制作图像分割数据集(多分类)
最近在学习图像分割相关知识,需要数据集,奈何网上找不到制作好的,只能硬着头皮制作。在网上找到一篇很好的文章记录一下
转载自:https://www.jianshu.com/p/29604b12f776?u_atoken=90e69015-31c5-42fb-baff-4555f55c7839&u_asession=013UCYdYUp89KfHvBR6fIF3P7FGu2tF1rYbCVYy6yn9MDRq1nu4dmrqys8z8Jft4RvX0KNBwm7Lovlpxjd_P_q4JsKWYrT3W_NKPr8w6oU7K8dzmQov3pBh5K5dE24POEhfT23-3PkyDy9XbOaRLWwzmBkFo3NEHBv0PZUm6pbxQU&u_asig=05H6c_C18NzGqylFOgxYxOf5PhkjJ-crctD3Ce3lQ-3CRbx_987BGP2MQjXAtuZFdd4ei3B58VJm8P9O6l43Y_Y6y9QMUGXddF1AITzPU0hHNP-imAsHIcdNGoWDBxK3tN2RXx_J8NNywm3uS24DDv6PXRk9yC8qSE3My0rT8H3nb9JS7q8ZD7Xtz2Ly-b0kmuyAKRFSVJkkdwVUnyHAIJzcqGdbjs2IuLuQ9zFCOy4p2hXjmK3uFUtinARWff5fio5tlkRHxf-gZK6IjlEzte9e3h9VXwMyh6PgyDIVSG1W-yGe3zhZTAI_dwdpEsPd2DJ2WtvUNG7x_AWHziMPYnF4177Y0aiqeo2F_OyerFysSX7SpnSKnv1VPZrRDQEO58mWspDxyAEEo4kbsryBKb9Q&u_aref=kas8AeMSnvPOjMClLF4TYN6u4vM%3D
1、使用labelme标注工具
这一步不多讲了,网上教程很多,贴一下代码
建议在anaconda虚拟环境下安装:创建虚拟环境安装,python版本选择3.6.x,打开Anaconda Prompt
conda create -n labelme python=3.6
conda activate labelme
pip install labelme
labelme
2、使用提供的脚本json_to_dataset.py把json转换为png形式,对于多分类的数据标注,需要在下面路径找到json_to_dataset.py修改
虚拟环境下的路径为
C:\Anaconda3\envs\labelme\Lib\site-packages\labelme\cli
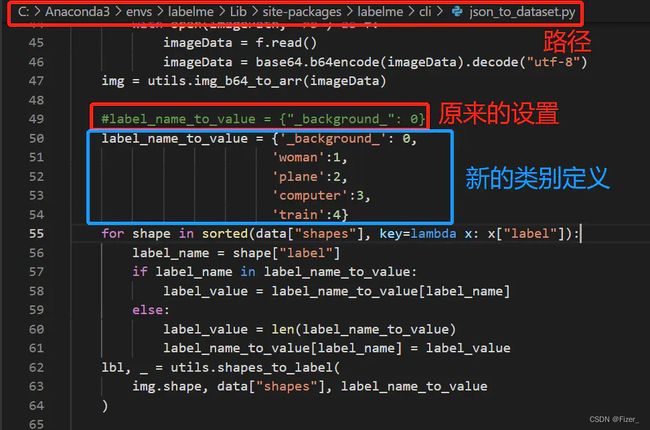
运行脚本执行转换json操作,以下代码名为labelme_json_to_png.py
# -*- coding: utf-8 -*-
import os
json_folder = r"C:\Users\eadhaw\Desktop\0120test"
# 获取文件夹内的文件名
FileNameList = os.listdir(json_folder)
for i in range(len(FileNameList)):
# 判断当前文件是否为json文件
if(os.path.splitext(FileNameList[i])[1] == ".json"):
json_file = json_folder + "\\" + FileNameList[i]
# 将该json文件转为png
os.system("labelme_json_to_dataset " + json_file)

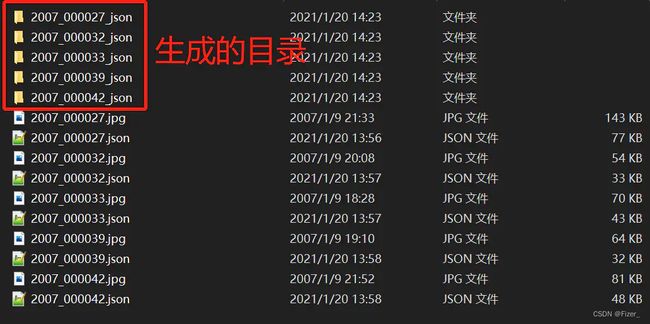
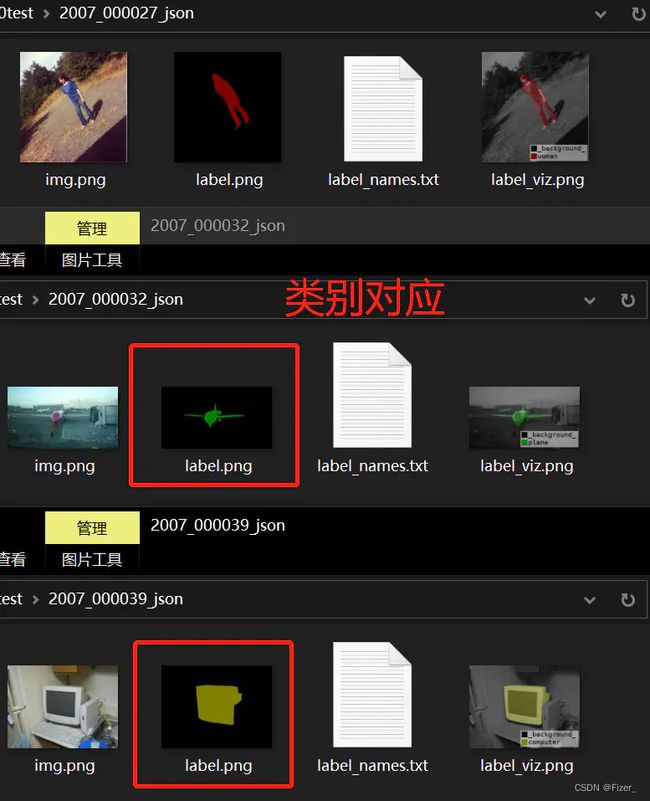
3、把数据整理为images,segmentations对应的文件夹
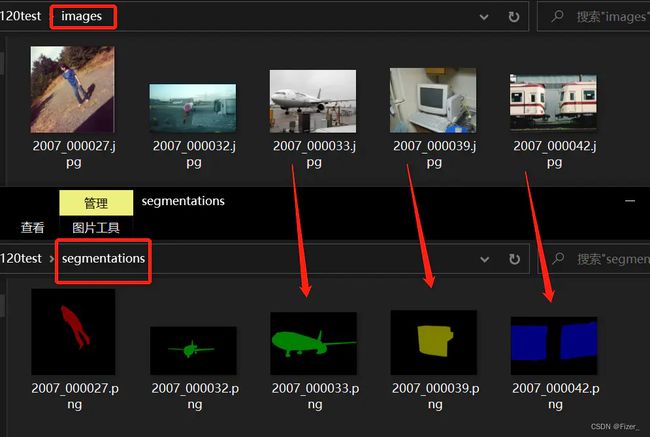
脚本如下:spilit_labelme_dataset.py
# -*- coding: utf-8 -*-
import os
import numpy as np
import json
import shutil
def find_dir_path(path, keyword_name, dir_list):
files = os.listdir(path)
for file_name in files:
file_path = os.path.join(path, file_name)
if os.path.isdir(file_path) and keyword_name not in file_path:
find_dir_path(file_path, keyword_name, dir_list)
elif os.path.isdir(file_path) and keyword_name in file_path:
dir_list.append(file_path)
all_result_path = []
src_path = r'C:\Users\eadhaw\Desktop\0120test'
label_save_path = r'C:\Users\eadhaw\Desktop\0120test\segmentations'
image_save_path = r'C:\Users\eadhaw\Desktop\0120test\images'
find_dir_path(src_path, '_json', all_result_path) # 找出所有带着关键词(_json)的所有目标文件夹
#print(all_result_path)
for dir_path in all_result_path:
# print(dir_path)
file_name = dir_path.split('\\')[-1]
key_word = file_name[:-5]
# print(key_word)
label_file = dir_path + "\\" + "label.png"
new_label_save_path = label_save_path + "\\" + key_word + ".png" # 复制生成的label.png到新的文件夹segmentations
#print(new_label_save_path)
shutil.copyfile(label_file, new_label_save_path)
img_dir = os.path.dirname(dir_path) # 复制原图到新的文件夹images
img_file = img_dir + "\\" + key_word + ".jpg"
new_img_save_path = image_save_path + "\\" + key_word + ".jpg"
shutil.copyfile(img_file, new_img_save_path)
4、把png转换为label图([128,0,0]对应类别1,其他依次类推)
# -*- coding: utf-8 -*-
import os
import cv2
import numpy as np
import matplotlib.pyplot as plt
import skimage.io as io
import skimage
print("skimage:", skimage.__version__) # '0.14.2'
color2index = {
(0,0,0) : 0,
(128,0,0) : 1,
(0,128,0) : 2,
(128,128,0) : 3,
(0,0,128) : 4,
}
def rgb2mask(img):
assert len(img.shape) == 3
height, width, ch = img.shape
assert ch == 3
W = np.power(256, [[0],[1],[2]])
img_id = img.dot(W).squeeze(-1)
values = np.unique(img_id)
mask = np.zeros(img_id.shape)
for i, c in enumerate(values):
try:
mask[img_id==c] = color2index[tuple(img[img_id==c][0])]
except:
pass
return mask
path = "C:/Users/eadhaw/Desktop/0120test/segmentations/"
new_path = "C:/Users/eadhaw/Desktop/0120test/labels/"
files = os.listdir(path)
for filename in files:
f_path = path + filename
print(f_path)
img = io.imread(f_path)
print(img.shape)
#判断一下读取的图像是否为三通道格式,rgba则要转换
if img.shape[2] == 4:
img = cv2.cvtColor(img, cv2.COLOR_BGRA2BGR)
mask = rgb2mask(img)
mask = mask.astype(np.uint8)
print(mask.shape)
f_new_path = new_path + filename
io.imsave(f_new_path,mask)
完成