声( e n o i s e e_{noise} enoise)。SDR、SIR和SAR的计算见公式(16)-(19),其中s^(t)为估计结果, s t a r g e t ( t ) s_{target}(t) starget(t)为目标。

对于这三个指标来说,更高的分数表示更好的源分离结果。
我们使用两个数据集进行了实验。
在第一个数据集中,心肺声是由SAM(学生听诊模拟装置)采集的,它是心肺声教学的标准设备[48]。图5显示了SAM的模型。SAM试图模拟真实的人体,在其体内有许多扬声器,对应于器官的位置。SAM可以在不同的位置产生干净的心脏声音或肺部声音。我们使用iMEDIPLUS电子听诊器在消声室中记录心脏和肺部声音。本实验中使用的心音包括有两次心跳的正常心音(S1和S2)。本实验中的肺部声音包括正常的、喘息的、虹吸的和喘息的声音。心脏和肺部的声音都是以8千赫兹采样的。两种声音在不同的信噪比(SNR)水平(-6dB、-2dB、0dB、2dB和6dB)下混合,以纯心脏声音作为目标信号,纯肺部心脏声音作为噪音信号。所有的声音都通过应用短时傅里叶变换(STFT)转换成频谱域,帧长2048,帧移128。由于高频部分可能不会为进一步的分析提供关键信息,我们在本研究中只使用了0-300个分档(对应0-1170Hz)。

B. 选定案例的潜空间分析——PC-DAE的步骤
在本节中,我们用一个混合声音的样本来详细说明PC-DAE系统的每一个步骤。图6显示了PC-
DAE的整体程序,其中图6(a)和(b)分别显示了纯心脏和肺部声音的频谱图。图6©显示了潜在表征的提取过程。
为了演示,我们选择了两个特定的神经元,一个对应于心音,另一个对应于肺音,并在图6(d)和(e)中分别绘制了它们沿时间轴的轨迹。通过评估图6(d)和(e),我们首先感知到图6(d)和(e)的周期性属性分别与图6(a)和(b)很好地吻合。同时,我们观察到这两个神经元的不同轨迹,心脏声音的周期性与肺部声音不同。
接下来,我们对图6(d)和(e)的轨迹应用DFT,分别得到图6(f)和(g),以更明确地捕捉周期性。值得注意的是,图6(a)(b)(d)(e)的X轴是时间(s),而图6(f)和(g)的X轴是频率(Hz)。在时间信号分析中,图6(f)和(g)中的信号被称为图6(d)和(e)的MFA。通过将轨迹转换为调制域可以看出,周期性可以更容易观察到。

图6.对样本声音的潜表征进行分析。(a)和(b)分别是纯心音和肺音的频谱图,x轴是时间(s),y轴是频率(Hz);©介绍了基于DAE模型的潜像提取;(d)和(e)是两个潜伏神经元的轨迹,其中x轴是时间,y轴是激活值;(f)和(g)是DFT结果,其中x轴是频率,y轴表示功率密度。
通过比较图6(f)和(g),我们观察到图6(g)的低频部分有一个峰值,而图6(f)的峰值位于高频部分。结果表明,这两个神经元应该被聚类为两个不同的组。我们对DAE中的所有神经元应用同样的程序(轨迹提取和DFT)。处理较短和较长周期的神经元被聚类为两个不同的组。最后,给定一个混合的声音,我们首先提取潜在的表征;为了提取心音,我们就保留对应心音的神经元,停用对应肺音的神经元,反之亦然。
为了进一步验证PC聚类方法的有效性,我们通过定性分析聚类结果来比较DC和PC聚类方法。为了便于进行清晰的视觉比较,我们采用了主成分分析(PCA),将潜在表征上的维度减少到只有二维,然后在图7中画出散射图。图中显示了两个混合心肺声音的频谱图和潜表征的聚类结果。图7(a)为正常心音和异常肺音(rhonchi)的混合频谱图;图7(b)为正常心音和异常肺音(stridor)的混合频谱图。图7©和(d)分别是对应于图7(a)和(b)的潜在表征(通过PCA降维)的DC聚类结果。图7(e)和(f)是分别对应于图7(a)和(b)的潜意识表征的PC聚类结果。
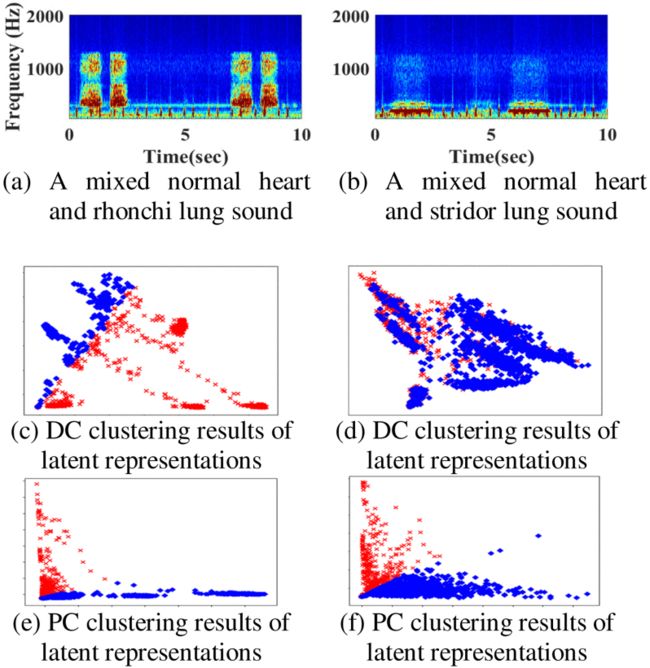
图7.两种心肺混合声的频谱图和潜表征的聚类结果。(a)和(b)是两个混合心肺声的频谱图;©和(d)是潜像表示的DC聚类结果;(e)和(f)是潜像表示的PC聚类结果。
通过观察图7(a)、©和(e),我们可以注意到,心脏和肺部的声音显示出明显不同的时间频率特性(如图7(a)所示)。在这种情况下,DC(如图7©)和PC(如图7(e))聚类方法都可以有效地将肺部和心脏声音对应的潜在特征分为两个不同的组。因此,DC和PC方法都可以取得令人满意的分离结果。接下来,通过观察图7(b)、(d)和(f)的结果,由于吸气声与心音高度重叠(如图7(b)所示),DC聚类方法(如图7(d)所示)不能有效地将潜在的表征分成两个不同的组。另一方面,PC聚类方法(如图7(f)所示)可以成功地将潜在表征聚成两个不同的组,从而产生更好的分离结果。
请注意,任何特定的时间-频率表示方法都可以用来执行MFA。本研究采用DFT作为一种代表性的方法。其他时频表示方法,如CWT和以及Hilbert-Huang变换,也可以使用。当使用这些方法时,需要仔细考虑合适的基础函数或先验知识。在这项研究中,我们打算把注意力集中在DFT上,并在将来进一步探索其他的时频表示方法。
C. 基于源分离评价指标的定量评价
接下来,我们打算用公式(9)和(10)以及公式(13)和(14)来比较分离性能。结果列于图8。
由于公式(9)和(10)直接估计了听到的声音和肺部声音,使用公式(9)和(10)的结果被称为 “直接”。
另一方面,由于公式(13)和(14)通过比率掩码函数估计心音和肺音,结果被称为 “掩码”。
我们用PC-DAE(F)和PC-DAE©来测试性能。
从图8的结果来看,除了PC-DAE(F)的心音SIR之外,"Mask "的结果一直优于 "Direct "的结果,并证实了使用比率掩码函数来进行分离而不是直接估计的有效性。
在下面的讨论中,我们只报告使用公式(13)和(14)的比率掩码函数的PC-DAE分离结果。
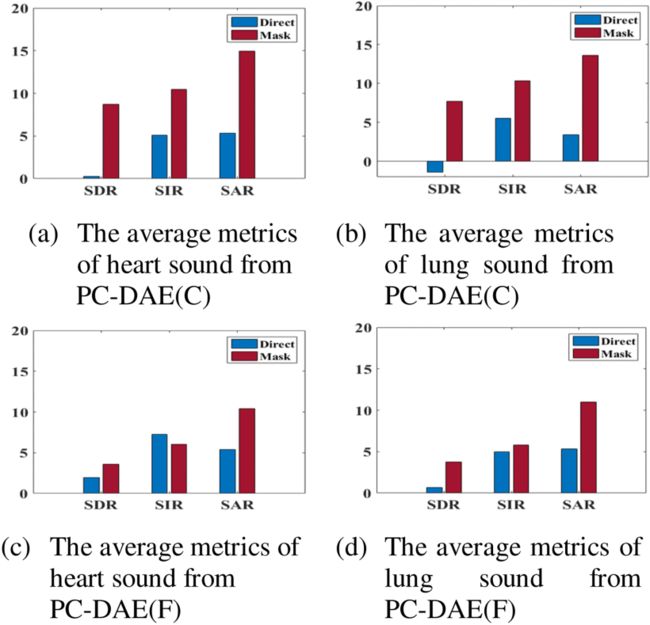
图8.不同信噪比条件下的平均分离结果。(a)和©分别显示了使用PC-DAE©和PC-DAE(F)的心音分离结果;(b)和(d)分别显示了使用PC-DAE©和PC-DAE(F)的肺音分离结果。
表一和表二显示了分别在所提出的PC-DAE(F)和PC-DAE©上测试的心脏和肺部声音的评估结果,并有比较的方法。心脏和肺部声音的分离性能是一致的。从这两个表格中,我们观察到所有的SDR、SIR和SAR分数大多随着SNR水平的增加而增加。同时,我们注意到PC-NMF优于DC-NMF,而PC-DAE©优于DC-DAE©,证实了周期性特性提供了比直接聚类更优越的分离性能。同时,我们观察到基于深度学习的方法,即DC-DAE©和PC-DAE©,优于基于NMF的对应方法,即DC-NMF和PC-NMF,验证了深度学习模型在提取代表性特征方面比浅层模型有效。最后,我们观察到PC-DAE©优于PC-DAE(F),这表明在这个声音分离任务中,卷积架构可以产生比全连接架构更好的性能。
表一:拟议的PC-DAE(F)和PC-DAE©生成的分离心音与三种传统方法在SDR、SIR和SAR方面的评估结果比较。平均值是指五个信噪比的平均分。

表二:建议的PC-DAE(F)和PC-DAE©产生的分离肺音与三种传统方法在SDR、SIR和SAR方面的评估结果比较。平均值是指五个信噪比的平均分。

D. 基于分离后的波形和频谱图的定性比较
除了定量比较,我们还展示了一个样本声音的波形和频谱,以直观地比较分离的结果。
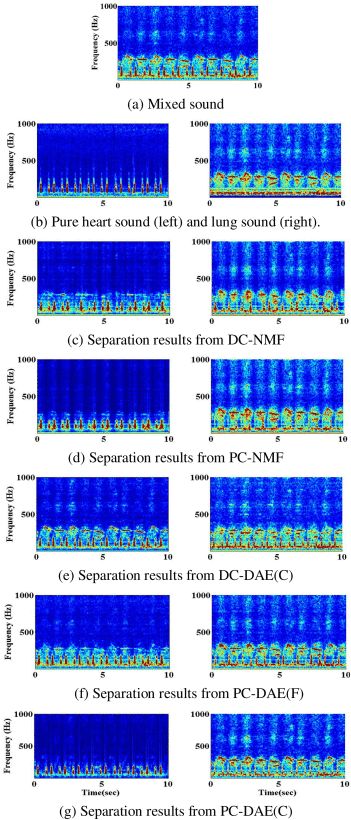
我们选择了一个样本声音,它是心脏声音(作为信号)和肺部喘息声音(作为噪声)的信噪比为6dB的混合声音。图9显示了样本声音的波形,其中图9(a)显示了混合声音。图9(b)显示了未被混合的纯心脏声(左图)和肺部声(右图)。图9(c)、(d)、(e)、(f)和(g)分别显示了DC-NMF、PC-NMF、DC-DAE(C)、PC-DAE(F)和PC-DAE(C)的分离结果。从图9中,我们观察到,与其他方法相比,PC-DAE©能更有效地分离心音和肺音;其趋势与表一和表二所示一致。

图9.混合样品的波形。y轴是信号的振幅,x轴是时间(s)。从(b)到(g),左边和右边的面板分别是心音和肺音。
接下来在图10中,我们展示了图9中所示的同一样本声音的频谱图。图10(a)显示了混合的声音,图10(b)显示了纯心脏和肺部的声音,图10©至(g)是分离的结果。从图10(a)我们可以观察到,这两种声音在低频区域高度重叠。我们还注意到,PC-NMF在肺部声音的高频期间拥有较高的干扰抑制性能,而PC-DAE(F)在重叠的频率带宽中拥有较高的性能,并能收到改善的心脏声音质量。PC-DAE(F)和PC-DAE©在最小的人工噪音下表现最好。总的来说,这两种PC-DAE方法的表现优于其他方法,产生了清晰的分离谱图。
E. 在第一心音(S1)和第二心音(S2)识别中的实际应用
我们使用另一个数据集来进一步评估所提出的算法在一个更真实的世界场景中。从国立台湾医院收集了真实的心肺混合音,并使用提议的PC-DAE来分离心肺音。由于不可能获得与心肺混合声相对应的纯心肺声,因此在这项任务中不能使用SDR、SIR和SAR分数作为评价指标。相反,我们采用第一心音(S1)和第二心音(S2)的识别精度来确定分离性能。我们采用了[10]、[65]中著名的S1和S2识别算法,该算法考虑了频率特性和S1-S2和S2-S1间隔的假设。我们相信这个替代指标是有说服力和价值的,因为S1-S2的识别准确度已经被作为医生诊断疾病发生的一个重要指标。
这个数据集包括3个不同的年龄组,即0-20岁(儿童和青少年)、21-65岁(成年)和66岁以上(老年人))。每组有6个病例,包括3个男性和3个女性,每个病例有7个心肺混合音(每个有10秒)。基于这样的设计,我们可以确定所提出的方法是否能对年龄和性别组的变化具有鲁棒性(相应地涵盖具有不同生理因素的人,如血压、心率等)。表三显示了进行心肺分离之前和之后的识别准确率。
表三 不同年龄和性别组的心肺混合音和分离心音的识别准确率。

为了直观地研究S1-S2的识别性能,我们在图11中展示了波形和识别结果。图11(a)和(b)是两个声音样本,其中图11(a)是带有正常心脏和肺部声音的心肺混合声,图11(b)是带有异常心脏声音(弱周期性)和异常肺部声音(虹吸)的心肺混合声音。图11©和(d)分别显示了与图11(a)和(b)相对应的进行心肺声分离后的S1-S2识别。

图11.两个声音样本的波形和相应的S1-S2识别结果。(a)心肺混合声,包括正常的心脏声和正常的肺部声。(b)带有异常心脏声和异常肺部声的心肺混合声。©和(d)是与(a)和(b)相对应的分离结果,分别是。识别的S1和S2结果分别用绿色和红色符号表示。
从图11(a)和(b)可以看出,混合音的S1-S2识别结果较差,而分离出的心音的识别性能明显提高(从图11©和(d)可以看出),证实了所提出的PC-DAE在分离心音和混合音方面的突出能力。
Conclusion
所提出的PC-DAE是基于信号的周期性特性,在单通道录音的情况下进行盲源分离。与传统的有监督的声源分离方法不同,PC-DAE不需要有监督的训练数据。据我们所知,所提出的PC-DAE是第一个结合了基于深度学习的特征表示和周期性特性的优势来进行心肺声分离的工作。本研究的结果表明,所提出的方法能有效地利用周期性分析算法来改善频率带宽重叠的声音的分离。结果还表明,与几个相关的工作相比,PC-DAE提供了令人满意的分离结果,并取得了优越的质量。此外,我们验证了通过使用所提出的PC-DAE作为预处理步骤,心脏声音的识别精度可以得到很大的提高。在我们目前的工作中,我们需要定义信号中有多少个来源。然而,在大多数情况下,确定信号源的确切数量是困难的。因此,确定一种有效的方法来确定声源的数量是未来的一项重要工作。在本研究中,我们考虑的条件是只有电子听诊器记录的声音。我们相信,这种实验设置接近于大多数真实的临床场景。在未来,我们将把提议的PC-DAE扩展到有额外生理数据的条件下,如心电图(ECG)、光脑图和血压信号。
优势
不需要有监督的训练数据,结合了基于深度学习的特征表示和周期性特性的优势来进行心肺音分离;
所提出的方法能有效地利用周期性分析算法来改善频率带宽重叠的声音的分离;
PC-DAE提供了令人满意的分离结果,可以提高心音识别精度;
问题
需要确定信号源的数量;
只使用了电子听诊器记录的声音,后续可以扩展到有ECG、光脑图、血压信号等额外生理数据的条件下。