【论文笔记】Image Tampering Localization Using a Dense Fully Convolutional Network
发布于IEEE Transactions on Information Forensics and Security
原文链接:https://ieeexplore.ieee.org/document/9393396
摘要
● 由于Photoshop在实际应用中被广泛用于图像篡改,本文试图通过对Photoshop中常用编辑工具和操作的检测来解决篡改定位问题。
● 为了很好地捕获篡改痕迹,设计了一种全卷积编码器-解码器架构,该架构采用密集连接和膨胀卷积实现更好的定位性能。
● 为了在图像篡改不足的情况下有效地训练模型,我们设计了一种训练数据生成策略,利用Photoshop脚本技术模拟人类操作,生成大规模的训练样本。
介绍
挑战
暴露篡改图像区域在实践中仍然具有挑战性。原因是:
图像篡改的复杂性
- 图像篡改是通过对图像区域的操作来实现的,包括Splicing, Copy-move, Removal等。
- 伪造者会通过一些后期处理(如调整大小、旋转、对比度/亮度调整、去噪)来调整篡改区域,以隐藏视觉上可察觉的篡改痕迹。后处理操作在图像编辑软件中很方便,尤其是使用最广泛的Photoshop。
- 在Photoshop中,可以利用各种编辑工具和操作对图像进行篡改,从而得到视觉上可信的图像,但篡改痕迹复杂而微妙。因此,很难提取或学习篡改和原始区域之间可识别的特征。
缺乏训练样本
在没有足够训练数据的情况下,很难得到可靠的篡改定位模型。
主要贡献
- 由于Photoshop被广泛用于图像篡改,检测Photoshop操作和工具留下的痕迹可以直接获得篡改图像区域的定位。
- 提出了一种用于图像篡改定位的编码器-解码器架构,其中包括密集连接和膨胀卷积。
- 引入了一种有效的策略来生成大规模的篡改图像用于训练。该策略使用Photoshop脚本来模拟实际的篡改过程。
背景和相关工作
Photoshop中常用的篡改操作和工具如下表,

方法的提出
方法概况
由于在实践中使用了Photoshop中的各种工具和操作,因此对篡改痕迹进行建模很困难。一些先前的工作试图逐块学习篡改痕迹的特征;因此,块大小严重影响篡改定位性能。此外,由于块的数量巨大,因此很难对高分辨率图像进行实时检测。最近的一些工作通过使用全卷积网络缓解了这些问题,该网络可以直接产生像素级定位结果。然而,在这些工作中,编码器部分中的最后输出特征图通常具有非常低的分辨率(输入图像的1/16或1/32),导致一些详细篡改痕迹的丢失,从而恶化了解码器部分中输出的最终定位结果。为了克服现有的缺点,我们在所提出的编码器-解码器架构中特别包括密集连接和膨胀卷积。通过这种方式,网络能够捕获图像中更细微的篡改痕迹,并获得用于进行预测的更精细的特征图。
我们使用Photoshop脚本程序来利用这些操作和工具创建篡改的图像,模仿实际的篡改过程。通过这种方式,我们可以通过编程生成大量篡改图像,并使用生成的篡改图像训练我们的模型。
提出的编码器-解码器架构
提出基于深度网络的编码器-解码器架构和生成大规模训练样本的策略。

如上图所示,所提出的体系结构由编码器和解码器组成,
● 编码器 将输入图像转换为判别特征图,含五个密集块和三个2 × 2平均池化层。
● 解码器 通过进一步处理特征图输出像素级预测,包含两个密集块,三个转置卷积层和一个5 × 5卷积层。
为了提高性能,我们在编码器和解码器中都包含密集块,并在密集块#4和#5的层中使用膨胀卷积。具体描述如下。
密集连接
一个典型的密集块例子如下图,前四层为内部卷积层,最后一层为过渡层。
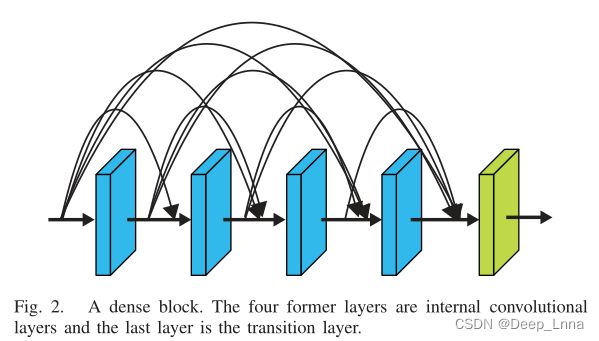

为什么使用密集块可以提高篡改定位性能?
● 由于连接较密,各个层可以通过较短的连接接受损失函数的额外监督。这可以为内核权重的本地化任务提供更强、更直接的监督。由于篡改痕迹是细微的,它有利于学习更具辨别性的特征和更强的监督。
● 密集的连接极大地促进了特征重用。通过这种方式,密集块中的后一层接收其前面不同层学习到的特征,增加了输入的变化,从而促进层学习各种篡改痕迹的有效特征。
膨胀卷积
在篡改定位中,仅从狭窄的局部区域学习特征会导致不稳定的特征表示。因此,有必要利用更大范围的信息进行特征学习,并捕获更多篡改痕迹,这意味着卷积层应该具有更大的感受域。
传统上,有两种可能的方法来增加感受野:
(i) 使用更大的卷积核:它的一个显著缺点是参数的数量随着感受野的增长而增加。
(ii) 在下一个卷积层之前添加池化层:这将导致特征图分辨率的降低,导致小篡改区域中一些细节痕迹的丢失。
为了超越这些限制,我们利用了膨胀卷积:通过对卷积核的相邻元素填充零来增大感受野的大小。核的感受野可以通过膨胀速率r来控制。随着层数的增加,在不添加额外参数的情况下,感受野呈指数增长,并保持特征图的分辨率,从而避免了对篡改定位有用信息的丢失。

如上图所示是不同膨胀率的膨胀卷积,黑色元素表示非零元素,白色元素表示零元素。
在我们提出的架构中,第四和第五密集块中使用了膨胀卷积层。下图用两个示例说明使用和不使用膨胀卷积获得的中间特征图。在每个子图中,第一个超级列显示输入图像及其ground-truth;在第二超级列中,第一行分别是块#4和#5的特征映射响应以及由所提出的架构输出的最终预测,而第二行中的那些是由没有膨胀卷积的架构输出的。

实验表明,使用膨胀卷积,特征响应可以更完全地覆盖篡改区域,这表明可以获得更好的定位性能。基于我们的实验结果,使用膨胀卷积可以将平均F1分数相对提高约4%(详情请参考第IV-B节)。
架构细节
我们在提出的编码器-解码器架构中总共使用了7个密集块,每个密集块的设置如下表所示。每个密集块由几个内部卷积层(第一个块有四个,其他块有两个)和一个作为输出层的过渡层组成。在第四和第五个密集块中,使用膨胀卷积层而不是普通卷积层。我们将每个扩张卷积层的核大小设为3,扩张速率设为2。除解码器网络中的最后一层核大小为5 × 5外,几乎所有普通卷积层的核大小都为3×3。每个卷积层的步长被设置为1,以便在密集块内不执行下采样。如图1所示,在输出前三个密集块之后,特征图的分辨率以步幅2降低了2×2个平均池化层。
由于在编码器网络中使用了三个池化层,特征图的分辨率仅为输入图像的1/8。为了获得像素级预测,我们需要将分辨率提高到输入大小。因此,在解码器部分使用三个转置卷积层,其核被初始化为4 × 4双线性核,卷积步长被设置为2。为了减少转置卷积层产生的棋盘状伪像,我们将最后一个转置卷积层的输出传递到一个5×5卷积层。最后,我们使用SoftMax层来生成篡改定位概率图。

训练数据生成策略
基于一些先前的工作(通过执行简单的拼接或复制移动来模拟篡改的图像)的方法,考虑实践中使用的各种后处理方法,设计了一种基于Photoshop脚本生成训练样本的策略。它提供了一系列命令和编程接口,可以使Photoshop自动执行图像编辑任务。生成策略如下图所示,表I中列出的工具用于后处理。
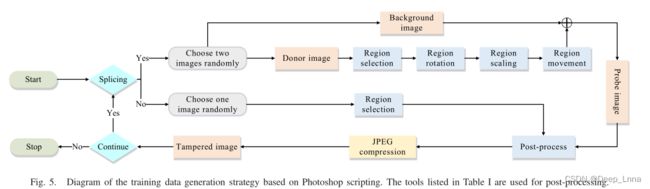
这个Photoshop脚本程序可以用来生成拼接和非拼接图像。
- 在生成拼接图像的情况下,首先随机选择两个图像;一个是背景图像,另一个是供体图像。为了模拟人类操作,选择特定区域作为操纵区域,然后使用一些常见的图像操作(例如旋转和缩放)进行变换。之后,采用区域移动来生成篡改图像。
- 在生成非拼接图像的情况下,选择一个图像,然后随机选择一个区域作为操纵区域。为了使篡改区域更难被检测,使用表I中列出的一些常用编辑工具来消除视觉上可辨别的痕迹。
- 最后,随机选择Photoshop中常用的一种JPEG压缩质量,将篡改后的图像保存为JPEG文件。通过为操作、工具和压缩质量选择不同的参数,产生了大量的篡改图像及其相应的掩模。
尽管生成的篡改图像在视觉内容/效果上不同于真实的篡改图像,但它们包含了Photoshop脚本引入的篡改痕迹。因此,这种策略使得利用足够的篡改数据训练篡改定位模型成为可能,并且由于生成的篡改图像更加复杂和多样,这种策略优于先前的策略。
实验
数据集
● PS脚本生成的书籍封面数据集:这个数据集是由12个不同的手机摄像头拍摄的1200张图像构建而成的。图像的内容是书籍封面,用于模拟证书和文档。通过使用Photoshop脚本程序,我们生成了14,581幅篡改图像及其对应的像素级篡改掩膜。
● PS脚本生成的Dresden数据集:为了使用自然场景图像为训练模型准备语料库,我们将Photoshop script程序应用于从Dresden数据集下载的7,876幅原始图像,并获得了5,295幅篡改图像及其相应的像素级篡改掩膜。
● 在边界上进行后处理的人工PS数据集(PS-boundary) :由10个手机摄像头拍摄的1000张书籍封面图片创建的(与PS-scripted book-cover dataset使用的不同)。使用Photoshop工具对边界进行后处理,获得1000张经过边界后处理的篡改图像。
● 具有任意后处理的人工PS数据集(PS-arbitrary) :使用Photoshop进行1000次伪造,使用任意合适的操作和工具,使篡改后的图像在视觉上与真实图像难以区分。
● NIST-2016数据集:包括Splicing, Copy-move, Removal,使用未知图像编辑软件进行后处理,包含564张被篡改的图片。
下图是PS-boundary(第1行)、PS-arbitrary(第2行)和NIST-2016(第3行)中的一些被篡改的图像及其相应的ground-truths。

评价指标
F1分数、MCC、IOU、AUC
消融研究
通常,有三个因素会影响所提出的网络的定位性能,即
- 编码器中密集块的数量
- 膨胀卷积层的使用
- 两个转置卷积层之间密集块的使用
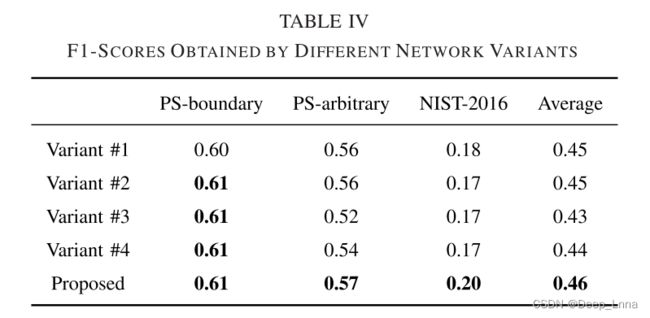
因此,我们设计了四种网络变体,如下表所示。其中,变体#1、#2和#3具有相同数量的卷积层但是不同的密集连接,因此变量#1、#2和#3的编码器网络中的密集块的数量分别是5、3和0;在变体#4中,转置卷积之间的密集块被移除。

我们用PS脚本生成的书籍封面数据集训练这些网络,并记录训练过程中的训练损失,如下图7所示。据观察,所提出的网络比其他变体收敛得更快,并且在收敛后实现了最低的损耗。

然后,我们用上面提到的三个测试数据集对训练好的模型进行测试,获得的F1分数如下表IV所示。基于比较和分析,我们得出结论,在提出的网络中设计的结构组件确实可以提高篡改定位性能。
使用PS脚本生成的图像进行培训的性能
下表是在不同方法上的性能比较。前三种情况中使用的模型用PS脚本生成的书籍封面数据集训练,而最后一种情况中使用的模型用PS脚本化的Dresden数据集进一步训练。
可以观察到,在大多数情况下,所提出的方法优于其竞争对手。对于NIST-2016数据集,所有方法都表现不佳。这可能是由于训练图像是书籍封面的图片,而NIST 2016中的测试图像是自然场景,训练和测试图像的不同属性导致性能不佳。然而,所提出的方法在所有方法中实现了最好的F1分数、MCC和IOU。
为了研究使用具有相同属性的训练和测试图像的性能,我们将使用PS脚本生成的书籍封面数据集训练的模型视为预训练模型,并进一步使用PS脚本的Dresden数据集训练它们。由此产生的模型再次在NIST-2016上进行测试。据观察,通过用自然场景图像进一步训练,性能通常得到提高。与其他方法相比,所提出的方法在F1、IOU和MCC方面实现了更好的性能。然而,值得注意的是,NIST-2016的本地化性能仍然不如PS-boundary和PS-arbitrary。一种可能的解释是,在NIST-2016中使用了不止一种图像编辑软件来创建被篡改的图像,而本实验中用于训练的所有被篡改的图像都是由Photoshop处理的。

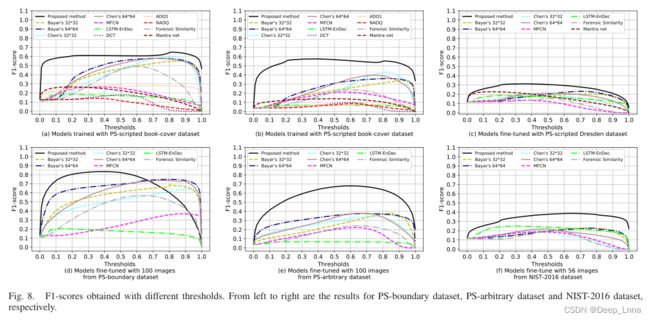
为了进一步研究不同阈值对性能的影响,我们以0.01的步长将阈值从0调整到1,并在下图8的顶行中绘制由不同阈值获得的F1分数的曲线。观察到,所提出的方法在所有三个数据集上实现了最佳和最稳定的性能,而其他方法对阈值更敏感。从左至右分别是PS-boundary数据集、PS-arbitrary数据集和NIST 2016数据集的结果。
微调后的性能
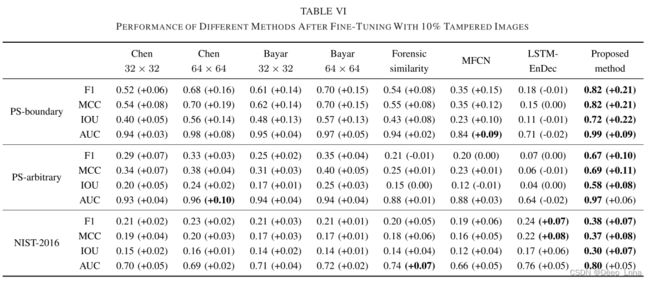
下图是利用10%篡改图像微调后不同方法的性能比较。
结合图8发现,在所有方法中,所提出的方法在较宽的阈值范围内获得了最好的性能。
为了直观地比较性能,我们在下图9中显示了一些篡改定位结果。从图中可以看出,我们的方法输出的结果更符合实际情况。例如,所提出的方法可以定位小的篡改区域(例如,第7个篡改图像中的小交通标志桶)并实现低的虚警率,而其他方法将产生更多的虚警,即使它们已经识别了篡改区域。

计算时间
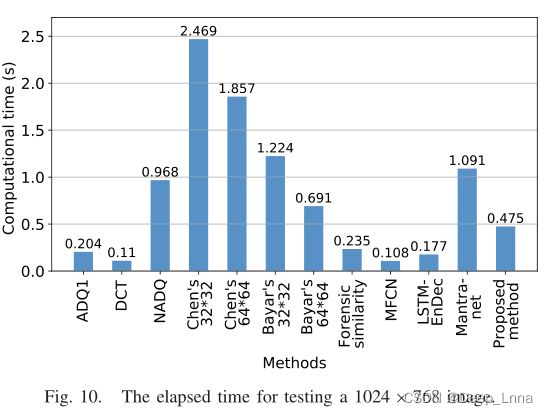
下图10比较不同方法的计算时间。从该图中,我们观察到基于DCT特征的方法在传统方法中运行最快,而MFCN在基于DL的方法中具有最低的计算时间。对于所提出的方法,测试一幅1024×768的图像需要不到0.5秒的时间。它比大多数以滑动窗口方式工作的基于DL的方法运行得更快,并且不需要比基于FCN的方法多得多的时间。相对较低的计算时间意味着我们的方法有可能部署在实际应用中。
鲁棒性分析
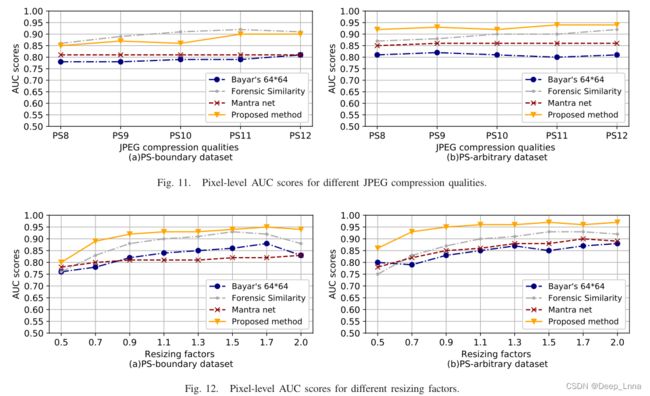
下图11是对不同JPEG压缩质量的像素级AUC分数的比较,图12是对不同大小调整因子的像素级AUC分数的比较。
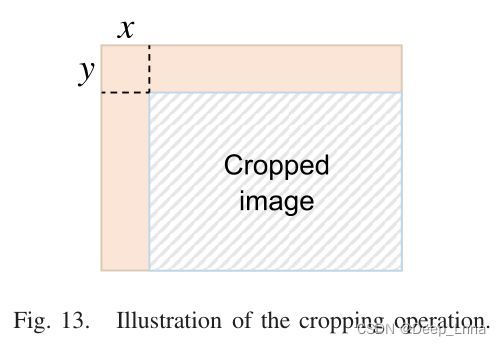
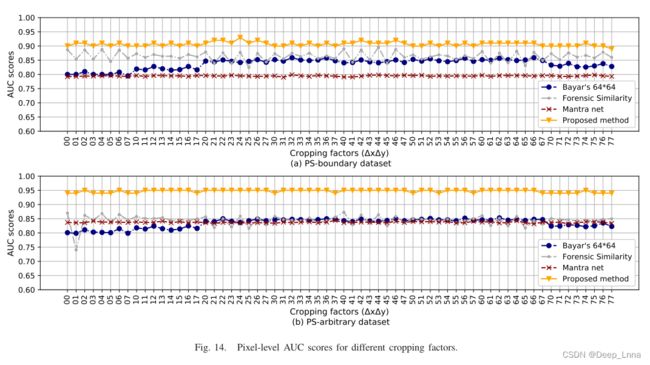
接下来是对其剪裁的鲁棒性进行分析。下图13表示的是裁剪操作的图示,图14是对不同裁剪因素的像素级AUC分数。图14是对不同水平的加高斯噪声的像素级AUC分数。

总结
● 为了学习篡改痕迹并实现像素级定位,作者设计了一个全卷积网络,该网络利用了密集连接和膨胀卷积的优点,能够获得良好的定位性能。
● 为了解决训练数据的不足,作者使用Photoshop脚本编程生成大规模训练篡改图像。
未来工作:
● 对NIST-2016数据集效果不是很好,可能是NIST-2016中使用了多种图像编辑软件来创建篡改图像,可以考虑分析其他图像编辑软件并进一步优化模型。
● 数据生成脚本程序可以考虑加入其他图像编辑软件,增加训练样本的多样性。