数据科学导论复习
文章目录
- 第一章 绪论
-
- 1.1 为什么要研究/学习数据科学
- 1.2 数据科学的基本概念
- 1.3 数据科学基本流程和数据流
- 第二章 问题与目标
-
- 2.1 用户层面的问题与目标
- 2.2 数据科学层面的问题与目标
- 第三章 数据获取
-
- 3.1 前提假设与数据方案设计
- 3.2 总体与抽样
- 3.3混杂因素和 A/B Testing
- 第四章 Python基础
- 第五章 探索性数据分析
-
- 5.1数据检查
- 5.2数据预处理
-
- 缺失处理
- 异常处理
- 冗余处理
- 5.3 描述性统计
-
- 位置性测度
- 离散型测度
- 图形化描述性统计
- [基本要求]
- 第六章 建模与性能评价
-
- 6.1 统计建模
- 6.2 回归模型
- 6.3 朴素贝叶斯模型
- 6.4 分类模型的性能评价
- 6.5 决策树
- 6.6 有监督学习模型与无监督学习模型
- 6.7 偏差-方差权衡
- 6.8 参数的网格搜索
- 6.9 集成学习
- 第七章 结果展示
-
- 7.1 面向不同对象的结果展示
- 7.2 数据可视化
第一章 绪论
[基本内容]
1.1 为什么要研究/学习数据科学
1.2 数据科学的基本概念
维基百科——应用科学的方法、流程、算法和系统从多种形式的结构化或非结构化数据中提取知识和洞见的交叉学科
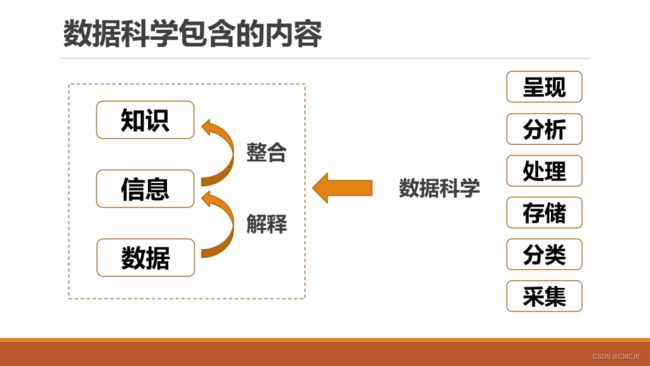
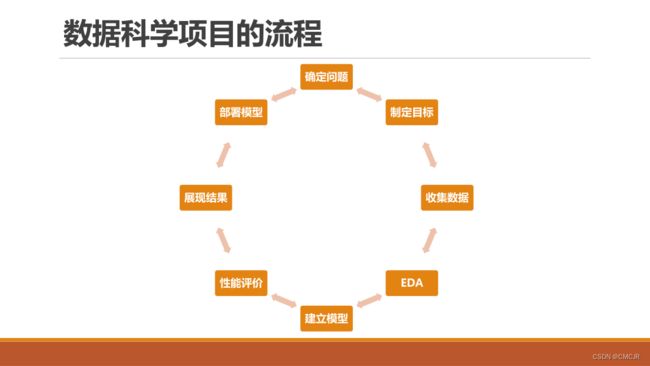
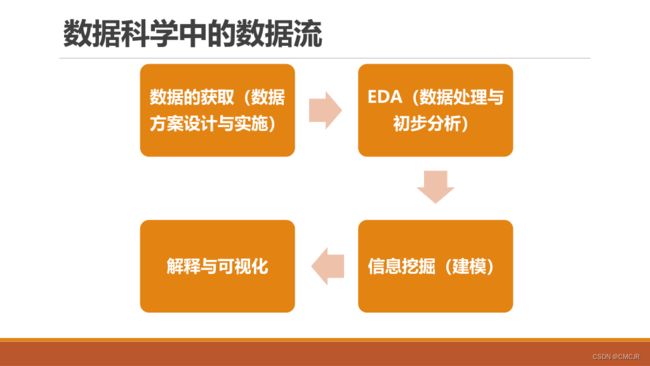
1.3 数据科学基本流程和数据流
[基本要求]
1.掌握:数据科学的基本概念
2.理解:数据科学基本流程和数据流
3.了解:学习/研究数据科学的目的与意义
第二章 问题与目标
[基本内容]
2.1 用户层面的问题与目标
2.2 数据科学层面的问题与目标



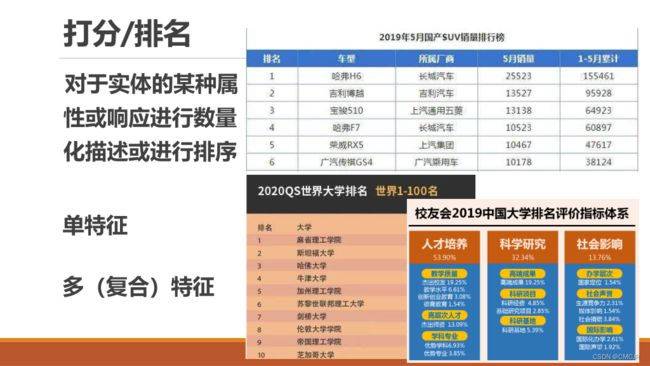


[基本要求]
1.掌握:用户层面与数据科学层面的问题与目标分别怎么确定
2.理解:数据科学的问题与目标的含义
第三章 数据获取
[基本内容]
3.1 前提假设与数据方案设计
3.2 总体与抽样
样本的两个必要条件:
- 容量不能太小(>30)
- 无偏抽样(抽样的过程不受个体性质的影响)
3.3混杂因素和 A/B Testing
辛普森悖论
现象描述: 每个分组里面A的优势都明显,但是总体上B的优势更大。
原因: 混杂因素
就是说,有些因素会对分组的总体造成影响,但是必须认识到这一点,只要适当剔除就可以了。

[基本要求]
1.掌握:数据获取的常用方法
2.理解:前提假设与数据方案设计、总体与抽样、混杂因素和 A/B Testing 的含义
第四章 Python基础
numpy.ndarray 的内存方式优于列表,通常适用于类型一致的数据,支持向量运算
DataFrame基础知识 具体参考DataFrame的使用方法
reshape方法可以重塑数组的维度 reshape()函数详解
#例4-4-9
import pandas as pd
import numpy as np
my_dataframe=pd.DataFrame(np.random.randn(4,5),index=['a','b','c','d'],columns=['A','B','C','D','E'])
my_dataframe[['B','C']]
my_dataframe[['B']] #指定访问列2,返回值有列标题,返回值仍是dataframe
my_dataframe['B'] #指定访问列3,返回值无列标题,返回值是序列series
my_dataframe.iloc[1] #指定访问行1,指定行号
my_dataframe.loc['b'] #指定访问行2,指定行索引
第五章 探索性数据分析
[基本内容]
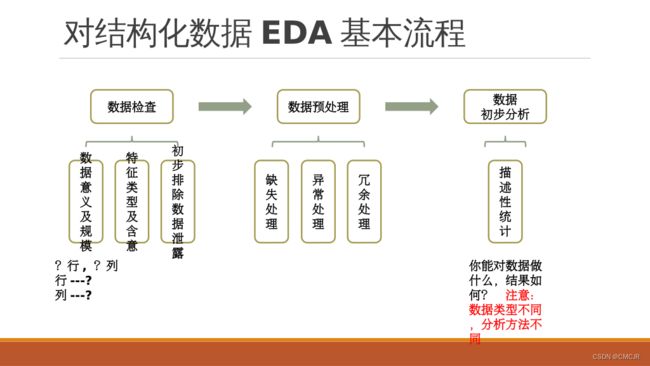
5.1数据检查
print(my_data.info()) #datdaframe的info方法可以返回对数据的一些总结
x = my_data.groupby(['Pclass']) #groupby分类获取数据
5.2数据预处理
缺失处理
data.head(10) #显示数据前10行,不填默认为5
data.isnull() #检测数据缺失值,返回True或False(缺失)
data.isnull().sum() #统计缺失值
- 缺失值丢弃
data.dropna(axis=0) #行丢弃 (丢弃包含NaN的数据)
data.dropna(axis=1) #列丢弃
- 缺失值填充
#字典填充
mean_Age = int(my_data[['Age']].mean()[0]) #取平均年龄
my_dict = {'Age':mean_Age,'Cabin':'haha'}
data1 = data.fillna(my_dict)
#邻近值填充
data2 = data.fillna(method = 'ffill')
#参数method = 'ffill' 缺失值之前最有效的邻近值来填充
#method = 'bfill' 缺失值之后最有效的邻近值来填充
异常处理
冗余处理
data.duplicated() #duplicated()函数判断是否有重复行,返回true或false
data1 = data.drop_duplicates() #drop_duplicates()函数直接删除重复行
线性相关分析: Dataframe.corr(method=’pearson’)求线性相关系数,当其接近1或-1,则说明两个数据存在强的线性相关或反相关,有较大冗余;等于0,则没有线性相关。
data.corr(method = 'person')
corr函数详细说明
5.3 描述性统计
位置性测度
#例5-3-3 Pandas数据框求位置性测度举例
import pandas as pd
import numpy as np
data = pd.read_csv("Titanic.csv")
print('对Fare的位置性测度统计结果:')
print('均值: ', data[['Fare']].mean()[0])
print('中位数: ', data[['Fare']].median()[0])
print('第25百分位数:', data[['Fare']].quantile(q = 0.25)[0])
print('众数: ', data[['Fare']].mode().values[0,0])
#mean(),median(),quantile()返回的都是Pandas的series的序列结构,直接用[0]访问
# mode()返回的是DataFrame的结构,所以用二维数组[0,0]的方式来访问
离散型测度
print('对Fare的离散性测度统计结果:')
print('变化范围: [',data[['Fare']].min()[0],'\t',data[['Fare']].max()[0], ']')
print('极差: ',data[['Fare']].max()[0] - data[['Fare']].min()[0])
print('方差: ',data[['Fare']].var()[0])
print('标准差: ',data[['Fare']].std()[0])
print('变异系数:',data[['Fare']].std()[0] / data[['Fare']].mean()[0])
图形化描述性统计
- 直方图
data[['Fare']].hist(bins=40,figsize=(18,5),xlabelsize=16,ylabelsize=16)
直方图详细用法
- 箱型图
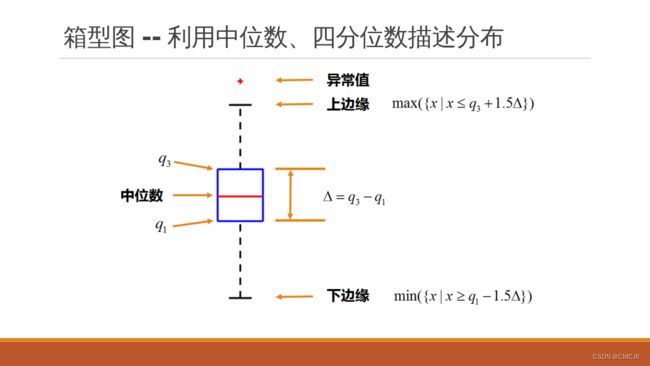
data[['Fare']].boxplot()
箱型图详细用法
- 散点图
scatterplot = pd.plotting.scatter_matrix(data,alpha = 0.3,figsize = (10,10),
diagonal = 'hist',color = colors,marker ='o',grid=True)
# alpha表示透明度
# diagonal = "hist" 选择显示对应特征的直方图
# color = 可以设置颜色
# marker ='o' 散点图案
# grid=True 显示坐标线
散点图详细用法
[基本要求]
1.掌握:探索性数据分析的常用方法与一般流程
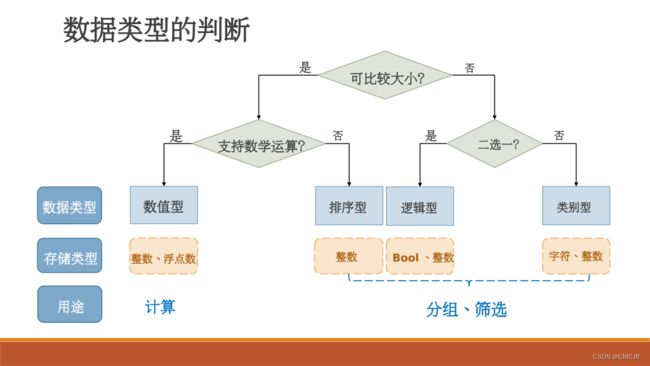



2.理解:数据检查、数据预处理与描述性统计的主要含义
第六章 建模与性能评价
[基本内容]
6.1 统计建模
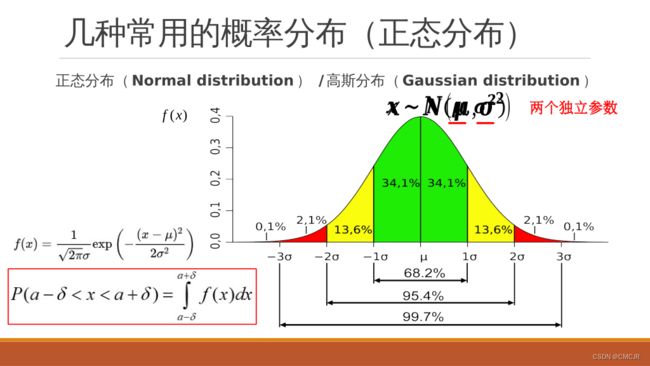
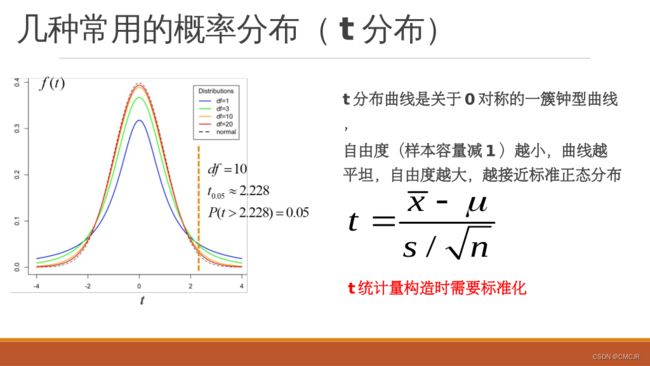


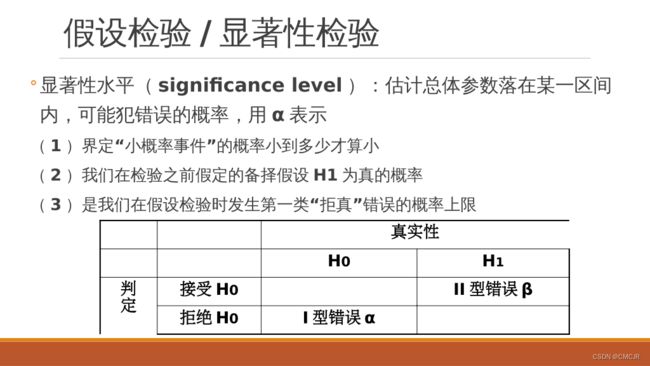

代码展示与说明:
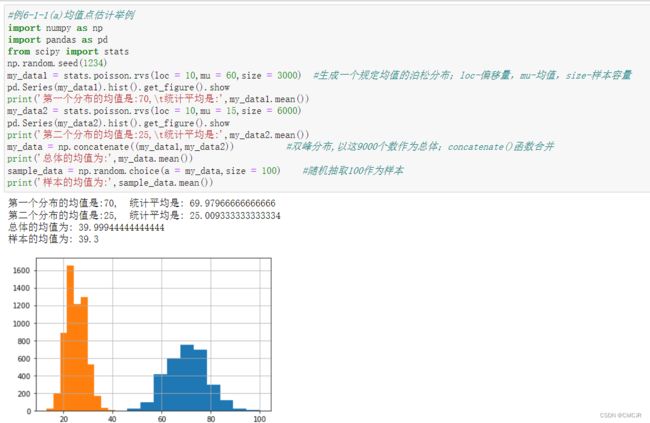

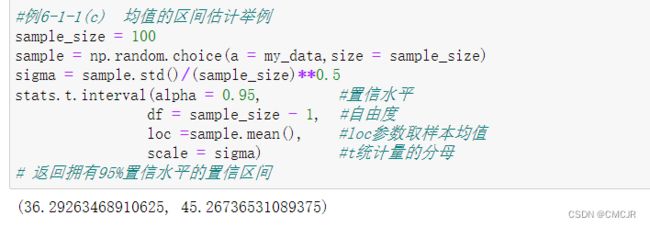
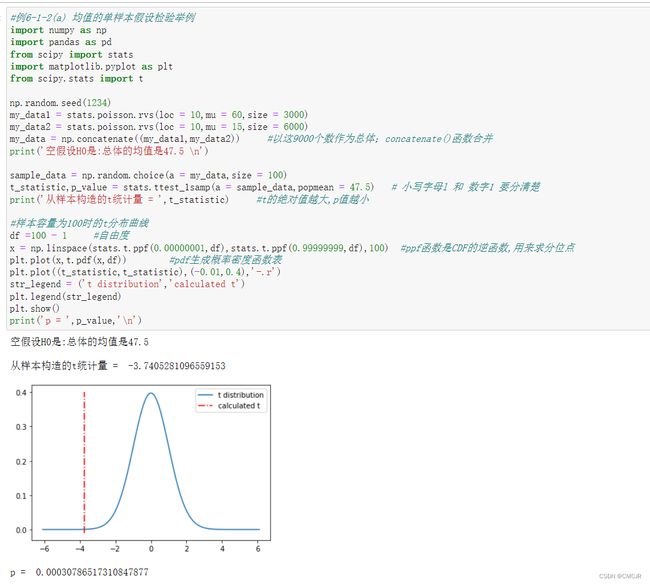
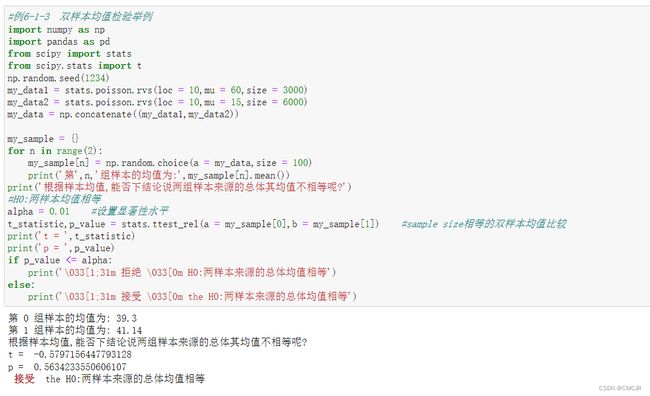
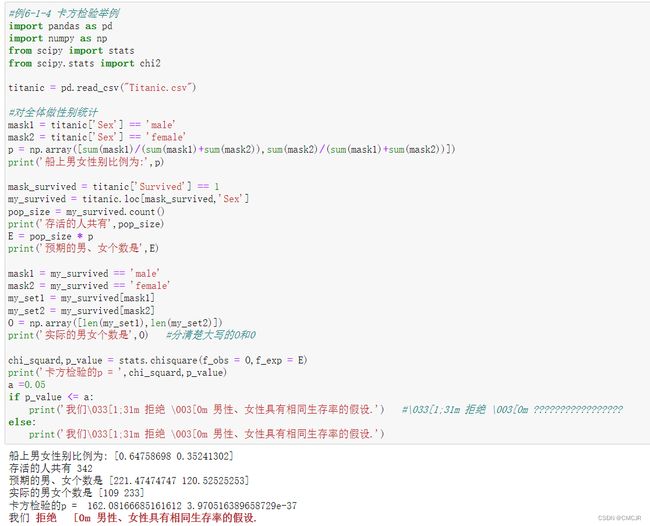
部分代码解析——回归/朴素贝叶斯/决策树/K-means
6.2 回归模型
6.3 朴素贝叶斯模型
6.4 分类模型的性能评价
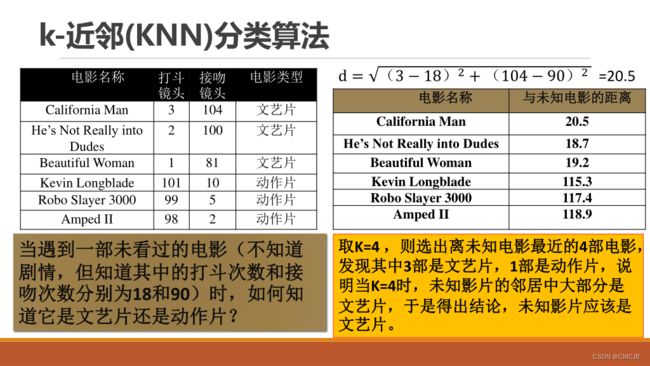
6.5 决策树
决策树学习
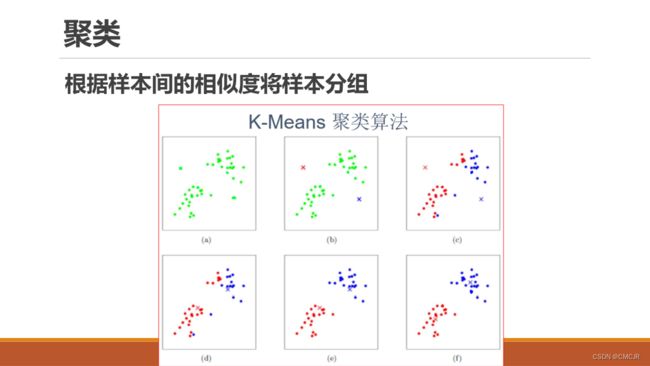
6.6 有监督学习模型与无监督学习模型
K-means学习
6.7 偏差-方差权衡
6.8 参数的网格搜索
6.9 集成学习
[基本要求]
1.掌握:数据科学常用的建模与性能评价的方法;
2.理解:统计建模、回归模型、朴素贝叶斯模型、决策树及典型的机器学习模型;
3.了解:偏差-方差权衡、参数的网格搜索与集成学习
第七章 结果展示
[基本内容]
7.1 面向不同对象的结果展示
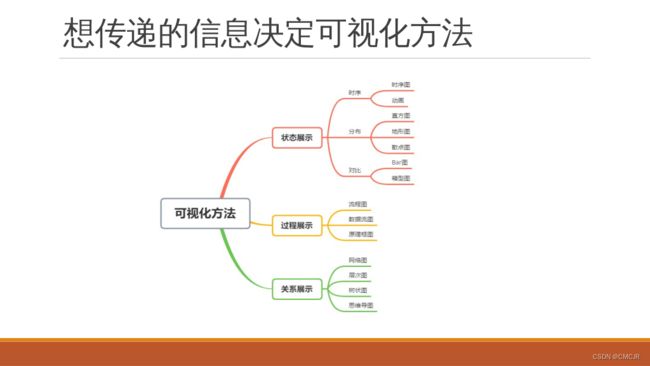
7.2 数据可视化
[基本要求]
1.掌握:数据可视化的一般方法;
2.理解:如何根据面向对象的不同进行结果展示;