【论文笔记】PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and
PSCC-Net: Progressive Spatio-Channel Correlation Network for Image Manipulation Detection and Localization
发布于IEEE Transactions on Circuits and Systems for Video Technology 2022
论文链接:https://arxiv.org/pdf/2103.10596v2.pdf
一作开源代码:https://github.com/proteus1991/pscc-net
摘要
开发了一种渐进式空间通道相关网络 (PSCC-Net) 对图像篡改进行检测和定位。
PSCC-Net以双路径过程处理图像:
- 自上而下的路径:提取局部和全局特征。
- 自下而上的路径:检测输入图像是否被篡改,并以多个比例估计其mask,其中每个mask都以前一个为条件。
与传统的encoder-decoder和no-pooling结构不同,PSCC-Net利用具有密集交叉连接的不同尺度的特征以从粗到细的方式产生操纵掩模。空间信道相关模块(SCCM)捕获自底向上路径中的空间和信道相关性,赋予特征整体线索,使网络能够应对广泛的操纵攻击。SCCM避免了使用大量注释数据对特征提取器进行预训练; 连续实现了图像处理、检测和定位的SoTA结果。由于重量轻的主干和渐进式机制,PSCC-Net可以以50+FPS的速度处理1080p图像。 大量的实验表明,PSCC-Net在检测和定位方面都优于现有的方法。
引言
通常,图像处理由内容相关过程和与内容无关过程组成。
内容相关过程:拼接、复制移动和移除。通常,内容相关过程遵循目标图像中的语义安排。
内容无关过程:包括全局修改,例如亮度/对比度变化,模糊,噪声和图像压缩。它们几乎不会产生任何虚假信息,但是它们产生的噪声可能会破坏对图像/相机轨迹的分析,并可能隐藏被操纵区域和原始区域之间的差异。
IMDL三个主要未解决的问题:
- 规模变化:伪造区域大小不一。大多数先前的工作都忽略了尺度变化的重要性,并且在检测不同尺寸的伪造区域时遇到困难。传统的encoder-decoder和no-pooling结构都难以联合利用局部和全局特征,因此只能处理有限的尺度变化。
- 图像相关性:与原始区域相比,可以最好地确定被操纵的区域,尤其是对于拼接攻击。 从操纵图像到操纵mask映射的简单学习可能导致训练中对特定攻击类型的过拟合。 相比之下,考虑图像的空间相关性可以得到更广义的定位解决方案。 然而,这种相关性在以往的研究中大多被忽略。
- 检测:现有的大多数研究都假设在所有输入图像中都存在操纵。 因此,这会在原始图像上造成许多虚警(把真实的图像检测为篡改),使检测变得不可靠。
为了解决上述问题,本文提出了一种新的渐进空间信道相关网络(PSCC-NET),如图2所示。

由检测头预测的检测分数指示输入是否被操纵。 从mask-4到mask-1的操作定位精度逐渐提高,例如,mask-4的预测混淆了粘贴(伪造)区域和原始(复制)区域,而mask-1有效地修复了粘贴(伪造)区域。
PSCC-Net由一个自顶向下的路径和一个自底向上的路径组成。 在自上而下的路径中,骨干编码器首先从输入图像中提取局部和全局特征,其不同尺度之间的紧密联系促进了信息的交换。 在自底向上的路径中,我们利用学习到的特征从小尺度到大尺度估计4个操纵掩码,其中每个掩码作为下尺度估计的先验信息。 由于这样的设计,最终的mask是以一种从粗到细的方式估计的,收获了本地和全局的信息。 如果中间掩码令人满意,则通过终止自下而上的掩码估计,该设计实现了潜在的加速。 此外,我们不是研究预测的操纵mask的响应,而是将学习到的特征输入检测头,以产生二分分类的分数。
为了利用图像相关性,我们提出了一个空间通道关联模块(SCCM),该模块在每个自下而上的步骤中同时掌握空间关联和通道关联。空间相关性在局部特征之间聚合全局上下文。由于来自不同信道的响应可能与同一类(例如,操纵的或原始的)相关,信道相关性计算特征映射之间的相似性,以增强感兴趣区域的表示。考虑到编码器的轻量级设计,PSCC-Net可以以50+FPS的速度处理1080P。
相关
图像的篡改检测分为隐式检测和显式检测。
- 隐式检测:说明了图像整体篡改的概率
- 显式检测:说明逐像素篡改的概率
由于只考虑局部区域的相关性,因此Mantra-Net和SPAN未能充分利用空间相关性,推广性有限。 在这项工作中,我们的PSCC-Net利用一种渐进机制来改进多尺度特征表示和SCCM模块,以更好地探索空间和信道相关性。
PSCC-NET
与图像级检测相比,像素级定位更加困难。 因此,PSCC-NET特别重视解决本地化问题。 事实上,由于用于检测和定位的特征是联合学习的,提高定位性能自然有利于检测。
网络体系结构
自顶向下路径
以前的大多数工作使用传统的encoder-decoder和no-pooling结构来提取特征。 由于伪造区域的尺寸多种多样,因此融合局部特征和全局特征来处理尺度变化是非常重要的。 然而,这两种结构都是在顺序流水线上提取特征,忽略了不同尺度之间的特征融合,因此只能处理有限的尺度变化。
与encoder-decoder和no-pooling结构相比,我们的backbone的好处是双重的。 首先,并行计算不同尺度的特征。 因此,不同尺度之间的紧密联系能够有效地进行信息交换,有利于处理尺度的变化。 其次,由于对每个尺度进行局部和全局特征融合,每个特征包含足够的信息来预测相应尺度下的操纵mask。 因此,这个主干符合我们的渐进式机制,其中每个mask的预测都应该依赖于所有局部和全局特征来提高其准确性。 实际上,除了上一个尺度上的预测mask,其他的都作为下一个尺度mask预测的先验。 经过自上而下的路径,提取4个尺度上的操纵特征。 然后,使用自底向上的路径执行操作检测和定位。
自底向上路径
PSCC-NET中的自底向上路径估计检测得分和操作掩码。 具体地,基于通过检测头从自上而下路径提取的特征预测检测得分,然后通过完全监督的渐进机制生成操纵掩码。 特别是,从粗到细的渐进机制模拟了人类如何处理日常生活中的复杂问题。
为了降低预测难度,提出的渐进机制避免了直接以最小尺度生成掩码。 取而代之的是,最粗尺度上的掩码首先被预测,以根据当前可用信息定位潜在伪造的区域。 在更细尺度上的后续预测可以利用先前的掩模,更多地关注那些选定的区域。 这个过程一直持续到以最细的尺度生成操作掩码,这是最后的预测。 然而,如果没有对每一个尺度的明确监管,中间mask可能不会遵循从粗到细的顺序。 因此,在所有尺度上应用全面监督来指导掩码估计。
空间信道相关模块
下图3是SCCM的结构。其中红色箭头显示公共特征流; 粉红色和绿色箭头分别表示空间和通道注意的特征流。输入特征x的大小为H×W×C,尽管x很小(256×256),但其空间相关性的大小可能非常大(65,536×65,536),很容易超过内存限制。
因此,该操作保留了所有特征信息,避免了对潜在大尺寸HW×HW的空间相关性建模。

为了建立空间上和通道上的相关性,可以直接利用x。 然而,通过引入嵌入式高斯函数可以获得额外的灵活性。 因此,我们用1×1卷积构造不同的函数g、θ和φ,将x变换成新的线性嵌入,即xg=g(x)、xθ=θ(x)和xφ=φ(x),它们的大小都与x相同。 然后,计算了嵌入特征Xθ和Xφ的空间相关性和信道相关性,并用Softmax函数实现了高斯运算。 最后,通过矩阵乘法分别实现了空间和信道注意。不同于先前的方法对不同的特征进行两种关注,我们将这两种方法应用于相同的线性嵌入以相互适应。 实际上,这样做降低了后续融合过程的难度,也节省了SCCM中的计算操作。 具体地说,空间注意可以表述为:


它们越相似,相关性就越高。 这有助于网络学习用于区分伪造区域和原始区域的特征表示,并避免在训练中过度拟合特定的攻击类型。 类似地,channel-wise attention表示为:
由于来自不同通道的响应可能与同一类相关联,例如,被操纵的或原始的,通道相关性根据它们的相似性聚合特征图,以增强伪造区域中的表示。
我们使用 h−1 将 Y ‘ s Y`s Y‘s 和 Y ‘ c Y`c Y‘c 分别重塑回大小为 H × W × C 的 Ys 和 Yc。此外,两个函数 ωs 和 ωc 通过 1×1 卷积构建以改进它们的特征表示。 ωs 和 ωc 的输出特征相互补充。由于确定它们的相对重要性并非易事,因此使用两个初始化为 1 的可学习参数 αs 和 αc 进行权衡。 αs 和 αc 的学习值可以在补充中找到。我们还采用残差学习将特征Z表示为:

SCCM 的最终输出是一个只有一个通道的预测掩码。为了减少 Z 中的通道数,我们采用顺序为 ConvReLU-Conv-Sigmoid 的掩码生成块,其中 Conv 是 3 × 3 卷积。
损失函数
采用二元交叉熵损失。预测检测分数 (sd) 由 groundtruth (GT) 标签 (ld) 监督,其中 0 代表原始图像,1 代表伪造图像。此外,通过根据相应的大小将 GT 掩码 G1 下采样到 G2、G3 和 G4,对每个预测掩码应用完全监督,其中 0 代表原始像素,1 代表伪造像素。通过不同尺度的渐进机制预测的掩码被认为是同等重要的。因此,我们最终的损失函数可以表示为:

训练数据合成
构建了一个合成数据集来训练和验证我们的 PSCCNet。该数据集包括四个类别 1) 拼接、2) 复制-移动、3) 移除、 4) 原始类。对于拼接,使用 MS COCO生成拼接图像,其中每个图像随机选择一个注释区域,并在几次转换后粘贴到不同的图像中。对其进行变换,包括缩放、旋转、移位和亮度变化。由于拼接区域不一定是物体,我们使用贝塞尔曲线生成随机轮廓,然后填充它们以产生拼接掩码。遵循上述相同的过程,在 KCMI 、VISION和 Dresden中随机选择通常用于识别相机源的供体和目标图像,以生成额外的拼接图像作为补充。对于复制移动,采用了[28]中的数据集。对于移除,采用 SoTA 修复方法来填充从每个选定的 MS COCO 图像中随机移除的一个注释区域。至于原始类,我们只是从 MS COCO 数据集中选择图像。
总之,我们在剪接类中有116 583个图像,在复制移动类中有100 000个图像,在删除类中有78 246个图像,在原始类中有81 910个图像,因此总共约0.38M。图4演示了合成数据集中不同操作类型的示例。应该强调的是,我们的训练数据集比Mantra-Net和SPAN的数据集小得多,在MantraNet和SPAN中,使用海量注释数据1.25M来训练其特征提取器,更不用说为培训其余网络而进行的大量综合操作了。
由于在一个epoch对所有操纵图像进行训练效率低下,我们统一地对每个班级的0.025M图像进行采样,以形成一个0.1M的数据集,在每个时代进行训练。此外,我们还构建一个包含4 × 100个图像的验证集。合成影像的大小都设定为256 × 256。
下图4是来自合成数据集的实例。

表1总结了我们预训练和微调模型的测试数据集(# 代表图像数量,并指示是否涉及操作类型)。

实验
测试数据集
Columbia、Coverage、CASIA和 NIST16,以及一个真实世界的数据集:IMD20。
评价指标
图像水平的AUC和F1分数、等错误率 (EER) 和 1% 假阳性率下的真阳性率 (TPR1%) 。由于计算 F1 分数需要二进制掩码和检测分数,因此我们采用 EER 阈值对它们进行二值化。
定位比较
与J-LSTM 、HLSTM 、RGB-N、ManTra-Net和 SPAN进行比较,其中 SPAN 报告了定位的 SoTA 性能。
使用两种模型比较定位性能:
- 预训练模型在合成数据集上训练,并在完整测试数据集上评估;
- 微调模型是在测试数据集的训练分裂上进一步微调并在测试分裂上评估的预训练模型。
预训练的模型是为了体现每种方法的泛化能力,微调的模型是为了体现每种方法的局部化性能,同时极大地缓解了领域差异。
预训练的模型
表2显示了预训练模型的本地化AUC(%)。 经过预训练的PSCC-Net在Columbia、CASIA、NIST16和IMD20上实现了最好的定位性能,在Coverage上排名第二。 最显著的性能增益是在处理现实生活中的操纵图像时(5.6%↑)。 结果表明,PSCC-NET具有较好的泛化能力。 尽管在AUC下超过了Mantra-Net2.8%,但我们未能在Coverage上取得最佳表现。 原因可能是我们的训练数据不完善,在这种情况下,复制的对象被故意移动,以覆盖外观相似的原始对象。 事实上,通过微调预先训练的覆盖模型,PSCC-NET在AUC下实现了0.4%的SPAN增益(表3)。
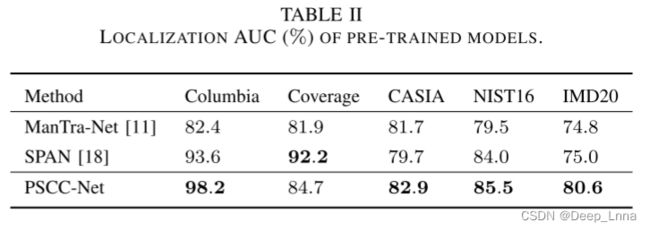
微调模型
使用预训练模型的网络权重来启动微调模型,这些微调模型将分别在Coverage、CASIA和NIST16数据集的训练分裂上进行训练。对AUC来说,PSCC-NET在所有情况下都超过了基线(平均超过2.4%)。 至于F1评分,我们的模型以很大的优势胜过他们(平均跨度超过16.6%)。 这验证了我们的整体网络设计的有效性。
表3是对微调模型的评估。 本地化AUC/F1s报告(%)。 这里没有显示Mantra-Net,因为它只开发了预训练的模型。

表4是在CASIA-D上的检测评估。

定性比较
如图5、6所示,与Mantra-Net和Span相比,PSCC-Net的预测掩码在更高的预测精度(例如,图5的第1行)和更少的假警报(例如,图的第6行)方面实现了最佳性能。 另外,该方法对尺度变化的敏感性较低。 大的(例如,图5中的第5行)和小的(例如,·图的第7行)操作都可以有效地定位。 在实际数据集上,PSCC-NET仍然比其他两个(如图6中的第2行)表现得更好,显示了其良好的泛化能力。


检测比较
由于Mantra-Net和SPAN是定位评估中性能最好的基线,而Mantra-Net没有开发微调模型,因此我们选择了预训练的模型进行检测评估,以便对两者进行比较。 尽管这两个基线没有直接尝试执行检测,但它们估计的操纵掩码可以用于此目的。 因此,我们简单地把面具的平均值作为他们的分数。图7描绘了不同检测方法的ROC曲线。 我们的检测头成功地缓解了原始图像中虚警的影响,达到了最佳的检测效果。

可见,引入一个定制的磁头可以显著提高检测性能。 在检测良好的情况下,IMDL方法可以更加有效。 即在定位前进行检测,只通过检测到的伪造物进行定位。 我们的网络设计与这种效率考虑相兼容,因为检测头被放置在自底向上路径的开始。 对操纵检测的定性评价在图8进行了论证 ,其中SPAN和PSCC-NET在原始图像和操作图像上预测的掩膜进行了比较。 如果没有假设操纵的存在,对于原始图像,从PSCC-net中得到的相应的预测掩模几乎是空白的。 然而,在大多数情况下,来自SPAN的会遭受严重的假警报。 对于相关的操纵图像,该方法更准确地定位了伪造区域。

SCCM可视化
我们为每个图像选择 3 个代表性像素,并标注为 P1、P2 和 P3。对于经过处理的图像,P1 和 P2 来自伪造区域,P3 来自原始区域;至于真实图像,所有像素都是原始的。 对于经过处理的图像,P1 和 P2 的空间响应图在大多数情况下在伪造区域具有高值而在原始区域具有低值,但是 P3 的图在所有区域(包括提供复制的区域)中都保持低值内容(例如,图 9(e)第二行中的 P3 响应)。对于真实图像,所有选定像素的空间响应图始终保持低值。这种可视化表明伪造区域中的特征已成功聚集在一起,从而证明了 SCCM 中空间注意力的有效性。
我们选择可视化 Yc 的一个通道并将其与 X 的同一通道进行比较,以查看是否有任何区域得到增强。我们在图9中可视化 X 和 Yc 的第一个通道。实际上,与 X 中的伪造区域相比,Yc 中的伪造区域得到了巩固,如果伪造区域不存在(即在真实图像的情况下),则没有区域被增强。这证明了SCCM中channel-wise attention的有效性。
图9是SCCM中空间和通道注意的可视化。 从上到下,分别展示了拼接、复制移动、修复和真实图像。 对于每个测试图像,我们显示了它的GT,3个空间响应图(每个选定的像素一个),以及X和YC中的第一通道图。

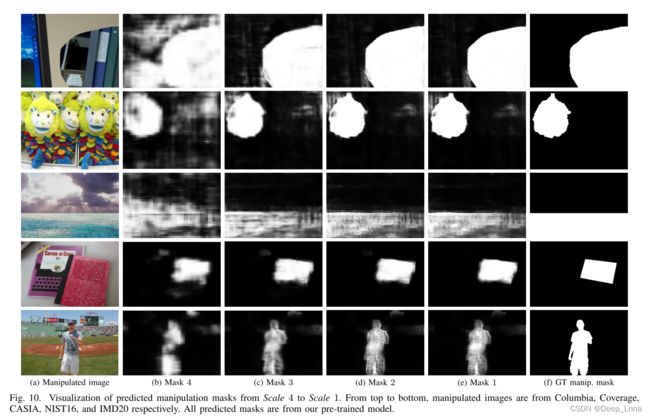
不同尺度上预测操作掩码的可视化
PSCC-Net 利用渐进机制通过避免直接从最精细的尺度生成掩码来降低预测难度。相反,首先预测最粗尺度的掩码以根据当前可用信息定位可能伪造的区域。随后在更精细尺度上的预测可以利用先前的掩码并更加关注那些选定的区域。这个过程重复执行,直到生成最精细尺度的操作掩码作为我们的最终预测。
在此,我们可视化操作定位从Scale 4到Scale 1的性能改进。在图10中,Mask 4、Mask 3和Mask 2是在第4、3、2比例上生成操纵蒙版后截断原始模型的变体,而Mask 1是原始模型的输出。由此可见,受益于提出的渐进机制,本定位性能从Mask 4逐步提升到Mask 1,以较低的误报和更清晰的界限。
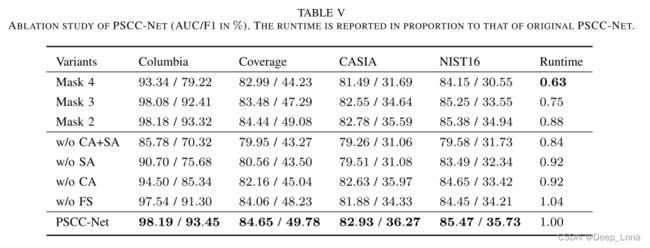
运行时间分析和消融研究
我们测试了 PSCC-Net 的几个变体来证明网络设计的合理性,其中所有变体都在我们的合成数据集上进行了预训练。报告了平均 AUC/F1(以 % 表示),运行时间(按比例)是相对于 PSCC-Net 的。我们的完整模型需要 0.019 秒来处理一张 1080P 图像,而 ManTra-Net 和 SPAN 分别需要 0.208 秒和 0.161 秒。此外,如图 2 所示,在推理时间内在 Mask 4、Mask 3 或 Mask 2 上提前终止 PSCC-Net 是可行的,并且不会干扰该尺度下操作掩码的预测。从我们的实验来看,终止 Mask 4 的预测可以将运行时间缩短至 0.012 秒,即额外节省约 37%。虽然对于研究数据集来说不是必需的,但这种节省时间的方式在实际应用中非常重要且经济,例如,每小时有 1460 万张照片上传到 Facebook。
Mask 4、Mask 3、Mask 2和原来的PSCC-Net的比较证明了性能的逐步提升,这是我们进步机制的明显体现。由于Mask 3在AUC和F1分数下已经表现良好,因此是mask预测的良好停止点。
我们还为SCCM构建了几种变体,包括没有空间和通道注意力( w/o SA + CA ) ,没有空间注意力( w/o SA ) ,没有通道注意力( w/o CA ) ,以及没有特征共享( w/o FS )的变体,其从不同的θ和φ函数获得嵌入以计算空间和通道相似性。 比较表明, SA和CA的表现都超过基线(w/o SA + CA) ,并且从SA获得的性能增益高于从CA获得的性能增益。 此外,特征共享不仅略微减少了运行时间,而且还使得这两个注意机制之间能够相互调节,以帮助SCCM比采用不同特征(即w/o FS )的SCCM实现更好的结果。
鲁棒性实验
使用一些失真设置来降低来自 Columbia 和 NIST16 的原始处理图像。这些失真包括将图像调整为不同的比例 (Resize)、应用内核大小为 k 的高斯模糊 (GSBlur)、添加标准差为 σ 的高斯噪声 (GSNoise) 以及执行质量因子为 q 的 JPEG 压缩 (JPEGComp)。此外,我们引入了上述失真的混合版本(Mixed),其中resizing scale、kernel size k、标准差σ、quality factor q是从区间[0.25, 0.78], [3, 15]中随机选择的,分别为 [3, 15] 和 [50, 100]。

表6显示了使用预训练模型在像素级 AUC 下定位的鲁棒性分析。 PSCC-Net 在所有失真下都比 ManTra-Net 和 SPAN 更健壮。值得注意的是,将图像上传到社交媒体时通常会执行调整大小。事实上,受益于将操作特征重新采样为固定大小的操作,与其他方法相比,调整大小对 PSCCNet 的影响最小。我们还分析了 PSCC-Net 对 CASIA-D 上各种失真的检测鲁棒性。在表7中,可以看出我们的 PSCC-Net 对于检测非常稳健,尤其是在执行 JPEG 压缩的情况下。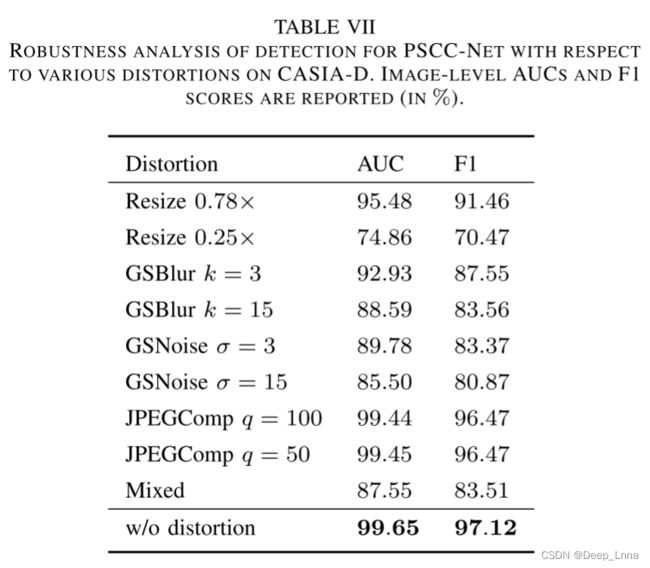
局限
图11是一些失败案例。

对于实时操纵的图像,伪造区域可具有不同的尺寸和形状。 在第一行中,我们显示了一个特定的例子,其中相同的图案被复制了几次,但缩放比例不同。 尽管我们的方法未能定位所有伪造区域,但它对规模变化不太敏感。 此外,我们的方法可能无法定位整个伪造区域,或者在一些情况下仅定位它们的部分(例如,最后两行)。 一个可能的原因是一些操作痕迹被制造商精心去除。 事实上,现有的IMDL方法也难以解决这些被操纵的图像。 请注意,即使在这些情况下,我们的PSCC网络在图像操作定位方面仍然比SoTA性能更好(例如,参见第2行)。
总结
提出了一个新的PSCC-Net ,以应对先进图像操作技术的挑战。 我们采用一种渐进机制来预测所有骨架尺度的操作掩模,其中每个掩模都用作帮助预测下一个尺度的掩模。 此外, SCCM设计用于对所提取的特征执行空间和通道注意,从而提供整体信息,使我们的模型更广泛地适用于操纵攻击。 广泛的实验表明,我们的PSCC-Net在检测和定位方面都优于SoTA方法。 对于未来的工作,我们将开发技术来估计预测的操纵掩模的不确定性,以进一步提高IMDL性能。