PyG学习 - Dataset, DataLoader, Tranforms
目录
自定义Dataset
DataLoader
Transforms
复制自:图神经网络 PyTorch Geometric 入门教程 - 掘金
PyG 的 Dataset继承自torch.utils.data.Dataset,自带了很多图数据集;
通过以下代码就可以加载数据集TUDataset,root参数设置数据下载的位置。通过索引可以访问每一个数据:
from torch_geometric.datasets import TUDataset
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES')
data = dataset[0] 在一个图中,由edge_index和edge_attr可以决定所有节点的邻接矩阵。PyG 通过创建稀疏的对角邻接矩阵,并在节点维度中连接特征矩阵和 label 矩阵,实现了在 mini-batch 的并行化。PyG 允许在一个 mini-batch 中的每个Data (图) 使用不同数量的节点和边.
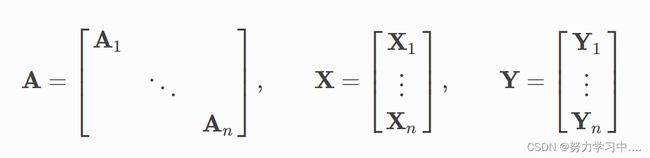
自定义Dataset
1 尽管 PyG 已经包含许多有用的数据集,我们也可以通过继承torch_geometric.data. Dataset类定义自己的数据集;
2 提供 2 种不同的Dataset类:
InMemoryDataset:使用这个Dataset会一次性把数据全部加载到内存中;
Dataset: 使用这个Dataset每次加载一个数据到内存中,比较常用;
我们需要在自定义的Dataset的初始化方法中传入数据存放的路径,然后 PyG 会在这个路径下再划分 2 个文件夹:
raw_dir: 存放原始数据的路径,一般是 csv、mat 等格式;processed_dir: 存放处理后的数据,一般是 pt 格式 ( 由我们重写process()方法实现);
3 这两个文件夹在 PyG 中的实际意义和处理逻辑:
torch_geometric.data.Dataset继承自torch.utils.data.Dataset,在初始化方法 __init__()中,会调用_download()方法和_process()方法
def __init__(self, root=None, transform=None, pre_transform=None,
pre_filter=None):
super(Dataset, self).__init__()
if isinstance(root, str):
root = osp.expanduser(osp.normpath(root))
self.root = root
self.transform = transform
self.pre_transform = pre_transform
self.pre_filter = pre_filter
self.__indices__ = None
# 执行 self._download() 方法
if 'download' in self.__class__.__dict__.keys():
self._download()
# 执行 self._process() 方法
if 'process' in self.__class__.__dict__.keys():
self._process() _download()方法如下,首先检查self.raw_paths列表中的文件是否存在;如果存在,则返回;如果不存在,则调用self.download()方法下载文件
def _download(self):
if files_exist(self.raw_paths): # pragma: no cover
return
makedirs(self.raw_dir)
self.download() _process()方法如下,首先在self.processed_dir中有pre_transform,那么判断这个pre_transform和传进来的pre_transform是否一致,如果不一致,那么警告提示用户先删除self.processed_dir文件夹。pre_filter同理;
然后检查self.processed_paths列表中的文件是否存在;如果存在,则返回;如果不存在,则调用self.process()生成文件;
def _process(self):
f = osp.join(self.processed_dir, 'pre_transform.pt')
if osp.exists(f) and torch.load(f) != __repr__(self.pre_transform):
warnings.warn(
'The `pre_transform` argument differs from the one used in '
'the pre-processed version of this dataset. If you really '
'want to make use of another pre-processing technique, make '
'sure to delete `{}` first.'.format(self.processed_dir))
f = osp.join(self.processed_dir, 'pre_filter.pt')
if osp.exists(f) and torch.load(f) != __repr__(self.pre_filter):
warnings.warn(
'The `pre_filter` argument differs from the one used in the '
'pre-processed version of this dataset. If you really want to '
'make use of another pre-fitering technique, make sure to '
'delete `{}` first.'.format(self.processed_dir))
if files_exist(self.processed_paths): # pragma: no cover
return
print('Processing...')
makedirs(self.processed_dir)
self.process()
path = osp.join(self.processed_dir, 'pre_transform.pt')
torch.save(__repr__(self.pre_transform), path)
path = osp.join(self.processed_dir, 'pre_filter.pt')
torch.save(__repr__(self.pre_filter), path)
print('Done!')4 一般来说不用实现downloand()方法。
如果你直接把处理好的 pt 文件放在了self.processed_dir中,那么也不用实现process()方法;
在 Pytorch 的dataset中,我们需要实现__getitem__()方法,根据index返回样本和标签;
在torch_geometric.data.Dataset中,重写了__getitem__()方法,其中调用了get()方法获取数据;
def __getitem__(self, idx):
if isinstance(idx, int):
data = self.get(self.indices()[idx])
data = data if self.transform is None else self.transform(data)
return data
else:
return self.index_select(idx) 需要实现的是get()方法,根据index返回torch_geometric.data.Data类型的数据;
5 process()方法存在的意义是原始的格式可能是 csv 或者 mat,在process()函数里可以转化为 pt 格式的文件;
这样在get()方法中就可以直接使用torch.load()函数读取 pt 格式的文件,返回的是torch_geometric.data.Data类型的数据,而不用在get()方法做数据转换操作 (把其他格式的数据转换为 torch_geometric.data.Data类型的数据);
当然我们也可以提前把数据转换为 torch_geometric.data.Data类型,使用 pt 格式保存在self.processed_dir中
DataLoader
通过torch_geometric.data.DataLoader可以方便地使用 mini-batch;
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for batch in loader:
# 对每一个 mini-batch 进行操作
... torch_geometric.data.Batch继承自torch_geometric.data.Data,并且多了一个属性:batch;
batch是一个列向量,它将每个元素映射到每个 mini-batch 中的相应图:
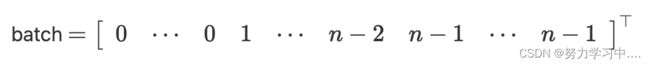
可以使用它分别为每个图的节点维度计算平均的节点特征
from torch_scatter import scatter_mean
from torch_geometric.datasets import TUDataset
from torch_geometric.data import DataLoader
dataset = TUDataset(root='/tmp/ENZYMES', name='ENZYMES', use_node_attr=True)
loader = DataLoader(dataset, batch_size=32, shuffle=True)
for data in loader:
data
#data: Batch(batch=[1082], edge_index=[2, 4066], x=[1082, 21], y=[32])
x = scatter_mean(data.x, data.batch, dim=0)
# x.size(): torch.Size([32, 21])Transforms
transforms在计算机视觉领域是一种很常见的数据增强,PyG 有自己的transforms,输入是Data类型,输出也是Data类型;
可以使用torch_geometric.transforms.Compose封装一系列的transforms;
以 ShapeNet 数据集 (包含 17000 个 point clouds,每个 point 分类为 16 个类别的其中一个) 为例,我们可以使用transforms从 point clouds 生成最近邻图:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6))
# dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])还可以通过transform在一定范围内随机平移每个点,增加坐标上的扰动,做数据增强:
import torch_geometric.transforms as T
from torch_geometric.datasets import ShapeNet
dataset = ShapeNet(root='/tmp/ShapeNet', categories=['Airplane'],
pre_transform=T.KNNGraph(k=6),
transform=T.RandomTranslate(0.01))
# dataset[0]: Data(edge_index=[2, 15108], pos=[2518, 3], y=[2518])