基于PCIe的NVMe协议在FPGA中实现方法
NVMe协议是工作在PCIE的最上层协议层的,故需要先搞清楚PCIE。本文基于Xilinx的UltraScale+,开发工具为Vivado2021.2。学习中以spec为主,其它资料辅助参考(重点介绍学习方法及资料,有时间再加细节)。请勿转载!
1 PCIe学习与实践
1.1 理论
主要参考的文章是《老男孩读PCIe》,同时参考《古猫先生》,重点学习TLP报文部分,数据链路层和物理层的内容可以先不看。再买一本书《PCI Express 体系结构导读-王齐》用来查阅做笔记。


老男孩读PCIe介绍系列_Ha-Ha-Interesting的博客-CSDN博客_老男孩读pcie
PCIe最全科普贴流出!不说了,赶快Mark!_古猫先生的博客-CSDN博客
还有2本MindShare的英文书籍参考,备用即可。

 https://www.mindshare.com/files/ebooks/PCI%20Express%20System%20Architecture.pdf
https://www.mindshare.com/files/ebooks/PCI%20Express%20System%20Architecture.pdf
https://www.mindshare.com/files/ebooks/PCI%20Express%20Technology%203.0.pdf
在NVMe工程中用到的TLP类型为mem读写、config、中断:
- config TLP用户不用特别关心,在Xilinx IP GUI配置,由IP维护。它用于上电时host访问EP设备的reg,协商配置;
- 中断TLP用户也不直接使用,用户仅通过IO脉冲控制IP发出完整中断TLP,再检查IP给出的完成状态IO即可;
- mem TLP是需要用户真正掌握的,但是IP的AXI\stream口出来的TLP格式可能不是标准的TLP,它是对TLP做了进一步处理的。
1.2 工程
在Xilinx的Vivado中关于PCIe的IP有3个:PCIE4,XDMA,QDMA。后两个IP都基于前一个,使用难度递增、速率递增、资源占用也递增。
下列文章中详细介绍了7系列PCIE(此IP使用标准TLP格式,不同于UP系列PCIE4)、XDMA IP的基础配置、官方Demo的生成、仿真分析。Demo中用Verilog代码设计了一个RootPort来和EP通信,模拟了上电后Bar扫描、分配地址、速率宽度等协商配置。Demo中的EP代码可以用于实际的设计中。在7系Demo与UP demo中PCIE HEAD扩展reg的偏移地址有个别不同,以实际PG为准。
开发板可以用黑金、米联客的板子。

PCIe基础知识及Xilinx相关IP核介绍_lu-ming.xyz的博客-CSDN博客_pcie ip核 xilinx
2 NVMe理论学习
2.1 理论
2.1.1 学习内容
- NVMe的学习主要以Spec为主,官方下载链接如下,我使用的是spec1.2版本,此本版应该是蛋蛋读NVMe系列文章所用,图表序号能对应上。选用的功能可以先不看,并在NVMe配置reg、Controller Data Structure(4KB)中配置为关闭。
NVMe Base Specification – NVM Express![]() https://nvmexpress.org/developers/nvme-specification/
https://nvmexpress.org/developers/nvme-specification/
- 同时参考以下ssdfans blog,一共6篇,第5篇讲数据保护(可以选择不用),第6篇讲NameSpace(可以只用一个NS,NSID=1)
蛋蛋读NVMe之一(cmd processing)
蛋蛋读NVMe之二 (SQ,CQ和DB)
蛋蛋读NVMe之三 (PRP)
蛋蛋读NVMe之四(Trace)
蛋蛋读NVMe之五(Protection Information)
蛋蛋读NVMe之六(Namespace)
以下的系列4篇文章也可以参考对比:
NVMe 协议详解(一)_IFappy的博客-CSDN博客_nvme协议
NVMe详解(四)_IFappy的博客-CSDN博客_nvme smart-log 详解
下面文章对spec1.3做了部分翻译,有个别内容不准确,可以参考
【NVMe】NVMe 1.3协议中文翻译——第一章简介_ljyyyyyyyyy的博客-CSDN博客_nvme1.3协议
2.1.2 抓包工具trace
下面的文章实际抓取了NVMe报文,并做了分析,有助于理解NVMe工作的完整流程。PCIE协议可以使用分析仪抓取报文,分析仪串在链路中,抓取上行、下行报文。目前看到的文章中主要有2家:力科、Saniffer。
从PCIe trace中分析NVMe_Ingram14的博客-CSDN博客_pcie trace
【71】力科PCIe 协议分析仪常见操作_linjiasen的博客-CSDN博客_pcie协议分析仪
Saniffer公司的分析仪及软件,可以联系他们获取软件及SSD启动抓取的完整报文、分析仪的使用培训教程等等。
PCIe和NVMe SSD初始化过程简介_SSD学院_SSDtime
PCIe和NVMe SSD初始化过程简介-面包板社区 同一篇文章的不同链接。
2.1.3 Spec中重点关注的内容(我的调试)
1、spec1.2中7.6.1 Initialization 介绍了上电后整个通信链路建立的过程:host写NVMe reg、创建Admin Queue,通过Admin创建IO Queue。之后才能进行数据的读写。
2、spec 7.2.1command processing 介绍了取SQ,执行,返回CQ,中断的详细过程。注意在步骤4指令执行时,可能包含多个纯TLP报文完成数据读写,图中并未标出;
3、第1章主要是一些名词解释,重点1.6节。
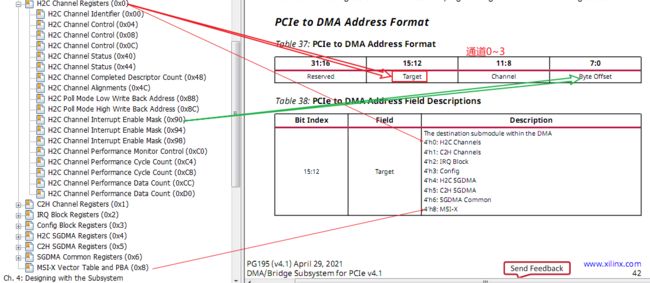
4、第2章是PCIE的寄存器配置,此部分内容在使用Xilinx IP时用户不能直接访问,而是通过IP GUI设置参数即可。在IP中必须注意class code要改为下方协议中值,否则无法识别为NVMe控制器。电源管理PM、中断MSI\MSI-X\等都在GUI配置,由IP负责维护reg。

5、第3章重点3.1节,是NVMe协议层reg,需要mem TLP来读写,这些reg有专门的地址,即TLP中的地址段。先不展开细说了,重点提示如下:
- INTMS,INTMC:这两个reg不是可选,但是也可不用,属于在协议层控制中断屏蔽。需要在本地维护一个中断屏蔽mask reg,置位mask<=mask | MS ,清除mask<=mask &(~MC),读取时都返回mask的值,而不是MC or MS 自己的值。
- AQA中由host写入的是ASQ、ACQ的队列深度,ASQ是Admin Submission Queue,其中一条指令缩写ASQE,占用64B。ACQE占用16B;
- ASQ中存储AdminSQ的基地址,要读取其中ASQE时,地址=baseaddr+head doorbell*64。而IO SQ的基地址不在这些reg中,它是在用Admin指令创建IO队列时才由host分配的,需要FPGA自己维护保存;
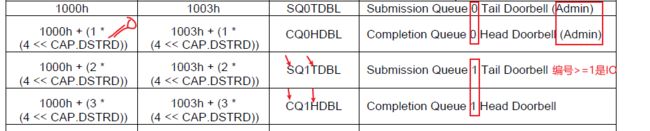
- SQTail DBL,CQHead DBL是由host维护写入FPGA中。编号0的是Admin,>=1是IO。Tail总是指向空,表示下一次可以写入的指针位置。Head≠Tail则表示Queue中还有Entry没有取走。SQHead DBL由PL自己维护,每读走一个SQE后+1.CQTail DBL由PL维护,每向host写一个CQE,Tail+1,注意队列的满空,以及从尾部返回到头部循环时,报文中的P位要0-1反转一次。
6、第4章 Memory structure,介绍了NVMe中一些基本的定义。重点4.1SQCQ定义,4.2SQE,4.3PRP,4.6CQE格式。其他的SGL、MR、CMB、Fused Operation都不用,arbitration只用默认的RoundRobin即可。
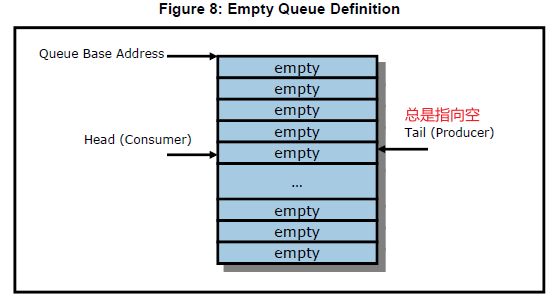
- 注意Queue的empty、full

- ASQE,IOSQE都包含64B=16DW,两者DW0的格式相同。一条SQE中本身包含两个PRP,一个PRP指向4K空间,超过8K空间需要使用PRP List,一个List的最大空间为4K,一个PRP地址本身占用8B,则一个List中最多512个PRP,若还有更多的PRP则第一个list的最后一个PRP指向下一个List的存放地址。PRP计算方法,考虑4K对齐(所谓4K对齐,是指如果访问地址不是从4K边界开始的,那么本次对多只能操作起始地址->4K边界尾)。
SSD NVMe核心之PRP算法_Ingram14的博客-CSDN博客
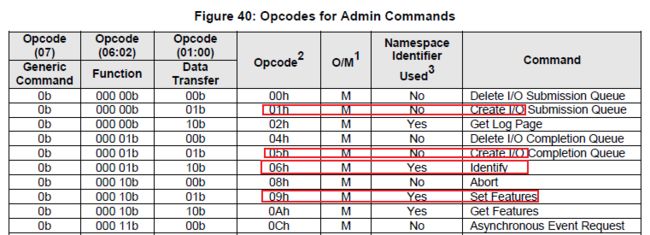
7、第5章是Admin指令。重点关注强制cmd中红圈部分,是初始化使用到的,顺序参见spec1.2 的7.6.1 Initialization 章节。5.11 Identify command中的data structure和namespace structure特别重要,至于figure91 电源可以只要一种即可,不支持切换。先创建CQ,后创建SQ;先删除SQ,后删除CQ。删除cmd就是把创建指令设置的各项参数都复位。
8、第6章是NVM=IO 指令,重点是读写。flush指令若没有用缓存,或确定数据已全部写入外部存储,可以不做操作,直接回复CQE即可。

9、第7章重点关注7.2指令的处理流程,7.6 控制器初始化过程(整理链路建立过程)。
10、第8章大部分都不用看,关注8.6 Doorbell Stride。在硬件使用时=0,用在doorbell reg 地址分配上,=0则紧凑排布。
2.2 工程实现
三种实现方案NVMe协议,基于3种不同的IP,QDMA仅支持ultralscale+器件。
2.2.1 PCIE4
PCIE4是ultralscale+器件中的型号,手册为PG213。与7 Series Integrated Block for PCI Express IP(PG054)略有不同,7系的IP用户数据stream接口分为tx,rx两个,报文格式基本与标准TLP相同;
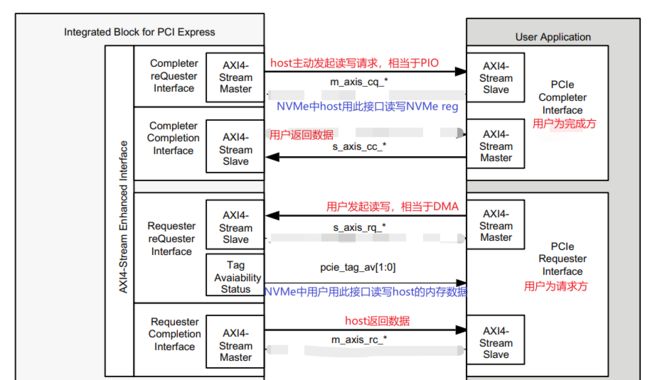
PCIE4 IP的用户接口分为4个:CQ/CC,RQ/RC。XX中前一位是用户的角色:C代表用户是完成方被动响应,R代表用户请求方主动发起;后一位表示请求数据or完成数据。报文格式与标准TLP略有不同。
Admin,IO指令都用PL纯逻辑实现,节约资源。用于和ASMedia USB转NVMe芯片的通信,此转接芯片的协议严格遵守了NVMe spec,不需要PC端有NVMe的驱动,PC将其识别为USB设备。
Controller data structure和Namespace data structure各占用4KB的空间,可以把参数提前配好,用一个ROM+.coe初始化文件的方式,供Admin读取。
调试时先确保PCIE层通信正常,可以使用WinDriver来调试CQ/CC口,即调试NVMe reg。注意使用金手指上的复位来复位PCIE4 IP。根据SQE中LBA的个数决定PRP List长度,读写数据前先读取PRPList,并压入FIFO中,用一个出一个。
2.2.2 XDMA
该方案用MicroBlaze核解析Admin指令,IO指令用PL逻辑实现,MB核占用资源。该方案需要PC端驱动的配合,无法与ASMedia芯片配合使用。
Demo由复旦大学设计,并且有配套论文,硬件基于KCU105开发板。设计中创建了一个Admin Queue,8个IO Queue。启用了XDMA的4条stream通道、descriptor bypass通道、AXI-master、AXI-slave。
- AXI-slave:用户配置XDMA的内部reg,控制中断,数据传输启动、停止等;
- AXI-master:host用来配置NVMe协议中的reg(维护在PL中),如doorbell head/tail;

- descriptor bypass通道:用户写入地址+长度,告知host要取回,或发出数据的信息。
- 4条stream通道:传输数据。数据可以是SQE、CQE等指令,也可以是要转移的数据。在demo设计中,2条steam用于读写SQE/CQE/PRP,2条steam用于读写数据。
https://github.com/yhqiu16/NVMeCHA
2.2.3 QDMA
Xilinx官方提供了Demo,使用QDMA+收费的NVMeTC。其Admin指令由MB核解析,且MB上运行了linux系统,占用大量资源。仅用于和PC通信。
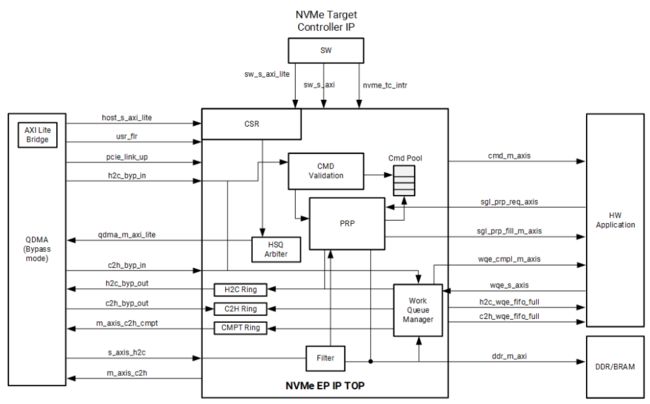
Documentation Portal https://docs.xilinx.com/r/en-US/pg329-nvme-target-controller?tocId=R9sEYjIxu5Zmhve4J9K7gg
https://docs.xilinx.com/r/en-US/pg329-nvme-target-controller?tocId=R9sEYjIxu5Zmhve4J9K7gg
在手册中搜索 Download the reference design files,下载工程。
3 测速软件
crystal disk mark:测速更准确。
HD_speed:可以长时间连续测试,由写+读+验证模式。