win10 YOLOv3-tf 训练自己的数据集
win10 YOLOv3-tf
- win10 YOLOv3-tf 训练自己的数据集
-
-
- 获取yolov3-tensorflow的项目
- 运行demo
- 制作自己的训练数据集
- 由数据集制作标准数据集txt文件及修改相应配置
- 训练数据
- 评价VOC数据集
- 运行训练的权重,修改demo使显示图片和bbox
-
win10 YOLOv3-tf 训练自己的数据集
1.获取项目https://github.com/YunYang1994/tensorflow-yolov3
2.运行demo(查看自己配置的环境是否符合)
3.制作训练数据集
注:经过实际操作发现yolov3的darknet版本(C/C++)相比与github上的tensorflow版本实用性更强,且用起来更方便,但是在windows下配置起来可能比tf版本麻烦一些,不过还是推荐使用,详细配置及训练过程见:
https://blog.csdn.net/longlong068/article/details/105088304
注:如果觉得windows下配置环境太过繁琐或者自己的电脑没有较高算力的GPU,可以采用谷歌Colab提供的免费云GPU服务来训练自己的数据集,具体操作见:谷歌Colab训练自己YOLOv3数据集
获取yolov3-tensorflow的项目
-
获取地址https://github.com/YunYang1994/tensorflow-yolov3
-
在window10 下配置对应需要的环境,采用tensorflow-gpu=1.11.0,及下载相应项目所需的包,推荐新建conda环境。(前提是安装了anaconda)
#运行CMD 创建单独的conda环境 conda create -n tf1.11 python=3.6.5 #激活conda环境 activate tf1.11 #在环境下安装对应的包 用conda或者pip都可以 conda install tensorflow-gpu==1.11.0conda install除了会下载指定包外,还会下载其他附带包,如果不需要可以采用pip下载单个包,但是pip和conda下载都很慢,conda安装可以先采用conda config配置一下清华源。
注:如果要用tensoflow-gpu,要事先下载cuda和cudnn。cuda和cudnn的安装配置见之前:https://blog.csdn.net/longlong068/article/details/105087705。
-
检查tensorflow-gpu是否正常运行
#在配置的tf1.11环境下 import tensorflow as tf print(tf.test.is_gpu_available()) >> True
运行demo
此项目下给出了image_demo,可以使自己在整体了解一下yolov3模型和检测一下自己的环境可行性。
-
下载已经训练好的权重文件和权重文件格式转换
$ cd checkpoint $ wget https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3_coco.tar.gz $ tar -xvf yolov3_coco.tar.gz $ cd .. $ python convert_weight.py $ python freeze_graph.py以上为运行demo之前需要做的操作,因为这个demo不包括模型的训练,模型的权重文件采用事先训练好的coco数据集权重,需要下载权重文件并放到checkpoin文件下,可在项目github上下载。下载完权重后,运行convert_weight.py和freeze_graph.py后,在目录下会生成yolov3c_coco.pb文件,如下。
-
运行image_demo.py或video_demo.py文件
$ python image_demo.py $ python video_demo.py # if use camera, set video_path = 0直接运行image_demo.py文件,其中demo的部分代码如下:
import cv2 import numpy as np import core.utils as utils import tensorflow as tf from PIL import Image return_elements = ["input/input_data:0", "pred_sbbox/concat_2:0", "pred_mbbox/concat_2:0", "pred_lbbox/concat_2:0"] pb_file = "./yolov3_coco.pb" image_path = "./docs/images/road.jpeg" num_classes = 80 input_size = 416 graph = tf.Graph()其中需要关注有pb_file(即上一步产生的.pb文件),image_path(所检测的图片路径),num_class因为采用了coco数据集训练所得权重所以此处为80,此后如果要训练自己的数据集,并用此demo来以图像的形式显示出来,需要对以上三个参数进行修改。
制作自己的训练数据集
此项目的作者给的训练模型是基于VOC数据格式的,所以在训练自己的数据集之前要按一定的形式制作自己的数据集,VOC数据集的文件结构如下:
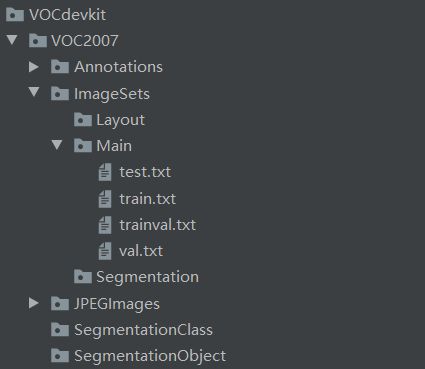
VOCdevkit
└─VOC2007
├─ImageSets # 存放数据集列表文件 主要关注其下的Main文件
├─Annotations # 存放图片标签,xml 格式
├─JPEGImages # 存放图片,训练集和测试集的原图片都放在这里
├─SegmentationClass
└─SegmentationObject
其中ImageSets
├─Main #主要关注Main 存放含有划分的训练集、测试集的文件名的多个txt文件
├─Layout
└─Segmentation
-
按以上图创建一样结构的VOCdevkit文件夹,将要进行训练测试的原图片(不需要考虑图片是否要画框和输入图片的分辨率,此yolov3-tf模型会将不同分辨率的图片进行resize)放入JPEGImages文件下,图片最好采用以下命名格式:
-
采用labelimg工具进行画框生成xml文件,并设置将生成的xml文件放到Annotations文件下。labelimg下载地址:链接:https://pan.baidu.com/s/1o41wwXzHEm2kZgz52A37BA
提取码:flwm -
划分训练集和测试集,在ImageSets\Main下生成train.txt和test.txt文件(包含相应划分数据集文件名的txt)。
可采用以下程序进行划分,此划分部分代码及流程都参考博主:
https://blog.csdn.net/qq_38441692/article/details/103652760,在此进行感谢。
划分数据集代码如下 在VOCdekit\VOC2007(即Annotations的上级目录)下运行spilt.py
import os import random import sys if len(sys.argv) < 2: print("no directory specified, please input target directory") exit() root_path = sys.argv[1] xmlfilepath = root_path + '/Annotations' txtsavepath = root_path + '/ImageSets/Main' if not os.path.exists(root_path): print("cannot find such directory: " + root_path) exit() if not os.path.exists(txtsavepath): os.makedirs(txtsavepath) trainval_percent = 0.9 train_percent = 0.8 total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) print("train and val size:", tv) print("train size:", tr) ftrainval = open(txtsavepath + '/trainval.txt', 'w') ftest = open(txtsavepath + '/test.txt', 'w') ftrain = open(txtsavepath + '/train.txt', 'w') fval = open(txtsavepath + '/val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()在对应的VOCdekit\VOC2007文件夹下建立以上代码的split.py文件并运行,此程序会将VOC2007\Annotations下的xml文件按9:1进行随机划分,并在VOC2007\ImageSets\Main下生成trian.txt、test.txt等文件。
-
制造yolov3-tensorflow即此项目要求结构的数据集
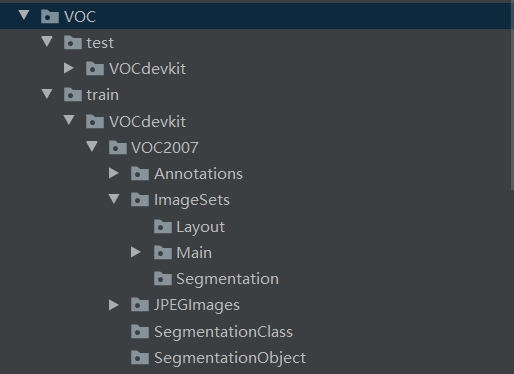
完成以上三步只是制作了符合标准VOC结构的数据集,但是此项目模型要求VOC数据集结构的基础上进行改变,以适应项目具体代码,此项目要求的数据集结构为:
VOC # path: /home/yang/dataset/VOC ├── test | └──VOCdevkit | └──VOC2007 (from VOCtest_06-Nov-2007.tar) └── train └──VOCdevkit └──VOC2007 (from VOCtrainval_06-Nov-2007.tar) └──VOC2012 (from VOCtrainval_11-May-2012.tar)可通过以下代码在以上生成的数据集的基础上进行修改,此脚本主要在前三步生成的Main\train.txt和Main\test.txt基础上运行。
import os from shutil import copyfile #根据tarin.txt和test.txt将数据集分为标准数据集(此yolov3-tf要求的标准数据集) train_text_path = 'D:/pycharmwork/traindata/dataset/wow/VOCdevkit/VOC2007/ImageSets/Main/train.txt' test_text_path = 'D:/pycharmwork/traindata/dataset/wow/VOCdevkit/VOC2007/ImageSets/Main/test.txt' #图片存放地址 image_path = 'D:/pycharmwork/traindata/dataset/wow/VOCdevkit/VOC2007/JPEGImages' #xml文件存放地址 xml_path = 'D:/pycharmwork/traindata/dataset/wow/VOCdevkit/VOC2007/Annotations' #输出的目录 outdir = 'D:/pycharmwork/traindata/dataset/wow' #创建各级文件夹 test_xml_out = os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/Annotations') os.makedirs(test_xml_out) os.makedirs(os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/ImageSets/Layout')) os.makedirs(os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/ImageSets/Main')) os.makedirs(os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/ImageSets/Segmentation')) test_img_out = os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/JPEGImages') os.makedirs(test_img_out) os.makedirs(os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/SegmentationClass')) os.makedirs(os.path.join(outdir,'VOC/test/VOCdevkit/VOC2007/SegmentationObject')) train_xml_out = os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/Annotations') os.makedirs(train_xml_out) os.makedirs(os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/ImageSets/Layout')) os.makedirs(os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/ImageSets/Main')) os.makedirs(os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/ImageSets/Segmentation')) train_img_out = os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/JPEGImages') os.makedirs(train_img_out) os.makedirs(os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/SegmentationClass')) os.makedirs(os.path.join(outdir,'VOC/train/VOCdevkit/VOC2007/SegmentationObject')) with open(train_text_path) as f: lines = f.readlines() for i in lines: img_save_path = os.path.join(train_img_out,i.rstrip('\n')+'.jpg') xml_save_path = os.path.join(train_xml_out, i.rstrip('\n') + '.xml') copyfile(os.path.join(image_path,i.rstrip('\n')+'.jpg'),img_save_path) copyfile(os.path.join(xml_path, i.rstrip('\n') + '.xml'), xml_save_path) print(i) with open(test_text_path) as f: lines = f.readlines() for i in lines: img_save_path = os.path.join(test_img_out, i.rstrip('\n') + '.jpg') xml_save_path = os.path.join(test_xml_out, i.rstrip('\n') + '.xml') copyfile(os.path.join(image_path, i.rstrip('\n') + '.jpg'), img_save_path) copyfile(os.path.join(xml_path, i.rstrip('\n') + '.xml'), xml_save_path) print(i)运行以上程序后会在设定的输出目录创建一个新的VOC目录,如下:
-
在test和trian文件下的VOC2007下运行spilt.py
以上只创建了对应文件夹和将xml和jpeg进行了划分,但是Main文件夹下还缺少train.txt、test.txt等,需要再进行划分。
#运行cmd 将路径切换到split.py所在路径 cd /d D:\ #具体路径 python .\split.py D:\pycharmwork\traindata\dateset\wow\VOC\train\VOCdevkit\VOC2007 python .\split.py D:\pycharmwork\traindata\dateset\wow\VOC\test\VOCdevkit\VOC2007
由数据集制作标准数据集txt文件及修改相应配置
-
将生成VOC文件拷贝到项目文件下,修改项目下的scripts/voc_annotation.py并运行此py文件,配置程序训练需要的两个文件如下:
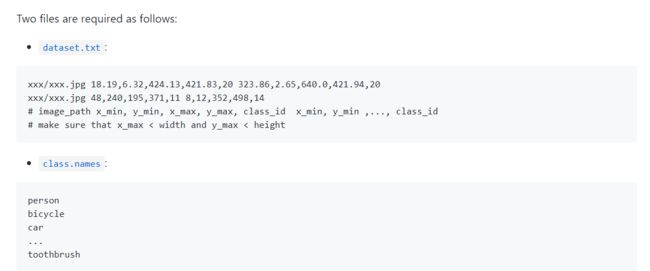
此部分流程:
#1.class.names: 将data/classes/voc_names中的类名修改为自己数据集的名字 #2.dataset.txt 修改voc_annotation.py ------>运行voc_annotation.py在voc_train.txt和voc_test.txt下生成所需格式上述两个所需文件在项目中的位置如下:
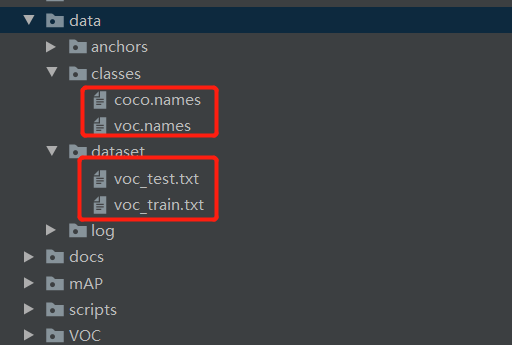
voc_test.txt和voc_train.txt由voc_annotation.py根据以上创建的结构生成。根据自己数据集VOC目录对voc_annotation.py进行修改,修改部分如下:
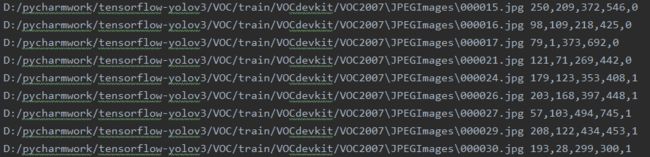
if __name__ == '__main__': parser = argparse.ArgumentParser() # default 更改为你自己数据集VOC的目录 parser.add_argument("--data_path", default="D:/pycharmwork/tensorflow-yolov3/VOC/") # default 更改为voc_train.txt的存放的位置 parser.add_argument("--train_annotation", default="../data/dataset/voc_train.txt") parser.add_argument("--test_annotation", default="../data/dataset/voc_test.txt") flags = parser.parse_args() if os.path.exists(flags.train_annotation):os.remove(flags.train_annotation) if os.path.exists(flags.test_annotation):os.remove(flags.test_annotation) # 更改训练集和测试集的相对路径 num1 = convert_voc_annotation(os.path.join(flags.data_path, 'train/VOCdevkit/VOC2007'), 'trainval', flags.train_annotation, False) #num2 = convert_voc_annotation(os.path.join(flags.data_path, 'train/VOCdevkit/VOC2012'), 'trainval', flags.train_annotation, False) num3 = convert_voc_annotation(os.path.join(flags.data_path, 'test/VOCdevkit/VOC2007'), 'test', flags.test_annotation, False) print('=> The number of image for train is: %d\tThe number of image for test is:%d' %(num1 , num3))生成的voc_train.txt中内容形式如下:
-
修改config配置文件
编辑您的文件./core/config.py以进行一些必要的配置,如下:
__C.YOLO.CLASSES = "./data/classes/voc.names" __C.TRAIN.ANNOT_PATH = "./data/dataset/voc_train.txt" __C.TEST.ANNOT_PATH = "./data/dataset/voc_test.txt"至此,训练所需要的数据形式已经有了,接下来就是运行训练了。
训练数据
此模型提供了两种训练方式:
-
从头开始训练
$ python train.py $ tensorboard --logdir ./data -
从COCO配置训练(推荐)
$ cd checkpoint $ wget https://github.com/YunYang1994/tensorflow-yolov3/releases/download/v1.0/yolov3_coco.tar.gz $ tar -xvf yolov3_coco.tar.gz $ cd .. $ python convert_weight.py --train_from_coco $ python train.py
注:如果显卡内存不是很大的话,建议修改一下config.py文件下的__C.TRAIN.BATCH_SIZE,可以改小一点。
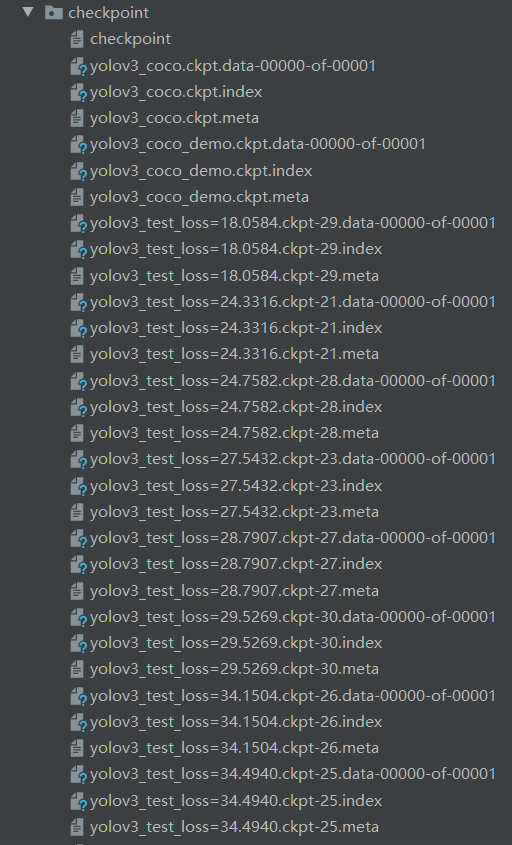
训练30个epoch,会在checkpoint下生成权重文件,如下:
评价VOC数据集
$ python evaluate.py
$ cd mAP
$ python main.py -na
运行训练的权重,修改demo使显示图片和bbox
当我们训练完成,想要采用训练的权重,在此基础上显示自己图片及其bbox,可以采用修改image_demo.py和configure.py。
-
先生成自己权重的.pb文件:
此步和运行demo前步骤一样,运行如以下代码,但在运行前需要对freeze_graph.py进行修改,将转换权重设置为自己训练产生的权重和修改一下生成.pb文件的名字。
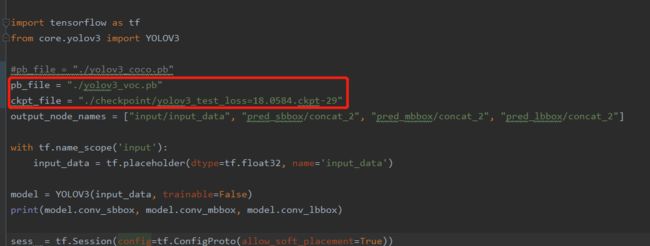
$ python convert_weight.py $ python freeze_graph.py -
将想要检测的图片放到"./docs/images/"路径下
-
修改configure.py
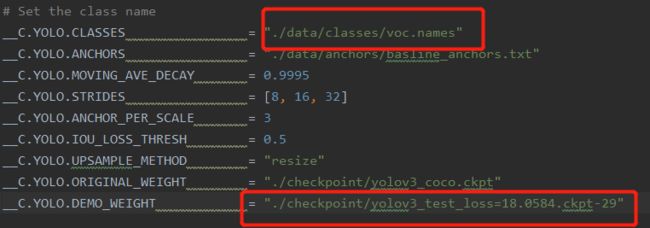
其中确保voc.names中为自己数据集中类的名字,将demo_weight修改为自己选择的权重文件。
-
拷贝image_demo.py为new_image_demo.py,并对其进行部分修改:
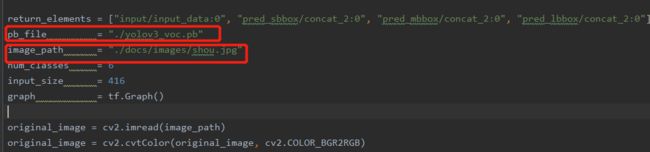
将pb_file修改为第一步生成的.pb文件;将image_path设置为自己要检测图片的路径
-
运行new_image_demo.py,效果图如下:
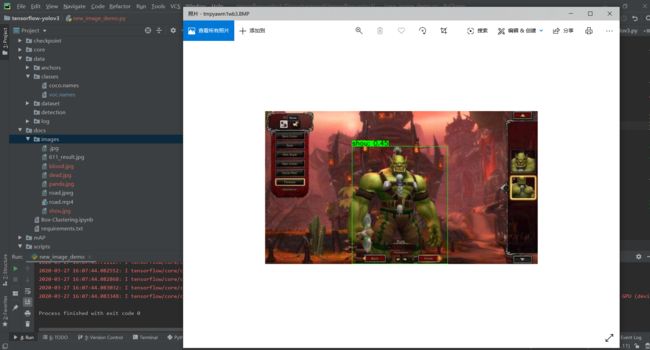
参考:https://blog.csdn.net/qq_38441692/article/details/103652760