NLP学习—12.Seq2Seq模型与Attention机制
文章目录
-
-
- 引言
- 一、文本生成任务
- 二、Seq2Seq讲解
-
- 1.Seq2Seq模型存在问题
- 三、Beam Search
-
- 1.Beam Search优化思路
- 四、Seq2Seq+Attention机制
-
引言
Seq2Seq模型用于文本生成。在这个模型基础上,加上Attention机制可以使得模型效果更好。
一、文本生成任务

常见的文本生成任务有以下几种:
-
Machine Translation(机器翻译)
不同语言之间的转换 -
Summarization(自动生成摘要)
有两种方法论:- 抽取式摘要生成
将原始文本中关键的句子、短语、关键单词抽取出来进行排序组合 - 生成式摘要生成
将文章做理解,再将理解到的意思写成简练的文本,很多单词不在原始文本,生成出来的文本可以存在语法上的问题,需要做二次修改。
- 抽取式摘要生成
-
Creative Writing(文案生成)
基于素材生成文案,比如根据产品的属性生成营销文案;根据研报生成文案;根据学生表现生成学习报告;根据知识图谱生成文案;根据评测生成评测报告; -
Image Captioning(给定图片,基于图片生成描述性文本)
如今,文本生成任务仍然存在局限性,很难达到百分之百自动化,而且需要大量的人工做二次编辑。
那么,如何构造文本生成模型呢?主要有两步:
- 理解文本(Encoder)
- 生成文本(Decoder)
Seq2Seq模型是Encoder-Decoder模型特例。下面介绍的Seq2Seq模型正好是基于这两步构建的,encoder主要用于理解给定的文本;用理解的含义通过decoder来生成文本。
二、Seq2Seq讲解
Seq2Seq实现了从一个序列到另外一个序列的转换,比如google曾用Seq2Seq模型加attention模型来实现了翻译功能,类似的还可以实现聊天机器人对话模型。
经典的RNN模型固定了输入序列和输出序列的大小,而Seq2Seq模型则突破了该限制。这种结构最重要的地方在于输入序列和输出序列的长度是可变的。Seq2Seq 模型可简单理解为由三部分组成:Encoder、Decoder 和连接两者的 State Vector (中间状态向量) C 。

S e q 2 S e q M o d e l Seq2Seq\ Model Seq2Seq Model
在 Encoder 中,将可变长度的序列转变为固定长度的向量表达,Decoder 将这个固定长度的向量转换为可变长度的目标的信号序列。
下面剖析经典的Vanilla Seq2Seq模型的细节。假设我们要做机器翻译任务,

我们训练(端到端训练)时,中文与英文同时给定,训练好后,就可以用于生成句子。vocab为语料库+[‘start’,‘end’]。
下面,我们重点讲解Greedy Decoding过程。预测时,Greedy Decoding(贪心解码)在每一步只会选择概率最大的作为下一步的输入,但选择当前最好的并不一定会给后面带来好的结果,这是Greedy Decoding存在的一个大的问题。解决这个问题的一个方式是做Exhaustive Search,即将所有的可能性全都考虑进来,然后计算所有可能性组合的语言模型的概率,选择语言模型概率最大的作为输出。这种方式不太合理,一方面需要知道有多少个单词需要生成;另一方面,计算量也非常大。
- Greedy Decoding—考虑最好的一个(Top1)
- Exhaustive Search—考虑所有(Top v)
基于这两个极端的这种方案为考虑Top K,即为Beam Search。
1.Seq2Seq模型存在问题
- 不同长度的输入文本,用同样大小的content表示是否合理?
从目前来说,确实是需要同样大小的content来表示的,假设考虑的问题都在同样的space上,那么,可以认为content vector处于某一个向量空间,同一个向量空间的大小肯定是一样的。在同样的文本下,必须采用同样的大小。这是Seq2Seq本身的问题。对于不同长度的文本学出来的c是一样的,但在训练阶段使用mini-batch的梯度下降法在gpu情况下是可以并行的,针对不同长度的句子,我们需要填充至同样的长度。 - c是否能够表达input text含义?
这是一个开放性问题,我们就认为c能够表达input text含义,没有准确的答案来定义这个问题。 - 梯度消失问题
当输入的文本序列很长时,由于梯度消失问题,就没有办法理解这么长文本序列的含义。 - 长期依赖
梯度消失问题导致长期依赖问题,因为梯度消失的问题导致不能捕获长序列文本的信息
由RNN/LSTM构成的Seq2Seq模型会导致梯度消失问题与长期依赖问题,解决这些问题需要Attention。
三、Beam Search
Beam Search即考虑Top K。例如,当k=3时,
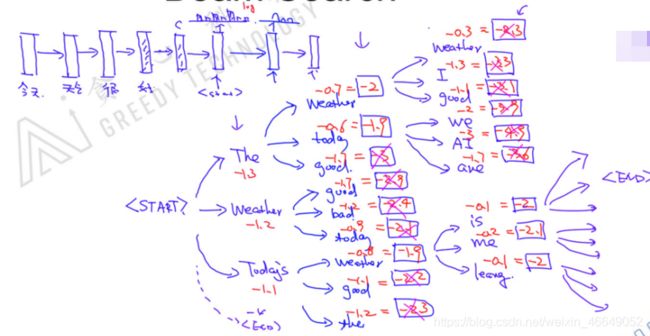
Beam Search不会进行无限扩张,会在每一个时间步中做裁剪(基于综合概率),每个时间步选择Top K单词,直到遇到 < E N D >
以这种方式运行的Beam Search的问题:会偏向于更短的句子序列。为了解决这个问题,将分数与序列长度挂钩,计算平均分数。
若
T = s e q u e n c e l e n g t h k = B e a m s i z e T=sequence\ length\\k=Beam\ size T=sequence lengthk=Beam size
时间复杂度为:
O ( k 2 T ) O(k^2T) O(k2T)
如果想在生成的环节上做一些控制,那么需要在decoding阶段 (Beam Search)做一些修改,最简单的需要修改的场景是在文章生成的过程中,我可能不想生成某一类的单词,则需要在Beam Search过程中将某些单词block掉。假设这个单词出现在Top 3的单词中,则将这个单词强行屏蔽掉,这是一种常见的方式。在某些任务中,可能更偏向于生成某些单词,则可以将概率强制性的调高。
1.Beam Search优化思路
Beam Search优化思路是Length normalization,对长度进行惩罚。
a r g m a x 1 T y α ∑ t = 1 T y l o g ( y < t > ∣ x , y < 1 > , . . . , y < t − 1 > ) arg\ max \ \frac{1}{T_y^\alpha}\sum_{t=1}^{T_y}log(y^{
Beam Search优化思路还有Coverage Normalization(coverage penalty),用于解决词被得到过多的关注。2016 年, 华为诺亚方舟实验室的论文提到,机器翻译的时候会存在over translation or under translation due to attention coverage。 作者提出了coverage-based atttention机制来解决coverage 问题。 Google machine system 利用了如下的方式进行了length normalization 和coverage penalty。

Encoder中的hidden states序号为 i i i。
Decoder中的hidden states序号为 j j j。
针对某一个 i i i,对attention weight进行相加后与1相比,然后再将所有的 i i i加起来。可以看出来:分布越均匀,cp值越大;分布差异越大,cp值越小。将 c p cp cp加到似然函数上得到 s ( Y , X ) s(Y,X) s(Y,X),越均匀似然函数越大,反之。优化目标是 − s ( Y , X ) -s(Y,X) −s(Y,X)越小越好。
句子生出什么时候停止?
- max length
- < e o s >
句子常依据上述两点进行停止,有时候会出现某些问题,导致长度一直不停止,长度过于长。这种情况的解决方案是 l o g l i k e h o d + e p ( X , Y ) loglikehod +ep(X,Y) loglikehod+ep(X,Y)

四、Seq2Seq+Attention机制
Attention机制的核心是计算出整个句子中哪个单词重要,哪个单词不重要。通俗来说,将重要的部分记住,将不重要的部分忘掉。注意力机制(Attention)其实本质上就是一种权重分配。
下面展示Seq2Seq+Attention机制的模型架构:
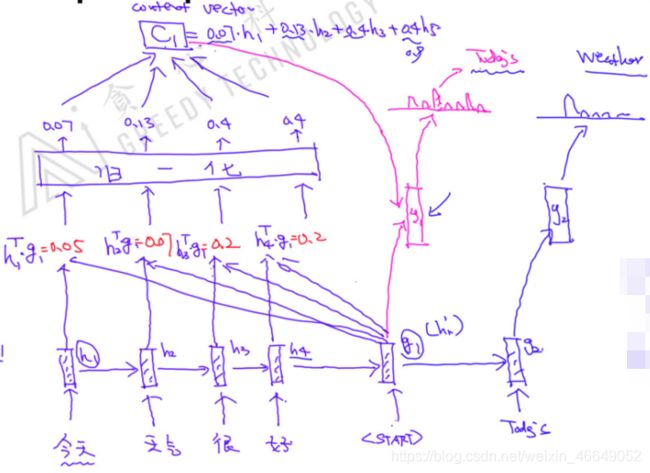
其中, c 1 c_1 c1由 h 1 T g 1 、 h 2 T g 1 、 h 3 T g 1 、 h 4 T g 1 h_1^Tg_1、h_2^Tg_1、h_3^Tg_1、h_4^Tg_1 h1Tg1、h2Tg1、h3Tg1、h4Tg1加权平均求得, c 2 c_2 c2由 h 1 T g 2 、 h 2 T g 2 、 h 3 T g 2 、 h 4 T g 2 h_1^Tg_2、h_2^Tg_2、h_3^Tg_2、h_4^Tg_2 h1Tg2、h2Tg2、h3Tg2、h4Tg2加权平均求得,
y 1 = f ( c 1 , g 1 ) = W h y [ c 1 , g 1 ] y ^ = s o f t m a x ( y 1 ) y_1=f(c_1,g_1)\\=W_{hy}[c_1,g_1]\\\hat{y}=softmax(y_1) y1=f(c1,g1)=Why[c1,g1]y^=softmax(y1)
g 1 g_1 g1是通过 h 4 h_4 h4与当前输入得到的,与之前的seq2seq是一样的。
每时每刻的输出依赖的content vector是不一样的,而在seq2seq中依赖的是同样的content vector。同时由于RNN/LSTM不能很好的记住长序列数据,加上Attention后,计算当前预测值相当于将之前所有隐变量全部考虑进来,所以可以部分的解决长期依赖问题(尽量避免梯度消失问题)。只要使用RNN/LSTM模型就一定会出现梯度消失问题。后面介绍的Transformer在没有所谓的梯度消失问题。
Attention与Beam Search是两个技术路线的东西,两者并不矛盾。Attention机制的可解释性与可视化的理解是非常优秀的。后面介绍的Transformer中的多头注意力机制可以看作是注意力机制的集成模型。
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论或者私信!
