轴承故障诊断:《用于轴承故障诊断的具有多尺度卷积融合的一维视觉Transformer》论文代码复现以及t-SNE可视化
论文题目:A One-Dimensional Vision Transformer with Multi-scale Convolution Fusion for Bearing Fault Diagnosis 点击此处查看论文地址 前面链接打不开点击此处下载pdf
摘要:
针对传统的基于卷积神经网络(CNN)的故障诊断方法无法获取滚动轴承的时间信息的问题,提出了一种基于多尺度卷积融合的一维视觉变压器(MCF-1DViT)。为了从采集到的振动信号中自动有效地丰富多尺度特征,设计了多尺度卷积融合(MCF)层,以捕获多个时间尺度的故障特征。然后,引入改进的Vision Transformer架构,利用Transformer学习长期时间相关信息,可以显著提高诊断精度和抗噪能力。最后,在一个常用的滚动轴承数据集上进行了实验,验证了该方法的有效性。结果表明,与现有方法相比,该方法具有更好的诊断性能。
方法:
- Step1: 结合多尺度学习,在MCF层中使用三个不同尺度的大卷积核来获取互补丰富的诊断信息。
- Step2: 使用标记器将多尺度振动信号的采样点分组为少量标记,每个标记代表多尺度信号中的一个语义概念,然后通过扁平化转换为序列,通过线性嵌入层投影到补丁嵌入。
- Step3: 为了保留信号的位置信息,将嵌入位置添加到补丁中。然后,所产生的序列被馈送给变压器编码器以生成最终的表示
- Step4:将第一个位置对应的输出表示作为头部分类器的全局信号表示,得到最终的故障分类结果。
数据选择
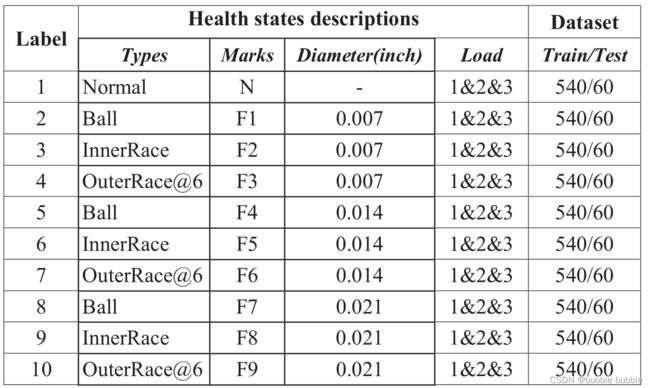
本文利用凯斯西储大学(CWRU)轴承数据中心[20]提供的公共轴承数据集,验证了MCF1DViT的故障诊断性能。在负载0、1、2、3 hp四种工况下,采集电机驱动机械系统加速度计的振动信号,采样频率为12 kHz。实验设置了四种轴承故障类型,包括正常故障、球圈故障、内圈故障和外圈故障。为了模拟轴承的故障,采用电火花加工方法建立了故障直径为0.007、0.014和0.021英寸的3个严重级别。因此,我们可以在四种类型的条件下获得包含10种健康状态的数据集。在实验中,我们引入了一种数据增强方法,通过对有重叠的原始信号进行切片来扩展训练样本。定义两个相邻样本的移位大小为512,每个样本的长度分别为1024。总体数据包含5400个训练样本和600个测试样本,它们在1 hp至3 hp负载下的10种不同健康状态。下表列出了数据集描述的详细信息。
代码复现及分类性能
- 我们完整的复现了MCF-1DViT模型,并严格按照数据集的处理方式进行划分,最终的分类准确率可达99%,部分少量代码如下:
# 代码索要 @ 马化腾: 1444151069
"""++++++++++++++++++++++++++网络定义++++++++++++++++++++++++++"""
"""++++++++++++++++++++++++++模型训练++++++++++++++++++++++++++"""
class McfVit1D(nn.Module):
def __init__(self, num_classes=10):
super(McfVit1D, self).__init__()
self.mcf = MCF()
self.patch_emb = PatchEmbed()
num_patches = self.patch_emb.num_patchs
dim = 64
# class token & position learning
self.cls_token = nn.Parameter(torch.zeros(1, 1, dim))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, dim))
# vit blocks
self.blocks = nn.ModuleList(Block(dim=dim, num_heads=16, mlp_hidden_dim=128) for _ in range(6))
# classify head
self.head = nn.Linear(dim, num_classes)
self.norm = nn.LayerNorm(dim, eps=1e-6)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward(self, x):
x = self.mcf(x)
x = self.patch_emb(x)
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.cat((cls_token, x), dim=1)
x = x + self.pos_embed
for i, b in enumerate(self.blocks):
x = b(x)
x = self.norm(x)
head = self.head(x[:, 0])
return head
"""++++++++++++++++++++++++++模型训练++++++++++++++++++++++++++"""
"""++++++++++++++++++++++++++模型训练++++++++++++++++++++++++++"""
import math
import torch
from tqdm import tqdm
from torch import optim, nn
from mcf_vit1d import McfVit1D
from gene_data import load_data
import torch.optim.lr_scheduler as lr_scheduler
def one_cycle(y1=0.0, y2=1.0, steps=100):
# lambda function for sinusoidal ramp from y1 to y2
return lambda x: ((1 - math.cos(x * math.pi / steps)) / 2) * (y2 - y1) + y1
def train(epoch, train_loader):
# 训练函数
correct = 0
tra_loss = 0
train_data_bar = tqdm(train_loader)
for data, target in train_data_bar:
data, target = data.to(device), target.to(device)
# 梯度清零
optimizer.zero_grad()
# 网络前向传播
output = net(data)
# 计算loss
loss = criterion(output, target)
# loss 反向传播
loss.backward()
# loss 相加
tra_loss += loss.item()
# 计算准确率
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
optimizer.step()
train_data_bar.set_description(
f'Epoch:[{epoch}/{epochs}] Loss:{loss.item():.4f}| Correct:{correct}/{len(train_loader.dataset)}')
tra_loss /= len(train_loader.dataset)
# 打印相关信息
print('\tTrain set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)'.format(
tra_loss, correct, len(train_loader.dataset), 100. * correct / len(train_loader.dataset)))
@torch.no_grad()
def evaluate(val_loader):
global best_acc
# 验证函数
val_loss = 0
correct = 0
for data, target in val_loader:
data, target = data.to(device), target.to(device)
output = net(data)
# sum up batch loss
val_loss += criterion(output, target).item()
# get the index of the max log-probability
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
val_loss /= len(val_loader.dataset)
val_acc = 100. * correct / len(val_loader.dataset)
print('\t Val set: Average loss: {:.4f}, Accuracy: {}/{} ({:.4f}%)'.format(
val_loss, correct, len(val_loader.dataset), val_acc))
if best_acc < val_acc:
best_acc = val_acc
torch.save(net.state_dict(), './best.pth')
def run():
print('Load datasets ...')
train_loader, val_loader = load_data(bs=batchsize)
for epoch in range(1, epochs + 1):
net.train()
train(epoch, train_loader)
scheduler.step()
net.eval()
evaluate(val_loader)
print('Best Accuracy:{:.4f}%'.format(best_acc))
if __name__ == '__main__':
best_acc = 0.0
epochs = 10
batchsize = 4
device = torch.device("cuda:0" if torch.cuda.is_available() else 'cpu')
print('Using Device:', device.type)
net = McfVit1D(num_classes=10).to(device)
optimizer = optim.SGD(net.parameters(), lr=0.01)
scheduler = lr_scheduler.LambdaLR(optimizer, lr_lambda=one_cycle(1, 0.1, epochs))
criterion = nn.CrossEntropyLoss()
run()
- 我们还参照论文方法,对验证集的样本进行了t-SNE可视化,验证网络不同层输出对高维特征的分辨能力。

- 本人已将代码的复现版本打包好,项目中包含运行说明.txt文档以及所需环境.txt,需要一维信号分类以及其他Pytorch框架任务寻求帮助可私信。