【论文笔记】MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection
发布于TPAMI2022
原文链接:https://arxiv.org/pdf/2112.08935v3.pdf
源码链接:https://github.com/dong03/MVSS-Net
本文只对于和MVSS不同的部分进行介绍,具体MVSS的内容见另一篇博客:https://blog.csdn.net/weixin_45366180/article/details/127643547?spm=1001.2014.3001.5501
主要贡献
- 为了将像素级操纵检测转换为图像级预测,我们提出了一种名为卷积广义平均池化(ConvGem) 的新模块代替之前使用的global max pooling (GMP),新模块有效地克服了 GMP 的两个缺点,即反向传播图像尺度损失的瓶颈以及缺乏考虑积极响应的数量和空间分布的能力。提出了更好的模型 MVSS-Net++。
- 对当前模型如何对通过屏幕截图重新捕获的操纵图像做出反应进行了初步研究,这是图像在互联网上传播时的常见操作。测试其鲁棒性。
提出的模型
下图是MVSS模型。

下图是MVSS++模型。

本文的目的是训练一个多头的神经网络G(即不仅确定图像是否被操纵,而且确定其被操纵的像素)。
- 语义分割头 G s e g G_{seg} Gseg:像素级操作的概率S(x)。
- 图像分类头 G c l f G_{clf} Gclf:图像被操纵的概率C(x),根据像素级的证据,我们从分割图中得到C(x)。

为了提取可推广的操作检测特征,G被设计成同时接受输入图像的原始RGB视图和额外噪声视图。 为了在检测灵敏度和特异性之间取得适当的平衡,多视点特征学习过程由像素、边缘和图像三个尺度的标注共同监督。 这就产生了多视图多尺度监督网络(MVSS-NET)。
用于图像级预测的ConvGeM
Global Max Pooling (GMP)将 S(x) 的最大值作为 C(x),即C(x) = S i ∗ , j ∗ S_{i∗,j∗} Si∗,j∗(x) ,虽然 GMP 将 C(x) 直接链接到 S(x),但由于以下两个缺点:
- 由于图像分类损失实际上是基于 S i ∗ , j ∗ S_{i∗,j∗} Si∗,j∗(x) 计算的,梯度损失仅通过唯一点 (i*, j*) 反向传播。这样的瓶颈不仅会减慢分类头的训练速度,还会阻碍头对整个网络的指导。
- GMP 对于积极响应的数量以及它们在空间上的分布方式是不变的。然而,这两个属性对于像素级检测结果是否有意义都很重要。根据格式塔理论,人类感知的视觉模式与他们的空间环境有关。根据这个理论,为了有效的欺骗,给定图像中的一定量的像素必须用一定的配置同时操作。 因此,零星出现的积极反应比它们在空间上分组的对应反应更有可能是噪声。 GMP并不能区分它们。
对于第一个缺点:
注意到,最初为图像检索而提出的广义平均池化(GeM)可以用来克服GMP的第一个缺点。如公式所示 GeM使用一个可训练的正参数p来在全局平均池化(p=1)和全局最大池化GMP(比如100的大p值)之间取得平衡:

由于更多的像素对C(x)的贡献,GeM有效地打破了GMP在反向传播中的瓶颈。 我们的经验观察到,用GeM代替GMP大约节省了10个训练周期。 尽管如此,GEM对正反应的空间分布仍然不变。
对于第二个缺点:
由于卷积自然地捕捉像素之间的空间相关性,可以考虑在GeM之前添加一个的卷积块,用conv(S(x))表示。注意到神经网络在早期训练的时候,特别是它的分割头 G s e g G_{seg} Gseg得不到很好地训练,因此、产生了很多无意义地S(x)。这种对 G c l f G_{clf} Gclf的噪声输入会被conv进一步夸大,使得分类头和整个网络难以训练。 为了抑制这种负面影响,我们通过一个由非负超参数λ作为加权的衰减跳跃连接将GeM(s(x))添加到C(x)中。

其中 λ 被初始化为接近1的值,并且随着epoch的数目增大非线性地衰减。如图6所示,使用接近1的λ可以让 G c l f G_{clf} Gclf在早期训练阶段暂时忽略conv块。 然后,随着 G s e g G_{seg} Gseg不断改进以提供更准确、更可靠的S(x),λ迅速减小以使 G c l f G_{clf} Gclf更多地依靠conv来充分利用S(x)。 公式6表明,GeM和GeM(conv)在训练过程中权重动态确定的凸组合有效地解决了GMP的缺陷。

多尺度监督
图像级损失:使用的二进制交叉熵(BCE)损失。
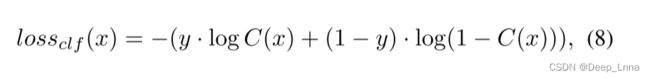
值得指出的是, l o s s c l f loss_{clf} lossclf的有用性并不局限于提高模型特异性。 通过ConvGeM,图像尺度监督现在可以比我们以前使用的GMP更有效地反向传播,以改善特征学习。
消融实验
语义分割主干网络的影响
下表3是不同语义分割骨干的性能比较,只用分割损失进行训练。 F1成绩以百分比表示。

G c l f G_{clf} Gclf的影响
我们比较了 G c l f G_{clf} Gclf的三种不同实现,即GMP、GeM和建议的ConvGeM,它们的性能如表4的最后三行所示。与GMP相比,GeM获得了更高的像素级别F1,表明可以更有效地使用图像尺度监督来改善分割网络。然而,GeM对像素上的响应进行平均,尽管以非线性方式,使得它不太敏感,并且因此导致图像级检测灵敏度的急剧下降 (从79.7到63.1)。它在像素级任务上的增益和在图像级任务上的损失相互抵消,使Com-F1与GMP相比基本上没有变化。相比之下,ConvGeM在两项任务之间取得了最佳平衡,将Com-F1从64.3提高到66.3。
边缘分割与边界框回归的比较
学习被操纵区域周围边界伪影的两种策略分别是边缘分割和将篡改定位视为边界框回归任务。用目标检测损失训练的 MVSS-Net 的性能显示在表 4 的倒数第二行,在像素级和图像级操作检测方面,它的分数相对低于 Setup #9,这表明边缘分割损失更适合学习边界伪影特征。

下图7是可视化提出的模型在不同设置下的像素级操作检测结果。数据来源:Defacto。 最后三行的测试图像是真实的。 多尺度监督(seg+clf及其后)的设置提高了检测的特异性,但代价是检测的灵敏度,这必须通过多视图特征学习来恢复。 其中,MVSS-NET++在检测灵敏度和特异性之间取得了最佳平衡。

与SOTA对比
像素级操纵检测
下表5显示了不同模型的像素级检测性能。 就整体性能而言,MVSS-NET++是最好的。 我们将Mantra-Net在DEF-12K上的良好性能归因于其大规模的训练数据,这些数据也源于MSCOCO的DE-12K。 NIST中性能最好的是H-LSTM,其训练数据约占NIST的70%。 与在同一CASIAV2上训练的基线MFCN、RGB-N、CR-CNN和GSR-NET相比,MVSS-NET++在几乎所有测试集上都超过了它们。 它在这种跨数据集环境下的优异性能证明了它更好的泛化能力。 将表5的左边部分(显示模型在最佳条件下的表现)和右边部分(显示模型在真实情况下的表现)进行比较,存在明显的差距。 对于最佳基线,即跨度,它的像素级F1从68.8下降到21.4。 至于MVSS-NET++,它的F1从73.2下降到38.7。 结果显示了这项任务的挑战性,以及所提出的评估协议对于公平评估向实际部署迈进的技术进展的必要性。

图像级操纵检测
表6显示了不同模型的图像级性能,所有模型都使用了0.5的默认决策阈值(较大的阈值意味着较低的敏感性和较高的特异性。)。 MVSS-NET++再次成为表现最好的模型。通过多尺度监督,MVSSNET系列能够从真实的测试集中学习,在大多数测试集上获得更高的特异性,从而降低误报率。 我们的模型还具有竞争性的AUC分数,这意味着它们在广泛的操作点上优于基线。 图8给出了w.r.t.模型的性能曲线、 决策阈值。 MVSS-NET++的峰值性能在决策值为0.46时,比其他模型的峰值性能更接近0.5。 这一结果再次表明我们的模型具有较好的泛化能力。


像素级和图像级操作检测的总体性能在表7中提供。

鲁棒性实验
下图9是对JPEG压缩和高斯模糊两种图像处理技术的鲁棒性评价。 测试集:CASIAV1+、MVSS-NET++(W/O AUG)表示在数据增强中排除了JPEG压缩和高斯模糊的训练。 所提出的模型比基线更稳健。

首次研究了模型如何对通过截图重新捕获的操纵图像做出反应。
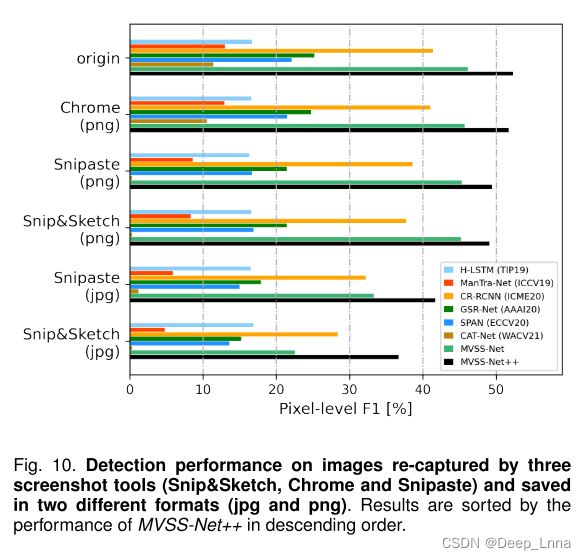
面向截图的评估如下所示。 从CASIAV1++中随机选择100个操纵图像的子集。 然后在屏幕分辨率为1920×1080的Windows10笔记本电脑上手动重新捕捉每个图像。 使用了三种商业截图工具,包括Microsoft Snip&Sketch、Google Chrome DevTools和Snipaste。每个图像和工具,结果图像分别保存在JPG(质量水平为90%)和PNG格式,除了Chrome只支持PNG。 改变屏幕工具的配置和图像格式会导致测试集的五种变体,即snip&sketch(png)、snip&sketch(jpg)、chrome(png)、snagest(png)和snagest(jpg)。
图 10显示了单个模型在原始测试集及其变体上的性能。 我们从图中得出两个结论。 首先,对于图像重新捕获的两个因素,即截图工具和文件格式,后者更为重要。 其次,虽然所有模型都存在基于截图的图像重新捕获问题,但MVSS-NET++仍然是最好的。
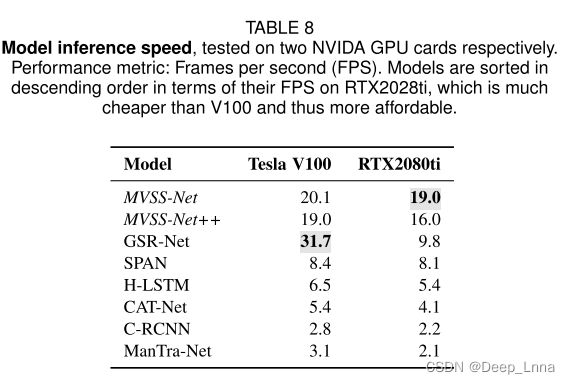
效率测试
下表8为模型推断的速度。
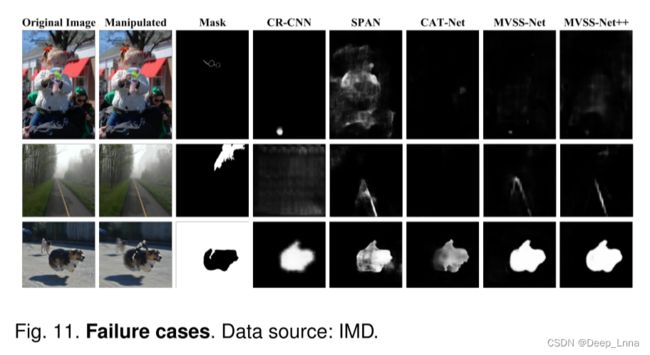
失败案例分析
如下图 11,第一排的图像是通过暗化孩子戴的眼镜的框架来操纵的。 这种操纵痕迹似乎太小了,不能被当前的模型揭示出来。 第二行图像的右上角覆盖了一定的半透明图像补丁,处理过的痕迹很好地融入了迷雾场景。 至于最后一张图像,操纵是通过在前景的狗背上放一个骑士来进行的,同时模糊背景。 所有模型都捕捉到了前景和背景之间的不一致性,但都无法识别背景实际上是被操纵的。
附录
下表9显示了不同模型的精确度和MCC得分。 MVSS-NET系列在平衡良好的MCC方面明显优于基线。

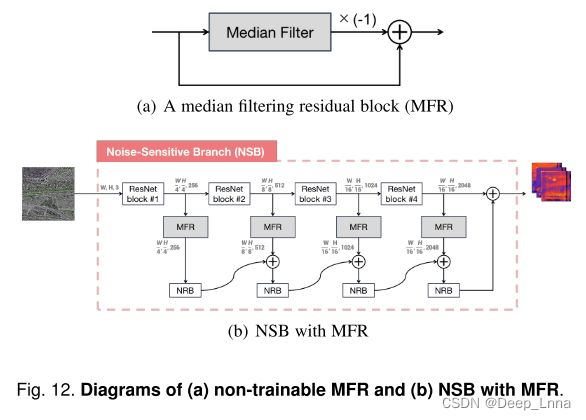
下图12展示了如何以类似于ESB的从浅到深的方式向NSB添加不可训练的MFR块。NRB(噪声残差块)的实现方式与图的ERB(边缘残差块)相同 3(b)。