代码调试全指南-自然语言处理-基于预训练模型的方法,车万翔
文章目录
- introduction
- chp2: fmm分词&svg
- chp3: 维基百科语料库处理
- chp4: 情感分类
- chp5: cbow, skipgram...
- chp6: 动态词向量,ELMo
- chp7: 预训练语言模型(Pre-trained Language Model, PLM)GPT & BERT
introduction
从github中下载代码包或从我的某度网盘链接中下载我处理好的代码包plm-nlp-code-main,其中有chp2~chp8的示例代码。
注意右下角的解释器,选择自己下载好pytorch的环境,笔者这里是名为python3.7的环境(可以起任意名)。
chp2: fmm分词&svg
Page23:最简单的分词算法:正向最大匹配(Forward Maximum Matching, FMM)
i.e. 从前向后扫描桔子中的字符串,尽量找到词典中较长的单词作为分词的结果。
fmm_word_seg.py

Page16:svd.py奇异值分解,这里正确显示需要添加字体,详见chp2代码调试

chp3: 维基百科语料库处理
下载的文本text文件夹、wikiextractor工具、语料库压缩包均放在chp3同级的chp3-src目录中。注意,如果要用pycharm打开项目,那么应当单独打开chp3,否则如果打开项目中包含了text语料库,则会消耗大量时间进行编制索引 indexing (笔者进行了一个下午都没搞完AA文件夹,所以大概是不可行)
page63:
- convert_t2s.py
先根据chp3代码调试,对convert_t2s.py进行修改,对windows适配。
在plm-nlp-code-main文件夹中打开Terminal
在命令行工具中
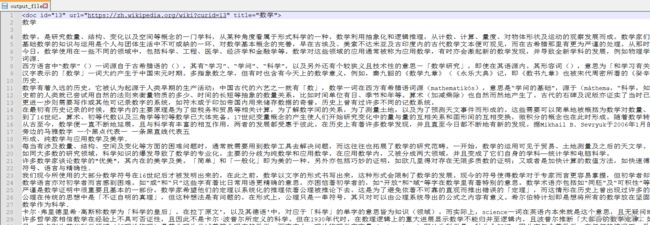
python .\chp3\convert_t2s.py .\chp3-src\text\AA\wiki_00 > output_file
原先\text\AA\wiki_00中的繁体文本

变为了output_file中的简体文本
2. wikidata_cleaning.py
对f_in = open(sys.argv[1], 'r')添加为f_in = open(sys.argv[1], 'r', encoding="utf-8");
对结尾print(line)添加为print(line.encode('GBK','ignore').decode('GBK'))
同样是在plm-nlp-code-main目录中写命令:
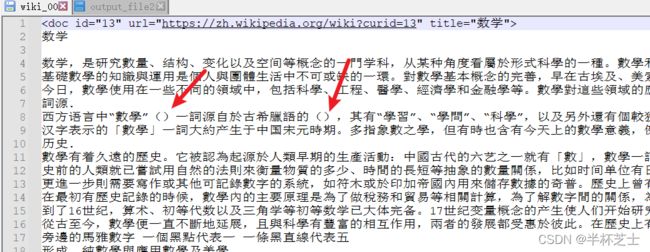
python .\chp3\wikidata_cleaning.py .\chp3-src\text\AA\wiki_00 > output_file2
可以将wiki_00数据进行清洗,去掉wiki_00中的括号等,打开output_file2可以看到括号等被去除了。
chp4: 情感分类
这里需要nltk工具包和语料,参考这里nltk的安装或者里nltk的安装2
简而言之,就是下载好nltk_data,把它放到合适的目录中即可。有点大,3G,并且是零散的小文件组合而成,所以复制或下载的速度都比较慢。(打个预防针,usb2.0的U盘拷贝都要用半个小时)
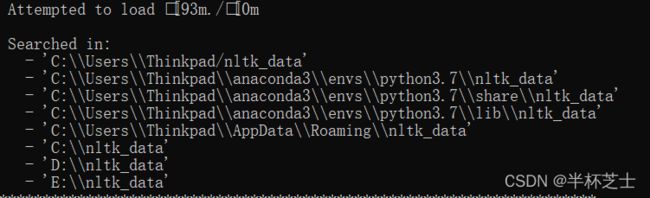
然后将代码分别运行即可。
cnn_sent_polarity.py:
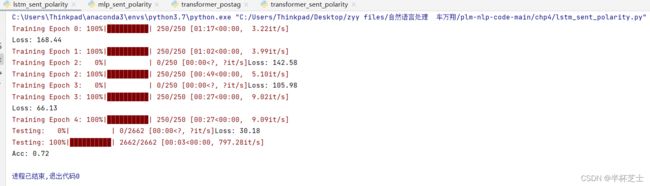
lstm_postag.py:
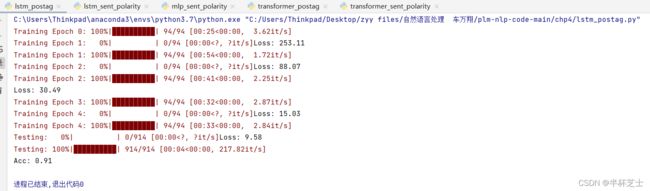
lstm_sent_polarity.py:
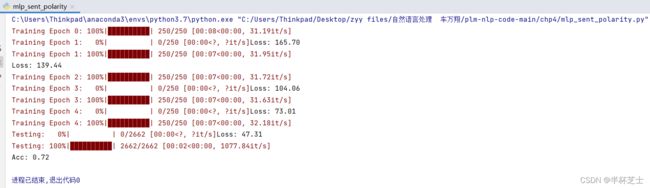
mlp_sent_polarity.py:
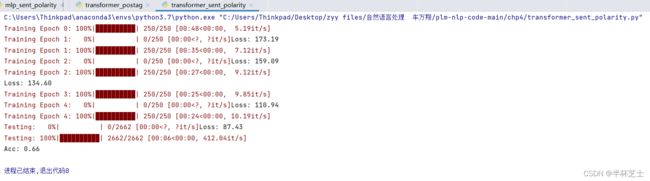
transformer_postag.py:

transformer_sent_polarity.py:
chp5: cbow, skipgram…
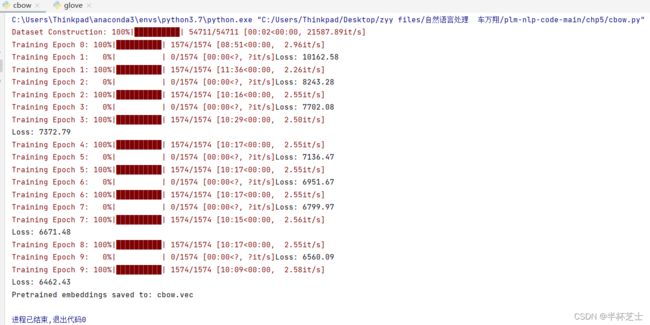
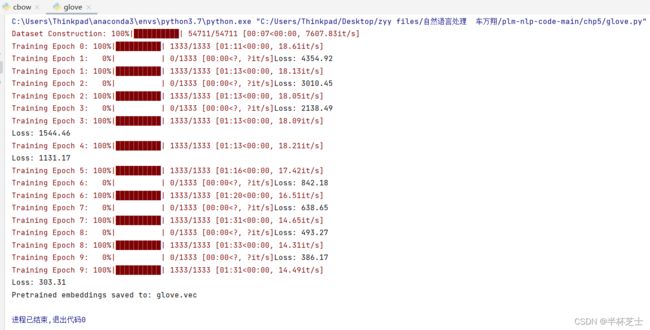
先运行cbow, glove, 产生.vec文件,再运行evaluate等。
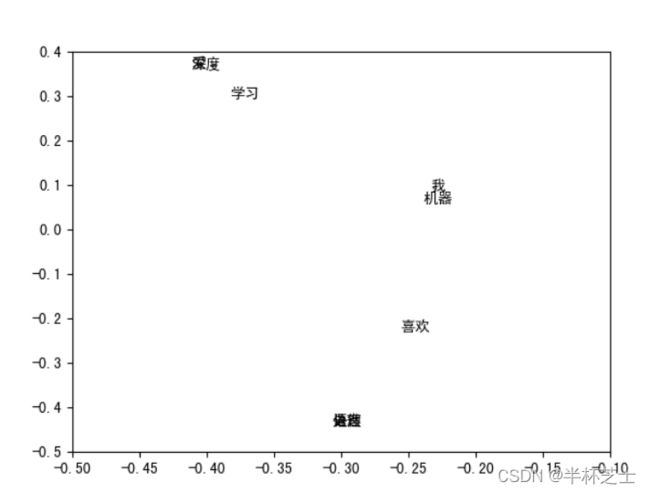
cbow.py
glove.py
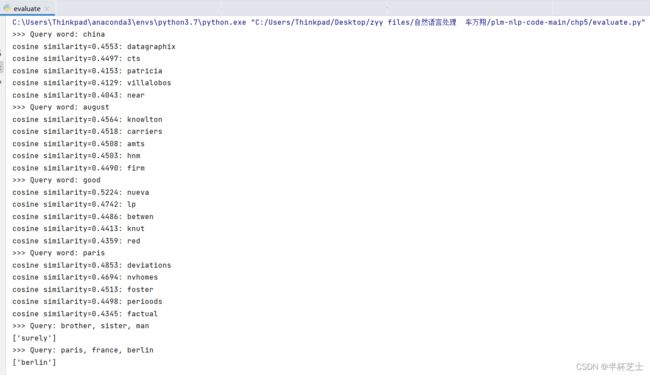
evaluate.py
ffnnlm.py
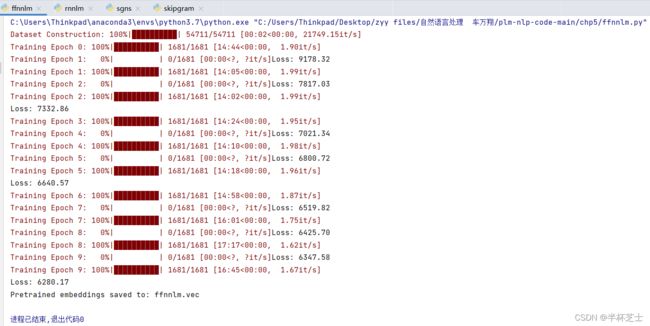
rnnlm.py 循环神经网络语言模型
这段代码绝了,用 机带RAM 64GB的工作站,还是out of memory,放弃。
RuntimeError: [enforce fail at ..\c10\core\CPUAllocator.cpp:72] data. DefaultCPUAllocator: not enough memory: you tried to allocate 26734632960 bytes. Buy new RAM!
like this:

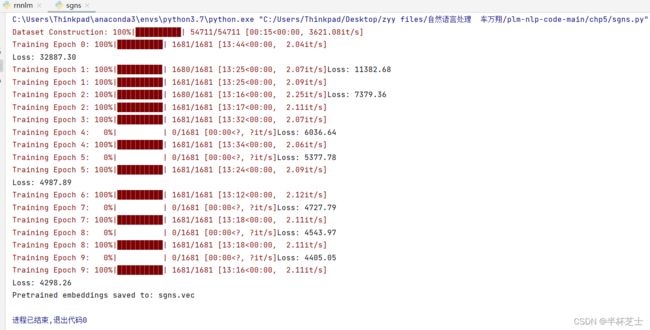
sgns.py skip-gram with negative-sample
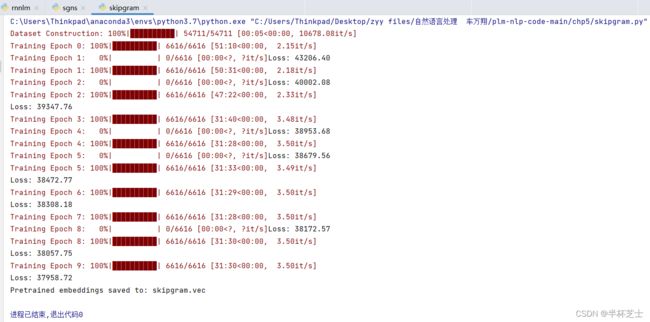
skipgram.py
chp6: 动态词向量,ELMo
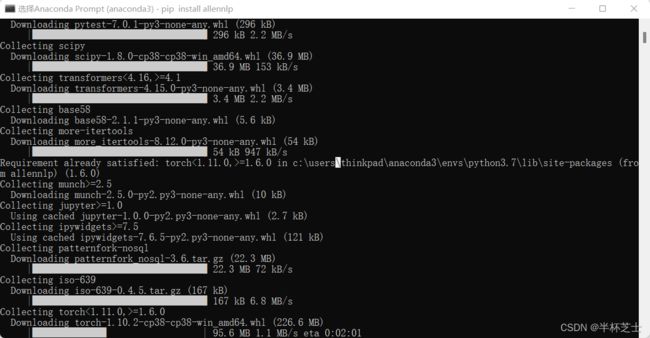
算力受限,不用自己的预料训练了,试用AI2发布的AllenNLP 工具包。
在anaconda的prompt shell中pip install allennlp安装
如图:
之后项目中新建allen_nlp.py文件,放入代码:
from allennlp.modules.elmo import Elmo, batch_to_ids
options_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json"
weights_file = "https://allennlp.s3.amazonaws.com/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
elmo = Elmo(options_file, weights_file, num_output_representations=1, dropout=0)
sentences = [['I', 'love', 'Elmo'], ['Hello', 'Elmo']]
character_ids = batch_to_ids(sentences)
print(character_ids)
embeddings = elmo(character_ids)
print(embeddings)
chp7: 预训练语言模型(Pre-trained Language Model, PLM)GPT & BERT
主流GPU均需要数小时的运行。普通笔记本还是别跑了。。。