Tensorflow新版Seq2Seq接口使用
简介
Tensorflow 1.0.0 版本以后,开发了新的seq2seq接口,弃用了原来的接口。
旧的seq2seq接口也就是tf.contrib.legacy_seq2seq下的那部分,新的接口在tf.contrib.seq2seq下。
新seq2seq接口与旧的相比最主要的区别是它是动态展开的,而旧的是静态展开的。
静态展开(static unrolling) :指的是定义模型创建graph的时候,序列的长度是固定的,之后传入的所有序列都得是定义时指定的长度。这样所有的句子都要padding到指定的长度,很浪费存储空间,计算效率也不高。但想处理变长序列,也是有办法的,需要预先指定一系列的buckets,如
[(5,10), (10, 15), (15, 20)]然后序列根据长度分配到其中某个bucket,再padding成bucket指定的长度,创建graph的时候其实是根据buckets创建多个sub-graph。
动态展开(dynamic unrolling):使用控制流ops处理序列,可以不需要事先指定好序列长度。
但是不管静态还是动态,输入的每一个batch内的序列长度都要一样。
新的接口中的类别与方法如下
_allowed_symbols = [
"sequence_loss",
"Decoder",
"dynamic_decode",
"BasicDecoder",
"BasicDecoderOutput",
"BeamSearchDecoder",
"BeamSearchDecoderOutput",
"BeamSearchDecoderState",
"Helper",
"CustomHelper",
"FinalBeamSearchDecoderOutput",
"gather_tree",
"GreedyEmbeddingHelper",
"SampleEmbeddingHelper",
"ScheduledEmbeddingTrainingHelper",
"ScheduledOutputTrainingHelper",
"TrainingHelper",
"BahdanauAttention",
"LuongAttention",
"hardmax",
"AttentionWrapperState",
"AttentionWrapper",
"AttentionMechanism",
"tile_batch"]熟悉这些接口最好的方法就是阅读API文档,然后使用它们。
这一篇先总结一下使用其中的几项,来实现一个基本的Encoder-Decoder Seq2Seq模型。
基本Encoder-Decoder模型
Sequence to Sequence Learning with Neural Networks [1]这篇文章提出了一个最基本的Encoder-Decoder模型,没有Attention机制。模型的框架如下图所示:
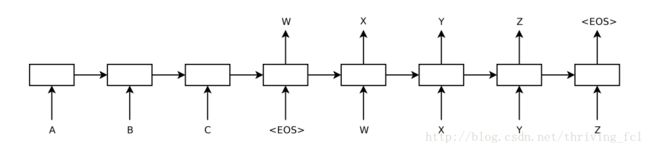
输入的序列为['A', 'B', 'C', ',输出序列为['W', 'X', 'Y', 'Z', '
这里Encoder对输入序列进行编码,将最后一时刻输出的hidden state(下文的final state)作为输入序列的编码向量。
Decoder将终止符
结构很简单,只要实现Encoder与Decoder再将他们串起来即可。
Encoder 实现
[1]中的Encoder使用的是一个4层的单向LSTM,这一部分使用RNN的接口即可,还不需要用到Seq2Seq中的接口。第一张图中的模型框架虽然阐述清楚了Encoder-Decoder这种架构,但是具体实现上,不是直接将序列['A', 'B', 'C', '输入到Encoder中,Encoder的完整架构如下图所示:
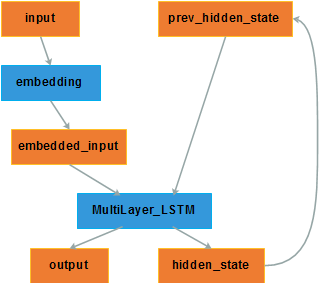
框架说明:
input:不是原始的序列,而是将序列中的每个元素都转换为字典中对应的id。不管是train还是inference阶段,为了效率都是一次输入一个mini-batch,所以需要为input定义一个int型rank=2的placeholder。
embedding:定义为trainable=True的变量,这样即使使用pre-trained的词向量也可以在训练模型的过程中调优。
MultiLayer_LSTM:接收的输入是序列中每个元素对应的词向量。
其中,tf.nn.dynamic_rnn方法接收encoder实例以及embbeded向量之后,就会输出包含每个时刻hidden state的outputs以及final state,如果初始状态为0的话,不需要显式的声明zero_state再将其作为参数传入,只需要指定state的dtype,这个方法中会将初始状态自动初始化为0向量,从tensorflow中截取的源码如下:
if initial_state is not None:
state = initial_state
else:
if not dtype:
raise ValueError("If there is no initial_state, you must give a dtype.")
state = cell.zero_state(batch_size, dtype)Decoder 实现
Decoder部分的实现开始需要用到seq2seq模块了。同样的,将第一张总体框架图的Decoder部分展开的架构图如下所示
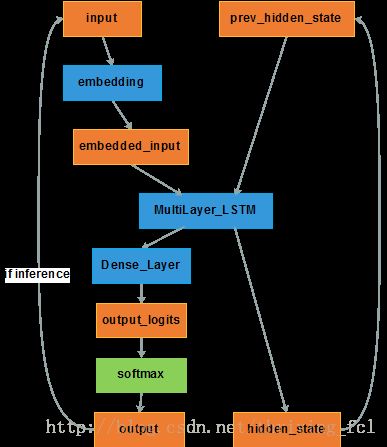
框架说明:
input:与encoder的一样,也是序列元素对应的id。
embedding:视情况而定需不需要与encoder的embedding不同,比如在翻译中,源语言与目标语言的词向量空间就不一样,但是像文本摘要这种都是基于一种语言的,encoder与decoder的embedding matrix是可以共用的。
Dense_Layer:与encoder仅输出hidden state不同,decoder需要输出每个时刻词典中各token的概率,因此还需要一个dense layer将hidden state向量转换为维度等于vocabulary_size的向量,然后再将dense layer输出的logits经过softmax层得到最终的token概率。
Decoder的定义需要区分inference阶段还是train阶段。
inference阶段,decoder的输出是未知的,对于生成['W', 'X', 'Y', 'Z', '序列,是在decoder输出token 'W'之后,再将'W'作为输入,结合此时的hidden state,推断出下一个token 'X',以此类推直到输出为
而在train阶段,decoder应该输出的序列是已知的,不管最终output的结果是什么,都将已知序列中的token依次输入。train的阶段如果也将输出的结果再作为输入,一旦前面的一步错了,都会放大误差,导致训练过程更不稳定。
接口说明
decoder将用到seq2seq中的TrainingHelper, GreedyEmbeddingHelper, BasicDecoder三个类,以及dynamic_decode方法,还将用到tensorflow.python.layers.core下的Dense类。
BasicDecoder
实现decoder最先关注到的就是BasicDecoder,它的构造函数与参数的定义如下:
__init__( cell, helper, initial_state, output_layer=None )
- cell: An RNNCell instance.
- helper: A Helper instance.
- initial_state: A (possibly nested tuple of…) tensors and TensorArrays. The initial state of the RNNCell.
- output_layer: (Optional) An instance of tf.layers.Layer, i.e., tf.layers.Dense. Optional layer to apply to the RNN output prior to storing the result or sampling.
cell:在这里就是一个多层LSTM的实例,与定义encoder时无异
helper:这里只是简单说明是一个Helper实例,第一次看文档的时候肯定还不知道这个Helper是什么,不用着急,看到具体的Helper实例就明白了
initial_state:encoder的final state,类型要一致,也就是说如果encoder的final state是tuple类型(如LSTM的包含了cell state与hidden state),那么这里的输入也必须是tuple。直接将encoder的final_state作为这个参数输入即可
output_layer:对应的就是框架图中的Dense_Layer,只不过文档里写tf.layers.Dense,但是tf.layers下只有dense方法,Dense的实例还需要from tensorflow.python.layers.core import Dense。
BasicDecoder的作用就是定义一个封装了decoder应该有的功能的实例,根据Helper实例的不同,这个decoder可以实现不同的功能,比如在train的阶段,不把输出重新作为输入,而在inference阶段,将输出接到输入。
TrainingHelper
构造函数与参数如下:
__init__( inputs, sequence_length, time_major=False, name=None )
- inputs: A (structure of) input tensors.
- sequence_length: An int32 vector tensor.
- time_major: Python bool. Whether the tensors in inputs are time major. If False (default), they are assumed to be batch major.
- name: Name scope for any created operations.
inputs:对应Decoder框架图中的embedded_input,time_major=False的时候,inputs的shape就是[batch_size, sequence_length, embedding_size] ,time_major=True时,inputs的shape为[sequence_length, batch_size, embedding_size]
sequence_length:这个文档写的太简略了,不过在源码中可以看出指的是当前batch中每个序列的长度(self._batch_size = array_ops.size(sequence_length))。
time_major:决定inputs Tensor前两个dim表示的含义
name:如文档所述
TrainingHelper用于train阶段,next_inputs方法一样也接收outputs与sample_ids,但是只是从初始化时的inputs返回下一时刻的输入。
GreedyEmbeddingHelper
__init__( embedding, start_tokens, end_token )
- embedding: A callable that takes a vector tensor of ids (argmax ids), or the params argument for embedding_lookup. The returned tensor will be passed to the decoder input.
- start_tokens: int32 vector shaped [batch_size], the start tokens.
- end_token: int32 scalar, the token that marks end of decoding.A helper for use during inference.
Uses the argmax of the output (treated as logits) and passes the result through an embedding layer to get the next input.
官方文档已经说明,这是用于inference阶段的helper,将output输出后的logits使用argmax获得id再经过embedding layer来获取下一时刻的输入。
embedding:params argument for embedding_lookup,也就是 定义的embedding 变量传入即可。
start_tokens: batch中每个序列起始输入的token_id
end_token:序列终止的token_id
dynamic_decode
dynamic_decode( decoder, output_time_major=False, impute_finished=False, maximum_iterations=None, parallel_iterations=32, swap_memory=False, scope=None)
这个方法很直观,将定义好的decoder实例传入,其他几个参数文档介绍的很清楚。很值得学习的是其中如何使用control flow ops来实现dynamic的过程。
代码
综合使用上述接口实现基本Encoder-Decoder模型的代码如下
#-*- coding:utf-8 -*-
import tensorflow as tf
from tensorflow.contrib.seq2seq import *
from tensorflow.python.layers.core import Dense
class Seq2SeqModel(object):
def __init__(self, rnn_size, layer_size, encoder_vocab_size,
decoder_vocab_size, embedding_dim, grad_clip, is_inference=False):
# define inputs
self.input_x = tf.placeholder(tf.int32, shape=[None, None], name='input_ids')
# define embedding layer
with tf.variable_scope('embedding'):
encoder_embedding = tf.Variable(tf.truncated_normal(shape=[encoder_vocab_size, embedding_dim], stddev=0.1),
name='encoder_embedding')
decoder_embedding = tf.Variable(tf.truncated_normal(shape=[decoder_vocab_size, embedding_dim], stddev=0.1),
name='decoder_embedding')
# define encoder
with tf.variable_scope('encoder'):
encoder = self._get_simple_lstm(rnn_size, layer_size)
with tf.device('/cpu:0'):
input_x_embedded = tf.nn.embedding_lookup(encoder_embedding, self.input_x)
encoder_outputs, encoder_state = tf.nn.dynamic_rnn(encoder, input_x_embedded, dtype=tf.float32)
# define helper for decoder
if is_inference:
self.start_tokens = tf.placeholder(tf.int32, shape=[None], name='start_tokens')
self.end_token = tf.placeholder(tf.int32, name='end_token')
helper = GreedyEmbeddingHelper(decoder_embedding, self.start_tokens, self.end_token)
else:
self.target_ids = tf.placeholder(tf.int32, shape=[None, None], name='target_ids')
self.decoder_seq_length = tf.placeholder(tf.int32, shape=[None], name='batch_seq_length')
with tf.device('/cpu:0'):
target_embeddeds = tf.nn.embedding_lookup(decoder_embedding, self.target_ids)
helper = TrainingHelper(target_embeddeds, self.decoder_seq_length)
with tf.variable_scope('decoder'):
fc_layer = Dense(decoder_vocab_size)
decoder_cell = self._get_simple_lstm(rnn_size, layer_size)
decoder = BasicDecoder(decoder_cell, helper, encoder_state, fc_layer)
logits, final_state, final_sequence_lengths = dynamic_decode(decoder)
if not is_inference:
targets = tf.reshape(self.target_ids, [-1])
logits_flat = tf.reshape(logits.rnn_output, [-1, decoder_vocab_size])
print 'shape logits_flat:{}'.format(logits_flat.shape)
print 'shape logits:{}'.format(logits.rnn_output.shape)
self.cost = tf.losses.sparse_softmax_cross_entropy(targets, logits_flat)
# define train op
tvars = tf.trainable_variables()
grads, _ = tf.clip_by_global_norm(tf.gradients(self.cost, tvars), grad_clip)
optimizer = tf.train.AdamOptimizer(1e-3)
self.train_op = optimizer.apply_gradients(zip(grads, tvars))
else:
self.prob = tf.nn.softmax(logits)
def _get_simple_lstm(self, rnn_size, layer_size):
lstm_layers = [tf.contrib.rnn.LSTMCell(rnn_size) for _ in xrange(layer_size)]
return tf.contrib.rnn.MultiRNNCell(lstm_layers)