《Aidlux智慧安防AI实战训练营》大作业总结及心得
1 训练营课程
(1)本节课主要学习智慧安防实战训练营的课程,课程详情见链接:
https://fd5gw1nrcx.feishu.cn/docx/FuVYdmYnIoLWzBxGwxdcVOiwnbb。
(2)学习目的
作为一名算法工程师,对学如逆水行舟,不进则退这句话有着深刻的理解,在这个行业内卷越来越严重的情况下,需要通过不停的学习来努力提升自己,同时算法工程师也需要具有敏锐的洞察力,对新出现的技术,科技充满兴趣,热情,才能快速的成长。
首先感谢大白老师提供的这次学习的机会,也感谢Rocky老师悉心的教学,大白老师组织的训练营我已经参加了好几次了,每一次都干货满满,当然每一次我也是满载而归,再次感谢两位老师的付出。
这次学习Aidlux也是收获满满,Aidlux能快速部署到ARM架构的手机、平板、电脑上,这对于算法开发人员来说简直就是福音,可以用python实现从模型训练+模型部署。

附两张电脑浏览器登陆Aidlux界面显示图。
**2 作业题目一 生成对抗样本 **
***题目一:将生成的有效的对抗样本以及相关思路介绍文档进行提交。***
实现过程:
2.1 车辆检测以及车辆目标图提取
本次作业使用的车辆检测模型为yolov5。
2.1.1通过Aidlux进行车辆目标提取代码如下
aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res, extract_detect_res
import time
import cv2
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
model_path = '/home/Lesson5_code/yolov5_code/models/yolov5_car_best-fp16.tflite'
# 定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
# 读取图片进行推理
# 设置测试集路径
source = "/home/Lesson5_code/yolov5_code/data/images/tests"
images_list = os.listdir(source)
print(images_list)
frame_id = 0
# 读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# cvs.imshow(res_img)
# 测试结果展示停顿
#time.sleep(5)
# 图片裁剪,提取车辆目标区域
extract_detect_res(frame, pred, image_name)
# cvs.imshow(cut_img)
# cap.release()
# cv2.destroyAllWindows()
2.1.2对提取到的车辆目标进行迁移攻击
这里我们将Mobilenetv2作为常规模型,将ResNet18作为替身模型,在业务场景下,客户系统用Mobilenetv2,把扣取出的车的小图,识别成了出租车,这是正确的。而替身模型,是攻击者自己掌握的模型,进行攻击后,生成新的攻击样本(比如在图片上增加了非常不起眼的扰动),这时再用常规模型Mobilenetv2,去进行分类识别时,看是否识别就错误了,比如识别成卡车、或者救护车了。当攻击者掌握了以上的漏洞后,他在一些业务场景,增加这种不起眼的干扰因素,客户系统就会出现各种问题。

这里攻击算法采用PGD,部使用替身模型ResNet18的相关信息进行对抗样本的生成,比如替身模型的参数,输出label。
 对抗样本生成以后,我们用常规模型MobileNetv2进行测试。
对抗样本生成以后,我们用常规模型MobileNetv2进行测试。
效果如下图所示:


可以看到在攻击以后检测到的车辆标签发生了变化。
2.1.3 使用检测模型对对抗样本进行检测存储对抗有效图片
本课程中的监测模型代码如下所示:

作业完成代码如下:
import os
import torch
import torch.nn as nn
import torchvision.utils
from torchvision.models import mobilenet_v2, resnet18
from advertorch.utils import predict_from_logits
from advertorch.utils import NormalizeByChannelMeanStd
from robust_layer import GradientConcealment, ResizedPaddingLayer
from timm.models import create_model
from advertorch.attacks import LinfPGDAttack
from advertorch_examples.utils import ImageNetClassNameLookup
from advertorch_examples.utils import bhwc2bchw
from advertorch_examples.utils import bchw2bhwc
from skimage.io import imread
device = "cuda" if torch.cuda.is_available() else "cpu"
org_img_folder = '/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/myhomework/生成对抗样本/车辆裁减图'
### 对抗攻击监测模型
class Detect_Model(nn.Module):
def __init__(self, num_classes=2):
super(Detect_Model, self).__init__()
self.num_classes = num_classes
#model = create_model('mobilenetv3_large_075', pretrained=False, num_classes=num_classes)
model = create_model('resnet50', pretrained=False, num_classes=num_classes)
# self.multi_PreProcess = multi_PreProcess()
pth_path = os.path.join("/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/Lesson5_code/model", 'track2_resnet50_ANT_best_albation1_64_checkpoint.pth')
#pth_path = os.path.join("/Users/rocky/Desktop/训练营/Lesson5_code/model/", "track2_tf_mobilenetv3_large_075_64_checkpoint.pth")
state_dict = torch.load(pth_path, map_location='cpu')
is_strict = False
if 'model' in state_dict.keys():
model.load_state_dict(state_dict['model'], strict=is_strict)
else:
model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# self.model = nn.Sequential(normalize, self.multi_PreProcess, model)
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
# x = x[:,:,32:193,32:193]
# x = F.interpolate(x, size=(224,224), mode="bilinear", align_corners=True)
# x = self.multi_PreProcess.forward(x)
out = self.model(x)
if self.num_classes == 2:
out = out.softmax(1)
#return out[:,1:]
return out[:,1:]
# 遍历文件夹
def getFileList(dir, Filelist, ext=None):
"""
获取文件夹及其子文件夹中文件列表
输入 dir:文件夹根目录
输入 ext: 扩展名
返回: 文件路径列表
"""
newDir = dir
if os.path.isfile(dir):
if ext is None:
Filelist.append(dir)
else:
if ext in dir[-3:]:
Filelist.append(dir)
elif os.path.isdir(dir):
for s in os.listdir(dir):
newDir = os.path.join(dir, s)
getFileList(newDir, Filelist, ext)
return Filelist
### 读取图片
def get_image():
img_path = os.path.join("/home/yolov5_code/aidlux/extract_results", "vid_5_27640.jpg_0.jpg")
# img_url = "https://farm1.static.flickr.com/230/524562325_fb0a11d1e1.jpg"
def _load_image():
from skimage.io import imread
return imread(img_path) / 255.
if os.path.exists(img_path):
return _load_image()
else:
import urllib
urllib.request.urlretrieve(img_url, img_path)
return _load_image()
def tensor2npimg(tensor):
return bchw2bhwc(tensor[0].cpu().numpy())
### 展示攻击结果
def show_images(model, img, advimg, enhance=127):
np_advimg = tensor2npimg(advimg)
np_perturb = tensor2npimg(advimg - img)
pred = imagenet_label2classname(predict_from_logits(model(img)))
advpred = imagenet_label2classname(predict_from_logits(model(advimg)))
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 5))
plt.subplot(1, 3, 1)
plt.imshow(np_img)
plt.axis("off")
plt.title("original image\n prediction: {}".format(pred))
plt.subplot(1, 3, 2)
plt.imshow(np_perturb * enhance + 0.5)
plt.axis("off")
plt.title("the perturbation,\n enhanced {} times".format(enhance))
plt.subplot(1, 3, 3)
plt.imshow(np_advimg)
plt.axis("off")
plt.title("perturbed image\n prediction: {}".format(advpred))
plt.show()
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
### 常规模型加载
model = mobilenet_v2(pretrained=True)
# model=torch.load("/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/Lesson5_code/model/mobilenet_v2-b0353104.pth")
model.eval()
model = nn.Sequential(normalize, model)
model = model.to(device)
### 替身模型加载
model_su = resnet18(pretrained=True)
model_su.eval()
model_su = nn.Sequential(normalize, model_su)
model_su = model_su.to(device)
if __name__ == "__main__":
###xunhuandutu
imglist = getFileList(org_img_folder, [], 'jpg')
print('本次执行检索到 ' + str(len(imglist)) + ' 张图像\n')
print(imglist)
index=0
for imgpath in imglist:
np_img = imread(imgpath) / 255.
index=index+1
### 数据预处理
imgname = os.path.splitext(os.path.basename(imgpath))[0]
# get_image()
img = torch.tensor(bhwc2bchw(np_img))[None, :, :, :].float().to(device)
imagenet_label2classname = ImageNetClassNameLookup()
### 测试模型输出结果
pred = imagenet_label2classname(predict_from_logits(model(img)))
print("test output:", pred)
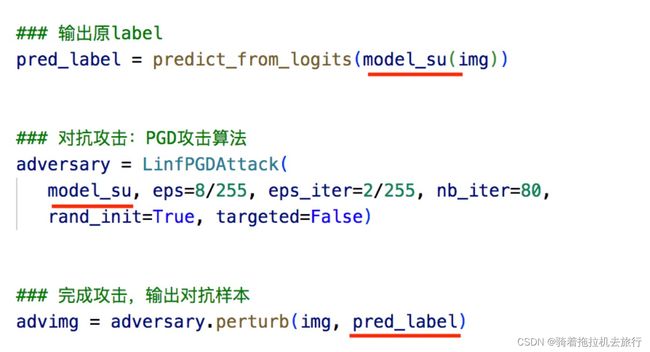
### 输出原label
pred_label = predict_from_logits(model_su(img))
### 对抗攻击:PGD攻击算法
adversary = LinfPGDAttack(
model_su, eps=8 / 255, eps_iter=2 / 255, nb_iter=80,
rand_init=True, targeted=False)
### 完成攻击,输出对抗样本
advimg = adversary.perturb(img, pred_label)
### 展示源图片,对抗扰动,对抗样本以及模型的输出结果
show_images(model, img, advimg)
##对生成的攻击样本进行判断是否有效,保存有效图片
detect_model = Detect_Model().eval().to(device)
### 对抗攻击监测
detect_pred = detect_model(img)
print(detect_pred)
#只保存有效的对抗样本
if detect_pred > 0.5:
### 迁移攻击样本保存
save_path = "/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/myhomework/1/adv_results/"
torchvision.utils.save_image(advimg.cpu().data, save_path + imgname+"_adv_image.png")
**3 作业题目二 整体业务功能串联 **
题目二:有了前面的对抗样本,即一张图片中其实暗藏着安全风险的图片。这时就将前面的业务逻辑串联,判断每一个车辆是正常图片还是有安全风险的图片如果是正常图片,就进入后面的车辆分类的判断,如果是有安全风险的图片,则通过喵提醒来进行告警。那么整体业务功能串联,主要包含以下几个部分: 在Aidlux中将车辆检测+检测框提取+使用对抗样本+AI安全监测与告警功能串联,完成功能代码的撰写。
3.1 系统告警
当对抗攻击监测模型,监测到对抗样本或者对抗攻击后。一般在实际场景的AI项目中,会出现一个告警弹窗,并且会告知安全人员及时进行安全排查。
当然我们此次训练营并没有业务系统,为了更加贴近实际,本次训练营采用一种简单的方式,当然也比较实用,即通过微信“喵提醒”的方式来实现。在后面的大作业中,我们也会使用到。
3.1.1喵提醒代码如下
需要注意的是,代码中的id要改成自己的“喵码”,text信息需要修改成告警信息,这里修改成“出现对抗攻击风险!!”。
if detect_pred > 0.5:
### 迁移攻击样本保存
#save_path = "/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/myhomework/1/adv_results/"
#torchvision.utils.save_image(advimg.cpu().data, save_path + imgname+"_adv_image.png")
# 填写对应的喵码
id = 't4ebTaH'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "出现对抗攻击风险!!"
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)
3.1.2 喵提醒效果展示

3.2 整体思路介绍以及代码实现
本次作业想实现以下功能:
(1)程序全程在安装了Aidlux软件的手机上运行。
(2)读取一张测试图片完成车辆检测、车辆区域提取、对抗攻击、Ai安全检测与告警的功能。
3.2.1 代码如下
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res, extract_detect_res
import time
import cv2
import requests
import os
import torch
import torch.nn as nn
import torchvision.utils
from torchvision.models import mobilenet_v2, resnet18
from advertorch.utils import predict_from_logits
from advertorch.utils import NormalizeByChannelMeanStd
from robust_layer import GradientConcealment, ResizedPaddingLayer
from timm.models import create_model
from advertorch.attacks import LinfPGDAttack
from advertorch_examples.utils import ImageNetClassNameLookup
from advertorch_examples.utils import bhwc2bchw
from advertorch_examples.utils import bchw2bhwc
from skimage.io import imread
device = "cuda" if torch.cuda.is_available() else "cpu"
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
model_path = '/home/myjomework/weights/best-fp16.tflite'
# 定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
### 常规模型加载
model = mobilenet_v2(pretrained=True)
# model=torch.load("/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/Lesson5_code/model/mobilenet_v2-b0353104.pth")
model.eval()
model = nn.Sequential(normalize, model)
model = model.to(device)
### 替身模型加载
model_su = resnet18(pretrained=True)
model_su.eval()
model_su = nn.Sequential(normalize, model_su)
model_su = model_su.to(device)
### 对抗攻击监测模型
class Detect_Model(nn.Module):
def __init__(self, num_classes=2):
super(Detect_Model, self).__init__()
self.num_classes = num_classes
#model = create_model('mobilenetv3_large_075', pretrained=False, num_classes=num_classes)
model = create_model('resnet50', pretrained=False, num_classes=num_classes)
# self.multi_PreProcess = multi_PreProcess()
pth_path = os.path.join("/home/myjomework/models", 'track2_resnet50_ANT_best_albation1_64_checkpoint.pth')
#pth_path = os.path.join("/Users/rocky/Desktop/训练营/Lesson5_code/model/", "track2_tf_mobilenetv3_large_075_64_checkpoint.pth")
state_dict = torch.load(pth_path, map_location='cpu')
is_strict = False
if 'model' in state_dict.keys():
model.load_state_dict(state_dict['model'], strict=is_strict)
else:
model.load_state_dict(state_dict, strict=is_strict)
normalize = NormalizeByChannelMeanStd(
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
# self.model = nn.Sequential(normalize, self.multi_PreProcess, model)
self.model = nn.Sequential(normalize, model)
def load_params(self):
pass
def forward(self, x):
# x = x[:,:,32:193,32:193]
# x = F.interpolate(x, size=(224,224), mode="bilinear", align_corners=True)
# x = self.multi_PreProcess.forward(x)
out = self.model(x)
if self.num_classes == 2:
out = out.softmax(1)
#return out[:,1:]
return out[:,1:]
if __name__ == '__main__':
# 设置测试集路径
source = "/home/myjomework/images/"
images_list = os.listdir(source)
print(images_list)
frame_id = 0
# 读取数据集
for image_name in images_list:
frame_id += 1
print("frame_id:", frame_id)
image_path = os.path.join(source, image_name)
frame = cvs.imread(image_path)
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.25, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# cvs.imshow(res_img)
# 测试结果展示停顿
# time.sleep(5)
# 图片裁剪,提取车辆目标区域
cut_img =extract_detect_res(frame, pred, image_name)
# cvs.imshow(cut_img)
# cap.release()
# cv2.destroyAllWindows()
##不进行攻击,直接输入检测模型
img = torch.tensor(bhwc2bchw(frame))[None, :, :, :].float().to(device)
#detect_model = Detect_Model().eval().to(device)
#detect_pred = detect_model(img)
imagenet_label2classname = ImageNetClassNameLookup()
pred = imagenet_label2classname(predict_from_logits(model(img)))
print("test output:", pred)
### 对抗攻击:PGD攻击算法
pred_label = predict_from_logits(model_su(img))
adversary = LinfPGDAttack(
model_su, eps=0.5 / 255, eps_iter=2 / 255, nb_iter=4,
rand_init=True, targeted=False)
### 完成攻击,输出对抗样本
advimg = adversary.perturb(img, pred_label)
### 对抗攻击监测
detect_model = Detect_Model().eval().to(device)
detect_pred = detect_model(advimg)
print(detect_pred)
#检测模型判断如果是对抗样本则进行喵提醒
if detect_pred > 0.5:
### 迁移攻击样本保存
#save_path = "/home/mystudy/Aidlux/Intelligent_transportation/Lesson5_code/myhomework/1/adv_results/"
#torchvision.utils.save_image(advimg.cpu().data, save_path + imgname+"_adv_image.png")
# 填写对应的喵码
id = 't4ebTaH'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "出现对抗攻击风险!!"
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)
3.2.2 用Aidlux实现对抗检测视屏
采用Aidlux实现对抗检测视屏演示
通过读取含有对抗样本的视频,采用对抗检测网络进行测试,如果发现对抗样本,发送警告到喵提醒公众号。
(视频转了好几次导致有点模糊了,后面再换清晰的吧)
**4 致谢 **
再次感谢大白老师和Rocky老师的悉心指导,祝工作顺利!
也希望我能在AI赛道上永远保持激情、热情。
5 作业所有代码如下
链接: https://pan.baidu.com/s/1f-951xwVi90Th-oBSCV7Ag 提取码: 5k6w