python pytorch使用
文章目录
- pytorch介绍
- 基本张量操作
- 使用gpu
- 保存模型
-
- gpu和cpu
- 训练结束后保存
-
- 如何选取最优的?
- 保存模型:数据量大,加载时慢
-
- 保存格式
- 代码
- 保存模型参数
-
- 保存格式
- 代码
- 训练中不得已结束(如:停电断网)时保存 checkpoint 断点续传,以便加载后继续训练
-
- 保存格式
- 代码
- pytorch自带数据集
- pytorch从数据集制作mini-batch
- 训练集和测试集
-
- 从pytorch自带的数据集
- 本地数据
- pytorch实现线性回归
- pytorch实现逻辑斯蒂回归:一维数据的二项分布
-
- 与线性回归区别1. 是否有激活函数
- 与线性回归区别2. 损失函数
- pytorch实现逻辑斯蒂回归:多维数据的二项分布
- 多层网络的二项分类
- 加载数据集的全连接神经网络的二项分类
- MNIST,通过全连接神经网络实现多分类
- MNIST CNN-gpu 多分类
-
- gpu-cpu区别
- gpu版
- Inception Module:带分支的网络,超参数优化
-
- 作用
- 结构代码
- MNIST 多分类 cnn inception
-
- 结构
- 代码
- ResidualBlock resnet 残差网络:解决神经网络的梯度消失
-
- 梯度消失问题
- resnet 结构
- resnet怎么解决梯度消失问题
- resblock 代码
- MNIST 卷积+resBlock 多分类
pytorch介绍
PyTorch是一个处理张量的库。张量:Tensor,可以是一个标量、一维、二维、或任何n维数组
Tensor是一个类,包含data(参数值,是一个Tensor)和grad(损失对参数的偏导,也是一个Tensor)

Tensor直接参与运算【张量与张量运算,张量与标量运算】,是在构建计算图
基本张量操作
from torchvision import transforms
Tensor.item()#当Tensor中数据为标量时,返回python的标量:只适用于保存了标量的Tensor
# 一般张量参与运算时,即构建计算图。但张量.data参与运算时,此时不参与构建计算图
Tensor.data#x.data返回和x的相同数据 tensor, 将参数从网络中隔离开,不会加入到x的计算历史里,不参与更新
x = torch.Tensor(2,3) #构造一个2x3的张量,没初始化但仍然会有值
x = torch.Tensor([1.0]) #构造一个张量
# 从numpy创建张量
array_numpy = numpy.array([1, 2, 3])
t = torch.from_numpy(array_numpy)# 注意该法创建的tensor于原ndarray共享内存,当修改其中一个数据,另一个也将会被改动
#根据size创建未初始化的张量,有随机数据u
#torch.empty(*size, out=None, dtype=None, layout=torch.strided, device=None, requires_grad=False, pin_memory=False)
torch.empty(2, 3)
torch.ones(2,3)# 根据size创建全0张量
# 创建同input_tensor形状的全0张量
input = torch.empty(2, 3)
torch.ones_like(input)
torch.zeros(2,3)# 根据size创建全1张量
# 创建同input_tensor形状的全1张量
torch.zeros_like(input)
# 修改张量的维度
tensor.view()#其中出现-1时,表示该位置自动计算
tensor=torch.randn(4,4) #4*4
tensor.view(16)#torch.Size([16])
tensor.view(2,-1)#torch.Size([2, 8])
tensor.view(-1,8)#torch.Size([2, 8])
tensor.view(2,2,-1)#torch.size([2,2,4])
tensor.view(-1,2,2)#torch.size([4,2,2])
torch.exp(input_tensor)#返回一个新张量,包含输入input张量每个元素的指数
'''
神经网络希望输入的数据比较小,最好[-1,1],最好属于正态分布,对训练有帮助
Compose中[]里都是类,将数据按照[]中的顺序对PIL.Image进行依次处理
transforms.ToTensor():
opencv读取图片为np.array:高*宽*通道数(彩色是高*宽*3,黑白是高*宽),像素值为0~255,bgr需转为rgb使用
pillow(pytorch的tv.dataset读取图片时使用)读取图片为:Image对象(宽*高),像素值为0~255,rgb,可直接使用ToTensor,或者先转为np.array此时变为那个
transforms.ToTensor()将其变成:通道数*高*宽(彩色是3*高*宽,黑白是1*高*宽),像素值进行归一化:先转为float后除以255.为0~1,方便高效处理数据
transforms.Normalize((0.1307,), (0.3081,)):
n为通道数
(mean,std)=((均值1,均值2,..均值n,(标准差1. 标准差2,..标准差n))
统计了数据的均值和标准差之后的数值
标准化:(数值-mean)/std,使其服从分布N(0,1) 均值为0,标准差为1,不一定是正太分布
'''
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
使用gpu
# 检测是否有gpu
status=torch.cuda.is_available()
# gpu个数
num=torch.cuda.device_count()
#如果有gpu,使用gpu
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#使用gpu计算,把数据转为gpu专用
x_data,y_data=x_data.to(device),y_data.to(device)
保存模型
gpu和cpu
训练结束后保存
如何选取最优的?
- 在训练时,放入测试,最后选择测试集上效果最好的
- 保存训练过程中最小损失的模型
保存模型:数据量大,加载时慢
保存格式
.pth
代码
- 保存模型:存训练过程中最小损失的模型
import torch
import copy
min_loss=100#给一个大值
min_epoch=3#更改min_loss的epoch
best_model=None
def train(x):
global min_loss
global min_epoch
global best_model
if loss<min_loss and epoch>=min_epoch:
min_loss=loss
best_model=copy.deepcopy(model)
path="D:/"
now = datetime.datetime.now()
now_time=now.strftime("%Y-%m-%d-%H%M%S")
torch.save(model.state_dict(),path+'/' + str(now_time)+' loss=' + str("%.4f" % min_loss) + '.pth')
- 保存模型:在训练时,放入测试,最后选择测试集上效果最好的
import torch
import copy
min_loss=100#给一个大值
min_epoch=3#更改min_loss的epoch
best_model=None
best_acc=0 #给一个小值
def train(x):
global min_loss
global min_epoch
global best_model
#训练结束
acc=test()
if acc>best_acc and epoch>=min_epoch:
min_loss=loss
best_acc=acc
best_model=copy.deepcopy(model)
path="D:/"
now = datetime.datetime.now()
now_time=now.strftime("%Y-%m-%d-%H%M%S")
torch.save(model.state_dict(),path+'/' + str(now_time)+' loss=' + str("%.4f" % min_loss) + ' acc=' + str("%.4f" % best_acc)+'.pth')
- 加载模型
class Net(torch.nn.Module):
pass
path="D:/nn/2021-07-31-165415 loss=12.9383.pth"
model = torch.load(path)
保存模型参数
保存格式
.pth.state
代码
- 保存模型:存训练过程中最小损失的模型
import torch
import copy
min_loss=100#给一个大值
min_epoch=3#更改min_loss的epoch
best_model_state_dict=None
def train(x):
global min_loss
global min_epoch
global best_model_state_dict
if loss<min_loss and epoch>=min_epoch:
min_loss=loss
best_model_state_dict=model.state_dict()
path="D:/"
now = datetime.datetime.now()
now_time=now.strftime("%Y-%m-%d-%H%M%S")
#torch.save(net.state_dict(),PATH)
torch.save(best_model_state_dict,path+'/' + str(now_time)+' loss=' + str("%.4f" % min_loss) + '.pth.state')
- 保存模型:在训练时,放入测试,最后选择测试集上效果最好的
import torch
import copy
min_loss=100#给一个大值
min_epoch=3#更改min_loss的epoch
best_model_state_dict=None
best_acc=0 #给一个小值
def train(x):
global min_loss
global min_epoch
global best_model_state_dict
#训练结束
acc=test()
if acc>best_acc and epoch>=min_epoch:
min_loss=loss
best_acc=acc
best_model_state_dict=model.state_dict()
path="D:/"
now = datetime.datetime.now()
now_time=now.strftime("%Y-%m-%d-%H%M%S")
#torch.save(net.state_dict(),PATH)
torch.save(best_model_state_dict,path+'/' + str(now_time)+' loss=' + str("%.4f" % min_loss) + ' acc=' + str("%.4f" % best_acc)+'.pth.state')
- 加载模型
class Net(torch.nn.Module):
pass
path="D:/nn/2021-07-31-165415 loss=12.9383.pth.state"
model = Net(*args, **kwargs)
model.load_state_dict(torch.load(path))
训练中不得已结束(如:停电断网)时保存 checkpoint 断点续传,以便加载后继续训练
保存格式
.pth.checkpoint
代码
- 保存
checkpoint_dict={
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss,
}
path="D:/"
now = datetime.datetime.now()
now_time=now.strftime("%Y-%m-%d-%H%M%S")
#torch.save(checkpoing_dict, PATH)
torch.save(checkpoing_dict,path+'/' + str(now_time)+'.pth.checkpoint')
- 加载
'''
运行推理之前,务必调用 model.eval() 去设置 dropout 和 batch normalization 为评估。
如果不这样做,有可能得到不一致的推断结果。 如果你想要恢复训练,请调用 model.train() 以
确保这些层处于训练模式。
'''
class Net(torch.nn.Module):
pass
model = Net(*args, **kwargs)
optimizer = TheOptimizerClass(*args, **kwargs)
path="D:/nn/2021-07-31-165415.pth.checkpoint"
checkpoint_dict = torch.load(path)
model.load_state_dict(checkpoint_dict['model_state_dict'])
optimizer.load_state_dict(checkpoint_dict['optimizer_state_dict'])
start_epoch = checkpoint['epoch']+1
loss = checkpoint['loss']
pytorch自带数据集
import torchvision as tv
#torchvision.datasets为数据集
'''
minist:手写数字图片,用于分类器的检测
training set:6000
test set:1000
classes:10
'''
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = tv.datasets.MNIST(root='', train=True,transform=tv.transforms.toTensor(),download=True)
test_set = tv.datasets.MNIST(root='', train=False,transform=tv.transforms.toTensor(),download=True)
'''
CIFAR-10:动物、交通工具图片,用于分类器的检测
training set:5000
test set:1000
classes:10
'''
train_set2 = tv.datasets.CIFAR10(root='', train=True,transform=tv.transforms.toTensor(),download=True)
test_set2 = tv.datasets.CIFAR10()(root='', train=False,transform=tv.transforms.toTensor(),download=True)
pytorch从数据集制作mini-batch
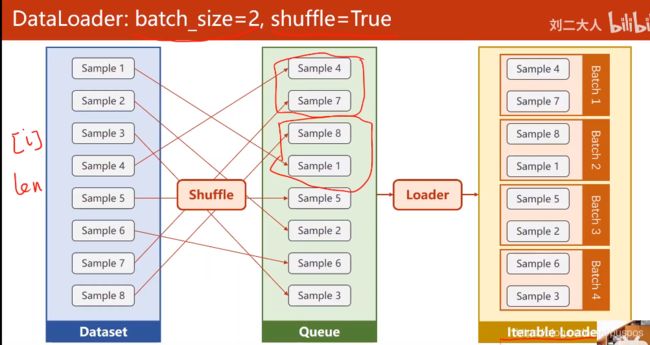
#Dataset抽象类,不能实例化,只能被子类继承,使用时需构造自己的类
from torch.utils.data import Dataset
#DataLoader加载数据于pytorch
from torch.utils.data import DataLoader
'''
Dataset是抽象类,不能实例化,继承Dataset时,需要重写__init__,__getitem__和__len__
1. 数据量不大,如结构性的:直接在__init__加载所有数据进内存,如下
2.数据量大,如图片,语音:
x:在__init__中把文件名放到列表里,__getitem__用时再加载进内存,并返回
y是:
简单的数值,__init__直接加载进内存
复杂的张量,在__init__中把文件名放到列表里,__getitem__用时再加载进内存,并返回
'''
class DataDataset(Dataset):
def __init__(self,filepath):
#因为一般的显卡只支持32位浮点数,所以不用double64位
data = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=data.shape[0]#shape (行数,列数)
self.x_data=torch.from_numpy(data[:, :-1])
self.y_data=torch.from_numpy(data[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset=DataDataset('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz')
'''
batch_size:mini-batch的样本数
shuffle:分组前先打乱顺序
num_workers:读取进内存时,是否多线程,windows下,要求须在__name__=='__main__'下调用
'''
train_loader=DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,(x_data_mini_batch,y_data_mini_batch) in enumerate(train_loader,0):
训练集和测试集
从pytorch自带的数据集
#DataLoader加载数据于pytorch
from torch.utils.data import DataLoader
import torchvision as tv
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = tv.datasets.MNIST(root='', train=True,transform=tv.transforms.toTensor(),download=True)
test_set = tv.datasets.MNIST(root='', train=False,transform=tv.transforms.toTensor(),download=True)
train_loader=DataLoader(dataset=train_set,batch_size=32,shuffle=True)
#不需打乱
test_loader=DataLoader(dataset=test_set,batch_size=32,shuffle=False)
for batch_idx, (x_data_mini_batch,y_data_mini_batch) in enumerate(train_loader):
本地数据
# 读取原始数据,并划分训练集和测试集
raw_data = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)
X = raw_data[:, :-1]
y = raw_data[:, [-1]]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
Xtest = torch.from_numpy(Xtest)
Ytest = torch.from_numpy(Ytest)
# 将训练数据集进行批量处理
# prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, data,label):
self.len = data.shape[0] # shape(多少行,多少列)
self.x_data = torch.from_numpy(data)
self.y_data = torch.from_numpy(label)
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
train_dataset = DiabetesDataset(Xtrain,Ytrain)
train_loader = DataLoader(dataset=train_dataset, batch_size=32, shuffle=True, num_workers=1) #num_workers 多线程
pytorch实现线性回归
# -*- coding: utf-8 -*-
"""
Created on Thu Jul 15 16:12:43 2021
@author: Administrator
"""
import torch
import matplotlib.pyplot as plt
epoch_list=[]
loss_list=[]
#torch.nn.Module是所有网络的父类
#torch.nn.Module是callable的。可以采用对象(参数)的方式
class LinearModel(torch.nn.Module):
#构造函数
def __init__(self):
super(LinearModel,self).__init__()
#(in_feature:每个样本的特征,out_feature,bias=True 要b)
#获取w张量:self.linear.weight
#获取b张量: self.linear.bias
self.linear=torch.nn.Linear(1,1,bias=True)
#重载nn.Module中的forward函数,定义y_pred=wx+b
def forward(self,x_data):
y_pred=self.linear(x_data)
return y_pred
#不用写backward函数,nn.Module会自动生成
x_data=torch.Tensor([[1.0],[2.0],[3.0]])#3*1
y_data=torch.Tensor([[2.0],[4.0],[6.0]])#3*1
model=LinearModel()
'''
MSELoss继承torch.nn.Module
(size_average,reduce)
size_average:要不要求均值,即要不要求1/n,其实求不求一样,因为求导后常数项没有影响,设为False后还少一步计算,只会影响学习率,不求均值时,相较于求均值时学习率要设置得更小。
reduce:最终要不要降维,一般不考虑
'''
#损失函数
criterion=torch.nn.MSELoss(size_average=False)
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
for epoch in range(100):
#y_pred是Tensor,3*1
y_pred=model(x_data)
#loss此时是个Tensor,loss的数据只有一个标量
loss=criterion(y_pred, y_data)
epoch_list.append(epoch)
loss_list.append(loss.item())
#把所有参数的梯度都归零
optimizer.zero_grad()
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新参数
optimizer.step()
#Tensor.item() 当Tensor中数据为标量时,返回python的标量:只适用于保存了标量的Tensor
#把w的梯度数据取出来,否则w.grad会构建计算图,吃内存
print('w:',model.linear.weight.item())
print('b:',model.linear.bias.item())
#测试,只有一个样本
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
plt.plot(epoch_list, loss_list)
plt.ylabel("losss")
plt.xlabel("epoch")
plt.show()
pytorch实现逻辑斯蒂回归:一维数据的二项分布
逻辑斯蒂回归实际是分类函数
与线性回归区别1. 是否有激活函数
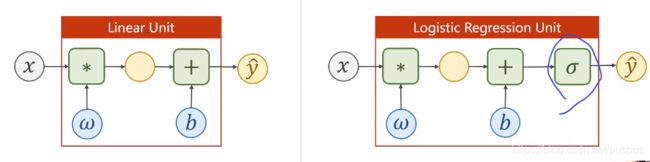
与线性回归区别2. 损失函数
线性回归的损失函数:计算预测值和实际值之间的差距
逻辑斯蒂回归(实为分类):计算预测分布和实际分布之间的差距


import torch
import torch.nn.functional as f
import matplotlib.pyplot as plt
epoch_list=[]
loss_list=[]
# prepare dataset
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[0], [0], [1]])
#design model using class
class LogisticRegressionModel(torch.nn.Module):
def __init__(self):
super(LogisticRegressionModel, self).__init__()
#输入的样本特征为1个,输出的特征为1
self.linear = torch.nn.Linear(1,1)
def forward(self, x):
#激活函数
y_pred = f.sigmoid(self.linear(x))
return y_pred
model = LogisticRegressionModel()
# BCE:二分类的交叉熵作为损失函数。
#size_average:要不要求均值,即要不要求1/n,其实求不求一样,因为求导后常数项没有影响,设为False后还少一步计算,只会影响学习率,不求均值时,相较于求均值时学习率要设置得更小。
criterion = torch.nn.BCELoss(size_average = False)
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# training cycle forward, backward, update
for epoch in range(1000):
#y_pred是张量
y_pred = model(x_data)
#loss是数据为一个标量的张量
loss = criterion(y_pred, y_data)
epoch_list.append(epoch)
loss_list.append(loss.item())
#把所有参数的梯度都归零
optimizer.zero_grad()
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新参数
optimizer.step()
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)
plt.plot(epoch_list, loss_list)
plt.ylabel("losss")
plt.xlabel("epoch")
plt.show()
pytorch实现逻辑斯蒂回归:多维数据的二项分布


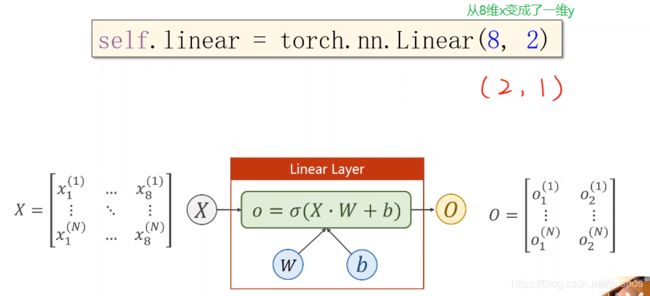
多层网络的二项分类
import matplotlib.pyplot as plt
import torch
import numpy as np
epoch_list=[]
loss_list=[]
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
#第一个线性模型:输入的样本特征为8个,输出的特征为6
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
self.linear1=torch.nn.Linear(8, 6)
#第二个线性模型:输入样本特征为上层的输出特征数6,输出特征数为4
self.linear2=torch.nn.Linear(6, 4)
#第三个线性模型:输入样本特征为上层的输出特征数6,输出特征数为4
self.linear3=torch.nn.Linear(4, 1)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
self.sigmoid=torch.nn.Sigmoid()
self.activate=torch.nn.ReLU()
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
'''
#x_data_2 第一层输出,也是第二层输入
x_data=self.sigmoid(self.linear1(x_data))
#x_data_3 第二层输出,也是第三层输入
x_data=self.sigmoid(self.linear2(x_data))
#y_pred
x_data=self.sigmoid(self.linear3(x_data))
'''
#x_data_2 第一层输出,也是第二层输入
x_data=self.activate(self.linear1(x_data))
#x_data_3 第二层输出,也是第三层输入
x_data=self.activate(self.linear2(x_data))
#y_pred
x_data=self.sigmoid(self.linear3(x_data))
return x_data
model=Model()
#因为一般的显卡只支持32位浮点数,所以不用double64位
data = np.loadtxt('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz',delimiter=',',dtype=np.float32)
x_data=torch.from_numpy(data[:,:-1])
y_data=torch.from_numpy(data[:,[-1]])
criterion=torch.nn.BCELoss(size_average=True)
optimizer=torch.optim.SGD(model.parameters(),lr=0.1)
for epoch in range(1000):
#前馈
#y_pred是张量
y_pred = model(x_data)
#loss是数据为一个标量的张量
loss = criterion(y_pred, y_data)
epoch_list.append(epoch)
loss_list.append(loss.item())
#把所有参数的梯度都归零
optimizer.zero_grad()
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新参数
optimizer.step()
print(loss_list[-1])
plt.plot(epoch_list, loss_list)
plt.ylabel("losss")
plt.xlabel("epoch")
plt.show()
加载数据集的全连接神经网络的二项分类
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
epoch_list=[]
loss_list=[]
'''
Dataset是抽象类,不能实例化,继承Dataset时,需要重写__init__,__getitem__和__len__
1. 数据量不大,如结构性的:直接在__init__加载所有数据进内存,如下
2.数据量大,如图片,语音:
x:在__init__中把文件名放到列表里,__getitem__用时再加载进内存,并返回
y是:
简单的数值,__init__直接加载进内存
复杂的张量,在__init__中把文件名放到列表里,__getitem__用时再加载进内存,并返回
'''
class DataDataset(Dataset):
def __init__(self,filepath):
#因为一般的显卡只支持32位浮点数,所以不用double64位
data = np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=data.shape[0]#shape (行数,列数)
self.x_data=torch.from_numpy(data[:, :-1])
self.y_data=torch.from_numpy(data[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset=DataDataset('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz')
'''
batch_size:mini-batch的样本数
shuffle:分组前先打乱顺序
num_workers:读取进内存时,是否多线程,windows下,要求须在__name__=='__main__'下调用
'''
train_loader=DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
#第一个线性模型:输入的样本特征为8个,输出的特征为6
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
self.linear1=torch.nn.Linear(8, 6)
#第二个线性模型:输入样本特征为上层的输出特征数6,输出特征数为4
self.linear2=torch.nn.Linear(6, 4)
#第三个线性模型:输入样本特征为上层的输出特征数6,输出特征数为4
self.linear3=torch.nn.Linear(4, 1)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
self.sigmoid=torch.nn.Sigmoid()
self.activate=torch.nn.ReLU()
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
'''
#x_data_2 第一层输出,也是第二层输入
x_data=self.sigmoid(self.linear1(x_data))
#x_data_3 第二层输出,也是第三层输入
x_data=self.sigmoid(self.linear2(x_data))
#y_pred
x_data=self.sigmoid(self.linear3(x_data))
'''
#x_data_2 第一层输出,也是第二层输入
x_data=self.activate(self.linear1(x_data))
#x_data_3 第二层输出,也是第三层输入
x_data=self.activate(self.linear2(x_data))
#y_pred
x_data=self.sigmoid(self.linear3(x_data))
return x_data
model=Model()
# construct loss and optimizr
'''
BCE:二分类的交叉熵作为损失函数。要求数据都是[0,1]
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
size_average:要不要求均值,即要不要求1/n,其实求不求一样,因为求导后常数项没有影响,设为False后还少一步计算,只会影响学习率,不求均值时,相较于求均值时学习率要设置得更小。
reduce:默认为None
为False时,size_average不起作用
为True时:
size_average=True返回loss的均值
size_average=False返回loss的和
reduction:让输出减少。
为'none'时,不减少,返回向量
为'sum',返回loss之和
为'mean' 返回loss的均值
'''
criterion=torch.nn.BCELoss(reduction='mean')
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,(x_data_mini_batch,y_data_mini_batch) in enumerate(train_loader,0):
y_pred_mini_batch=model(x_data_mini_batch)
loss=criterion(y_pred_mini_batch, y_data_mini_batch)
print(epoch,loss.item())
epoch_list.append(epoch)
loss_list.append(loss.item())
#把所有参数的梯度都归零
optimizer.zero_grad()
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新参数
optimizer.step()
plt.plot(epoch_list, loss_list)
plt.ylabel("losss")
plt.xlabel("epoch")
plt.show()
MNIST,通过全连接神经网络实现多分类
# -*- coding: utf-8 -*-
"""
多分类问题,标签y是one-hot,对应的类型是LongTensor。
y=torch.LongTensor([2]),对应的one-hot为[0,0,1,0,0]假如5个类
"""
import matplotlib.pyplot as plt
import torch
import numpy as np
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
time_list=[]
time=1
loss_list=[]
batch_size=64
'''
神经网络希望输入的数据比较小,最好[-1,1],最好属于正态分布,对训练有帮助
Compose中[]里都是类,将数据按照[]中的顺序依次处理
transforms.ToTensor():
opencv和pillow(pytorch读取图片时使用)读取图片矩阵为:高*宽*通道数(彩色是高*宽*3,黑白是高*宽),像素值为0~255
transforms.ToTensor()将其变成:通道数*高*宽(彩色是3*高*宽,黑白是1*高*宽),像素值进行归一化:先转为float后除以255.为0~1,方便高效处理数据
transforms.Normalize((0.1307,), (0.3081,)):
n为通道数
(mean,std)=((均值1,均值2,..均值n,(标准差1. 标准差2,..标准差n))
统计了数据的均值和标准差之后的数值
标准化:(数值-mean)/std,使其服从分布N(0,1) 均值为0,标准差为1,不一定是正太分布
'''
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=True,transform=transform,download=True)
test_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=False,transform=transform,download=True)
train_loader=DataLoader(dataset=train_set,batch_size=batch_size,shuffle=True)
#不需打乱
test_loader=DataLoader(dataset=test_set,batch_size=batch_size,shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
#第一个线性模型:输入的样本特征为784个,输出的特征为512
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
self.linear1=torch.nn.Linear(784, 512)
self.linear2=torch.nn.Linear(512, 256)
self.linear3=torch.nn.Linear(256, 128)
self.linear4=torch.nn.Linear(128, 64)
self.linear5=torch.nn.Linear(64, 10)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
self.sigmoid=torch.nn.Sigmoid()
self.relu=torch.nn.ReLU()
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
#把(n,1,28,28)->(n,28*28=784),因为全连接神经网络要求输入样本是矩阵即2维
#(-1,784) -1表自动计算n,784即把一张图片的三阶数据的变成一阶向量共有784个数据
x_data=x_data.view(-1,784)
#x_data_2 第一层输出,也是第二层输入
x_data=self.relu(self.linear1(x_data))
#x_data_3 第二层输出,也是第三层输入
x_data=self.relu(self.linear2(x_data))
x_data=self.relu(self.linear3(x_data))
x_data=self.relu(self.linear4(x_data))
#y_pred,还没有使用softmax
return self.linear5(x_data)
model=Net()
#因为一般的显卡只支持32位浮点数,所以不用double64位
#data = np.loadtxt('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz',delimiter=',',dtype=np.float32)
#x_data=torch.from_numpy(data[:,:-1])
#y_data=torch.from_numpy(data[:,[-1]])
#CrossEntropyLoss=softmax+NLLLoss
#NLLLoss=交叉熵 -yln(softmax(y_pred)) y_pred还没有经过激活函数
criterion=torch.nn.CrossEntropyLoss()
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率,冲量系数
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.5)
#一轮训练
def train(epoch):
running_loss=0.0
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,(x_data_mini_batch,y_data_mini_batch) in enumerate(train_loader,0):
#把所有参数的梯度都归零
optimizer.zero_grad()
#前馈
y_pred_mini_batch=model(x_data_mini_batch)
loss=criterion(y_pred_mini_batch, y_data_mini_batch)
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新,优化参数
optimizer.step()
running_loss+=loss.item()
if i%300 == 299:
#没训练300个batch,输出一次loss
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/300))
time_list.append(len(time_list)+1)
loss_list.append(running_loss/300)
running_loss=0.0
def test():
correct=0
total=0
# 不用计算梯度,因为train时已经训练好了
with torch.no_grad():
for data in test_loader:
x_data,y_data=data
#y_pred是个矩阵n*10【10分类】,每行是一个样本属于各种类的可能性概率,下标是种类
y_pred=model(x_data)
#获取每行的最大值及其下标【该样本属于哪个种类】
_,which_class=torch.max(y_pred.data,dim=1)
total+=y_data.size(0)#batch_size y_data.size=(n,1) n行1列
correct += (which_class == y_data).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
plt.plot(time_list, loss_list)
plt.ylabel("loss")
plt.xlabel("300batch_th")
plt.show()
MNIST CNN-gpu 多分类

gpu-cpu区别
'''模型部分'''
model=Net()
#如果有gpu,使用gpu
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
'''数据部分 train或test时'''
x_data,y_data=data
#使用gpu计算,把数据转为gpu专用
x_data,y_data=x_data.to(device),y_data.to(device)
gpu版
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 27 17:10:46 2021
@author: Administrator
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
import matplotlib.pyplot as plt
time_list=[]
loss_list=[]
epoch_list=[]
acc_list=[]
batch_size=64
'''
神经网络希望输入的数据比较小,最好[-1,1],最好属于正态分布,对训练有帮助
Compose中[]里都是类,将数据按照[]中的顺序依次处理
transforms.ToTensor():
opencv和pillow(pytorch读取图片时使用)读取图片矩阵为:高*宽*通道数(彩色是高*宽*3,黑白是高*宽),像素值为0~255
transforms.ToTensor()将其变成:通道数*高*宽(彩色是3*高*宽,黑白是1*高*宽),像素值进行归一化:先转为float后除以255.为0~1,方便高效处理数据
transforms.Normalize((0.1307,), (0.3081,)):
n为通道数
(mean,std)=((均值1,均值2,..均值n,(标准差1. 标准差2,..标准差n))
统计了数据的均值和标准差之后的数值
标准化:(数值-mean)/std,使其服从分布N(0,1) 均值为0,标准差为1,不一定是正太分布
'''
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=True,transform=transform,download=True)
test_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=False,transform=transform,download=True)
#num_workers:读取进内存时,是否多线程,windows下,要求须在__name__=='__main__'下调用
train_loader=DataLoader(dataset=train_set,batch_size=batch_size,shuffle=True)
#不需打乱
test_loader=DataLoader(dataset=test_set,batch_size=batch_size,shuffle=False)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
#第一个线性模型:输入的样本特征为784个,输出的特征为512
#self.linear1=torch.nn.Linear(784, 512)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
#self.sigmoid=torch.nn.Sigmoid()
#self.relu=torch.nn.ReLU()
'''
Conv2d:卷积核是2维的,有高宽,通道数由输入通道数决定
torch.nn.Conv2d(in_channel,out_channel,kernel_size,stride=1,padding=0,groups=1,bias=True)
in_channel:输入通道数
out_channel:输出通道数
kernel_size:卷积核(通道数=in_channel,高,宽)
3 : 高=宽=3
(3,3):高=宽=3
stride:int或元组
padding:是否为宽卷积
1:输入数据外圈加一圈0
(batch_size,in_channel,高,宽)->(batch_size,out_channel,高2,宽2) kernel=(kernel_num=out_channel,kernel_channel=in_channel,高',宽')
高-高'+1=高2
宽-宽'+1=宽2
'''
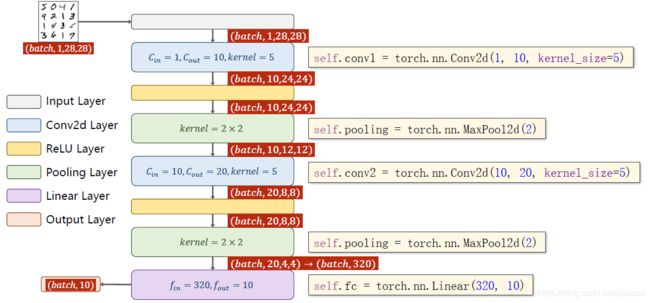
#(batch_size,1,高,宽)->(batch_size,10,高2,宽2) kernel=(10,1,5,5)
self.conv1=torch.nn.Conv2d(1, 10, kernel_size=5)
#(batch_size,10,高,宽)->(batch_size,20,高2,宽2) kernel=(20,10,5,5)
self.conv2=torch.nn.Conv2d(10, 20, kernel_size=5)
#池化层:由于没有参数,定义一个即可(高,宽)->(高/2,宽/2)
self.pooling=torch.nn.MaxPool2d(2)
#全连接层 (batch_size,320)->(batch_size,10)
self.full_conn=torch.nn.Linear(320, 10)
#但是由于没有参数,故只定义一个即可
self.relu=torch.nn.ReLU()
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
batch_size=x_data.size(0)#样本数量
'''
self.conv1(x_data):
(batch_size,1,28,28)->(batch_size,10,24,24) kernel=(10,1,5,5)
24=28-5+1
self.pooling():
(batch_size,10,24,24)->(batch_size,10,12,12)
'''
x_data=self.relu(self.pooling(self.conv1(x_data)))
'''
self.conv2(x_data):
(batch_size,10,12,12)->(batch_size,20,8,8) kernel=(20,10,5,5)
8=12-5+1
self.pooling():
(batch_size,20,8,8)->(batch_size,20,4,4)
'''
x_data=self.relu(self.pooling(self.conv2(x_data)))
#(batch_size,20,4,4)->(batch_size,320) -1表示该位置自动计算大小
x_data=x_data.view(batch_size,-1)
'''
y_pred,还没有使用激活函数
该层320个神经元,全连接要求输入样本是矩阵即2维 (batch_size,320)->(batch_size,10)
'''
return self.full_conn(x_data)
model=Net()
#如果有gpu,使用gpu
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#因为一般的显卡只支持32位浮点数,所以不用double64位
#data = np.loadtxt('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz',delimiter=',',dtype=np.float32)
#x_data=torch.from_numpy(data[:,:-1])
#y_data=torch.from_numpy(data[:,[-1]])
#CrossEntropyLoss=softmax+NLLLoss
#NLLLoss=交叉熵 -yln(softmax(y_pred)) y_pred还没有经过激活函数
criterion=torch.nn.CrossEntropyLoss()
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率,冲量系数
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.5)
#一轮训练
def train(epoch):
running_loss=0.0
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,data in enumerate(train_loader,0):
x_data_mini_batch,y_data_mini_batch=data
#使用gpu计算,把数据转为gpu专用
x_data_mini_batch,y_data_mini_batch=x_data_mini_batch.to(device),y_data_mini_batch.to(device)
#把所有参数的梯度都归零
optimizer.zero_grad()
#前馈 y_pred还没有经过激活函数
y_pred_mini_batch=model(x_data_mini_batch)
#计算损失,CrossEntropyLoss自带激活函数softmax
loss=criterion(y_pred_mini_batch, y_data_mini_batch)
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新,优化参数
optimizer.step()
running_loss+=loss.item()
if i%300 == 299:
#没训练300个batch,输出一次loss
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/300))
time_list.append(len(time_list)+1)
loss_list.append(running_loss/300)
running_loss=0.0
def test():
correct=0
total=0
# 不用计算梯度,因为train时已经训练好了
with torch.no_grad():
for data in test_loader:
x_data,y_data=data
#使用gpu计算,把数据转为gpu专用
x_data,y_data=x_data.to(device),y_data.to(device)
#y_pred是个矩阵n*10【10分类】,每行是一个样本属于各种类的可能性概率,下标是种类
y_pred=model(x_data)
#获取每行的最大值及其下标【该样本属于哪个种类】
_,which_class=torch.max(y_pred.data,dim=1)
total+=y_data.size(0)#batch_size y_data.size=(n,1) n行1列
correct += (which_class == y_data).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
if __name__ == '__main__':
s=time.time()
for epoch in range(10):
train(epoch)
acc=test()
epoch_list.append(epoch)
acc_list.append(acc)
e=time.time()
print(e-s,"秒")
ax1=plt.subplot(121)
plt.plot(time_list, loss_list)
ax1.set_xlabel("300batch_th")
ax1.set_ylabel("loss")
ax2=plt.subplot(122)
plt.plot(epoch_list, acc_list)
ax2.set_xlabel("epoch")
ax2.set_ylabel("acc")
plt.show()
Inception Module:带分支的网络,超参数优化
多分支,每个分支最后得到的(batch_size,channel,h,w)中branc_size,h,w都一样
全连接神经网络是串行的,一层输出就是下一层输入net1->net2->…->net_n
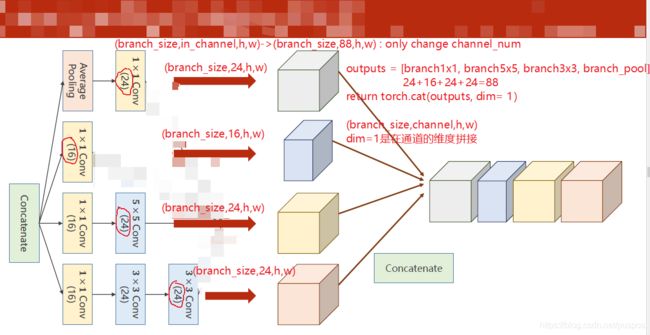
作用
超参数的选择:如二维卷积核的高宽,不知道哪个好,就都用一下,找到最优的,但是要保证数据的高宽一致
eg:一个55个卷积核,同两次33的卷积核
结构代码
'''
(batch_size,in_channel,h,w)->(batch_size,88,h,w),只有通道数可能改变
中间有几条分支
'''
class Inception(torch.nn.Module):
def __init__(self,in_channels):
super(Inception,self).__init__()
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch1x1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch5x5_1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,16,h,w)->(batch_size,24,h,w) h+2*2-5+1=h
self.branch5x5_2=torch.nn.Conv2d(16,24, kernel_size=5,padding=2)
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch3x3_1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,16,h,w)->(batch_size,24,h,w) h+2*1-3+1=h
self.branch3x3_2=torch.nn.Conv2d(16, 24,kernel_size=3,padding=1)
#(batch_size,24,h,w)->(batch_size,24,h,w) h+2*1-3+1=h
self.branch3x3_3=torch.nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool=torch.nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self,x):
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
branch1x1=self.branch1x1(x)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch_pool=F.avg_pool2d(x, kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool(branch_pool)
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
#(batch_size,channel,h,w) -1指的是在通道维度拼接 24+16+24+24=88
return torch.cat(outputs,dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
#第一个线性模型:输入的样本特征为784个,输出的特征为512
#self.linear1=torch.nn.Linear(784, 512)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
#self.sigmoid=torch.nn.Sigmoid()
#self.relu=torch.nn.ReLU()
'''
Conv2d:卷积核是2维的,有高宽,通道数由输入通道数决定
torch.nn.Conv2d(in_channel,out_channel,kernel_size,stride=1,padding=0,groups=1,bias=True)
in_channel:输入通道数
out_channel:输出通道数
kernel_size:卷积核(通道数=in_channel,高,宽)
3 : 高=宽=3
(3,3):高=宽=3
stride:int或元组
padding:是否为宽卷积
1:输入数据外圈加一圈0
(batch_size,in_channel,高,宽)->(batch_size,out_channel,高2,宽2) kernel=(kernel_num=out_channel,kernel_channel=in_channel,高',宽')
高-高'+1=高2
宽-宽'+1=宽2
'''
#(batch_size,1,高,宽)->(batch_size,10,高2,宽2) kernel=(10,1,5,5) 10个卷积核
self.conv1=torch.nn.Conv2d(1, 10, kernel_size=5)
#(batch_size,88,高,宽)->(batch_size,20,高2,宽2) kernel=(20,88,5,5) 20个卷积核
self.conv2=torch.nn.Conv2d(88, 20, kernel_size=5)
#(batch_size,10,h,w)->(batch_size,88,h,w)
self.incept1=Inception(in_channels=10)
#(batch_size,20,h,w)->(batch_size,88,h,w)
self.incept2=Inception(in_channels=20)
#池化层:由于没有参数,定义一个即可(高,宽)->(高/2,宽/2)
self.max_pooling=torch.nn.MaxPool2d(2)
#全连接层 (batch_size,320)->(batch_size,10)
self.full_conn=torch.nn.Linear(1408, 10)
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
batch_size=x_data.size(0)#样本数量
'''
self.conv1(x_data):
(batch_size,1,28,28)->(batch_size,10,24,24) kernel=(10,1,5,5) 10个卷积核
24=28-5+1
self.max_pooling():
(batch_size,10,24,24)->(batch_size,10,12,12)
'''
x_data=F.relu(self.max_pooling(self.conv1(x_data)))
#(batch_size,10,12,12)->(batch_size,88,12,12)
x_data=self.incept1(x_data)
'''
self.conv2(x_data):
(batch_size,88,12,12)->(batch_size,20,8,8) kernel=(20,88,5,5) 20个卷积核
8=12-5+1
self.max_pooling():
(batch_size,20,8,8)->(batch_size,20,4,4)
'''
x_data=F.relu(self.max_pooling(self.conv2(x_data)))
#(batch_size,20,4,4)->(batch_size,88,4,4)
x_data=self.incept2(x_data)
#(batch_size,88,4,4)->(batch_size,1408) -1表示该位置自动计算大小
x_data=x_data.view(batch_size,-1)
'''
y_pred,还没有使用激活函数
该层1408个神经元,全连接要求输入样本是矩阵即2维 (batch_size,320)->(batch_size,10)
'''
return self.full_conn(x_data)
model=Net()
MNIST 多分类 cnn inception
结构

代码
# -*- coding: utf-8 -*-
"""
Created on Tue Jul 27 17:10:46 2021
@author: Administrator
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
import matplotlib.pyplot as plt
time_list=[]
loss_list=[]
epoch_list=[]
acc_list=[]
batch_size=64
'''
神经网络希望输入的数据比较小,最好[-1,1],最好属于正态分布,对训练有帮助
Compose中[]里都是类,将数据按照[]中的顺序依次处理
transforms.ToTensor():
opencv和pillow(pytorch读取图片时使用)读取图片矩阵为:高*宽*通道数(彩色是高*宽*3,黑白是高*宽),像素值为0~255
transforms.ToTensor()将其变成:通道数*高*宽(彩色是3*高*宽,黑白是1*高*宽),像素值进行归一化:先转为float后除以255.为0~1,方便高效处理数据
transforms.Normalize((0.1307,), (0.3081,)):
n为通道数
(mean,std)=((均值1,均值2,..均值n,(标准差1. 标准差2,..标准差n))
统计了数据的均值和标准差之后的数值
标准化:(数值-mean)/std,使其服从分布N(0,1) 均值为0,标准差为1,不一定是正太分布
'''
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=True,transform=transform,download=True)
test_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=False,transform=transform,download=True)
#num_workers:读取进内存时,是否多线程,windows下,要求须在__name__=='__main__'下调用
train_loader=DataLoader(dataset=train_set,batch_size=batch_size,shuffle=True)
#不需打乱
test_loader=DataLoader(dataset=test_set,batch_size=batch_size,shuffle=False)
'''
(batch_size,in_channel,h,w)->(batch_size,88,h,w),只有通道数可能改变
中间有几条分支
'''
class Inception(torch.nn.Module):
def __init__(self,in_channels):
super(Inception,self).__init__()
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch1x1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch5x5_1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,16,h,w)->(batch_size,24,h,w) h+2*2-5+1=h
self.branch5x5_2=torch.nn.Conv2d(16,24, kernel_size=5,padding=2)
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
self.branch3x3_1=torch.nn.Conv2d(in_channels,16, kernel_size=1)
#(batch_size,16,h,w)->(batch_size,24,h,w) h+2*1-3+1=h
self.branch3x3_2=torch.nn.Conv2d(16, 24,kernel_size=3,padding=1)
#(batch_size,24,h,w)->(batch_size,24,h,w) h+2*1-3+1=h
self.branch3x3_3=torch.nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool=torch.nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self,x):
#(batch_size,in_channel,h,w)->(batch_size,16,h,w)
branch1x1=self.branch1x1(x)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
#(batch_size,in_channel,h,w)->(batch_size,24,h,w)
branch_pool=F.avg_pool2d(x, kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool(branch_pool)
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
#(batch_size,channel,h,w) -1指的是在通道维度拼接 24+16+24+24=88
return torch.cat(outputs,dim=1)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
#第一个线性模型:输入的样本特征为784个,输出的特征为512
#self.linear1=torch.nn.Linear(784, 512)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
#self.sigmoid=torch.nn.Sigmoid()
#self.relu=torch.nn.ReLU()
'''
Conv2d:卷积核是2维的,有高宽,通道数由输入通道数决定
torch.nn.Conv2d(in_channel,out_channel,kernel_size,stride=1,padding=0,groups=1,bias=True)
in_channel:输入通道数
out_channel:输出通道数
kernel_size:卷积核(通道数=in_channel,高,宽)
3 : 高=宽=3
(3,3):高=宽=3
stride:int或元组
padding:是否为宽卷积
1:输入数据外圈加一圈0
(batch_size,in_channel,高,宽)->(batch_size,out_channel,高2,宽2) kernel=(kernel_num=out_channel,kernel_channel=in_channel,高',宽')
高-高'+1=高2
宽-宽'+1=宽2
'''
#(batch_size,1,高,宽)->(batch_size,10,高2,宽2) kernel=(10,1,5,5) 10个卷积核
self.conv1=torch.nn.Conv2d(1, 10, kernel_size=5)
#(batch_size,88,高,宽)->(batch_size,20,高2,宽2) kernel=(20,88,5,5) 20个卷积核
self.conv2=torch.nn.Conv2d(88, 20, kernel_size=5)
#(batch_size,10,h,w)->(batch_size,88,h,w)
self.incept1=Inception(in_channels=10)
#(batch_size,20,h,w)->(batch_size,88,h,w)
self.incept2=Inception(in_channels=20)
#池化层:由于没有参数,定义一个即可(高,宽)->(高/2,宽/2)
self.max_pooling=torch.nn.MaxPool2d(2)
#全连接层 (batch_size,320)->(batch_size,10)
self.full_conn=torch.nn.Linear(1408, 10)
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
batch_size=x_data.size(0)#样本数量
'''
self.conv1(x_data):
(batch_size,1,28,28)->(batch_size,10,24,24) kernel=(10,1,5,5) 10个卷积核
24=28-5+1
self.max_pooling():
(batch_size,10,24,24)->(batch_size,10,12,12)
'''
x_data=F.relu(self.max_pooling(self.conv1(x_data)))
#(batch_size,10,12,12)->(batch_size,88,12,12)
x_data=self.incept1(x_data)
'''
self.conv2(x_data):
(batch_size,88,12,12)->(batch_size,20,8,8) kernel=(20,88,5,5) 20个卷积核
8=12-5+1
self.max_pooling():
(batch_size,20,8,8)->(batch_size,20,4,4)
'''
x_data=F.relu(self.max_pooling(self.conv2(x_data)))
#(batch_size,20,4,4)->(batch_size,88,4,4)
x_data=self.incept2(x_data)
#(batch_size,88,4,4)->(batch_size,1408) -1表示该位置自动计算大小
x_data=x_data.view(batch_size,-1)
'''
y_pred,还没有使用激活函数
该层1408个神经元,全连接要求输入样本是矩阵即2维 (batch_size,320)->(batch_size,10)
'''
return self.full_conn(x_data)
model=Net()
#如果有gpu,使用gpu
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#因为一般的显卡只支持32位浮点数,所以不用double64位
#data = np.loadtxt('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz',delimiter=',',dtype=np.float32)
#x_data=torch.from_numpy(data[:,:-1])
#y_data=torch.from_numpy(data[:,[-1]])
#CrossEntropyLoss=softmax+NLLLoss
#NLLLoss=交叉熵 -yln(softmax(y_pred)) y_pred还没有经过激活函数
criterion=torch.nn.CrossEntropyLoss()
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率,冲量系数
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.5)
#一轮训练
def train(epoch):
running_loss=0.0
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,data in enumerate(train_loader,0):
x_data_mini_batch,y_data_mini_batch=data
#使用gpu计算,把数据转为gpu专用
x_data_mini_batch,y_data_mini_batch=x_data_mini_batch.to(device),y_data_mini_batch.to(device)
#把所有参数的梯度都归零
optimizer.zero_grad()
#前馈 y_pred还没有经过激活函数
y_pred_mini_batch=model(x_data_mini_batch)
#计算损失,CrossEntropyLoss自带激活函数softmax
loss=criterion(y_pred_mini_batch, y_data_mini_batch)
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新,优化参数
optimizer.step()
running_loss+=loss.item()
if i%300 == 299:
#没训练300个batch,输出一次loss
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/300))
time_list.append(len(time_list)+1)
loss_list.append(running_loss/300)
running_loss=0.0
def test():
correct=0
total=0
# 不用计算梯度,因为train时已经训练好了
with torch.no_grad():
for data in test_loader:
x_data,y_data=data
#使用gpu计算,把数据转为gpu专用
x_data,y_data=x_data.to(device),y_data.to(device)
#y_pred是个矩阵n*10【10分类】,每行是一个样本属于各种类的可能性概率,下标是种类
y_pred=model(x_data)
#获取每行的最大值及其下标【该样本属于哪个种类】
_,which_class=torch.max(y_pred.data,dim=1)
total+=y_data.size(0)#batch_size y_data.size=(n,1) n行1列
correct += (which_class == y_data).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
if __name__ == '__main__':
s=time.time()
for epoch in range(10):
train(epoch)
acc=test()
epoch_list.append(epoch)
acc_list.append(acc)
e=time.time()
print(e-s,"秒")
ax1=plt.subplot(121)
plt.plot(time_list, loss_list)
ax1.set_xlabel("300batch_th")
ax1.set_ylabel("loss")
ax2=plt.subplot(122)
plt.plot(epoch_list, acc_list)
ax2.set_xlabel("epoch")
ax2.set_ylabel("acc")
plt.show()
ResidualBlock resnet 残差网络:解决神经网络的梯度消失
梯度消失问题
当网络较深时,效果会更差,因为如果梯度较小,经过多次相乘后得到的梯度趋于0,即没有学习到东西
resnet 结构
f(x)和x是在(batch_size,channel,h,w)四个维度都是一样的
f(x)+x时,直接同位置元素相加

resnet怎么解决梯度消失问题
正 常 结 构 : x − > f ( x ) − > σ ( f ( x ) ) = y 正 常 结 构 的 梯 度 : 当 ∂ f ∂ x 很 小 时 , ∂ L o s s ∂ x 很 小 , 连 乘 导 致 趋 于 0 ∂ L o s s ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ σ ⋅ ∂ σ ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ σ ⋅ ∂ σ ∂ f ⋅ ∂ f ∂ x r e s n e t 结 构 : x − > f ( x ) − > f ( x ) + x − > σ ( f ( x ) + x ) − > y r e s n e t 结 构 的 梯 度 : 当 ∂ f ∂ x 很 小 时 , ∂ L o s s ∂ x 趋 于 1 , 连 乘 导 致 趋 于 1 ∂ L o s s ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ σ ⋅ ∂ σ ∂ x = ∂ L o s s ∂ y ⋅ ∂ y ∂ σ ⋅ ∂ σ ∂ f ⋅ ( ∂ f ∂ x + 1 ) 正常结构:x->f(x)->\sigma(f(x))=y\\ 正常结构的梯度:当\frac{\partial f}{\partial x}很小时,\frac{\partial Loss}{\partial x}很小,连乘导致趋于0\\ \frac{\partial Loss}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial f} \cdot \frac{\partial f}{\partial x}\\ resnet结构:x->f(x)->f(x)+x->\sigma(f(x)+x)->y\\ resnet结构的梯度:当\frac{\partial f}{\partial x}很小时,\frac{\partial Loss}{\partial x}趋于1,连乘导致趋于1\\ \frac{\partial Loss}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial x}=\frac{\partial Loss}{\partial y} \cdot \frac{\partial y}{\partial \sigma} \cdot \frac{\partial \sigma}{\partial f} \cdot (\frac{\partial f}{\partial x}+1)\\ 正常结构:x−>f(x)−>σ(f(x))=y正常结构的梯度:当∂x∂f很小时,∂x∂Loss很小,连乘导致趋于0∂x∂Loss=∂y∂Loss⋅∂x∂y=∂y∂Loss⋅∂σ∂y⋅∂x∂σ=∂y∂Loss⋅∂σ∂y⋅∂f∂σ⋅∂x∂fresnet结构:x−>f(x)−>f(x)+x−>σ(f(x)+x)−>yresnet结构的梯度:当∂x∂f很小时,∂x∂Loss趋于1,连乘导致趋于1∂x∂Loss=∂y∂Loss⋅∂x∂y=∂y∂Loss⋅∂σ∂y⋅∂x∂σ=∂y∂Loss⋅∂σ∂y⋅∂f∂σ⋅(∂x∂f+1)
resblock 代码
'''
残差网络:解决nn中的梯度消失问题
正常:y=relu(f(x))
resnet:y=relu(f(x)+x)
'''
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels=channels
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
self.conv1=torch.nn.Conv2d(channels, channels, kernel_size=3,padding=1)
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
self.conv2=torch.nn.Conv2d(channels, channels, kernel_size=3,padding=1)
def forward(self,x):
'''
self.conv1(x):
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
'''
y=F.relu(self.conv1(x))
'''
self.conv2(x):
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
'''
y=self.conv2(y)
#x和y在(batch_size,channel,h,w)上四个维度是一样的,然后同位置相加
return F.relu(x+y)
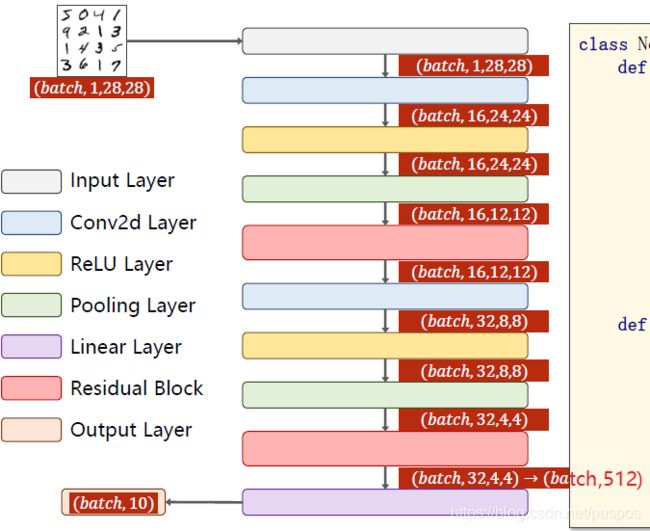
MNIST 卷积+resBlock 多分类
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 30 10:49:06 2021
@author: Administrator
"""
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
import time
import matplotlib.pyplot as plt
time_list=[]
loss_list=[]
epoch_list=[]
acc_list=[]
batch_size=64
'''
神经网络希望输入的数据比较小,最好[-1,1],最好属于正态分布,对训练有帮助
Compose中[]里都是类,将数据按照[]中的顺序依次处理
transforms.ToTensor():
opencv和pillow(pytorch读取图片时使用)读取图片矩阵为:高*宽*通道数(彩色是高*宽*3,黑白是高*宽),像素值为0~255
transforms.ToTensor()将PIL.Image对象/np.array(PIL.Image对象)变成:通道数*高*宽(彩色是3*高*宽,黑白是1*高*宽),像素值进行归一化:先转为float后除以255.为0~1,方便高效处理数据
transforms.Normalize((0.1307,), (0.3081,)):
n为通道数
(mean,std)=((均值1,均值2,..均值n,(标准差1. 标准差2,..标准差n))
统计了数据的均值和标准差之后的数值
标准化:(数值-mean)/std,使其服从分布N(0,1) 均值为0,标准差为1,不一定是正太分布
'''
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
#tv.dataset中图片是用PILLOW(PIL)加载的,数据为0~255,把他们转成张量时,数据会压缩成[0,1]或[-1,1]
train_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=True,transform=transform,download=True)
test_set = datasets.MNIST(root='D:/nn/dataset/mnist/', train=False,transform=transform,download=True)
#num_workers:读取进内存时,是否多线程,windows下,要求须在__name__=='__main__'下调用
train_loader=DataLoader(dataset=train_set,batch_size=batch_size,shuffle=True)
#不需打乱
test_loader=DataLoader(dataset=test_set,batch_size=batch_size,shuffle=False)
'''
残差网络:解决nn中的梯度消失问题
正常:y=relu(f(x))
resnet:y=relu(f(x)+x)
'''
class ResidualBlock(torch.nn.Module):
def __init__(self,channels):
super(ResidualBlock,self).__init__()
self.channels=channels
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
self.conv1=torch.nn.Conv2d(channels, channels, kernel_size=3,padding=1)
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
self.conv2=torch.nn.Conv2d(channels, channels, kernel_size=3,padding=1)
def forward(self,x):
'''
self.conv1(x):
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
'''
y=F.relu(self.conv1(x))
'''
self.conv2(x):
#(batch_size,channel,h,w)->(batch_size,channel,h,w) h+2*1-3+1=h
'''
y=self.conv2(y)
#x和y在(batch_size,channel,h,w)上四个维度是一样的,然后同位置相加
return F.relu(x+y)
class Net(torch.nn.Module):
def __init__(self):
super(Net,self).__init__()
'''
w和b的维度,自然就定了:
y_pred=wx+b
y_(n*6)=x_(n*8)*w+b
w=8*6
b=1*6最后广播机制,复制成n*6
'''
#第一个线性模型:输入的样本特征为784个,输出的特征为512
#self.linear1=torch.nn.Linear(784, 512)
#torch.nn.Sigmoid是个Module,也是继承torch.nn.Module,但是由于没有参数,故只定义一个即可,作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
#self.sigmoid=torch.nn.Sigmoid()
#self.relu=torch.nn.ReLU()
'''
Conv2d:卷积核是2维的,有高宽,通道数由输入通道数决定
torch.nn.Conv2d(in_channel,out_channel,kernel_size,stride=1,padding=0,groups=1,bias=True)
in_channel:输入通道数
out_channel:输出通道数
kernel_size:卷积核(通道数=in_channel,高,宽)
3 : 高=宽=3
(3,3):高=宽=3
stride:int或元组
padding:是否为宽卷积
1:输入数据外圈加一圈0
(batch_size,in_channel,高,宽)->(batch_size,out_channel,高2,宽2) kernel=(kernel_num=out_channel,kernel_channel=in_channel,高',宽')
高-高'+1=高2
宽-宽'+1=宽2
'''
#(batch_size,1,高,宽)->(batch_size,16,高,宽) kernel=(16,1,5,5) 16个卷积核
self.conv1=torch.nn.Conv2d(1, 16, kernel_size=5)
#(batch_size,32,高,宽)->(batch_size,16,高,宽) kernel=(32,16,5,5) 32个卷积核
self.conv2=torch.nn.Conv2d(16, 32, kernel_size=5)
#(batch_size,16,h,w)->(batch_size,16,h,w)
self.resblock1=ResidualBlock(16)
#(batch_size,32,h,w)->(batch_size,32,h,w)
self.resblock2=ResidualBlock(32)
#池化层:由于没有参数,定义一个即可(高,宽)->(高/2,宽/2)
self.max_pooling=torch.nn.MaxPool2d(2)
#全连接层 (batch_size,320)->(batch_size,10)
self.full_conn=torch.nn.Linear(512, 10)
def forward(self,x_data):
'''
只用一个x_data变量,虽然是有很多层,但是为了防止写错和节省内存
激活函数作为一个层,区分层标志为非线性激活函数,卷积层也是线性的
'''
batch_size=x_data.size(0)#样本数量
'''
self.conv1(x_data):
(batch_size,1,28,28)->(batch_size,16,24,24) kernel=(10,1,5,5) 10个卷积核
24=28-5+1
self.max_pooling():
(batch_size,16,24,24)->(batch_size,10,12,12)
'''
x_data=self.max_pooling(F.relu(self.conv1(x_data)))
'''
(batch_size,16,12,12) ->(batch_size,16,12,12)
'''
x_data=self.resblock1(x_data)
'''
self.conv1(x_data):
(batch_size,16,12,12)->(batch_size,32,8,8) (32,16,5,5) 32个卷积核
12-5+1=8
self.max_pooling():
(batch_size,32,8,8)->(batch_size,32,4,4)
'''
x_data=self.max_pooling(F.relu(self.conv2(x_data)))
'''
(batch_size,32,4,4) ->(batch_size,32,4,4)
'''
x_data=self.resblock2(x_data)
#(batch_size,32,4,4)->(batch_size,512) -1表示该位置自动计算大小
x_data=x_data.view(batch_size,-1)
'''
y_pred,还没有使用激活函数
该层512个神经元,全连接要求输入样本是矩阵即2维 (batch_size,512)->(batch_size,10)
'''
return self.full_conn(x_data)
model=Net()
#如果有gpu,使用gpu
device=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
#因为一般的显卡只支持32位浮点数,所以不用double64位
#data = np.loadtxt('D:\BaiduNetdiskDownload\PyTorch深度学习实践\diabetes.csv.gz',delimiter=',',dtype=np.float32)
#x_data=torch.from_numpy(data[:,:-1])
#y_data=torch.from_numpy(data[:,[-1]])
#CrossEntropyLoss=softmax+NLLLoss
#NLLLoss=交叉熵 -yln(softmax(y_pred)) y_pred还没有经过激活函数
criterion=torch.nn.CrossEntropyLoss()
#优化器 对哪些参数进行优化,并自动对参数进行初始化,指定学习率,冲量系数
#SGD随机梯度下降,但是不是真正的随机梯度下降,要看传的数据是单个还是批量,
#x_data中有3个数据,则是批量梯度,mini-batch
optimizer=torch.optim.SGD(model.parameters(),lr=0.1,momentum=0.5)
#一轮训练
def train(epoch):
running_loss=0.0
'''
train_loader先把数据打乱(shuffle),再分组,把每个组跑一遍,enumerate(,start_index)
x_data_mini_batch,y_data_mini_batch:Tensor
'''
for i,data in enumerate(train_loader,0):
x_data_mini_batch,y_data_mini_batch=data
#使用gpu计算,把数据转为gpu专用
x_data_mini_batch,y_data_mini_batch=x_data_mini_batch.to(device),y_data_mini_batch.to(device)
#把所有参数的梯度都归零
optimizer.zero_grad()
#前馈 y_pred还没有经过激活函数
y_pred_mini_batch=model(x_data_mini_batch)
#计算损失,CrossEntropyLoss自带激活函数softmax
loss=criterion(y_pred_mini_batch, y_data_mini_batch)
#进行反向传播,计算loss对参数的梯度
loss.backward()
#更新,优化参数
optimizer.step()
running_loss+=loss.item()
if i%300 == 299:
#没训练300个batch,输出一次loss
print('[%d, %5d] loss: %.3f' % (epoch+1, i+1, running_loss/300))
time_list.append(len(time_list)+1)
loss_list.append(running_loss/300)
running_loss=0.0
def test():
correct=0
total=0
# 不用计算梯度,因为train时已经训练好了
with torch.no_grad():
for data in test_loader:
x_data,y_data=data
#使用gpu计算,把数据转为gpu专用
x_data,y_data=x_data.to(device),y_data.to(device)
#y_pred是个矩阵n*10【10分类】,每行是一个样本属于各种类的可能性概率,下标是种类
y_pred=model(x_data)
#获取每行的最大值及其下标【该样本属于哪个种类】
_,which_class=torch.max(y_pred.data,dim=1)
total+=y_data.size(0)#batch_size y_data.size=(n,1) n行1列
correct += (which_class == y_data).sum().item() # 张量之间的比较运算
print('accuracy on test set: %d %% ' % (100*correct/total))
return correct/total
if __name__ == '__main__':
s=time.time()
for epoch in range(10):
train(epoch)
acc=test()
epoch_list.append(epoch)
acc_list.append(acc)
e=time.time()
print(e-s,"秒")
ax1=plt.subplot(121)
plt.plot(time_list, loss_list)
ax1.set_xlabel("300batch_th")
ax1.set_ylabel("loss")
ax2=plt.subplot(122)
plt.plot(epoch_list, acc_list)
ax2.set_xlabel("epoch")
ax2.set_ylabel("acc")
plt.show()