使用HOG+SVM进行人脸检测
一、实验内容
- 利用特征训练一个分类器(SVM)
- 按照sliding window思想编写代码,提取HOG并生成候选框;
- 使用分类器进行分类(Scoring each proposal)
- 编写非极大值抑制算法,去除一些置信度较低的候选框, 得到预测结果,实现人脸检测。
- 对实验结果进行分析。
二、实验原理
2.1 图片的HOG特征
概念:HOG,方向梯度直方图,是常用的一种目标检测的特征描述子。
提取流程:检测窗口、归一化图像、计算梯度、统计直方图、梯度直方图归一化、得到HOG特征向量。
检测窗口:HOG的检测窗口称为window,每个window包括几个块block,每个块是由细胞cell组成的,具体如下图所示:

图 1 HOG检测窗口的划分
黑色表示窗口的划分,蓝色表示块的划分,黄色表示细胞的划分。其中每个cell静止不动计算每个像素的方向梯度,block和window滑窗移动,实现不同区域的检测。
归一化图像:这一步的目的是减少光照因素影响,将整个图像进行一个归一化,分为Gamma空间和颜色空间归一化,可以避免在图像的纹理强度中,局部的表层曝光贡献度的比重较大的情况。其中gamma值可以根据效果修改,代码中默认为0.5。
计算梯度:计算图像的水平和竖直方向的梯度,并根据横纵坐标的梯度,计算整体梯度方向,可以参考平面直角坐标系中斜率的计算。代码中可以使用Sobel算子进行卷积计算,再得到tan值。
构建梯度直方图:梯度直方图是在cell层级进行构建的,横坐标的区间称为bins,若bins为9,则将180°等分为9个区间,每个区间横跨20°,先判断像素点梯度方向所属的区间,再根据像素点的梯度值和方向大小进行加权统计,可用线性加权、平方根等各种加权方法。
直方图归一化:在block一层,对每个cell进行颜色、亮度的归一化,去掉光影、阴影的影响。
得到特征向量:通过滑窗,将提取到的HOG特征首尾相连,形成一个大的一维向量,就是最后得到的特征向量。
2.2 非极大值抑制(NMS)
概念:NMS,非极大值抑制,原理是找到所有局部最大值,并抑制非局部最大值。
目标检测推理的过程中会产生很多的候选检测框,很多检测框都是检测同一个目标,导致候选框之间的重叠部分过多,这时使用非极大值抑制可以找出局部最优的框,去掉重复部分。
算法流程:根据置信度得分进行排序、选择置信度最高的候选框加入到最终结果列表,并在候选框中删除、计算所有边界框的面积、计算置信度边界框与其余边界框的IoU、删除大于阈值的候选框,直至候选集为空。
IoU:交并比,计算两个边框交集和并集的比值,可参考下图:
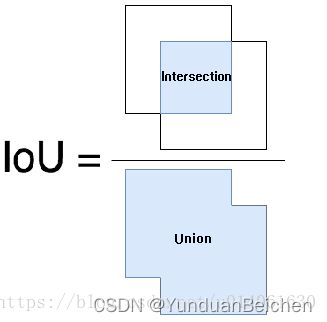
图 2 IoU计算示意图
PS:图片来自博客:目标检测之 IoU_黑暗星球的博客-CSDN博客_目标检测iou
三、实验结果与分析
3.1 实验流程与结果数据
使用HOG特征+SVM分类器进行人脸检测。
流程为:构建负例数据集、提取图像HOG特征、训练SVM分类器、人脸检测。
3.1.1 构建负例数据集
实验使用的数据集是RAF-DB的子集,有原图、人脸裁剪图、检测边界框,但无负例图片,需要使用原图和边界框log文件构建非人脸图片,核心代码如下:
- def build_neg_img(original_folder, box_folder, output_folder):
- mkdir(output_folder)
- for filename in tqdm(os.listdir(original_folder)):
- original_img = cv2.imread(original_folder + "\\" + filename)
- axis_list = get_box(box_folder, filename)
- # 设边界框的左上角为M点,右下角为N点,图片的原点位于左上角,x轴向右为正方向,y轴向下为正方向
- Mx = axis_list[0]
- My = axis_list[1]
- Nx = axis_list[2]
- Ny = axis_list[3]
- box_width = Nx - Mx
- box_height = Ny - My
- # 与人脸边界框错开构建负例图像,左上角起始点为K
- if Mx - box_width >= 0:
- # 在边界框左侧框选同样大小的负例框
- Kx = Mx - box_width
- Ky = My
- elif My - box_height >= 0:
- # 在边界框上方选同样大小的负例框
- Kx = Mx
- Ky = My - box_height
- else:
- # 在整个图像的左上角选边界框的小的负例框
- Kx = original_img.shape[1] - box_width - 1
- Ky = 0
- neg_img = original_img[Ky: Ky + box_height, Kx: Kx + box_width, :]
- cv2.imwrite(output_folder + "\\" + filename[:-4] + "_neg.jpg", cv2.resize(neg_img, (100, 100)))
最终结果:

图 3 负例图片构建结果
3.1.2 提取HOG特征
使用skimage库中的hog函数对正负例图像提取hog特征,并将提取到的特征向量存储为pkl文件,便于后续实验室用,核心代码如下:
- def get_hog_skimage(img, orientations=10, pixels_per_cell=[12, 12], cells_per_block=[4, 4], visualize=False):
- # 默认情况下,transform_sqrt=True,进行gamma correction,将较暗的区域变量,减少阴影和光照变化对图片的影响。
- features = ft.hog(img, orientations=orientations, pixels_per_cell=pixels_per_cell, cells_per_block=cells_per_block,
- visualize=visualize, transform_sqrt=True)
- return features
最终结果:(每张图片提取到的HOG向量长度为1*4000)

图 4 存储HOG特征结果
3.1.3 训练SVM分类器
调用sklearn库的SVC类,结合前一步提取的HOG特征,训练SVM分类器,并在测试集上验证分类器的效果,最后将训练好的SVM模型存储为SVM.model文件,便于预测使用。核心代码如下:
- # 训练svm
- classifier = SVC(kernel='linear')
- classifier.fit(X_train, Y_train)
- y_pred = classifier.predict(X_test)
- true = np.sum(y_pred == Y_test)
- print("预测正确的数目为:", true)
- print('预测错的的结果数目为:', Y_test.shape[0] - true)
- print('预测结果准确率为:', true / Y_test.shape[0])
- # 保存svm模型
- mkdir(model_pkl_folder)
- with open(model_pkl_folder + "\\svm.model", 'wb+') as f:
- pickle.dump(classifier, f)
- print("SVM模型保存完成!")
- f.close()
最终结果:
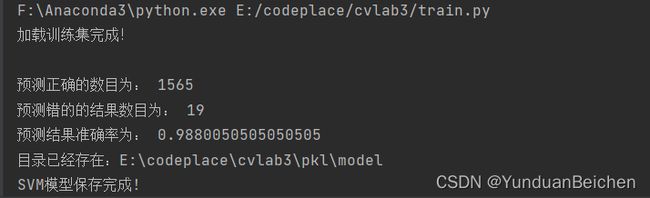
图 5 SVM在测试集上的表现
3.1.4 人脸检测
对原图进行滑窗处理,并使用SVM分类器对各个窗口进行检测,将检测到的人脸区域添加到候选集,核心代码如下:
- def sliding_window(img_name, img, classifier):
- # 设置初始窗长与原图高的比例为1:8
- scale = 4
- # 设置初始滑窗长度(正方形)和步长
- win_size = img.shape[0] // scale
- # 保证步长大于1
- step_size = max(win_size // 10, 1)
- candidate_box = []
- score = []
- while scale >= 2:
- # 设置窗的左上角为A点,初始化为(0,0)
- Ax = 0
- Ay = 0
- # 层优先滑窗
- while Ay + win_size < img.shape[0]:
- while Ax + win_size < img.shape[1]:
- win_hog = get_hog_skimage(cv2.resize(img[Ay:Ay + win_size, Ax:Ax + win_size], (100, 100))).reshape(
- (1, -1))
- y_pred = classifier.predict(win_hog)
- decision = classifier.decision_function(win_hog)
- # print(decision)
- if y_pred == 1:
- candidate_box.append((Ax, Ay, win_size))
- score.append(decision)
- Ax += step_size
- Ax = 0
- Ay += step_size
- Ay = 0
- # result的结构是:每行表示一个候选框,每行的元素依次是左上角x坐标、左上角y坐标、窗长
- if len(candidate_box) > 0:
- break
- else:
- scale -= 1
- win_size = img.shape[0] // scale
后续使用非极大值抑制,对候选集进行筛选,非极大值抑制核心代码如下:
- def nms(box, evaluation, threshold=0.2):
- """
- 对候选集进行非极大值抑制操作
- :param box: 候选集
- :param evaluation: 评价指标
- :param threshold: IoU阈值,默认为0.2
- :return: 非极大值抑制后的候选集
- """
- results = []
- while len(box) != 0:
- # step 1:根据置信度得分进行排序
- max_score = max(evaluation)
- max_index = evaluation.index(max_score)
- # step 2:选择置信度最高的候选框加入最终结果列表,并在候选框中删除
- results.append(box[max_index])
- del box[max_index]
- del evaluation[max_index]
- # step 3:计算所有边界框的面积(但是由于同一scale下的面积相等,所以可以省略此步骤)
- # step 4:计算置信度最高的边框与其余边框的IoU
- box_temp = [] # 此处解决for循环list下表超出问题,具体可以参考:Python遍历列表时删除元素_Sui Xin的博客-CSDN博客_python遍历列表时删除元素
- temp_score = []
- for index, value in enumerate(box):
- IoU = cal_IoU(results[-1], value)
- if IoU < threshold:
- box_temp.append(value)
- temp_score.append(evaluation[index])
- box = box_temp
- evaluation = temp_score
- return results
其中计算IoU的核心代码如下:
- def cal_IoU(box1, box2):
- """
- 两个边界框的交集部分除以它们的并集
- :param box1: 阈值最大的边框参数列表
- :param box2: 候选框参数列表
- :return: 二者的IoU
- """
- box1_area = box1[2] ** 2
- box2_area = box2[2] ** 2
- left_column_max = max(box1[0], box2[0])
- right_column_min = min(box1[0] + box1[2], box2[0] + box2[2])
- up_row_max = max(box1[1], box2[1])
- down_row_min = min(box1[1] + box1[2], box2[1] + box2[2])
- if left_column_max >= right_column_min or up_row_max >= down_row_min:
- return 0
- else:
- cross_area = (down_row_min - up_row_max) * (right_column_min - left_column_max)
- return cross_area / (box1_area + box2_area - cross_area)
滑窗处理时,设置最小scale与原图高的比值为1:4,最大比值为1:2,最后的选取方式分为:非极大值抑制结果和置信度最大结果,结果如下:
非极大值抑制结果:

图 6 人脸检测非极大值抑制结果
置信度最大结果:

图 7 人脸检测置信度最大结果
3.2 实验结果分析
本次实验在人脸检测部分使用了两种策略,最终的两种结果各有优略,结果分析将从这一部分入手。
3.2.1 非极大值抑制结果分析
在滑窗过后,候选框数目较多,并且有许多不符合最终要求。当IoU阈值设置足够低时(代码中为0.2),可以将大部分重叠的候选框去除,保留某一区域的最大值。
但是,非极大值抑制并不能将错误的候选框筛除,只能将每个部分多余的候选框剔除,所以单从人脸识别的角度来看,最终的结果并不尽如人意。
不过,由于保留了多个可能为人脸的区域,所以从多人脸识别角度来看,结果较好。PS:此处识别人脸的最大值与滑窗处理的scale比例设置有关,当比例足够小时,可以获得更多更小的候选框,也就能识别图中更多的“小”人脸。

图 8 NMS结果好的表现

图 9 NMS结果差的表现
3.2.2 置信度最大值结果分析
使用置信度最大值最为边界框的选取策略时,只会保留SVM得分最高的候选框,这就与训练集的正负例数量、质量密切相关,在本实验中,最终的结果十分准确,出错的概律不足5%(具体运行程序查看output\max文件夹下相关图片,或从图7中粗略评估),从人脸识别的角度来看,结果接近完美。
但是,由于只能保留得分最大的边界框,所以针对多人脸图片时,会出现遗漏检测的问题,只能检测到更完整、更符合正例、角度最正的人脸,所以,从多人脸检测的角度看,效果不尽人意。
另外,如果调整图片的宽高比,会得到不同的检测结果,在此猜测与提取HOG特征时,bins的选取有关(改变宽高比会改变像素的梯度方向,而bins会决定梯度方向直方图横坐标的区间,也就是在进行直方图统计和归一化时会出现不同)。同时训练集中正例的质量会直接决定最终选定的人脸,因此确保数据集质量也是实验的重要一环。

图 10 置信度最大值结果差的表现
.
图 11 置信度最大值结果好的表现
四、实验总结
本次实验遇到的问题与解决措施:
1、负例图片的选取。第一版代码使用提供的hog.mat作为正例特征,使用cifar-100数据集提取负例特征,虽然最终HOG特征维度可以对齐,但是具体的细节参数有所不同,并且cifar-100与人脸的差别过大,所以训练出的SVM在测试集上的表现为准确率100%,但是在人脸检测的过程中,准确率却极低。后续的解决措施即为为中提到的,结合边界框log文件与原图,裁剪非人脸区域构建负例图片,并采用相同的HOG参数提取特征,最后的效果较好。
2、滑窗大小的选取。由于给定的图片大小不一,图片中的人脸所占像素不一,所以滑窗的大小选取是一个比较麻烦的事情,在固定像素的情况下,容易出现漏检、多余计算的情况。采取的措施:使用比值的方式,动态调整滑窗大小,通过观察数据集中人脸所占图片的比例范围,设定一个滑窗的比例范围,尽可能的做到在保证有效计算的同时,能减少漏检的情况。
3、非极大值抑制时出现的编程问题。这个问题与实验的整体思路无关,单纯是编程过程中发现的python for循环问题。具体的内容为,在循环操作中,对列表某些元素进行删除操作后,会抛出数组下标越界的异常,经过学习发现,python中的for循环次数是预先确定的,虽然对列表进行del操作后,列表调用len()方法时长度发生了改变,但是for循环的循环次数时不会改变的,因此会出现下标越界的错误。解决措施:拷贝原列表,对拷贝的列表进行操作,最后再替换原列表,具体可以参考博客。
本次实验过程完整,思路明确,在编码的过程中发现了一些细节语法问题,在实验设计的过程中,更加深入的了解了特征算法的重要性,收获满满。
最后,为了方便代码的运行,编写了一体化的mian.py,具体使用方法可以参考README.md文件。GIT链接:https://github.com/YunduanBeichen/HOG-SVM。
数据集已上传百度网盘:https://pan.baidu.com/s/1hiN87WXnSCgPApZlc4rz8Q
提取码:uuga
如果对您有帮助,请受累点个star哦~