西储大学轴承数据一维时序方法基础测试
这篇文章主要是为了说明一个基本结论:
在单一工况下的故障分类准确率已经难以区分好的模型和方法,利用不同工况之间的直接预测,而后取均值是一种思路。
0.数据集处理方式
数据集处理方式具体见我之前的文章,这里基本的的信息就是取2048个点进行作为样本大小,样本通过滑动时间窗取值获得,步长为128,训练集、验证集、测试集的比例为7:1.5:1.5。标签处理为one-hot模式,如果用SVM就不需要了。
滑窗取值这里默认使用,后续我会单独比较和非滑窗的区别,还有一种是训练集和验证集和滑窗、测试集不滑窗取值,或者还可以只有训练集滑窗,所以还是很麻烦的,需要单独进行一次。
dataDE_A = case10.data_DE_win(650, 'A', steps=128)
dataDE_B = case10.data_DE_win(650, 'B', steps=128)
dataDE_C = case10.data_DE_win(650, 'C', steps=128)数据用的还是DE端的,A、B、C对应0/1/2三种转速工况。
1.单工况下的测试结果
单工况下主要比较SVM、普通CNN和WDCNN的差别,三种模型代码如下:
svm.SVC(C=0.9, kernel='rbf')
def CNN_1D():
inputs1 = Input(shape=(2048, 1))
conv1 = Conv1D(filters=16, kernel_size=6, strides=2)(inputs1)
BN1 = BatchNormalization()(conv1)
act1 = Activation('relu')(BN1)
pool1 = MaxPooling1D(pool_size=2, strides=2)(act1)
conv4 = Conv1D(filters=24, kernel_size=3, padding='same')(pool1)
BN2 = BatchNormalization()(conv4)
act2 = Activation('relu')(BN2)
pool2 = MaxPooling1D(pool_size=2, strides=2)(act2)
conv6 = Conv1D(filters=36, kernel_size=3, padding='same',
activation='relu')(pool2)
BN3 = BatchNormalization()(conv6)
act3 = Activation('relu')(BN3)
pool3 = MaxPooling1D(pool_size=2, strides=2)(act3)
flat1 = Flatten()(pool3)
dense1 = Dense(100)(flat1)
BN4 = BatchNormalization()(dense1)
outputs = Dense(10, activation='softmax')(BN4)
model = Model(inputs=inputs1, outputs=outputs)
return model
def WDCNN():
inputs1 = Input(shape=(2048, 1))
x = Conv1D(filters=16, kernel_size=64,strides=16,padding='same')(inputs1)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=32, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2, padding='valid')(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Conv1D(filters=64, kernel_size=3, strides=1, padding='valid')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = MaxPooling1D(pool_size=2, strides=2)(x)
x = Flatten()(x)
x = Dense(100)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
outputs = Dense(10, activation='softmax')(x)
model = Model(inputs=inputs1, outputs=outputs)
return modelWDCNN作为一个经常被比较的模型大家应该还算熟悉,这个CNN_1D是我根据Alexnet稍加改动而成的,简单调了以下参数。在数据集A上运行,均进行5次取均值,结果如下:
SVM运行很快,结果大概在75%。
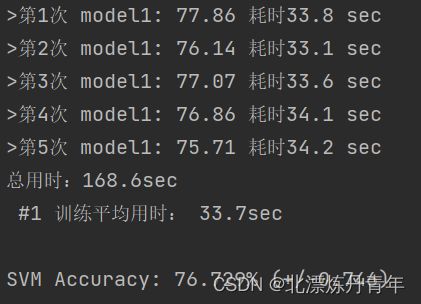
WDCNN很优秀,都是100%。

CNN_1D呢,也都是100%,耗时多一点点。可见,这里并没有分出高下。

2.多工况下的测试结果
这个方法就是比较常见的不同工况之间迁移测试,A-B就是指在A数据集上训练,然后直接用B工况的测试集得出结果,这比较考验模型的泛化能力,最后取均值进行比较。结果如何呢?
总用时:331.0sec
#1 训练平均用时: 31.8sec
#2 训练平均用时: 34.4sec
A-B model1准确率: 99.77 model2准确率: 100.00
A-C model1准确率: 82.73 model2准确率: 98.64
B-A model1准确率: 91.19 model2准确率: 96.87
B-C model1准确率: 90.57 model2准确率: 98.37
C-A model1准确率: 80.00 model2准确率: 80.51
C-B model1准确率: 83.19 model2准确率: 85.40
CNN_1D Accuracy: 87.907% (+/-1.112)
WDCNN Accuracy: 93.300% (+/-1.489)从结果上,大家能轻易看出差距。证明了我开头说的,单一工况的准确率是无法说明问题的,很多人的结果99%多一点,还各种比较,我觉得没啥意义,我这还100%呢。100%只是题目的上限,并不是模型能力的上限,在大家都能考满分的时候,我们是不是考虑换一套难一点的题呢?(最近我把多工况下的准确率我已经搞到99.2%了,感觉也已经没啥意思了)。
以上涉及代码大部分大家都可以在网上搜到,欢迎讨论。完整代码有偿,个人劳动成果,请大家见谅。点赞收藏关注者我可以送数据集处理代码和程序的运行代码~