【论文笔记】DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-move Forgery Detec
DOA-GAN: Dual-Order Attentive Generative Adversarial Network for Image Copy-move Forgery Detection and Localization
发布于CVPR2020
论文链接:https://ieeexplore.ieee.org/document/9157762
摘要
本文提出了一个具有双阶注意力模型的生成对抗网络来检测和定位复制移动伪造。 在生成器中,一阶的注意力模型用于捕捉 copy-move 对象的位置信息;二阶的注意力模型用于探索更多的 patch 一起共同出现的具有判别性的特征信息。这两个注意力图都是从亲和矩阵(又叫相似度矩阵)中提取的,并用于融合位置感知和共现特征,用于网络的最终检测和定位分支。 判别器网络的设计是为了进一步保证更准确的定位结果。 据我们所知,我们是第一个从亲和矩阵出发,提出了一个具有一阶注意力机制的网络体系结构。
引言
图1是使用对象克隆(顶部)和对象删除(底部)进行复制-移动伪造的两个示例。从左到右分别是原始图像、伪造图像和真实图像。我们的目标是自动检测和定位伪造图像中的源(绿色)和目标(红色)区域。其实,将复制移动与经常发生的偶然相似性区分开来非常具有挑战性。

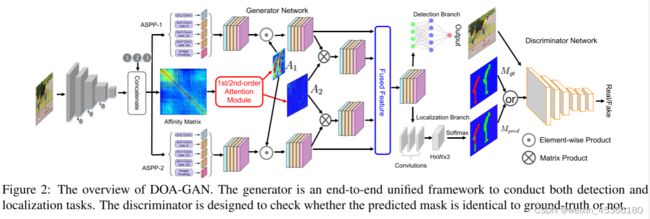
本文提出了一种用于复制移动伪造检测和定位的双阶注意生成对抗网络(DOA-GAN)。 如图2所示,生成器是基于深度卷积神经网络的端到端统一框架。 给定输入图像,我们基于每个像素处的提取的特征矢量来计算亲和矩阵。 我们设计双阶注意模块以产生一阶注意力图A1 ,所述一阶注意力图A1能够探索复制移动感知位置信息,以及二阶注意力图A2以捕获更精确的补丁相互依存性。 最后的特征表示是用这两个注意力映射形成的,然后馈送到检测分支中以输出检测置信度分数和定位分支以产生预测掩码,在所述预测掩码中,源区域和目标/伪造区域被区分。 同时,辨别器被设计来检查预测的掩码是否与GT相同。
直观上,双阶注意模块设计为首先高亮图像中所有相似区域,无论是否被操纵; 然后将非操纵的相似区域与复制移动(源和目标)区域区分开来。 通常,复制移动伪造中的源和目标区域比偶然相似的区域像素更相似,即使在旋转和缩放等变换之后也是如此。
我们的双阶注意模块是基于亲和矩阵计算的,它覆盖了特征的二阶统计量,并对更具鉴别性的表示起着关键作用。 这促使我们利用二阶共现注意图A2进行细粒度的区分,以区分复制-移动伪造与附带的对象和纹理相似性。 另外,我们观察到,非对角线元素中的高值表明补丁之间复制-移动空间关系的高可能性。 这一观察启发我们探索一阶注意力图A1,以关注复制-移动区域感知特征表示。 本文对亲和矩阵进行细化和归一化,取每列的前k个值,并对其进行整形,形成一个具有k个通道的三维张量。 然后将张量输入到简单的卷积中,形成我们最终的一阶注意力图A1,它能够给予源和目标区域更多的注意力。
我们在生成器和判别器之间采用对抗式训练过程来生成更精确的定位掩码。 随着epoch的增加,生成器和判别器都改进了它们的功能,从而使预测掩码迭代地变得与GT一样。 因此,足够多的epoch会导致训练的收敛,我们使用生成器中的学习参数来输出检测置信度分数和指示源和目标/伪造区域的预测定位掩码。
主要贡献
- 提出了一种用于图像复制-移动伪造检测和定位的双阶注意生成对抗网络。
- 我们的一阶的注意力模型用于捕捉 copy-move 对象的位置信息;二阶的注意力模型用于探索更多的 patch 一起共同出现的具有判别性的特征信息。 这两种注意力映射为复制-移动检测和定位提供了更有区分度的特征表示。
- 大量实验有力地证明,所提出的 DOA-GAN 在多个基准数据集上的检测和定位质量方面明显优于最先进的方法。
方法
所提出方法的框架如图 2 所示。

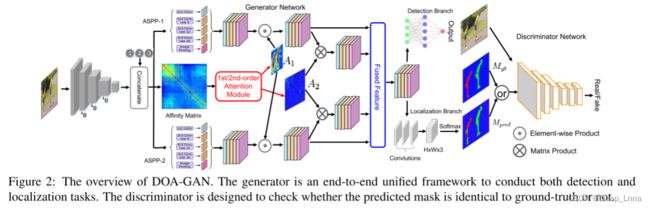
生成器网络

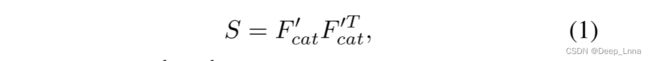
![]()

双阶注意力模块
双阶注意力模块的设计如图 3 所示,用于提取复制移动感知区域注意力图 A1 和共现注意力图 A2。然而,当我们计算图像的自相关时,S 将沿对角线具有更高的值,因为对角线值表示图像的一部分与其自身的相关性。为了解决这个问题,我们定义了一个操作 G
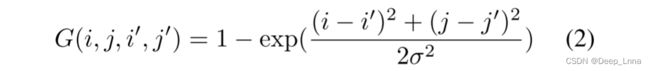
并调整大小为hw*hw。G使用高斯核减少了图片的相同部分的相关性分数(自己跟自己相关性肯定高)。![]()
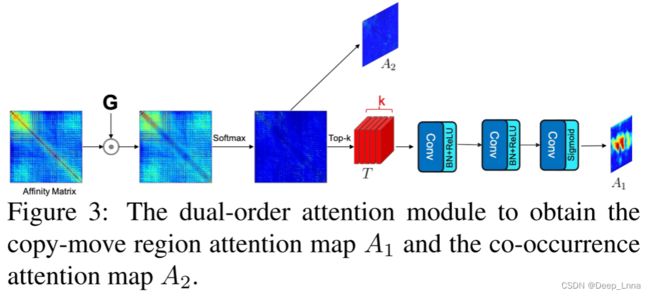
计算第 i 行与第 j 行中patch匹配的可能性:


如图4所示,复制移动区域注意图A1是通过抑制背景非操纵区域同时突出显示最有可能参与复制移动操作的区域而生成的。
为了充分利用patch-to-patch之间的依赖,对上述得到的亲和矩阵进行归一化,并且得到并发注意图A2。
空洞空间金字塔池 (ASPP) 块

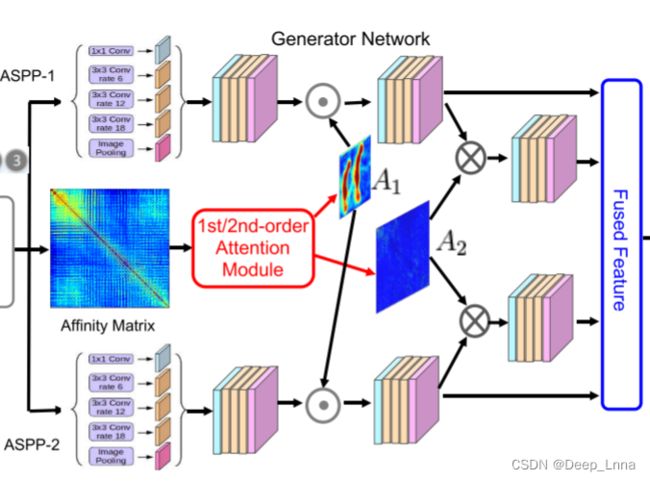
特征融合


检测分支和定位分支

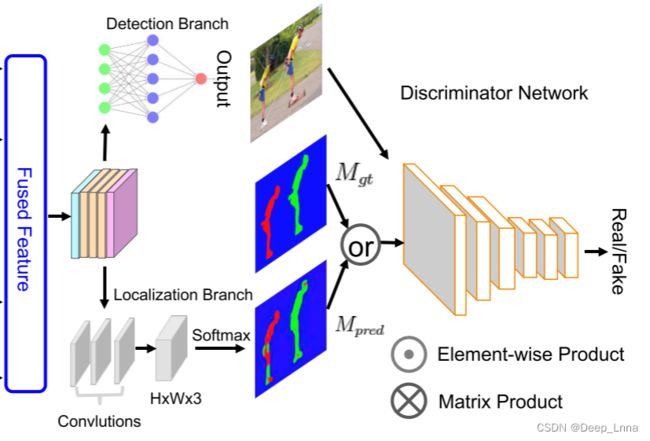
判别器网络

损失函数
损失函数由对抗性损失、交叉熵损失和检测损失组成:



实验
数据集
为了研究所提出的DOA-GAN方法对于copy-move伪造检测和定位的有效性,在三个基准数据集上进行了实验,分别为:USC-ISI CMFD数据集,CASIA CMFD 数据集,CoMoFoD数据集。
- USC-ISI CMFD:包含用于训练的80K,验证的10K和测试的10K图像。
- CASIA CMFD:包含1313张伪造图像以及其真实的副本。
- CoMoFoD:包含5000幅伪造图像,200幅基础图像以及25个操作类别,涵盖了5种操作以及后处理方法。
评价指标
通过平均每幅图像的分数,为三个类别(原始背景P,源S,目标T)给出了图像级(检测)和像素级(定位)的precision, recall, 和 F1 score 。
USC-ISI CMFD数据集的实验
下表1为在USC-ISI CMFD数据集上的进行伪造定位的结果(像素级定位):
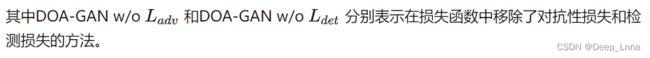

下表2在USC-ISI CMFD数据集上进行检测的结果(图像级检测):

观察结果发现:
- 没有 L a d v L_{adv} Ladv 的 DOA-GAN 在所有指标方面都比 BusterNet 表现更好,这清楚地证明了DOAGAN 中的生成器;
- DOA-GAN 在检测和定位任务上都比没有 L a d v L_{adv} Ladv 的 DOA-GAN 整体效果更好,这证明了 DOA-GAN 中鉴别器的鉴别能力的有效性,
- 没有 L d e t L_{det} Ldet 的DOAGAN比 DOAGAN中的检测性能更差,这证明了 L d e t L_{det} Ldet的有效性,
- FOA-GAN 和 SOA-GAN 在所有指标上的表现都比 DOA-GAN 差,除了原始像素的 F1 分数,这表明一阶和二阶注意相互补充,以提高复制移动伪造检测和定位的性能,
- U-Net 和 NA-GAN 基线的性能比 DOA-GAN、SOA-GAN 和 FOA -GAN差得多,尤其是在source mask的定位方面,证明了亲和力计算的功效。这间接验证了我们的双阶注意力模块的有效性。
为了进一步了解 DOA-GAN 方法的优势,我们还在图 5 中提供了一些可视化结果。正如我们所见,我们的 DOA-GAN 能够生成比 BusterNet、 FOA-GAN 和 FOA-GAN 更准确的mask。下图从左到右分别是输入图像;BusterNet、FOA-GAN、SOA-GAN 和 DOA-GAN 的结果;和GT。目标区域(作缩放变换)显示为红色,源区域显示为绿色。

CASIA CMFD 数据集上的实验
与USC-ISI CMFD数据不同,CASIA CMFD数据集并不会提供区分源和目标的Ground Truth Mask,因此更具有挑战性。下表3为在CASIA CMFD上实验的结果:
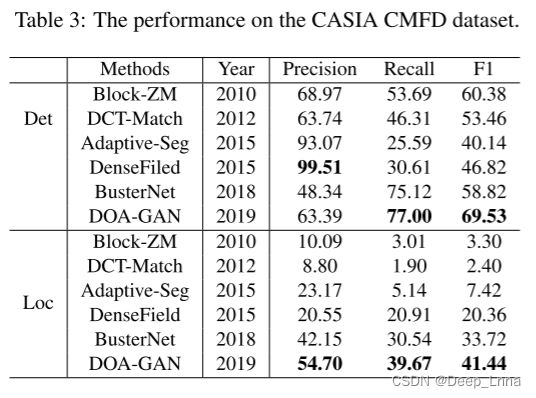
表 3 显示了与 CASIA CMFD 数据集上其他基线的性能比较。正如我们所看到的,我们提出的 DOA-GAN 在除检测精度之外的所有指标方面表现最好。这有力地证明了我们提出的方法的有前途的优势。图 6 提供了一个可视化结果,表明所提出的 DOA-GAN 能够检测到比 DenseField 和 BusterNet 更准确的掩码,用于复制移动伪造操作。

CoMoFoD数据集上的实验
下表4展示了在CoMoFoD数据集上的表现:

DOA-GAN在出了精确度以外的检测和定位方面取得了最好的性能。 请注意,在此数据集中应用不同类型的转换来创建复制-移动操作的图像,例如平移、旋转、缩放、组合和失真。 各种后处理方法,如JPEG压缩,模糊,添加噪声,颜色减少,也适用于所有伪造和原始图像。
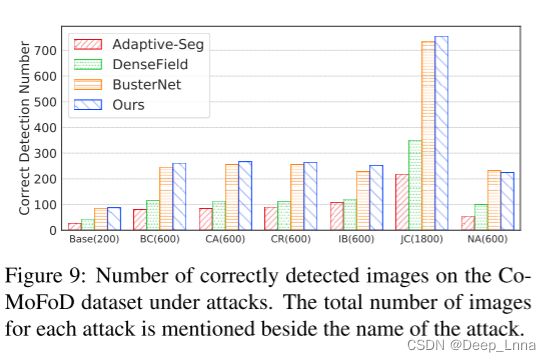
将每种后处理方法作为一种特定的攻击,利用该数据集进一步分析了我们提出的DOA-GAN在不同攻击下的效果。
图7提供了一个可视化示例。 图9显示了在不同类型的攻击下,Comofod 数据集上正确检测到的图像数量(在攻击名称旁边提到了每次攻击的图像总数),其中如果图像的像素级F1得分大于30%,则正确检测到图像。 图8显示了所有攻击的F1得分。 从这两个图中,我们可以看到DOA-GAN是鲁棒的,在所有类型的攻击下都表现最好。


讨论
DOA-GAN能够利用复制-移动区域的注意力来提取操作注意力特征,并考虑了块间相互依赖的共现特征。 但是,当复制区域刚刚从均匀背景中提取并粘贴在同一背景上时,可能会失败。 当比例尺发生重大变化时,它也可能失败。 我们在图10中提供了两个失败案例。 正如我们所看到的,第一个示例的背景是均匀的,第二个示例中复制移动区域的规模非常小。

扩展到其他操纵类型
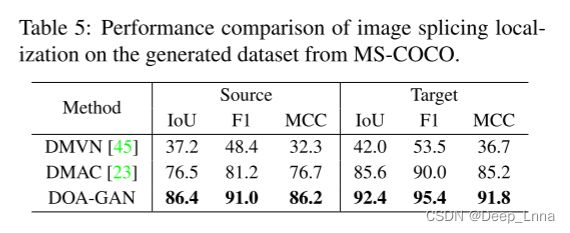
DOA-GAN是基于在同一图像上计算的亲和矩阵。 它很容易扩展为由两幅不同的图像(即施主图像和目标图像)计算出的亲和矩阵,相应的操作类型包括图像拼接和视频复制移动。 对于图像拼接操作,我们在同一个合成图像拼接数据集上训练DOA-GAN和两种最先进的方法DMVN和DMAC,然后对由42,093个测试图像对组成的MS-COCO生成的数据集进行评估。 表5是基于MS-COCO生成数据集的图像拼接定位性能比较,它的结果证明了DOA-GAN在剪接定位方面的优越性。
对于视频的copy-move操作,可以当做是视频中两个连续帧序列之间的帧间拼接。以下是评估了DOA-GAN在由视频对象分割数据集生成的视频copy-move数据集上的性能:

结论和今后的工作
本文提出了一种用于复制-移动伪造检测和定位的双阶注意生成对抗网络。生成器中设计了双级注意模块,用于提取操作位置感知注意图和patch之间潜在的共现关系。鉴别器是为了进一步确认预测mask的准确性。与以前的先进技术相比,所提出的DOA-GAN已经从经验上表明可以从源区域产生更精确的复制-移动mask和更好地区分复制-移动目标区域。
我们未来的工作包括扩展当前的工作,以识别卫星图像中的图像级伪造,并解决其他具有挑战性的视觉任务,如协同显著性检测和定位。