Linux学习笔记——3.文件系统挂载
文件系统挂载
建议先看前两篇文章:
《磁盘与磁盘分区》《文件系统》
命令篇
free 查看内存情况
swapon -s 查看swap分区情况
/etc/fstab 挂载的配置文件
mount -o loop xxx.iso /mnt/cdron 挂载iso文件
mount /dev/sda1 /mnt/usbdisk 挂载usb/闪存设备
parted /dev/vda print 列出/dev/vda 的分区情况
原理篇
文件系统挂载的概述
好吧,这一章主要讲的是文件系统挂载的问题。
我们都知道,文件系统需要挂载在目录上,然后我们通过目录作为入口,才可以访问该文件系统,或者说该分区空间。
先简单讲一下Linux的目录树结构:
Linux的目录树结构
我们前面有谈过 Linux 内的所有数据都是以文件的形态来呈现的,所以啰,整个 Linux 系统最重要的地方就是在于目录树架构。 所谓的目录树架构(directory tree)就是以根目录为主,然后向下呈现分支状的目录结构的一种文件架构。 所以,整个目录树架构最重要的就是那个根目录(root directory),这个根目录的表示方法为一条斜线『/』, 所有的文件都与目录树有关。目录树的呈现方式如下图所示:
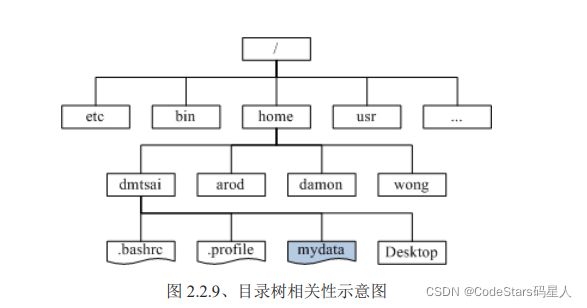
文件系统与目录树的关系(挂载)
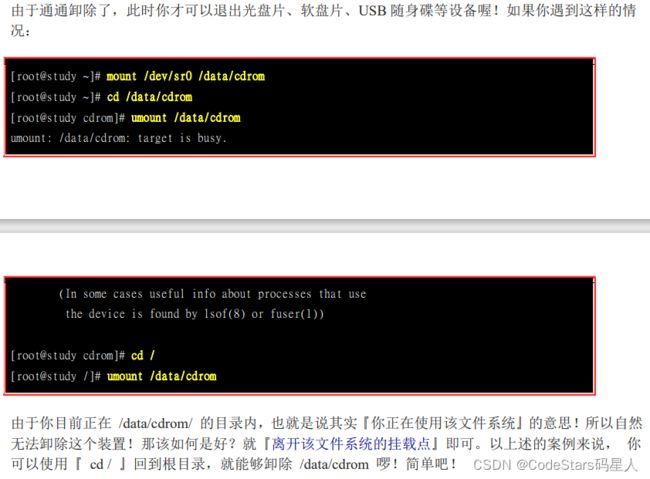
所谓的『挂载』就是利用一个目录当成进入点,将磁盘分区槽的数据放置在该目录下; 也就是说,进入该目录就可以读取该分区槽的意思。这个动作我们称之为【挂载】,那么进入点的目录我们称为【挂载点】。

我的理解是,根目录一定得首先挂载,然后你将partition挂载在根目录上,就说明所有存在根目录下的所有数据都会存在partition上,但是后来我们加入partition2,并将其挂载在/home上,所以这之后/home的内容存入partition上,但是其它内容仍然到partition上。
下面就来实际操作一下如何挂载?
首先,必须明确,要进行挂载的是文件系统,也就是已经格式化后的分区。
而且,还有下面几个要求:

尤其是上述的后两点!如果你要用来挂载的目录里面并不是空的,那么挂载了文件系统之后,原目录下的东西就会暂时的消失。举个例子来说,假设你的 /home 原本与根目录 (/) 在同一个文件系统中,底下原本就有 /home/test 与 /home/vbird 两个目录。然后你想要加入新的磁盘,并且直接挂载 /home 底下,那么当你挂载上新的分区槽时,则 /home 目录显示的是新分区槽内的资料,至于原先的 test 与vbird 这两个目录就会暂时的被隐藏掉了!注意喔!并不是被覆盖掉, 而是暂时的隐藏了起来,等到新分区槽被卸除之后,则 /home 原本的内容就会再次的跑出来啦!
实操篇
mount文件系统
挂载的命令也很简单,就用mount就好了。

你挂载时候,可以挂载文件系统的LABEL,或者文件系统的装置文件名,或者其UUID,当然最后一种方式比较建议。而且现在系统比较智能,甚至无需 -t 写上 文件系统的类型,系统就能自动识别为啥文件系统。
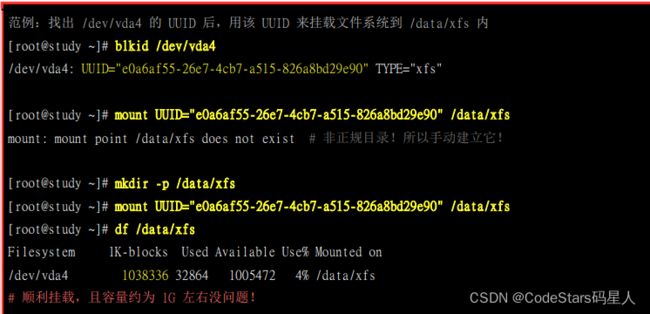
结合前几章所学,先blkid查询文件系统的UUID,然后挂载上去,然后再用df命令查看磁盘{文件系统)的使用情况。
mount USB磁盘
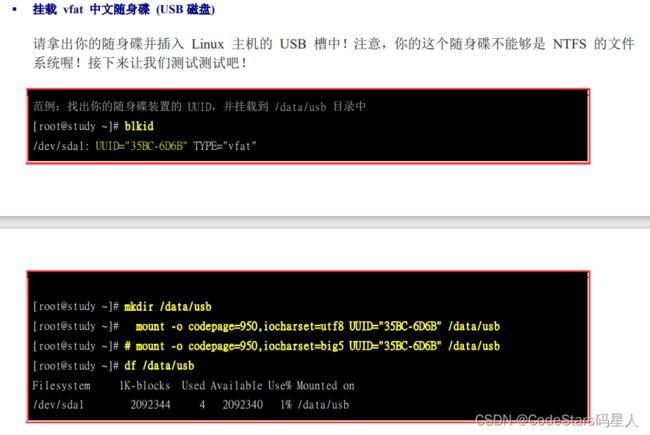
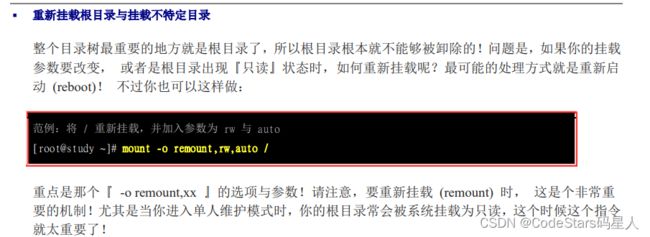
umount 将装置文件卸载

- xfs_admin 修改 XFS 文件系统的 UUID 与 Label name
- tune2fs 修改 ext4 的 label name 与 UUID
- mknod可以修改装置的 major,minor主要和次要装置代码
设定开机挂载
etc/fstab 与 /etc/mtab
刚刚上面说了许多,能不能在开机的时候就将我要的文件系统都挂好呢?
这样我就不需要每次进入都挂载一次了。当然可以,就去/etc/fstab里面修改就行了。
不过,在开始之前,还是需要说系统挂载的一些限制。

看一下/etc/fstab这个文件的内容:
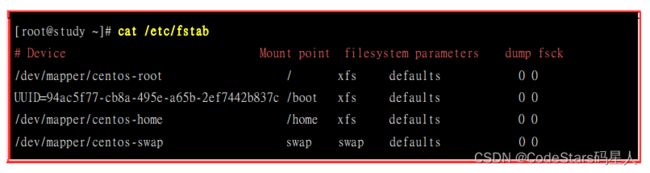


其实我们利用mount指令进行挂载时,也是将所有的选项与参数写入/etc/fstab这个文件中。
特殊装置 loop 挂载 (映象档不刻录就挂载使用)
这里也可以好好讲一下,在后面,我们会发现挂载的一些不是实际的硬盘,而时像光盘映像文件呀,或者说时文件作为磁盘的方式,那么就得用这种特殊的方式将其挂载起来.
比如说挂载镜像文件:
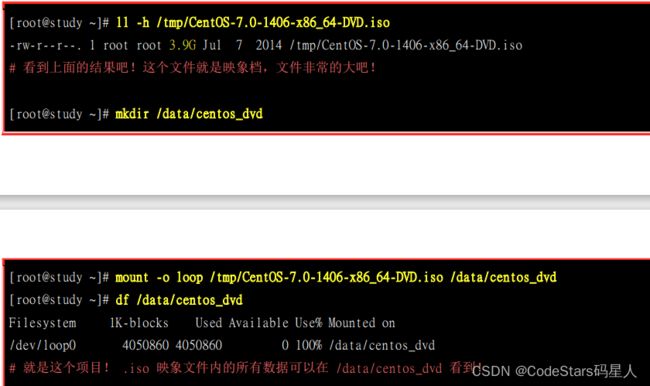
建立一个文件夹,然后将镜像文件挂载与该文件夹的目录,然后记得挂载时要加入参数 mount - o loop
就可以了.
其实镜像文件也可以理解成一个文件系统,而且这个文件系统还可以被软件识别然后刻录到光盘上.
再比如说挂载大文件:
我们其实可以建立一个大文件,然后将大文件格式化,其实这个大文件要挂载是就也得利用mount - o loop的参数.
先建立一个大文件:
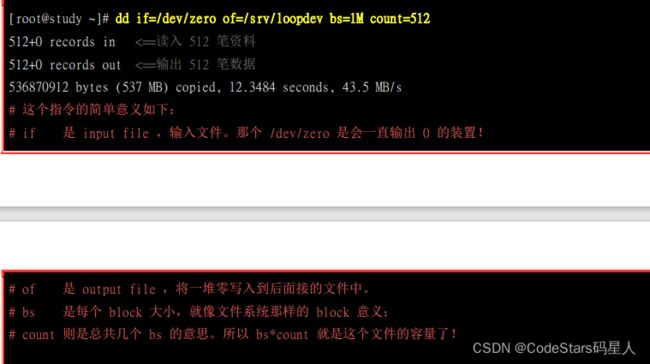
将大文件格式化

挂载:

写入/etc/fstab 文件

不过,这里提一嘴,建立这个大文件挂载有什么用呢?其实还挺有用的,可以帮助我们解决分区不良的问题.举例来说,如果当初在分区时, 你只有分区出一个根目录,假设你已经没有多余的容量可以进行额外的分区的!偏偏根目录的容量还很大! 此时你就能够制作出一个大文件,然后将这个文件挂载!如此一来感觉上你就多了一个分区槽啰!
使用实体分区槽建置 swap
先说说swap的功能吧,其实swap就是类似于window里面的虚拟内存,它的功能,就是当物理内存不够时,某些再内存中所占的程序会被暂时移动到swap当中,让物理内存被更需要的程序来使用.另外,如果主机休眠时,运行当中的程序状态会被记录到swap去,以作为唤醒主机状态的依据.
当时其实,window的虚拟内存和Linux的swap还是有所区别的.
1.window的虚拟内存可以放在c盘或者D盘,也就是说可以和其它系统文件放在一个盘符.虚拟内存时电脑自动设置的。而Linux的swap则是独立占用一个分区,且是需要在系统安装时手建立的。

2.且windows在物理内存没有用完时也会去用到虚拟内存,而Linux只有当物理内存用完时,才会主动去用swap分区。
那么简单说一下,如果建立系统后,却发现没有建置swap,该怎么办呢?其实也很简单,和前面分区的知识一样,只是将一些参数改变一下而已.
- 分区:先使用 gdisk 在你的磁盘中分区出一个分区槽给系统作为 swap 。由于 Linux 的 gdisk 预设会将分区槽的 ID 设定为 Linux 的文件系统,所以你可能还得要设定一下system ID 就是了。
- 格式化:利用建立 swap 格式的mkswap 装置文件名就能够格式化该分区槽成为 swap 格式啰
- 使用:最后将该 swap 装置启动,方法为:『swapon 装置文件名』。

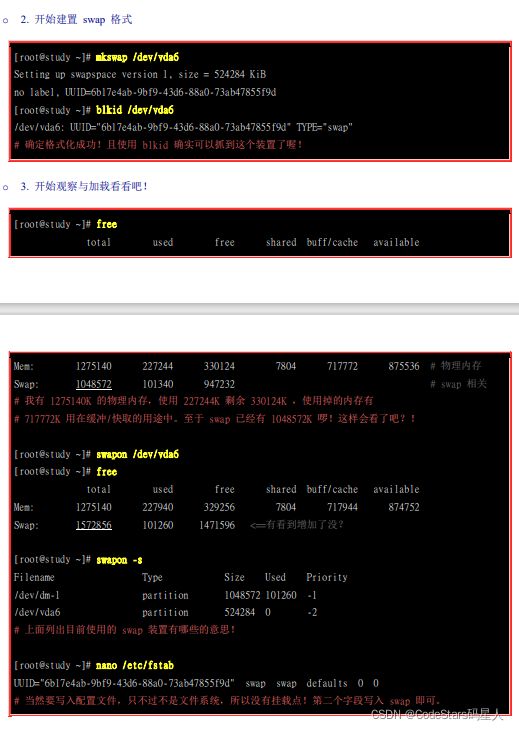
另外,也可以用前面说到的建立一个大文件然后将其格式化为swap的文件格式,然后将其启动.
总结一下:制作swap分区
- 首先建立文件或者划分出一个分区(得是swap格式)
- mkswap 该分区或者该文件 将其格式化为swap格式
- swpon 该文件或者该分区 将其启动
- nano /etc/fstab 写入配置文件
- swapon -s 与free 查看情况
好吧,我们前面也说明了磁盘的分区,分区的格式化,以及分区的挂载等问题,接下来,我们来学更加进阶的文件系统,分别时QUOTA和LVM.
进阶文件系统
下面是一些进阶的文件系统,如果太难理解就跳过,直接看总结部分吧。
磁盘配额(Quota)
什么是Quota?
在 Linux 系统中,由于是多人多任务的环境,所以会有多人共同使用一个硬盘空间的情况发生, 如果其中有少数几个使用者大量的占掉了硬盘空间的话,那势必压缩其他使用者的使用权力!
举例来说,我们用户的默认家目录都是在 /home 底下,如果 /home 是个独立的 partition , 假设这个分区槽有 10G 好了,而 /home 底下共有 30 个账号,也就是说,每个用户平均应该会有 333MB 的空间才对。 偏偏有个用户在他的家目录底下塞了好多只影片,占掉了 8GB 的空间,想想看,是否造成其他正常使用者的不便呢? 如果想要让磁盘的容量公平的分配,这个时候就得要靠 quota 的帮忙啰!
说白了,就是分区之后,然后对该分区中用户或者用户组能使用的量加以限制.

其实就好像是我们使用网络上的网盘的功能,某个公司给我们的网盘分配多少容量,就是我们所使用的服务器里的硬盘的Quota.(我猜的,可能原理差不多吧,后面再去深入了解下)
quota 这玩意儿针对 XFS filesystem 的限制项目主要分为底下几个部分:
o 分别针对用户、群组或个别目录 (user, group & project):
XFS 文件系统的 quota 限制中,主要是针对群组、个人或单独的目录进行磁盘使用率的限制!
o 容量限制或文件数量限制 (block 或 inode):
文件系统主要规划为存放属性的 inode 与实际文件数据的block 区块,Quota 既然是管理文件系统,所以当然也可以管理 inode 或 block 啰! 这两个管理的功能为:
限制 inode 用量:可以管理使用者可以建立的『文件数量』;
限制 block 用量:管理用户磁盘容量的限制,较常见为这种方式。

我们来实际操作一下XFS的Quota实作范例。
限制1:限制使用者与群组


首先第一步就是要在 /etc/fstab文件中找到要Quota的文件系统,然后再defaults后面加上需要要限额的参数.

比如上面就对user和group进行了Quota.
然后需要卸载,再重新挂载.
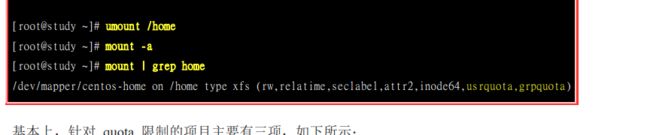
限额的参数有这三项:

现在已经启动了该功能,但还没有实际设置Quota.
设置用户的Quota
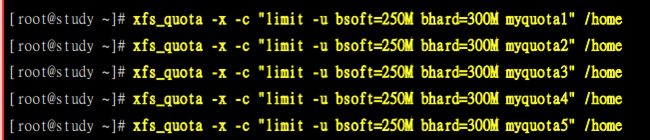
设置用户组的Quota
![]()
设定一下grace time

限制2:对project限制.只是这个项目不可以跟group 同时设定喔! 因此我们得要取消 group 设定并且加入 project 设定才行。那就来实验看看。
同样的,要修改/etc/fstab的文件,然后重新挂载.
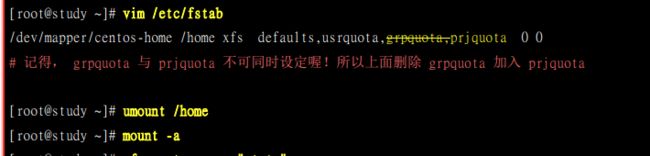
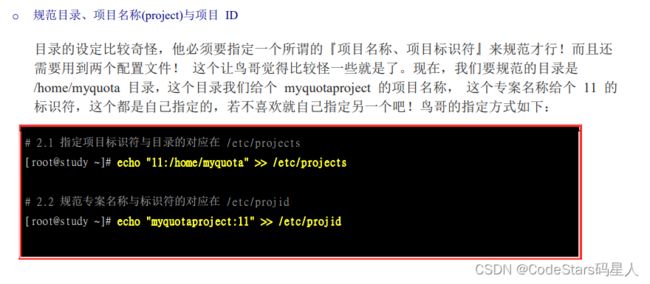
也就是说它必须让我们给目录起个名称(muquotaproject),然后下面的两个步骤就是将名称和目录对应起来.
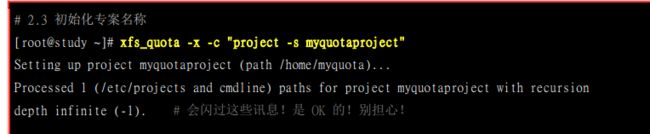
实际设置Quota

如何关系quota功能等,详情也可以看书.
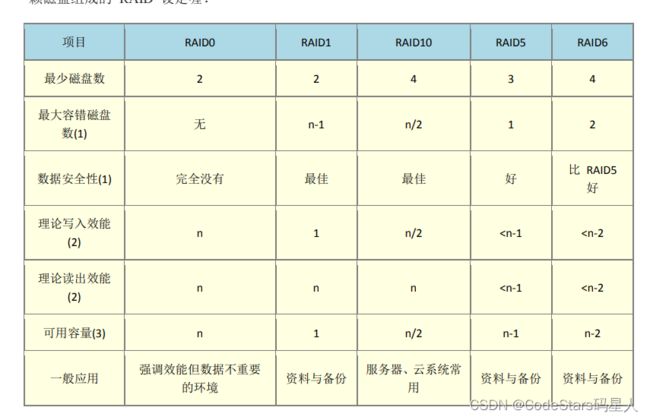
软件磁盘阵列(Sofeware RAID)
磁盘阵列全名是『 Redundant Arrays of Inexpensive Disks, RAID 』,RAID 可以透过一个技术(软件或硬件),将多个较小的磁盘整合成为一个较大的磁盘装置;而这个较大的磁盘功能可不止是储存而已,他还具有数据保护的功能呢。整个 RAID 由于选择的等级 (level) 不同,而使得整合后的磁盘具有不同的功能,基本常见的 level 有这几种
- RAID-0 (等量模式, stripe):效能最佳
这个其实很好理解,这种模式的RAID会将磁盘先切成等量的区块(名为 chunk,一般可设定 4K~1M 之间),然后当一个文件要写入RAID是,也是将文件依据chunk的大小切割好,放到各个磁盘里面去.
由于每个磁盘会交错的存放数据, 因此当你的数据要写入 RAID 时,数据会被等量的放置在各个磁盘上面。举例来说,你有两颗磁盘组成 RAID-0 , 当你有 100MB 的数据要写入时,每个磁盘会各被分配到 50MB 的储存量。
由于每个磁盘会交错的存放数据, 因此当你的数据要写入 RAID 时,数据会被等量的放置在各个磁盘上面。举例来说,你有两颗磁盘组成 RAID-0 , 当你有 100MB 的数据要写入时,每个磁盘会各被分配到 50MB 的储存量。

如图,越多颗磁盘组成的 RAID-0 效能会越好,因为每颗负责的资料量就更低了! 这表示我的资料可以分散让多颗磁盘来储存,当然效能会变的更好啊!此外,磁盘总容量也变大了! 因为每颗磁盘的容量最终会加总成为 RAID-0 的总容量喔!
但是有个缺点就是因此 RAID-0 只要有任何一颗磁盘损毁,在 RAID 上面的所有数据都会遗失而无法读取.
- RAID-1 (映像模式, mirror):完整备份

这个也很好了理解,就是用两个磁盘Disk A,Disk B组成.一份数据传送送到 RAID-1 之后会被分为两股,并分别写入到各个磁盘里头去。 由于同一份数据会被分别写入到其他不同磁盘,因此如果要写100MB 时,数据传送到 I/O 总线后会被复制多份到各个磁盘, 结果就是数据量感觉变大了!因此在大量写入 RAID-1 的情况下,写入的效能可能会变的非常差 (因为我们只有一个南桥啊!)。
好在如果你使用的是硬件 RAID (磁盘阵列卡)
时,磁盘阵列卡会主动的复制一份而不使用系统的 I/O 总线,效能方面则还可以。 如果使用软件磁
盘阵列,可能效能就不好了。
使用这个方法的缺点在于读写效率不高,而且由于磁盘容量有一半用在备份,因此总容量会是全部磁盘容量的一半而已.但是其最大的优点就是数据的备份.当任何一颗磁盘损坏时,另一颗可以完整地保存下来.
- RAID 1+0,RAID 0+1
既然RAID-0 的效能佳但是数据不安全,RAID-1 的数据安全但是效能不佳,那么能不能将这两者整合起来设定 RAID 呢?
可以的,那就是RAID-1+0或者 RAID -0+1的情况.
比如先看一下RAID-1+0的情况.所谓的RAID 1+0的意思就是先用两颗磁盘组成RAID1的情况,然后再另两颗磁盘组成RAID1的情况,然后这两组再组成一个RAID0.
复习一下RAID0是性能占有,RAID1是备份占优.所以整体思路就是要存数据时,一份给左边,下一份给右边.(RAID0).然后在左边和右边都各自有两个磁盘,各自备份一份,.(RAID1)
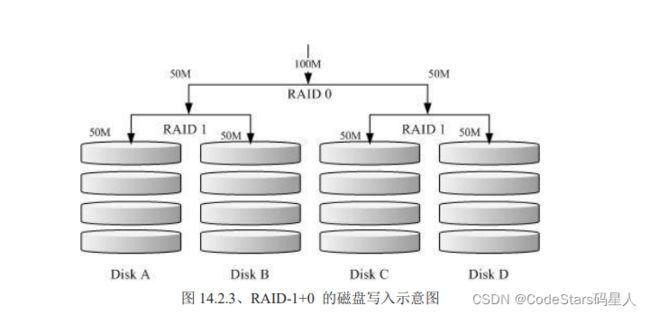
如图,就是这个道理.Disk A + Disk B 组成第一组 RAID 1,Disk C + Disk D 组成第二组 RAID 1, 然后这两组再整合成为一组 RAID 0。如果我有 100MB 的数据要写入,则由于 RAID 0 的关系, 两组RAID 1 都会写入 50MB,又由于 RAID 1 的关系,因此每颗磁盘就会写入 50MB 而已。 如此一来不论哪一组 RAID 1 的磁盘损毁,由于是 RAID 1 的映像数据,因此就不会有任何问题发生了!这也是目前储存设备厂商最推荐的方法!
- RAID 5:效能与数据备份的均衡考虑
RAID-5 至少需要三颗以上的磁盘才能够组成这种类型的磁盘阵列。这种磁盘阵列的数据写入有点类似 RAID-0 ,不过每个循环的写入过程中(striping),在每颗磁盘还加入一个同位检查数据 (Parity) ,这个数据会记录其他磁盘的备份数据, 用于当有磁盘损毁时的救援。RAID-5 读写的情况有点像底下这样:
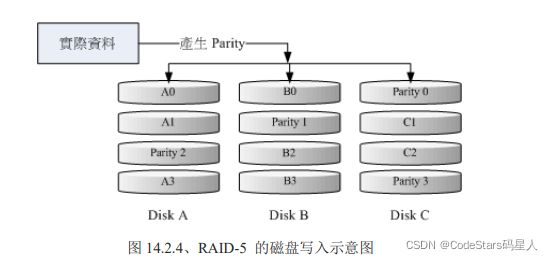
如上图所示,每个循环写入时,都会有部分的同位检查码 (parity) 被记录起来,并且记录的同位检查码每次都记录在不同的磁盘, 因此,任何一个磁盘损毁时都能够藉由其他磁盘的检查码来重建原本磁盘内的数据喔!不过需要注意的是, 由于有同位检查码,因此 RAID 5 的总容量会是整体磁盘数量减一颗。以上图为例, 原本的 3 颗磁盘只会剩下 (3-1)=2 颗磁盘的容量。而且当损毁的磁盘数量大于等于两颗时,这整组 RAID 5 的资料就损毁了。 因为 RAID 5 预设仅能支持一颗磁盘的损毁情况。
也就是说,如果一次磁盘损坏,那么它上面存储的数据在其它两个磁盘的parity上都能找到,所以一个磁盘坏了,可以回复,但如果两个磁盘坏了,那么剩下的另一个磁盘并没有能力恢复其余两个磁盘的数据.
在读写效能的比较上,读取的效能还不赖!与 RAID-0 有的比!不过写的效能就不见得能够增加很多! 这是因为要写入 RAID 5 的数据还得要经过计算同位检查码 (parity) 的关系。由于加上这个计算的动作, 所以写入的效能与系统的硬件关系较大!尤其当使用软件磁盘阵列时,同位检查码是透过 CPU 去计算而非专职的磁盘阵列卡, 因此效能方面还需要评估。

不仅有硬件磁盘阵列,还有软件磁盘阵列.软件磁盘阵列可以使用分区组成一个磁盘阵列

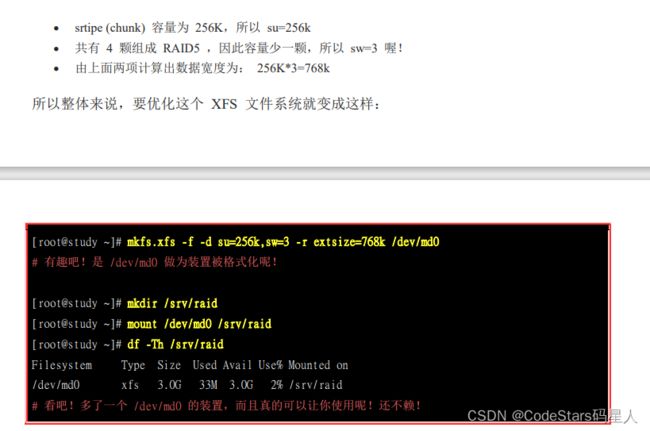
意思是将dev/vdaa{5,6,7,8,9}组成一个软件磁盘阵列/dev/md0.
然后如果要对该软件磁盘阵列格式化和挂载:
另外,关于软件磁盘的出错时的救援模式和开机自动挂载详情请看书吧.
总结
三篇文章,我们学习了磁盘的分区,MBR,GPT和LVM形式。
然后也学习了各种文件系统的格式,学习了挂载文件系统,学习了硬盘,文件系统,挂载和目录之间的关系。
构建文件系统三部曲总结如下:
- 找到磁盘,将磁盘分区(可以将分区变成LVM形式)
- 将分区格式化(建置文件系统)
- 将文件系统挂载到相应目录
三篇文章,将自己从《鸟哥的Linux私房菜》学到的关于磁盘与文件系统的知识总结如下,不够详细,也不够深入,自己也只是刚刚入门学习,如果总结的内容有什么不足或错误,也希望大家能够指出,共同学习,一起进步!
参考资料:《鸟哥的Linux私房菜——基础篇》